Podle Wikipedie je hromadné vkládání proces nebo metoda poskytovaná systémem správy databáze k načtení více řádků dat do databázové tabulky. Pokud toto vysvětlení upravíme na příkaz BULK INSERT, hromadné vložení umožní import externích datových souborů do SQL Serveru.
Předpokládejme, že naše organizace má soubor CSV s 1 500 000 řádky a chceme jej importovat do konkrétní tabulky na serveru SQL Server, abychom mohli na serveru SQL Server použít příkaz BULK INSERT. Můžeme najít několik způsobů, jak tento úkol zvládnout. Může to být pomocí BCP (b ulk c opište p program), Průvodce importem a exportem SQL Server nebo balíček SQL Server Integration Service. Příkaz BULK INSERT je však mnohem rychlejší a silnější. Další výhodou je, že nabízí několik parametrů, které pomáhají určit nastavení procesu hromadného vkládání.
Začněme základní ukázkou. Poté projdeme sofistikovanějšími scénáři.
Příprava
Nejprve potřebujeme vzorový soubor CSV. Stáhneme si ukázkový soubor CSV z webu E for Excel (sbírka ukázkových souborů CSV s jiným číslem řádku). Zde použijeme 1 500 000 záznamů o prodeji.
Stáhněte si soubor zip, rozbalte jej, abyste získali soubor CSV, a umístěte jej na místní disk.
Import souboru CSV do tabulky serveru SQL Server
Náš CSV soubor importujeme do cílové tabulky v nejjednodušší podobě. Umístil jsem svůj ukázkový soubor CSV na jednotku C:. Nyní vytvoříme tabulku pro import dat souboru CSV do ní:
DROP TABLE IF EXISTS Sales CREATE TABLE [dbo].[Sales]( [Region] [varchar](50) , [Country] [varchar](50) , [ItemType] [varchar](50) NULL, [SalesChannel] [varchar](50) NULL, [OrderPriority] [varchar](50) NULL, [OrderDate] datetime, [OrderID] bigint NULL, [ShipDate] datetime, [UnitsSold] float, [UnitPrice] float, [UnitCost] float, [TotalRevenue] float, [TotalCost] float, [TotalProfit] float )
Následující příkaz BULK INSERT importuje soubor CSV do tabulky Prodej:
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); Pravděpodobně jste si všimli konkrétních parametrů výše uvedeného příkazu hromadného vložení. Pojďme si je ujasnit:
- PRVNÍ určuje počáteční bod příkazu insert. V níže uvedeném příkladu chceme přeskočit záhlaví sloupců, proto nastavíme tento parametr na 2.

- FIELDTERMINATOR definuje znak, který odděluje pole od sebe. SQL Server tímto způsobem detekuje každé pole.
- ROWTERMINATOR se příliš neliší od FIELDTERMINATOR. Definuje charakter oddělení řádků.
V ukázkovém souboru CSV je FIELDTERMINATOR velmi jasný a je to čárka (,). Chcete-li tento parametr zjistit, otevřete soubor CSV v programu Notepad++ a přejděte na Zobrazit -> Zobrazit symbol -> Zobrazit všechny charty. Znaky CRLF jsou na konci každého pole.
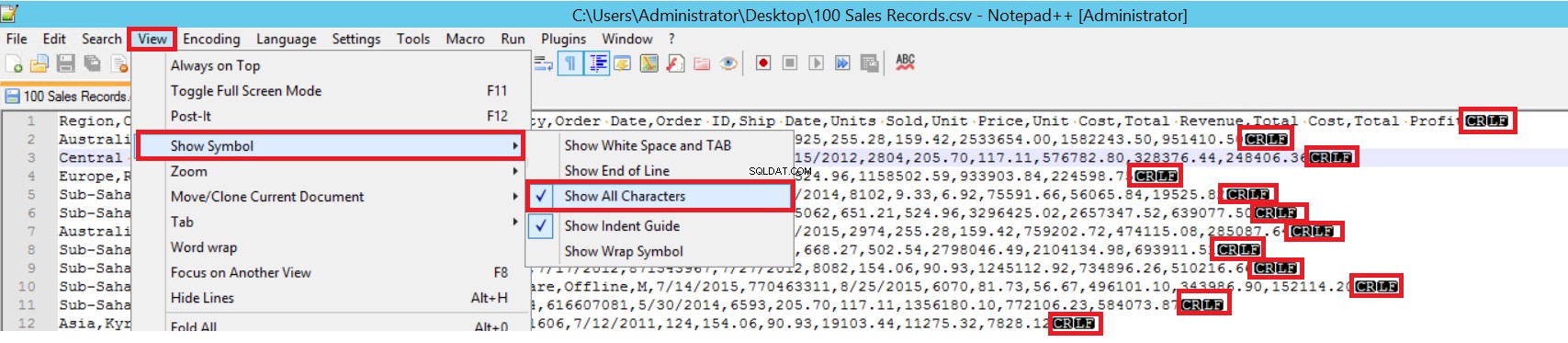
CR =Carriage Return a LF =Line Feed. Používají se k označení konce řádku v textovém souboru. V příkazu hromadného vložení je indikátor „\n“.
Dalším způsobem, jak importovat soubor CSV do tabulky s hromadným vkládáním, je použití parametru FORMAT. Upozorňujeme, že tento parametr je k dispozici pouze v SQL Server 2017 a novějších verzích.
BULK INSERT Sales FROM 'C:\1500000 Sales Records.csv' WITH (FORMAT='CSV' , FIRSTROW = 2);
To byl nejjednodušší scénář, kdy cílová tabulka a soubor CSV mají stejný počet sloupců. V případě, kdy má cílová tabulka více sloupců, je však typický soubor CSV. Zvažme to.
Přidáme primární klíč do tabulky Prodej, abychom narušili mapování sloupců rovnosti. Vytvoříme tabulku Prodej s primárním klíčem a importujeme soubor CSV pomocí příkazu hromadného vložení.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
Id INT PRIMARY KEY IDENTITY (1,1),
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); Vyvolá to však chybu:
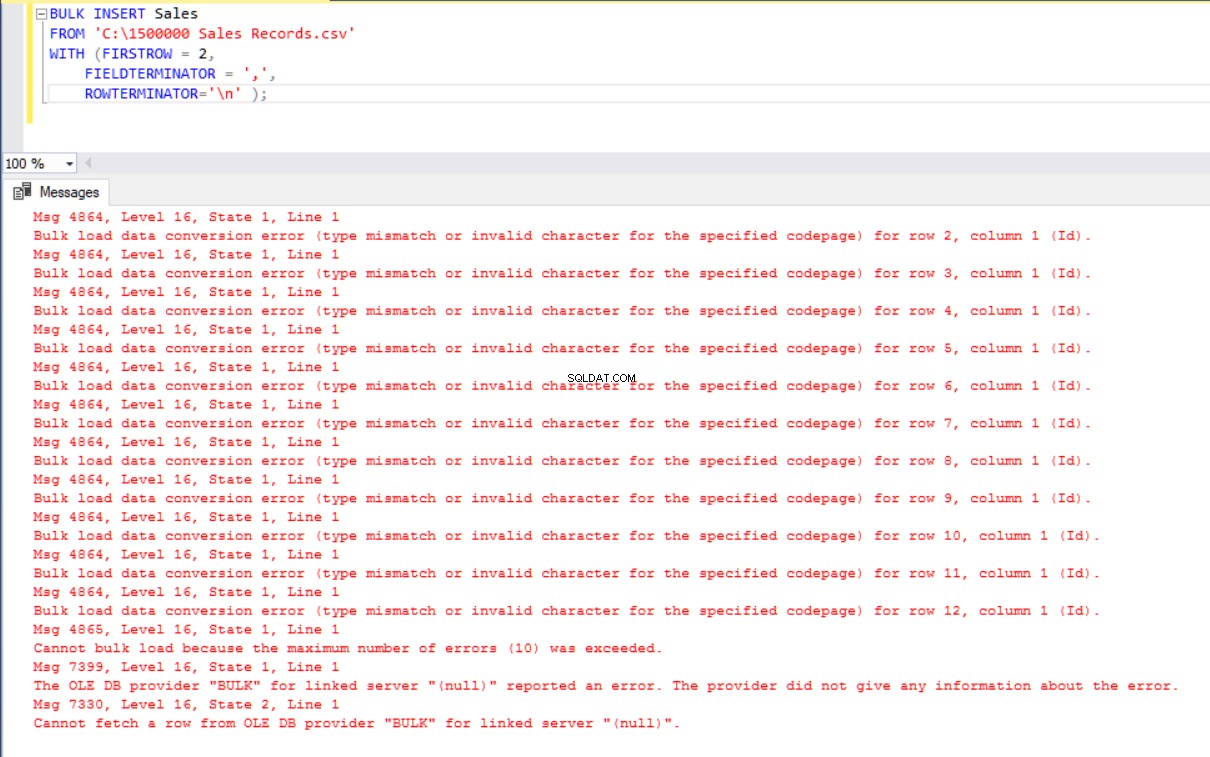
K překonání chyby vytvoříme pohled na tabulku Prodej s mapováním sloupců do souboru CSV. Poté importujeme data CSV přes toto zobrazení do tabulky Prodej:
DROP VIEW IF EXISTS VSales
GO
CREATE VIEW VSales
AS
SELECT Region ,
Country ,
ItemType ,
SalesChannel ,
OrderPriority ,
OrderDate ,
OrderID ,
ShipDate ,
UnitsSold ,
UnitPrice ,
UnitCost ,
TotalRevenue,
TotalCost,
TotalProfit from Sales
GO
BULK INSERT VSales
FROM 'C:\1500000 Sales Records.csv'
WITH ( FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); Oddělte a načtěte velký soubor CSV do malé dávky
SQL Server získá zámek cílové tabulky během operace hromadného vložení. Ve výchozím nastavení, pokud nenastavíte parametr BATCHSIZE, SQL Server otevře transakci a vloží do ní celá data CSV. Pomocí tohoto parametru SQL Server rozdělí data CSV podle hodnoty parametru.
Rozdělme celá data CSV do několika sad po 300 000 řádcích.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
batchsize=300000 ); Data budou importována pětkrát po částech.
- Pokud váš příkaz hromadného vložení neobsahuje parametr BATCHSIZE, dojde k chybě a SQL Server vrátí celý proces hromadného vložení zpět.
- S tímto parametrem nastaveným na příkaz hromadného vložení SQL Server vrátí zpět pouze část, kde došlo k chybě.
Pro tento parametr neexistuje optimální ani nejlepší hodnota, protože jeho hodnota se může měnit podle požadavků vašeho databázového systému.
Nastavte chování v případě chyb
Pokud v některých scénářích hromadného kopírování dojde k chybě, můžeme proces hromadného kopírování buď zrušit, nebo jej ponechat v chodu. Parametr MAXERRORS nám umožňuje určit maximální počet chyb. Pokud proces hromadného vkládání dosáhne této maximální chybové hodnoty, zruší operaci hromadného importu a vrátí se zpět. Výchozí hodnota tohoto parametru je 10.
Například jsme poškodili datové typy ve 3 řádcích souboru CSV. Parametr MAXERRORS je nastaven na 2.

DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2); Celá operace hromadného vkládání bude zrušena, protože existuje více chyb než hodnota parametru MAXERRORS.
Pokud změníme parametr MAXERRORS na 4, příkaz hromadného vložení tyto řádky s chybami přeskočí a vloží řádky se správnou strukturou dat. Proces hromadného vkládání bude dokončen.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=4);
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales Pokud použijeme současně BATCHSIZE i MAXERRORS, proces hromadného kopírování nezruší celou operaci vložení. Zruší pouze rozdělenou část.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
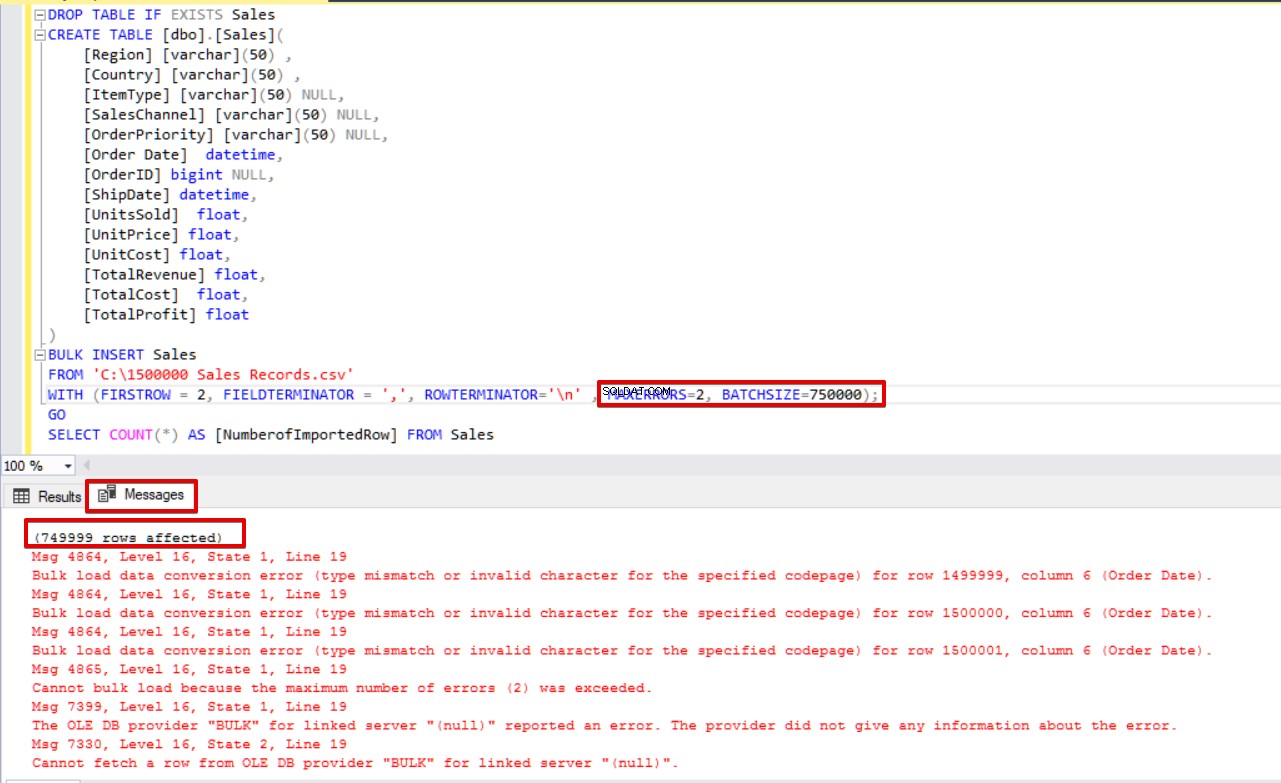
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2,
BATCHSIZE=750000);
GO
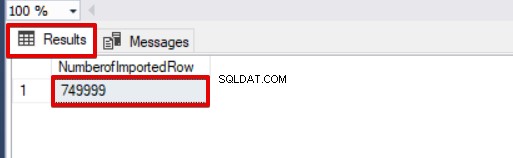
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales Podívejte se na obrázek níže, který ukazuje výsledek provedení skriptu:
Další možnosti procesu hromadného vkládání
FIRE_TRIGGERS – povolení spouštěčů v cílové tabulce během operace hromadného vkládání
Ve výchozím nastavení se během procesu hromadného vkládání nespouštějí spouštěče vložení zadané v cílové tabulce. Přesto je v některých situacích možná budeme chtít povolit.
Řešením je použití možnosti FIRE_TRIGGERS v příkazech hromadného vkládání. Pamatujte však, že to může ovlivnit a snížit výkon operace hromadného vkládání. Je to proto, že spouštěče/spouštěče mohou provádět samostatné operace v databázi.
Nejprve nenastavíme parametr FIRE_TRIGGERS a proces hromadného vložení nespustí spouštěč vložení. Viz níže uvedený skript T-SQL:
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
DROP TABLE IF EXISTS SalesLog
CREATE TABLE SalesLog (OrderIDLog bigint)
GO
CREATE TRIGGER OrderLogIns ON Sales
FOR INSERT
AS
BEGIN
SET NOCOUNT ON
INSERT INTO SalesLog
SELECT OrderId from inserted
end
GO
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
);
SELECT Count(*) FROM SalesLogKdyž se tento skript spustí, nespustí se spouštěč vložení, protože není nastavena možnost FIRE_TRIGGERS.
Nyní do příkazu hromadného vložení přidáme možnost FIRE_TRIGGERS:
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n',
FIRE_TRIGGERS);
GO
SELECT Count(*) as [NumberOfRowsinTriggerTable] FROM SalesLog 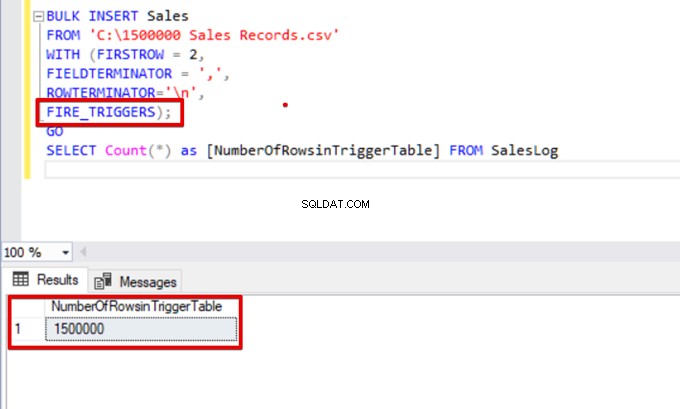
CHECK_CONSTRAINTS – povolení kontrolního omezení během operace hromadného vkládání
Kontrolní omezení nám umožňují vynutit integritu dat v tabulkách SQL Server. Účelem omezení je zkontrolovat vložené, aktualizované nebo vymazané hodnoty podle jejich syntaxe. Například omezení NOT NULL zajišťuje, že hodnota NULL nemůže změnit zadaný sloupec.
Zde se zaměřujeme na omezení a hromadné vkládání interakcí. Ve výchozím nastavení jsou během procesu hromadného vkládání všechna omezení kontroly a cizího klíče ignorována. Ale existují výjimky.
Podle Microsoftu jsou vždy vynucována omezení UNIQUE a PRIMARY KEY. Při importu do sloupce znaků, pro který je definováno omezení NOT NULL, vloží BULK INSERT prázdný řetězec, pokud v textovém souboru není žádná hodnota.“
V následujícím skriptu T-SQL přidáváme kontrolní omezení do sloupce Datum objednávky, které řídí datum objednávky větší než 01.01.2016.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
ALTER TABLE [Sales] ADD CONSTRAINT OrderDate_Check
CHECK(OrderDate >'20160101')
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
);
GO
SELECT COUNT(*) AS [UnChekedData] FROM
Sales WHERE OrderDate <'20160101'V důsledku toho proces hromadného vkládání přeskočí kontrolu omezení. SQL Server však označuje kontrolní omezení jako nedůvěryhodné:
SELECT is_not_trusted ,* FROM sys.check_constraints where name='OrderDate_Check'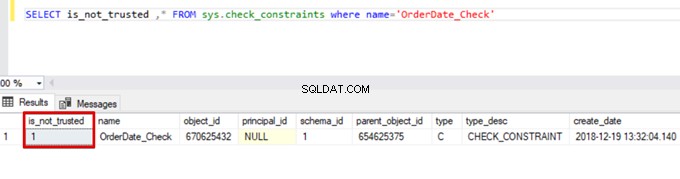
Tato hodnota označuje, že někdo vložil nebo aktualizoval některá data do tohoto sloupce přeskočením kontrolního omezení. Zároveň může tento sloupec obsahovat nekonzistentní údaje týkající se daného omezení.
Pokuste se provést příkaz hromadného vložení s možností CHECK_CONSTRAINTS. Výsledek je jednoduchý:kontrola omezení vrátí chybu kvůli nesprávným datům.
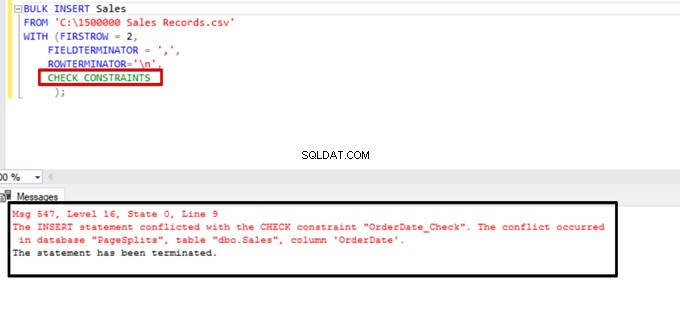
TABLOCK – zvýšení výkonu při hromadném vkládání do jedné cílové tabulky
Primárním účelem zamykacího mechanismu v SQL Server je ochrana a zajištění integrity dat. Podrobnosti o zamykacím mechanismu naleznete v hlavním konceptu článku zamykání serveru SQL Server.
Zaměříme se na podrobnosti zamykání procesu hromadného vkládání.
Pokud spustíte příkaz hromadného vložení bez možnosti TABLELOCK, získá zámek řádků nebo tabulek podle hierarchie zámků. V některých případech však můžeme chtít provést více procesů hromadného vkládání u jedné cílové tabulky a zkrátit tak dobu operace.
Nejprve provedeme dva příkazy hromadného vložení současně a analyzujeme chování zamykacího mechanismu. Otevřete dvě okna dotazu v SQL Server Management Studio a spusťte současně následující příkazy hromadného vložení.
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
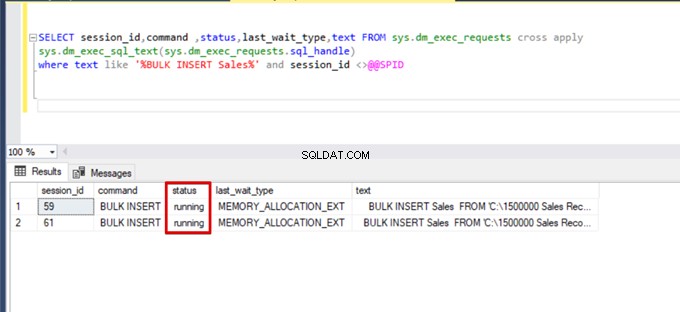
);Proveďte následující dotaz DMV (Dynamic Management View) – pomáhá to sledovat stav procesu hromadného vkládání:
SELECT session_id,command ,status,last_wait_type,text FROM sys.dm_exec_requests cross apply
sys.dm_exec_sql_text(sys.dm_exec_requests.sql_handle)
where text like '%BULK INSERT Sales%' and session_id <>@@SPID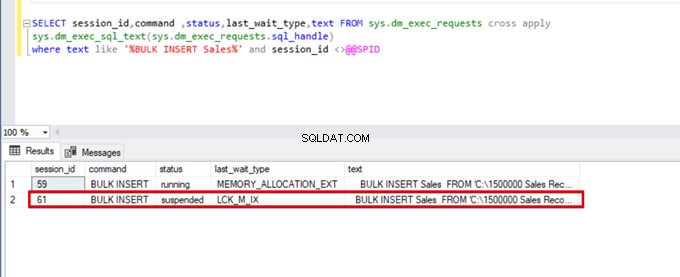
Jak můžete vidět na obrázku výše, relace 61, stav procesu hromadného vkládání je pozastaven kvůli uzamčení. Pokud problém ověříme, relace 59 uzamkne cílovou tabulku hromadného vložení. Potom relace 61 čeká na uvolnění tohoto zámku, aby pokračovala v procesu hromadného vkládání.
Nyní do příkazů hromadného vložení přidáme možnost TABLOCK a spustíme dotazy.
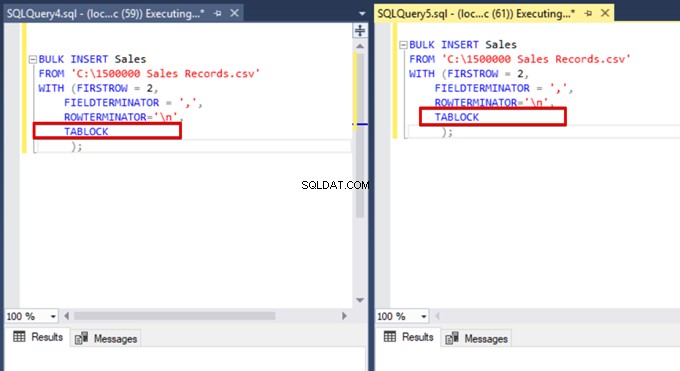
Když znovu spustíme dotaz monitorování DMV, nevidíme žádný pozastavený proces hromadného vkládání, protože SQL Server používá konkrétní typ zámku nazývaný zámek hromadné aktualizace (BU). Tento typ zámku umožňuje zpracování více operací hromadného vkládání u stejné tabulky současně. Tato možnost také zkracuje celkovou dobu procesu hromadného vkládání.
Když během procesu hromadného vkládání provedeme následující dotaz, můžeme sledovat podrobnosti zamykání a typy zámků:
SELECT dm_tran_locks.request_session_id,
dm_tran_locks.resource_database_id,
DB_NAME(dm_tran_locks.resource_database_id) AS dbname,
CASE
WHEN resource_type = 'OBJECT'
THEN OBJECT_NAME(dm_tran_locks.resource_associated_entity_id)
ELSE OBJECT_NAME(partitions.OBJECT_ID)
END AS ObjectName,
partitions.index_id,
indexes.name AS index_name,
dm_tran_locks.resource_type,
dm_tran_locks.resource_description,
dm_tran_locks.resource_associated_entity_id,
dm_tran_locks.request_mode,
dm_tran_locks.request_status
FROM sys.dm_tran_locks
LEFT JOIN sys.partitions ON partitions.hobt_id = dm_tran_locks.resource_associated_entity_id
LEFT JOIN sys.indexes ON indexes.OBJECT_ID = partitions.OBJECT_ID AND indexes.index_id = partitions.index_id
WHERE resource_associated_entity_id > 0
AND resource_database_id = DB_ID()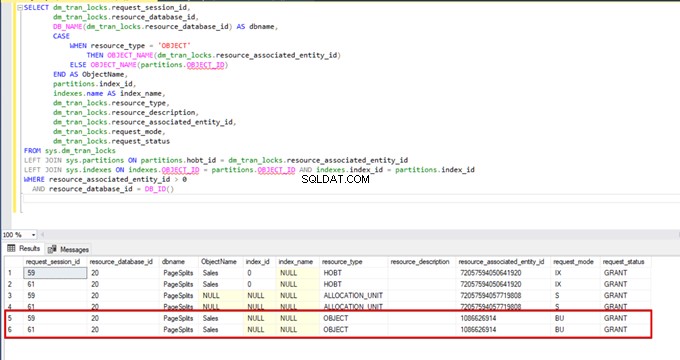
Závěr
Aktuální článek prozkoumal všechny podrobnosti operace hromadného vkládání na SQL Server. Zejména jsme zmínili příkaz BULK INSERT a jeho nastavení a možnosti. Také jsme analyzovali různé scénáře blízké skutečným problémům.
Užitečný nástroj:
dbForge Data Pump – doplněk SSMS pro plnění databází SQL externími zdrojovými daty a migraci dat mezi systémy.