Tento článek pojednává o základech sémantického vyhledávání, včetně kompletního průvodce sémantickým vyhledáváním:začíná od nuly a končí funkcí připravenou k použití.
Kromě toho se čtenáři dozvědí o některých velmi užitečných, ale ne obecně známých funkcích vyhledávání dostupných na serveru SQL Server, jako je sémantické vyhledávání, které si ukážeme na několika základních příkladech.
Tento článek také zdůrazňuje důležitost sémantického vyhledávání pro konkrétní formu analýzy, kterou nelze provést běžným vyhledáváním.
Co je sémantické vyhledávání
Pojďme si nejprve zjistit, co přesně je sémantické vyhledávání a jak se liší od fulltextového vyhledávání.
Definice společnosti Microsoft
Podle dokumentace společnosti Microsoft poskytuje sémantické vyhledávání hluboký vhled do nestrukturovaných dokumentů.
Alternativní definice
Sémantické vyhledávání je speciální vyhledávací technologie nebo funkce používaná k provádění komplexního vyhledávání nebo srovnávací analýzy především v nestrukturovaných datech nebo dokumentech, jako jsou dokumenty MS Word, za předpokladu, že nestrukturovaná data jsou uložena v databázi SQL Server.
Kompatibilita
Sémantické vyhledávání je kompatibilní pouze se serverem SQL Server 2012 a novějšími verzemi.
Pamatujte, že sémantické vyhledávání není kompatibilní s Azure SQL databází nebo cloudovými řešeními datového skladu Azure.
To znamená, že k využití této výkonné funkce musíte pracovat buď s virtuálním počítačem v Azure, nebo s místní instancí SQL Serveru.
Sémantické vyhledávání vs. fulltextové vyhledávání
Podle dokumentace společnosti Microsoft vám fulltextové vyhledávání umožňuje dotazovat se na slova v dokumentu; sémantické vyhledávání vám umožňuje dotazovat se na význam dokumentu.
Sémantické vyhledávání spolu s fulltextovým vyhledáváním představuje jednu společnou funkci nabízenou Microsoft SQL Server a můžete se rozhodnout, zda je nainstalovat během instalace vaší instance SQL Serveru, nebo později přidáním nových funkcí do vaší stávající instance SQL.
Předpoklady
Pojďme si projít předpoklady pro obecné použití sémantického vyhledávání spolu s některými věcmi potřebnými k tomu, abyste se řídili návodem(y) v tomto článku.
Instalováno fulltextové vyhledávání
Je povinné vědět, jak nastavit fulltextové vyhledávání, protože fulltextové vyhledávání a sémantické vyhledávání jsou nabízeny jako společná funkce.
Informace o nastavení fulltextového vyhledávání, které je nezbytným předpokladem pro instalaci sémantického vyhledávání na SQL Server, naleznete v článku Implementace fulltextového vyhledávání v SQL Server 2016 pro začátečníky.
Tento článek předpokládá, že jste na instanci serveru SQL Server nainstalovali Fulltextové vyhledávání.
dbForge Studio pro SQL Server
Použití sémantického vyhledávání (v návodu k tomuto článku) vyžaduje, aby byla nestrukturovaná data uložena v databázi SQL Server, a v tomto článku jsme to provedli pomocí dbForge Studio pro SQL Server místo přímého ukládání nestrukturovaných dat na SQL Server.
SQL Server 2016
V tomto článku používáme SQL Server 2016, ale kroky by měly být téměř stejné pro jakoukoli jinou kompatibilní verzi.
Nastavení sémantického vyhledávání
Chcete-li používat sémantické vyhledávání nebo statistické sémantické vyhledávání, můžete je nainstalovat během instalace fulltextového vyhledávání nebo později přidáním fulltextového vyhledávání a sémantického vyhledávání jako nové funkce.
Kontrola fulltextového vyhledávání
Zkontrolujte prosím stav instalace FullText Search a Semantic Search spuštěním následujícího skriptu proti hlavní databázi:
-- Full-Text Search and Semantic Search status
SELECT SERVERPROPERTY('IsFullTextInstalled') as [Full-Text-Search-and-Semantic-Search-Installed];
GO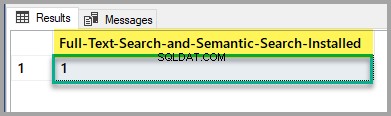
Pokud je výstup 1, pak můžete začít, ale pokud je to 0, přečtěte si výše uvedený článek o instalaci funkce FullText Search a Semantic Search pomocí nastavení SQL Server.
Nainstalujte databázi sémantických jazykových statistik
Nainstalujte databázi sémantických jazykových statistik buď vyhledáním Microsoft® SQL Server® 2016 Sémantic Language Statistics na internetu nebo kliknutím na následující odkaz.
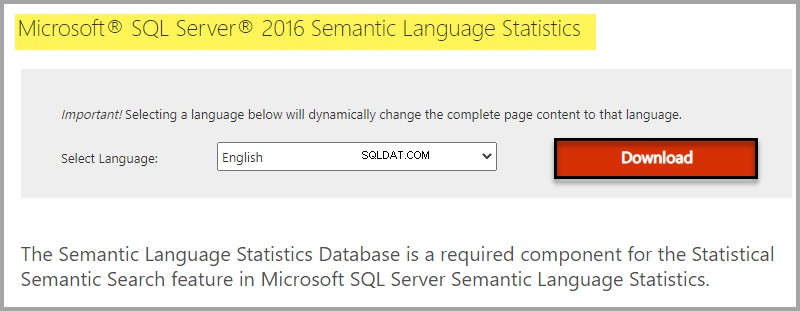
Výběr stahování podle edice Windows:
Nainstalujte jazykovou databázi:
Klikněte na Další pokračovat, pokud souhlasíte s podmínkami licenční smlouvy:
Ponechte výchozí možnosti tak, jak jsou, ale doporučujeme zkontrolovat cenu disku, jak je uvedeno níže:
Přestože soubor zabírá pouze asi 747 MB místa (v době psaní tohoto článku), zkontrolujte cenu disku, abyste se ujistili, že máte k dispozici dostatek místa:
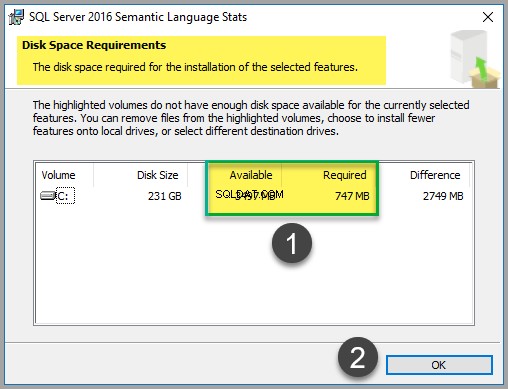
Po dokončení kontroly ceny disku klikněte na OK a poté klikněte na Další .
Budete požádáni o instalaci souboru, klikněte prosím na Instalovat (pokud o to máte zájem):
Klikněte na Dokončit jakmile je instalace úspěšně dokončena, což by mělo vypadat jako snímek obrazovky níže:
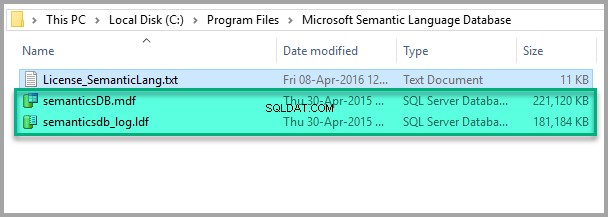
Vyhledejte složku, do které byla standardně nainstalována databáze sémantických jazyků (C:\Program Files\Microsoft databáze sémantických jazyků):
Všechno vypadá dobře, takže zkopírujte soubor Data and Log do složky Data instance SQL, jak je znázorněno níže:
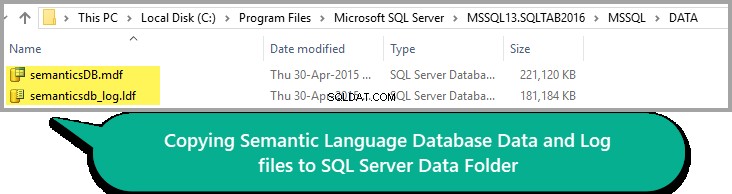
Pamatujte prosím, že cesta ke složce DATA se může lišit v závislosti na verzi vašeho serveru SQL.
Připojit databázi sémantického jazyka k instanci SQL
Klikněte pravým tlačítkem na Databáze uzel pod Průzkumníkem objektů v SSMS (SQL Server Management Studio) a klikněte na Připojit :
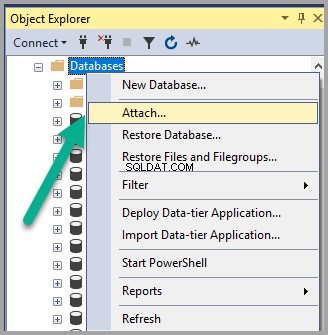
Přidejte Semanticsdb.mdf a klikněte na OK :
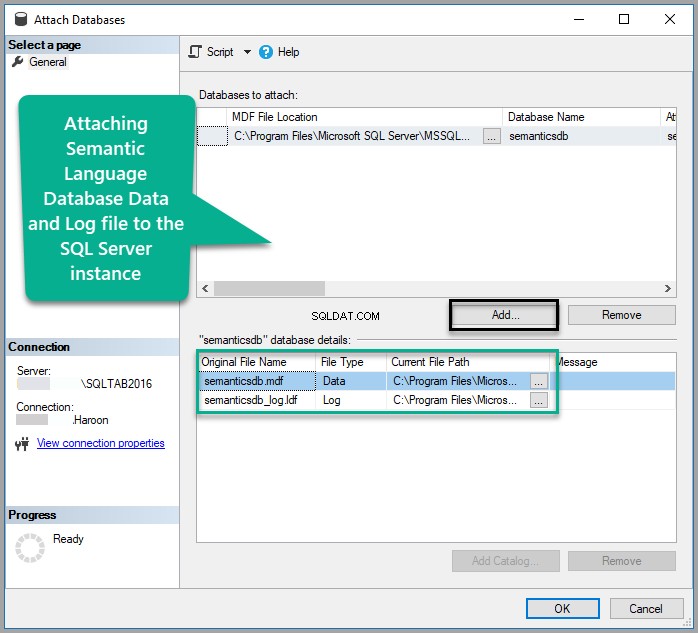
Zobrazit databázi:
Registrace sémantické databáze
Chcete-li zaregistrovat databázi sémantických jazykových statistik, zadejte následující skript proti hlavní databázi:
-- Register Semantic Language Statistics Database
EXEC sp_fulltext_semantic_register_language_statistics_db @dbname = N'semanticsdb';
GOZkontrolujte stav sémantické databáze
Zkontrolujte stav databáze sémantických jazykových statistik spuštěním následujícího skriptu proti hlavní databázi:
-- Check Semantic Language Statistics Database status
SELECT * FROM sys.fulltext_semantic_language_statistics_database;
GOVýstup nesmí být prázdný a bude vypadat následovně:

Pamatujte, že výše uvedené hodnoty se mohou na vašem počítači lišit, což je normální, pokud vidíte řádek, pak to znamená, že databáze sémantických statistik jazyka byla úspěšně nainstalována na vaši instanci SQL.
Použití sémantického vyhledávání
Jakmile je sémantické vyhledávání nastaveno, jsme připraveni jej používat na serveru SQL.
Scénář sémantického vyhledávání
Dokumenty zaměstnanců (ukázky) budeme ukládat ve formátu RTF v databázi SQL Server, abychom je mohli později prohledávat a porovnávat pomocí sémantického vyhledávání.
Nastavte ukázkovou databázi zaměstnanců
Vytvořte ukázkovou databázi s jednou tabulkou spuštěním skriptu T-SQL proti hlavní databázi následovně:
-- (1) Setup sample database
Create DATABASE EmployeesSample;
GO
USE EmployeesSample
-- (2) Create EmployeesForSemanticSearch table
CREATE TABLE [dbo].[EmployeesForSemanticSearch](
[EmpID] [int] NOT NULL,
[DocumentName] [varchar](200) NULL,
[EmpDocument] [varbinary](max) NULL,
[EmpDocumentType] [varchar](200) NULL,
CONSTRAINT [PK_EmployeesForSemanticSearch_EmpID] PRIMARY KEY CLUSTERED
(
[EmpID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
GOZkontrolujte ukázkovou databázi
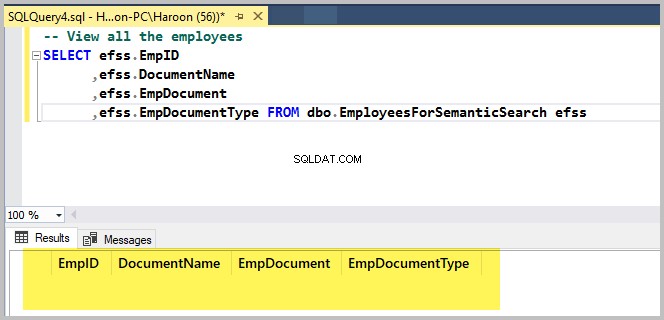
Spusťte následující skript pouze pro kontrolu ukázkové databázové tabulky:
-- View all the employees
SELECT efss.EmpID
,efss.DocumentName
,efss.EmpDocument
,efss.EmpDocumentType FROM dbo.EmployeesForSemanticSearch efssVýstup je následující:
Přidejte první soubor RTF pomocí dbForge Studio pro SQL Server
Do tabulek budeme přidávat binární data, která jsou reprezentována soubory s formátovaným textem, pomocí dbForge Studio pro SQL Server .
Otevřete ukázkovou databázi EmployeesSample v dbForge Studio pro SQL Server.
Klikněte pravým tlačítkem na EmployeesForSemanticSearch tabulky a klikněte na Načíst data:
Přidejte následující data do EmployeesForSemanticSearch tabulky kromě EmpDocument po zajištění, že tabulka není v režimu pouze pro čtení:
EmpID:1
DocumentName:Employee1Document
EmpDocument:(null)
EmpDocumentType:.rtf
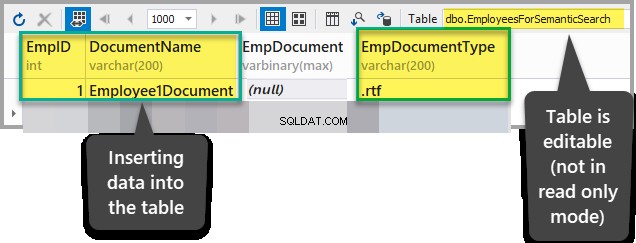
Vložte dokument ve formátu RTF do EmpDocument přidáním následujícího textu do tabulky (kliknutím na elipsy a přidáním dat):
This is a research based article and it is a new research which is in process but this is superb in the field of research.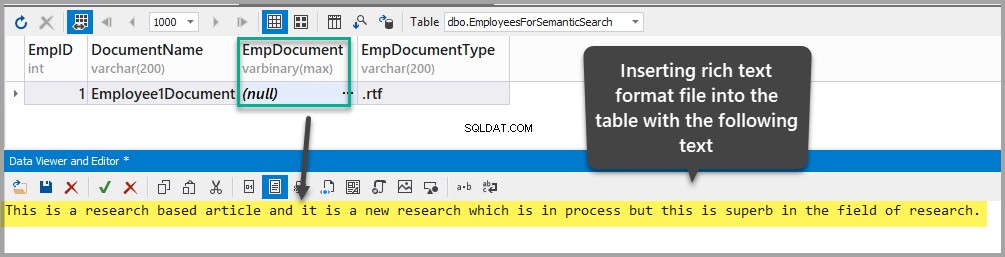
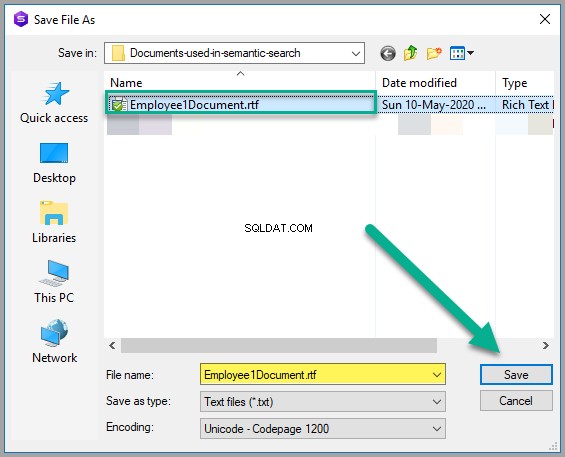
Uložte dokument jako Employee1Document.rtf v jakékoli vhodné složce systému Windows:
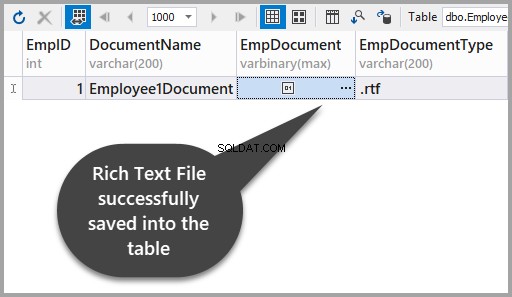
Aplikujte změny, abyste viděli, že jste úspěšně uložili soubor s formátovaným textem do tabulky:
Přidejte druhý soubor RTF pomocí dbForge Studio pro SQL Server
Dále přidejte další soubor s formátovaným textem do EmployeesForSemanticSearch tabulky stejným způsobem jako výše s použitím následujících informací:
EmpID:2
DocumentName:Employee2Document
EmpDocument:(null)
EmpDocumentType:.rtf
Přidejte další soubor RTF s následujícím textem:
This is an article which is about facts and figures with little research in it it talks about fact and figures just facts and figures.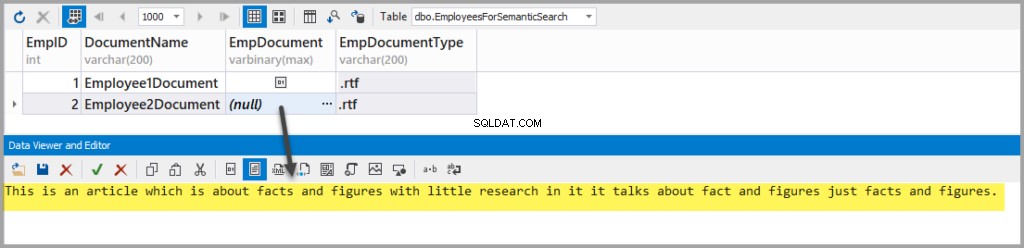
Uložte dokument do stejné složky následovně:
Uložte data obnovením tabulky a následným potvrzením změn, které jste právě provedli, kliknutím na ano:
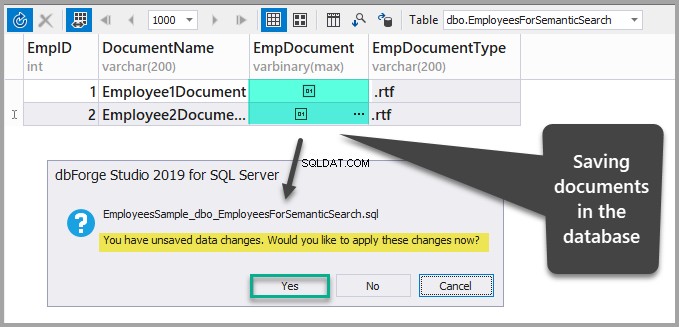
Vytvořte jedinečný index, fulltextový index a sémantický index pomocí průvodce
Zpět v SSMS (SQL Server Management Studio) klikněte pravým tlačítkem na tabulku a klikněte na Fulltextový index a poté klikněte na Definovat fulltextový index… jak je uvedeno níže:
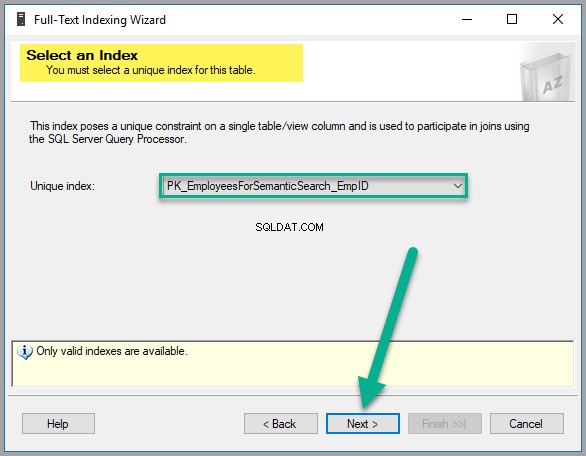
Dále musíte vybrat jedinečný index, který je ve skutečnosti vybrán jako výchozí, protože jsme vytvořili EmpID primární klíč dříve, jak je uvedeno níže, proto klikněte na Další pokračovat:
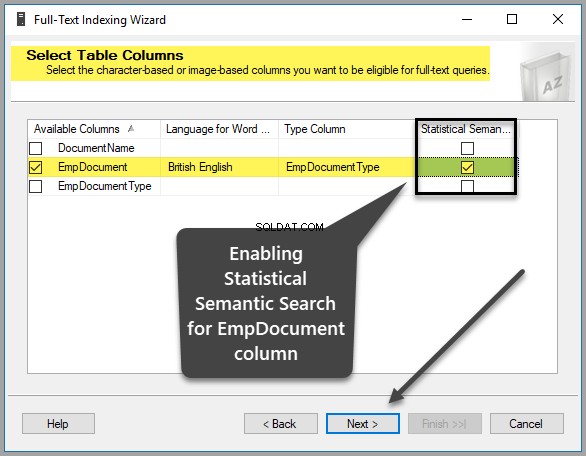
Vyberte prosím EmpDocument z Dostupných sloupců , britská angličtina jako Jazyk pro Word Breaker , EmpDocumentType jako Sloupec typu a zkontrolujte Statistické sémantické vyhledávání pole ve stejném řádku takto:
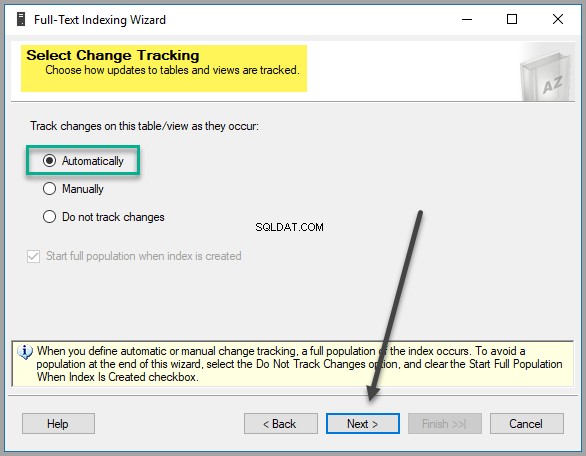
Vyberte možnost sledování změn tak, že ji ponecháte jako výchozí nastavení, pokud nemáte pádný důvod tato nastavení měnit:
Vytvořte nový katalog jako EmployeeCatalog :
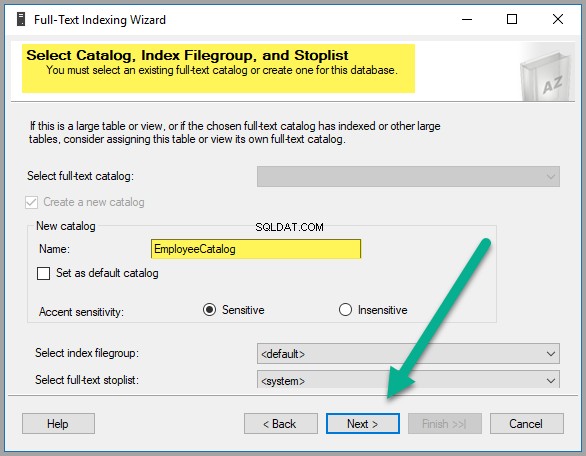
Klikněte na Další znovu:
Nakonec po několika dalších kliknutích (klikněte na Další ), požadovaná tabulka je připravena k dotazování pomocí sémantického vyhledávání:
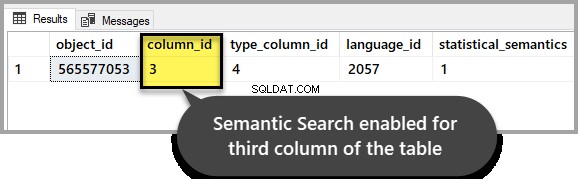
Zkontrolujte, zda je pro tabulku povoleno sémantické vyhledávání
Zkontrolujte prosím, zda sémantické vyhledávání zůstává nedotčené pro tabulku zájmu spuštěním následujícího skriptu proti ukázkové databázi:
-- Check if Semantic Search is enabled for a database, table, and column
SELECT * FROM sys.fulltext_index_columns WHERE object_id = OBJECT_ID('EmployeesForSemanticSearch')
GOVýstup by měl indikovat, že byl povolen pro třetí sloupec, jak jsme jej nastavili na začátku návodu:
Příklad 1:Použití skóre sémantického vyhledávání k nalezení relevantního dokumentu
Nyní můžeme použít sémantické vyhledávání k porovnání dvou dokumentů, abychom našli klíčové slovo, které nás zajímá, a jeho relativní skóre, což nám pomáhá nasměrovat nás na relevantnější dokumenty.
Pokud máme zájem, prohlédneme si dokument, kde je slovo „výzkum ” je zmiňován častěji ve srovnání s jiným dokumentem, pak musíme dávat pozor na skóre pro každý z dokumentů, když spustíme následující skript T-SQL:
-- Using Semantic Search to find the score for the word research in both documents
SELECT TOP (100) DOC_TBL.EmpID, DOC_TBL.EmpDocumentType,KEYP_TBL.keyphrase,
KEYP_TBL.score
FROM
EmployeesForSemanticSearch AS DOC_TBL
INNER JOIN SEMANTICKEYPHRASETABLE
(
EmployeesForSemanticSearch,
EmpDocument
) AS KEYP_TBL
ON DOC_TBL.EmpID = KEYP_TBL.document_key
WHERE KEYP_TBL.keyphrase = 'research'
ORDER BY KEYP_TBL.Score DESC;Výsledek výše uvedeného dotazu je následující:
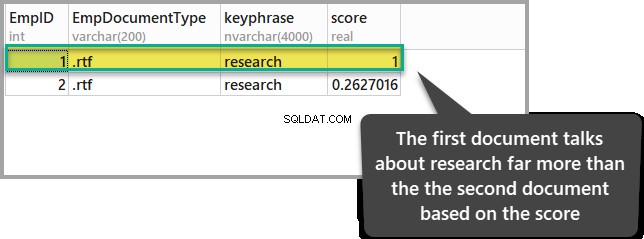
Dokument s nejvyšším skóre ukazuje, že má větší relevanci ve srovnání s jiným dokumentem, pokud jde o náš bod zájmu (výzkum).
Příklad 2:Použití skóre sémantického vyhledávání k nalezení relevantního dokumentu
Dokument, kde dominuje slovo „fakt“ ve srovnání s jakýmkoli jiným dokumentem, můžeme také najít spuštěním následujícího skriptu:
-- Using Semantic Search to find the score for the word fact in both documents
SELECT TOP (100) DOC_TBL.EmpID, DOC_TBL.EmpDocumentType,KEYP_TBL.keyphrase,
KEYP_TBL.score
FROM
EmployeesForSemanticSearch AS DOC_TBL
INNER JOIN SEMANTICKEYPHRASETABLE
(
EmployeesForSemanticSearch,
EmpDocument
) AS KEYP_TBL
ON DOC_TBL.EmpID = KEYP_TBL.document_key
WHERE KEYP_TBL.keyphrase = 'fact'
ORDER BY KEYP_TBL.Score DESC;Výsledky jsou následující:
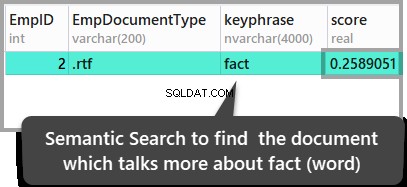
Výše uvedené výsledky vedou k závěru, že druhý uložený dokument je jediný dokument, který obsahuje slovo fakt je zmíněno, ale pokud chcete tyto výsledky zkontrolovat, otevřete uložené dokumenty a podívejte se na ně.
Gratulujeme! Úspěšně jste se naučili nejen nastavit sémantické vyhledávání na SQL Server, ale také jste získali praktické zkušenosti s používáním sémantického vyhledávání.
Co dělat
Nyní, když můžete nastavit a napsat několik základních dotazů sémantického vyhledávání, vyzkoušejte následující, abyste své dovednosti dále zlepšili:
- Zkuste přidat další dokument, který vypráví o výzkumu a poté spusťte skript v prvním příkladu, abyste zjistili, který dokument je nejrelevantnější, porovnáním jejich skóre.
- S ohledem na tento článek přidejte další dokument se slovem fakt je několikrát zmíněn a poté spusťte T-SQL v příkladu 2 tohoto článku, abyste zjistili, zda výsledky zůstanou stejné nebo se změní.
- Zkuste použít sémantické vyhledávání přidáním dalších dokumentů a více textu do stávajících i nových dokumentů a poté vyhledáním dokumentů, které odpovídají vašim slovům zájmu.
- Prozkoumejte dále příklady, abyste sami zjistili, zda sémantické vyhledávání nerozlišuje velká a malá písmena (Tip:Příklady můžete mírně upravit).