V tomto článku budeme hovořit o SQL Server Checkpoints.
Pro zvýšení výkonu SQL Server aplikuje úpravy databázových stránek v paměti. Tato paměť se často nazývá mezipaměť vyrovnávací paměti nebo oblast vyrovnávací paměti. SQL Server nevyprázdní tyto stránky na disk po každé změně. Místo toho databázový stroj čas od času provádí operaci kontrolního bodu u každé databáze. CHECKPOINT operace zapíše nečisté stránky (aktuální stránky upravené v paměti) a také zapíše podrobnosti o transakčním protokolu.
SQL Server podporuje čtyři typy kontrolních bodů:
1. Automaticky – Tento typ kontrolních bodů se vyskytuje za scénou a závisí na konfiguraci serveru intervalu obnovy. Hodnota se měří v minutách a výchozí hodnota je 1 minuta (nelze nastavit nižší). Kontrolní bod bude dokončen v době, která minimalizuje dopad na výkon.
EXEC sp_configure 'recovery interval', 'seconds'
V rámci modelu obnovy SIMPLE se také spustí automatický kontrolní bod, když je protokol transakcí ze 70 % plný.
2. Nepřímé — Tento typ kontrolních bodů se také vyskytuje v zákulisí podle uživatelem zadaného nastavení doby obnovy databáze. Počínaje SQL Server 2016 CTP2 je výchozí hodnota pro tento typ kontrolního bodu 1 minuta. To znamená, že databáze bude používat nepřímé kontrolní body. Pro starší verze SQL Serveru je výchozí hodnota 0. To znamená, že databáze bude používat automatické kontrolní body, jejichž frekvence závisí na nastavení intervalu obnovy instance SQL Server. Společnost Microsoft doporučuje pro většinu systémů 1 minutu.
ALTER DATABASE … SET TARGET_RECOVERY_TIME =
target_recovery_time { SECONDS | MINUTES }
Při nastavování zvažte možnosti základního I/O subsystému. U rychlejších I/O subsystémů (např. SSD) by mohlo mít smysl nastavit toto nižší. Buďte opatrní, toto nastavení přetrvává i během zálohování a obnovy, takže obnovení na pomalejší hardware může způsobit problémy s výkonem v důsledku příliš velkého zatížení I/O.
3. Ruční — Vyskytuje se při provádění příkazu T-SQL CHECKPOINT.
CHECKPOINT [ checkpoint_duration ]
checkpoint_duration je celé číslo používané k definování doby, za kterou by měl být kontrolní bod dokončen. Tento parametr také určuje, kolik zdrojů je přiřazeno operaci kontrolního bodu. Pokud parametr není zadán, kontrolní bod se dokončí v době, která minimalizuje dopad na výkon.
4. Interní — Některé operace SQL Server vydávají tento typ kontrolních bodů, aby zajistily, že obrazy disku odpovídají aktuálnímu stavu protokolu transakcí. Toto jsou kontrolní body, které se provádějí, když dojde k určité operaci:
- Je přidán nebo odebrán datový soubor
- Dojde k vypnutí databáze (z jakéhokoli důvodu)
- Vytvoří se záloha nebo snímek databáze
- Je spuštěn příkaz DBCC, který vytvoří skrytý snímek databáze (nebo např. DBCC_CHECKDB, DBCC_CHECKTABLE).
Proč jsou kontrolní body užitečné?
Kontrolní body zkracují dobu zotavení po havárii. K tomu dochází, protože stránky datového souboru nejsou zapisovány na disk současně se záznamy protokolu. V paměti jsou stránky datových souborů, které jsou aktuálnější než stránky datových souborů na disku.
Kontrolní body snižují I/O na disk a zlepšují výkon. Důvodem, proč stránky datového souboru nejsou zapsány na disk v okamžiku potvrzení transakce, je snížení počtu I/O operací. Představte si několik tisíc transakcí UPDATE na jedné datové stránce. Je efektivnější zapsat datovou stránku na disk pouze jednou, během kontrolního bodu, než po každé změně.
Čisté a špinavé stránky
Společná vyrovnávací paměť udržuje v paměti určitý počet datových stránek. Existují dva typy datových stránek:čisté a špinavé . Čistá stránka je stránka, která nebyla změněna od posledního čtení z disku nebo zápisu na disk. Špinavá stránka je stránka, která byla změněna a změny nebyly zapsány na disk. Kontrolní body odkazují na „špinavé stránky“.
Informace o stránce lze zobrazit pomocí sys.dm_os_buffer_descriptors . Podívejme se, co tato funkce vrátí:
SELECT * FROM sys.dm_os_buffer_descriptors dobd; GO
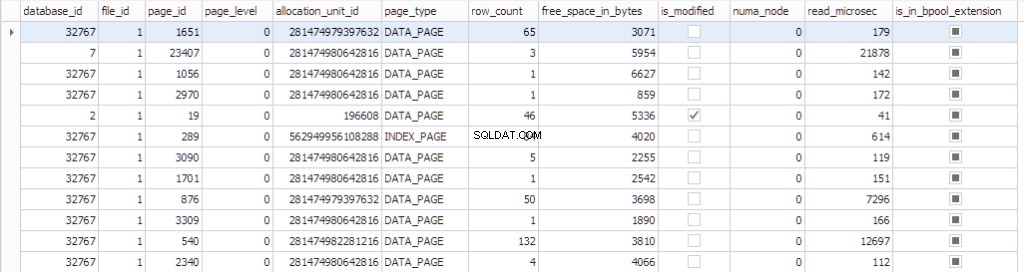
Každá stránka má přidruženou ovládací strukturu, která sleduje stav stránky:
- Databáze, která má id datdabase_id 32767 je databáze zdrojů pouze pro čtení, která obsahuje všechny systémové objekty.
- id_souboru , page_id , allocation_unit_id tato stránka patří.
- O jaký druh stránky se jedná:datová stránka nebo stránka indexu.
- Počet řádků na stránce.
- Volné místo na stránce
- Zda je stránka špinavá nebo ne
- Číselný_uzel, ke kterému patří konkrétní stránka
- Několik informací o naposledy použitém algoritmu
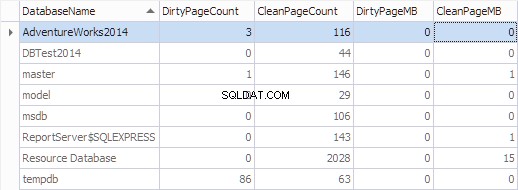
Shromážděme tyto informace podle databáze pomocí následujícího kódu:
SELECT
*,
[DirtyPageCount] * 8 / 1024 AS [DirtyPageMB],
[CleanPageCount] * 8 / 1024 AS [CleanPageMB]
FROM (SELECT
(CASE
WHEN ([database_id] = 32767) THEN N'Resource Database'
ELSE DB_NAME([database_id])
END) AS [DatabaseName],
SUM(CASE
WHEN ([is_modified] = 1) THEN 1
ELSE 0
END) AS [DirtyPageCount],
SUM(CASE
WHEN ([is_modified] = 1) THEN 0
ELSE 1
END) AS [CleanPageCount]
FROM sys.dm_os_buffer_descriptors
GROUP BY [database_id]) AS [buffers]
ORDER BY [DatabaseName]
GO
Mechanismus kontrolních bodů
Když nastane kontrolní bod, zapíše všechny špinavé stránky na disk. Stránky jsou označeny jako špinavé, jakmile mají nějaké změny. Nezáleží na tom, zda je transakce, která provedla změnu, v okamžiku kontrolního bodu potvrzena nebo zrušena. Po zapsání stránek na disk se „špinavý“ bit vymaže. Když dojde ke kontrolnímu bodu, proběhnou následující akce:
- Nový záznam protokolu označuje začátek kontrolního bodu
- Další záznamy protokolu se zobrazí s informacemi o kontrolním bodu (jako je stav protokolu transakcí v době zahájení kontrolního bodu)
- Všechny špinavé stránky se zapisují na disk
- Označte LSN kontrolního bodu na spouštěcí stránce databáze (v dbi_checkptLSN), je to kritické pro zotavení z havárie
- Pokud je použit model obnovení SIMPLE, zkuste vymazat protokol
- Konečný záznam protokolu ukazuje, že kontrolní bod je dokončen
Je možné, aby se kontrolní body více databází vyskytovaly paralelně. SQL Server 2000 byl omezen na jeden kontrolní bod najednou. Když správce vyrovnávací paměti zapisuje stránku, hledá sousední špinavé stránky, které lze zahrnout do jediné operace shromažďování a zápisu. Fond vyrovnávací paměti se také pokusí zajistit, aby nepřetěžoval I/O subsystém. Sleduje, jak dlouho trvá dokončení I/O. Pokud latence zápisu během kontrolního bodu překročí 20 ms, sám se zkrátí. Během vypínání se práh škrcení zvýší na 100 ms. Podrobnější vysvětlení naleznete zde. K nastavení rychlosti I/O kontrolního bodu na XX MB/s můžete použít nezdokumentovanou možnost spuštění „-kXX“.
Když je stránka datového souboru zapsána na disk kontrolním bodem, protokolování předem zaručuje, že všechny záznamy protokolu ovlivňující tuto stránku musí být zapsány nejprve do protokolu transakcí na disku. Všechny záznamy protokolu až do posledního záznamu, který ovlivnil stránku, jsou vypsány bez ohledu na to, které transakce jsou součástí. Záznamy protokolu se zapisují třemi způsoby:
- Když se jakákoli transakce potvrdí nebo přeruší
- Při zápisu stránky datového souboru na disk
- Když blok protokolu dosáhne maximální velikosti 60 kB a bude násilně ukončen
Záznam protokolu kontrolního bodu
Kontrolní body zapisují více záznamů protokolu do protokolu transakcí:
- LOP_BEGIN_CKPT — znamená, že kontrolní bod začal
- LOP_XACT_CKPT s kontextem NULL (pouze v případě, že v době zahájení kontrolního bodu existují nepotvrzené transakce) — obsahuje počet nepotvrzených transakcí. Obsahuje také seznam LSN záznamů protokolu LOP_BEGIN_XACT o nepotvrzených transakcích.
- LOP_BEGIN_CKPT s kontextem LOP_BOOT_PAGE_CKPT (pouze SQL Server 2012) – znamená, že spouštěcí stránka byla aktualizována.
- LOP_END_CKPT — znamená konec kontrolního bodu.
Monitorování kontrolních bodů
Může být užitečné korelovat kontrolní body vyskytující se se špičkami v I/O, aby bylo možné provést změny ve specifické databázi (pro I/O subsystém), aby se zmírnila I/O špička, pokud přetíží I/O subsystém. Například provádění častějších ručních kontrolních bodů nebo konfigurace nižšího intervalu obnovy na SQL Server 2012 s nepřímými kontrolními body. To vytvoří konstantnější I/O zátěž bez vysokých špiček, které přetěžují I/O subsystém. Hlavní příčinou však může být více I/O prováděných kvůli nějaké změně, takže neakceptujte náhlé zvýšení aktivity kontrolního bodu, aniž byste zjistili, proč k němu došlo.
Počítadlo Buffer Manager/Kontrolní bod stránek/s není specifické pro databázi, takže identifikace, o kterou databázi se jedná, vyžaduje příznaky trasování nebo rozšířené události.
Příznak trasování 3502 zapisuje zprávy do protokolu chyb o tom, pro který kontrolní bod databáze se vyskytuje.
Příznak trasování 3504 zapíše podrobnější informace o počtu vypsaných stránek a průměrné latenci zápisu.
Tyto trasovací příznaky lze bezpečně používat při výrobě omezeného množství vápna. Jediné, co dělají, je tisk zpráv v protokolu chyb.
Pokud chcete použít rozšířené události, můžete použít dvě události:checkpoint_begin a checkpoint_end.
Shrnutí
V tomto článku jsme hovořili o kontrolních bodech na serveru SQL Server – hlavním mechanismu pro zápis stránek datových souborů na disk poté, co byly změněny.