Používáte poddotazy SQL nebo se jim vyhýbáte?
Řekněme, že hlavní kreditní a inkasní úředník vás požádá, abyste uvedli jména lidí, jejich nezaplacené zůstatky za měsíc a aktuální průběžný zůstatek a chce, abyste toto pole dat importovali do Excelu. Účelem je analyzovat data a přijít s nabídkou, která zjednoduší platby a zmírní dopady pandemie COVID19.
Rozhodli jste se použít dotaz a vnořený poddotaz nebo spojení? Jaké rozhodnutí učiníte?
Poddotazy SQL – co to jsou?
Než se pustíme do hlubokého ponoru do syntaxe, dopadu na výkon a upozornění, proč nejprve nedefinovat poddotaz?
Zjednodušeně řečeno, poddotaz je dotaz v dotazu. Zatímco dotaz, který ztělesňuje poddotaz, je vnější dotaz, poddotaz označujeme jako vnitřní dotaz nebo vnitřní výběr. A závorky uzavírají poddotaz podobný struktuře níže:
SELECT
col1
,col2
,(subquery) as col3
FROM table1
[JOIN table2 ON table1.col1 = table2.col2]
WHERE col1 <operator> (subquery)V tomto příspěvku se podíváme na následující body:
- Syntaxe poddotazu SQL závisí na různých typech poddotazů a operátorech.
- Kdy a v jakých typech příkazů lze použít dílčí dotaz.
- Důsledky na výkon vs. JOIN .
- Obvyklá upozornění při používání poddotazů SQL.
Jak je zvykem, uvádíme příklady a ilustrace pro lepší porozumění. Ale mějte na paměti, že hlavní zaměření tohoto příspěvku je na dílčí dotazy na SQL Server.
Nyní začněme.
Vytvářejte poddotazy SQL, které jsou samostatné nebo korelované
Za prvé, poddotazy jsou kategorizovány na základě jejich závislosti na vnějším dotazu.
Dovolte mi popsat, co je samostatný dílčí dotaz.
Samostatné poddotazy (nebo někdy označované jako nekorelované nebo jednoduché poddotazy) jsou nezávislé na tabulkách ve vnějším dotazu. Dovolte mi to ilustrovat:
-- Get sales orders of customers from Southwest United States
-- (TerritoryID = 4)
USE [AdventureWorks]
GO
SELECT CustomerID, SalesOrderID
FROM Sales.SalesOrderHeader
WHERE CustomerID IN (SELECT [CustomerID]
FROM [AdventureWorks].[Sales].[Customer]
WHERE TerritoryID = 4)Jak je ukázáno ve výše uvedeném kódu, poddotaz (uzavřený níže v závorkách) nemá žádné odkazy na žádný sloupec ve vnějším dotazu. Navíc můžete poddotaz zvýraznit v SQL Server Management Studio a spustit jej, aniž by došlo k chybám za běhu.
Což zase vede ke snadnějšímu ladění samostatných poddotazů.
Další věcí, kterou je třeba zvážit, jsou korelované poddotazy. Ve srovnání s jeho samostatným protějškem má tento alespoň jeden sloupec odkazovaný z vnějšího dotazu. Pro upřesnění uvedu příklad:
USE [AdventureWorks]
GO
SELECT DISTINCT a.LastName, a.FirstName, b.BusinessEntityID
FROM Person.Person AS p
JOIN HumanResources.Employee AS e ON p.BusinessEntityID = e.BusinessEntityID
WHERE 1262000.00 IN
(SELECT [SalesQuota]
FROM Sales.SalesPersonQuotaHistory spq
WHERE p.BusinessEntityID = spq.BusinessEntityID)Byli jste dostatečně pozorní, abyste si všimli odkazu na BusinessEntityID od osoby stůl? Výborně!
Jakmile je sloupec z vnějšího dotazu odkazován v poddotazu, stane se korelovaným poddotazem. Ještě jeden bod ke zvážení:pokud zvýrazníte dílčí dotaz a provedete jej, dojde k chybě.
A ano, máte naprostou pravdu:díky tomu je ladění korelovaných poddotazů mnohem těžší.
Chcete-li umožnit ladění, postupujte takto:
- izolujte dílčí dotaz.
- nahraďte odkaz na vnější dotaz konstantní hodnotou.
Po izolaci poddotazu pro ladění bude vypadat takto:
SELECT [SalesQuota]
FROM Sales.SalesPersonQuotaHistory spq
WHERE spq.BusinessEntityID = <constant value>Nyní se podívejme trochu hlouběji na výstup dílčích dotazů.
Vytvářejte poddotazy SQL se 3 možnými vrácenými hodnotami
Nejprve se zamysleme nad tím, jaké vrácené hodnoty můžeme očekávat od poddotazů SQL.
Ve skutečnosti existují 3 možné výsledky:
- Jedna hodnota
- Více hodnot
- Celé stoly
Jedna hodnota
Začněme výstupem s jednou hodnotou. Tento typ dílčího dotazu se může objevit kdekoli ve vnějším dotazu, kde se očekává výraz, například WHERE doložka.
-- Output a single value which is the maximum or last TransactionID
USE [AdventureWorks]
GO
SELECT TransactionID, ProductID, TransactionDate, Quantity
FROM Production.TransactionHistory
WHERE TransactionID = (SELECT MAX(t.TransactionID)
FROM Production.TransactionHistory t)Když použijete MAX () funkce, získáte jednu hodnotu. Přesně to se stalo našemu dílčímu dotazu výše. Použití rovného (= ) operátor říká serveru SQL Server, že očekáváte jedinou hodnotu. Další věc:pokud poddotaz vrátí více hodnot pomocí rovná se (= ), zobrazí se chyba podobný tomu níže:
Msg 512, Level 16, State 1, Line 20
Subquery returned more than 1 value. This is not permitted when the subquery follows =, !=, <, <= , >, >= or when the subquery is used as an expression.Více hodnot
Dále prozkoumáme vícehodnotový výstup. Tento druh poddotazu vrací seznam hodnot s jedním sloupcem. Kromě toho operátoři jako IN a NENÍ V bude očekávat jednu nebo více hodnot.
-- Output multiple values which is a list of customers with lastnames that --- start with 'I'
USE [AdventureWorks]
GO
SELECT [SalesOrderID], [OrderDate], [ShipDate], [CustomerID]
FROM Sales.SalesOrderHeader
WHERE [CustomerID] IN (SELECT c.[CustomerID] FROM Sales.Customer c
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
WHERE p.lastname LIKE N'I%' AND p.PersonType='SC')Celé hodnoty tabulky
A v neposlední řadě, proč se neponořit do výstupů celé tabulky.
-- Output a table of values based on sales orders
USE [AdventureWorks]
GO
SELECT [ShipYear],
COUNT(DISTINCT [CustomerID]) AS CustomerCount
FROM (SELECT YEAR([ShipDate]) AS [ShipYear], [CustomerID]
FROM Sales.SalesOrderHeader) AS Shipments
GROUP BY [ShipYear]
ORDER BY [ShipYear]Všimli jste si OD klauzule?
Namísto tabulky použil poddotaz. To se nazývá odvozená tabulka nebo poddotaz tabulky.
A nyní mi dovolte, abych vám představil některá základní pravidla při používání tohoto druhu dotazu:
- Všechny sloupce v poddotazu by měly mít jedinečné názvy. Podobně jako fyzická tabulka by měla mít odvozená tabulka jedinečné názvy sloupců.
- OBJEDNAT PODLE není povoleno, pokud není TOP je také specifikováno. Je to proto, že odvozená tabulka představuje relační tabulku, kde řádky nemají definované pořadí.
V tomto případě má odvozená tabulka výhody fyzické tabulky. Proto v našem příkladu můžeme použít COUNT () v jednom ze sloupců odvozené tabulky.
To je asi vše ohledně výstupů poddotazů. Ale než se dostaneme dále, možná jste si všimli, že logiku příkladu pro více hodnot a další lze také provést pomocí JOIN .
-- Output multiple values which is a list of customers with lastnames that start with 'I'
USE [AdventureWorks]
GO
SELECT o.[SalesOrderID], o.[OrderDate], o.[ShipDate], o.[CustomerID]
FROM Sales.SalesOrderHeader o
INNER JOIN Sales.Customer c on o.CustomerID = c.CustomerID
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
WHERE p.LastName LIKE N'I%' AND p.PersonType = 'SC'Ve skutečnosti bude výstup stejný. Ale který z nich funguje lépe?
Než se do toho pustíme, dovolte mi, abych vám řekl, že jsem tomuto horkému tématu věnoval sekci. Prozkoumáme to s kompletními prováděcími plány a podíváme se na ilustrace.
Tak se mnou chvilku vydrž. Pojďme diskutovat o jiném způsobu umístění dílčích dotazů.
Další příkazy, kde můžete použít poddotazy SQL
Dosud jsme na SELECT používali poddotazy SQL prohlášení. A jde o to, že si můžete užívat výhody dílčích dotazů na INSERT , AKTUALIZOVAT a SMAZAT nebo v jakémkoli příkazu T-SQL, který tvoří výraz.
Pojďme se tedy podívat na řadu dalších příkladů.
Použití poddotazů SQL v příkazech UPDATE
Do AKTUALIZACE lze zahrnout dílčí dotazy prohlášení. Proč se nepodívat na tento příklad?
-- In the products inventory, transfer all products of Vendor 1602 to ----
-- location 6
USE [AdventureWorks]
GO
UPDATE [Production].[ProductInventory]
SET LocationID = 6
WHERE ProductID IN
(SELECT ProductID
FROM Purchasing.ProductVendor
WHERE BusinessEntityID = 1602)
GOViděl jsi, co jsme tam dělali?
Jde o to, že poddotazy můžete umístit do KDE klauzule UPDATE prohlášení.
Protože to v příkladu nemáme, můžete také použít poddotaz pro SET klauzule jako SET sloupec =(poddotaz) . Ale pozor:měl by vypsat jednu hodnotu, protože jinak dojde k chybě.
Co budeme dělat dál?
Použití poddotazů SQL v příkazech INSERT
Jak již víte, záznamy můžete do tabulky vkládat pomocí SELECT prohlášení. Jsem si jistý, že máte představu o tom, jaká bude struktura poddotazu, ale pojďme si to ukázat na příkladu:
-- Impose a salary increase for all employees in DepartmentID 6
-- (Research and Development) by 10 (dollars, I think)
-- effective June 1, 2020
USE [AdventureWorks]
GO
INSERT INTO [HumanResources].[EmployeePayHistory]
([BusinessEntityID]
,[RateChangeDate]
,[Rate]
,[PayFrequency]
,[ModifiedDate])
SELECT
a.BusinessEntityID
,'06/01/2020' as RateChangeDate
,(SELECT MAX(b.Rate) FROM [HumanResources].[EmployeePayHistory] b
WHERE a.BusinessEntityID = b.BusinessEntityID) + 10 as NewRate
,2 as PayFrequency
,getdate() as ModifiedDate
FROM [HumanResources].[EmployeeDepartmentHistory] a
WHERE a.DepartmentID = 6
and StartDate = (SELECT MAX(c.StartDate)
FROM HumanResources.EmployeeDepartmentHistory c
WHERE c.BusinessEntityID = a.BusinessEntityID)Takže, na co se tady díváme?
- První dílčí dotaz načte poslední platovou sazbu zaměstnance před přidáním dalších 10.
- Druhý dílčí dotaz získá poslední záznam o mzdě zaměstnance.
- A konečně výsledek SELECT se vloží do Historie plateb zaměstnance stůl.
V dalších příkazech T-SQL
Kromě VYBRAT , INSERT , AKTUALIZOVAT a SMAZAT , můžete také použít poddotazy SQL v následujícím:
Deklarace proměnných nebo příkazy SET v uložených procedurách a funkcích
Dovolte mi to objasnit pomocí tohoto příkladu:
DECLARE @maxTransId int = (SELECT MAX(TransactionID)
FROM Production.TransactionHistory)Případně to můžete provést následujícím způsobem:
DECLARE @maxTransId int
SET @maxTransId = (SELECT MAX(TransactionID)
FROM Production.TransactionHistory)V podmíněných výrazech
Proč se nepodíváte na tento příklad:
IF EXISTS(SELECT [Name] FROM sys.tables where [Name] = 'MyVendors')
BEGIN
DROP TABLE MyVendors
ENDKromě toho to můžeme udělat takto:
IF (SELECT count(*) FROM MyVendors) > 0
BEGIN
-- insert code here
ENDVytvářejte poddotazy SQL pomocí porovnávacích nebo logických operátorů
Zatím jsme viděli rovné (= ) a operátor IN. K prozkoumání je toho ale mnohem víc.
Použití porovnávací operátory
Když je s poddotazem použit operátor porovnání jako =, <,>, <>,>=nebo <=, měl by poddotaz vrátit jednu hodnotu. Navíc dojde k chybě, pokud poddotaz vrátí více hodnot.
Níže uvedený příklad vygeneruje chybu běhu.
USE [AdventureWorks]
GO
SELECT b.LastName, b.FirstName, b.MiddleName, a.JobTitle, a.BusinessEntityID
FROM HumanResources.Employee a
INNER JOIN Person.Person b on a.BusinessEntityID = b.BusinessEntityID
INNER JOIN HumanResources.EmployeeDepartmentHistory c on a.BusinessEntityID
= c.BusinessEntityID
WHERE c.DepartmentID = 6
and StartDate = (SELECT d.StartDate
FROM HumanResources.EmployeeDepartmentHistory d
WHERE d.BusinessEntityID = a.BusinessEntityID)Víte, co je ve výše uvedeném kódu špatně?
Nejprve kód používá operátor rovná se (=) s poddotazem. Poddotaz navíc vrátí seznam počátečních dat.
Chcete-li problém vyřešit, nastavte poddotaz používat funkci jako MAX () ve sloupci počátečního data, chcete-li vrátit jednu hodnotu.
Použití logických operátorů
Pomocí EXISTS nebo NOT EXISTS
EXISTUJE vrátí PRAVDA pokud poddotaz vrátí nějaké řádky. V opačném případě vrátí hodnotu FALSE . Mezitím pomocí NE EXISTUJE vrátí PRAVDA pokud nejsou žádné řádky a FALSE , jinak.
Zvažte příklad níže:
IF EXISTS(SELECT name FROM sys.tables where name = 'Token')
BEGIN
DROP TABLE Token
ENDNejprve mi dovolte vysvětlit. Výše uvedený kód zruší token tabulky, pokud je nalezen v sys.tables , což znamená, pokud existuje v databázi. Další bod:odkaz na název sloupce je irelevantní.
Proč?
Ukázalo se, že databázovému stroji stačí získat alespoň 1 řádek pomocí EXISTUJE . V našem příkladu, pokud poddotaz vrátí řádek, tabulka bude zrušena. Na druhou stranu, pokud poddotaz nevrátil ani jeden řádek, následující příkazy nebudou provedeny.
Zájem o EXISTUJE jsou jen řádky a žádné sloupce.
Navíc EXISTUJE používá dvouhodnotovou logiku:PRAVDA nebo NEPRAVDA . Neexistují žádné případy, kdy by to vrátilo NULL . Totéž se stane, když negujete EXISTUJE pomocí NE .
Pomocí IN nebo NOT IN
Dílčí dotaz představený pomocí IN nebo NENÍ V vrátí seznam nula nebo více hodnot. A na rozdíl od EXISTUJE , je vyžadován platný sloupec s příslušným typem dat.
Dovolte mi to objasnit dalším příkladem:
-- From the product inventory, extract the products that are available
-- (Quantity >0)
-- except for products from Vendor 1676, and introduce a price cut for the --- whole month of June 2020.
-- Insert the results in product price history.
USE [AdventureWorks]
GO
INSERT INTO [Production].[ProductListPriceHistory]
([ProductID]
,[StartDate]
,[EndDate]
,[ListPrice]
,[ModifiedDate])
SELECT
a.ProductID
,'06/01/2020' as StartDate
,'06/30/2020' as EndDate
,a.ListPrice - 2 as ReducedListPrice
,getdate() as ModifiedDate
FROM [Production].[ProductListPriceHistory] a
WHERE a.StartDate = (SELECT MAX(StartDate)
FROM Production.ProductListPriceHistory
WHERE ProductID = a.ProductID)
AND a.ProductID IN (SELECT ProductID
FROM Production.ProductInventory
WHERE Quantity > 0)
AND a.ProductID NOT IN (SELECT ProductID
FROM [Purchasing].[ProductVendor]
WHERE BusinessEntityID = 1676Jak můžete vidět z výše uvedeného kódu, oba IN a NENÍ V jsou představeni operátoři. A v obou případech budou vráceny řádky. Každý řádek ve vnějším dotazu bude porovnán s výsledkem každého dílčího dotazu, abychom získali produkt, který je k dispozici, a produkt, který nepochází od dodavatele 1676.
Vnoření poddotazů SQL
Poddotazy můžete vnořovat až do 32 úrovní. Tato schopnost nicméně závisí na dostupné paměti serveru a složitosti dalších výrazů v dotazu.
Jaký na to máte názor?
Z mé zkušenosti si nepamatuji vnoření do 4. Málokdy používám 2 nebo 3 úrovně. Ale to jsem jen já a moje požadavky.
Co takhle dobrý příklad, jak to zjistit:
-- List down the names of employees who are also customers.
USE [AdventureWorks]
GO
SELECT
LastName
,FirstName
,MiddleName
FROM Person.Person
WHERE BusinessEntityID IN (SELECT BusinessEntityID
FROM Sales.Customer
WHERE BusinessEntityID IN
(SELECT BusinessEntityID
FROM HumanResources.Employee))Jak můžeme vidět na tomto příkladu, vnoření dosáhlo 2 úrovní.
Jsou poddotazy SQL špatné pro výkon?
V kostce:ano i ne. Jinými slovy, záleží.
A nezapomeňte, je to v kontextu SQL Server.
Pro začátek lze mnoho příkazů T-SQL, které používají poddotazy, alternativně přepsat pomocí JOIN s. A výkon u obou je obvykle stejný. Přesto existují konkrétní případy, kdy je spojení rychlejší. A existují případy, kdy dílčí dotaz funguje rychleji.
Příklad 1
Podívejme se na příklad poddotazu. Před jejich spuštěním stiskněte Control-M nebo povolte Zahrnout skutečný plán provádění z panelu nástrojů SQL Server Management Studio.
USE [AdventureWorks]
GO
SELECT Name
FROM Production.Product
WHERE ListPrice = SELECT ListPrice
FROM Production.Product
WHERE Name = 'Touring End Caps')Alternativně lze výše uvedený dotaz přepsat pomocí spojení, které poskytne stejný výsledek.
USE [AdventureWorks]
GO
SELECT Prd1.Name
FROM Production.Product AS Prd1
INNER JOIN Production.Product AS Prd2 ON (Prd1.ListPrice = Prd2.ListPrice)
WHERE Prd2.Name = 'Touring End Caps'Nakonec je výsledkem pro oba dotazy 200 řádků.
Kromě toho si můžete prohlédnout plán provádění pro oba příkazy.
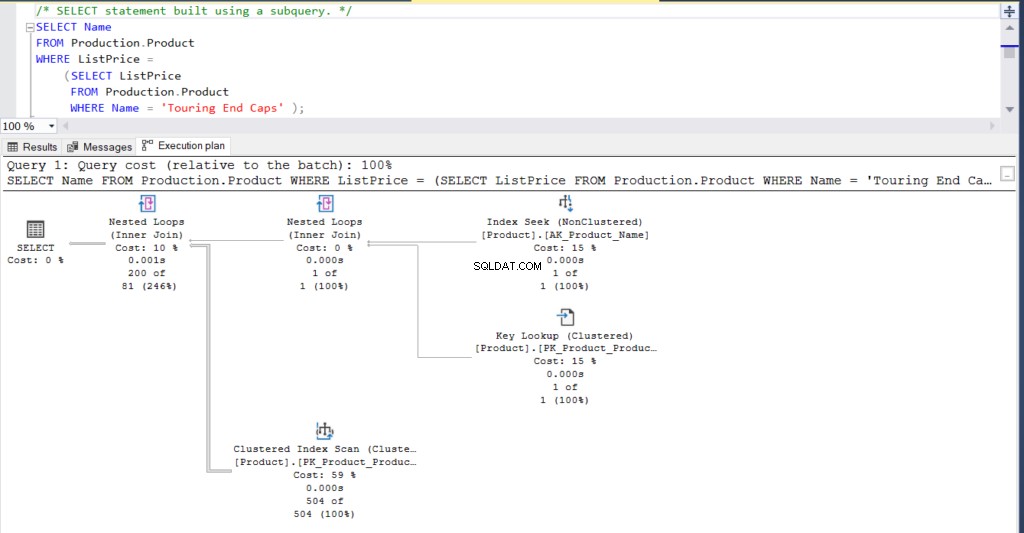
Obrázek 1:Plán provádění pomocí dílčího dotazu
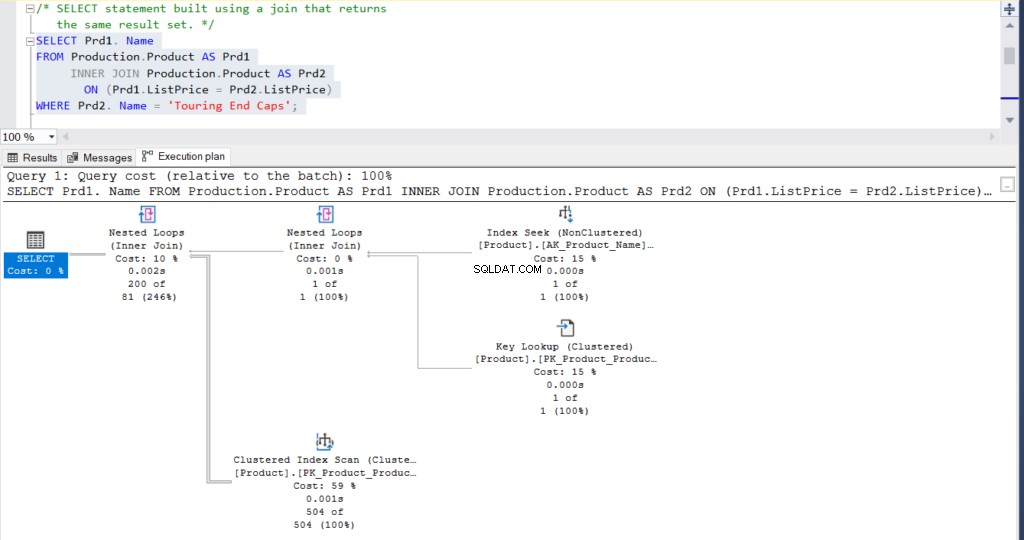
Obrázek 2:Plán realizace pomocí spojení
Co myslíš? Jsou prakticky stejné? Kromě skutečného uplynulého času každého uzlu je vše ostatní v podstatě stejné.
Ale tady je další způsob, jak to porovnat kromě vizuálních rozdílů. Doporučuji použít Porovnat plán zobrazení .
Chcete-li to provést, postupujte takto:
- Klikněte pravým tlačítkem myši na plán provádění příkazu pomocí dílčího dotazu.
- Vyberte Uložit plán provedení jako .
- Pojmenujte soubor subquery-execution-plan.sqlplan .
- Přejděte na plán provádění příkazu pomocí spojení a klikněte na něj pravým tlačítkem.
- Vyberte Porovnat plán představení .
- Vyberte název souboru, který jste uložili do #3.
Nyní se podívejte na toto, kde najdete další informace o Porovnat plán výstav .
Měli byste vidět něco podobného:
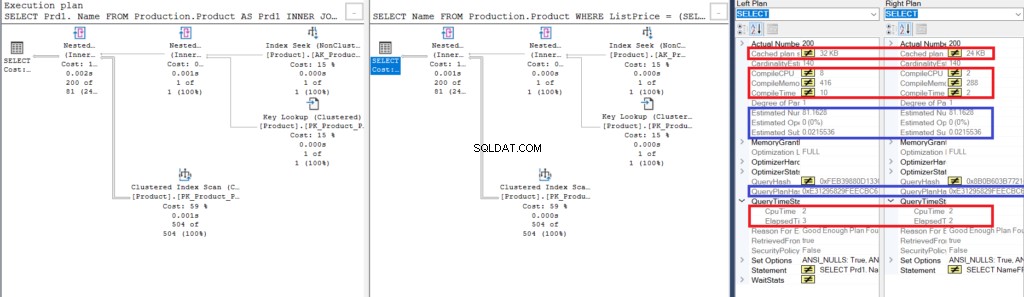
Obrázek 3:Porovnání Showplanu pro použití spojení a použití poddotazu
Všimněte si podobností:
- Odhadované řádky a náklady jsou stejné.
- QueryPlanHash je také stejný, což znamená, že mají podobné prováděcí plány.
Přesto si všimněte rozdílů:
- Velikost plánu mezipaměti je větší při použití spojení než při použití dílčího dotazu
- Kompilace CPU a čas (v ms), včetně paměti v kB, který se používá k analýze, svázání a optimalizaci plánu provádění, je vyšší při použití spojení než při použití dílčího dotazu
- Čas procesoru a uplynulý čas (v ms) k provedení plánu jsou o něco vyšší při použití spojení oproti dílčímu dotazu
V tomto příkladu je dílčí dotaz o tic rychlejší než spojení, i když výsledné řádky jsou stejné.
Příklad 2
V předchozím příkladu jsme použili pouze jednu tabulku. V následujícím příkladu použijeme 3 různé tabulky.
Udělejme to:
-- Subquery example
USE [AdventureWorks]
GO
SELECT [SalesOrderID], [OrderDate], [ShipDate], [CustomerID]
FROM Sales.SalesOrderHeader
WHERE [CustomerID] IN (SELECT c.[CustomerID] FROM Sales.Customer c
INNER JOIN Person.Person p ON c.PersonID =
p.BusinessEntityID
WHERE p.PersonType='SC')-- Join example
USE [AdventureWorks]
GO
SELECT o.[SalesOrderID], o.[OrderDate], o.[ShipDate], o.[CustomerID]
FROM Sales.SalesOrderHeader o
INNER JOIN Sales.Customer c on o.CustomerID = c.CustomerID
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
WHERE p.PersonType = 'SC'Oba dotazy vydávají stejných 3806 řádků.
Dále se podívejme na jejich prováděcí plány:
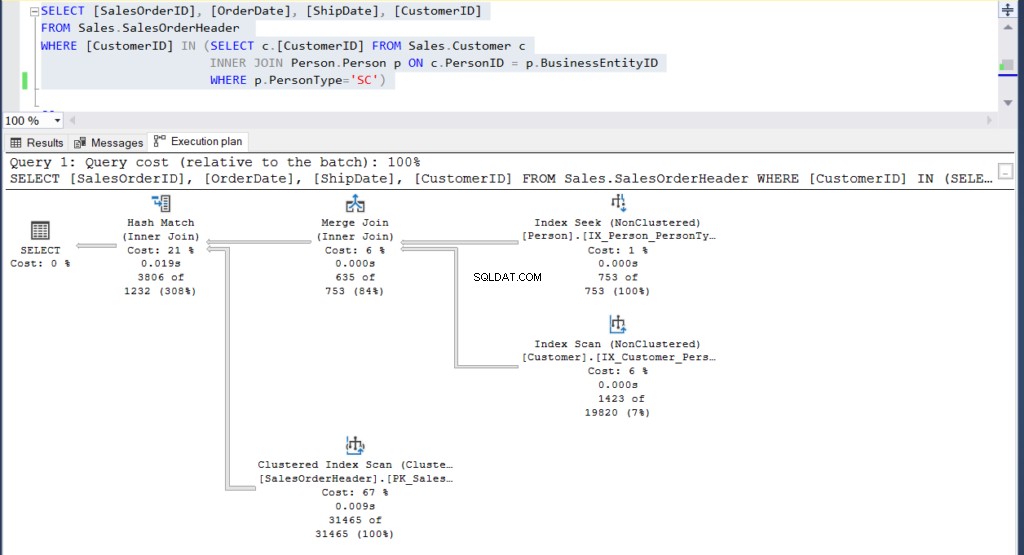
Obrázek 4:Plán provádění pro náš druhý příklad pomocí dílčího dotazu
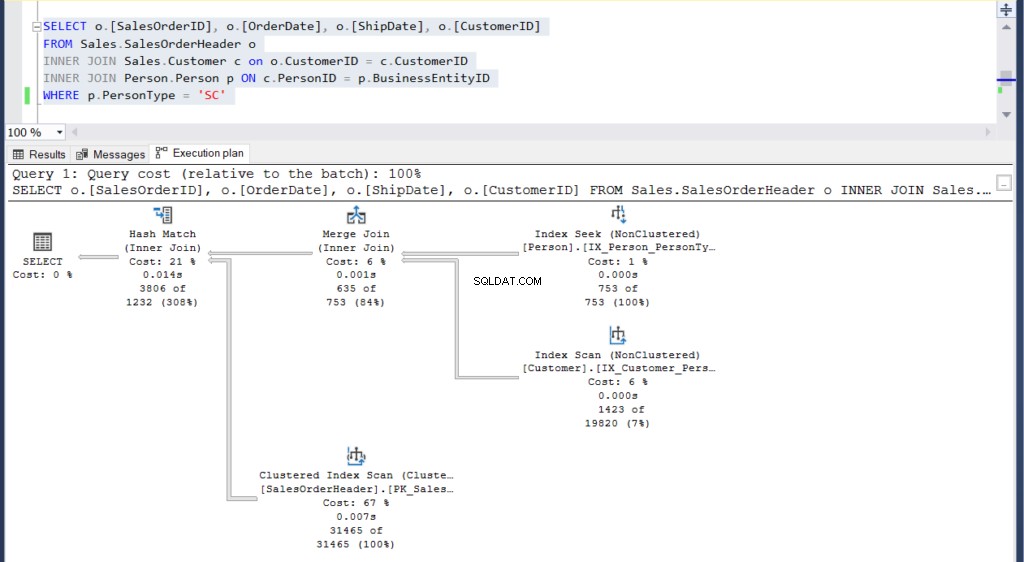
Obrázek 5:Plán provedení pro náš druhý příklad s použitím spojení
Vidíte 2 prováděcí plány a najdete mezi nimi nějaký rozdíl? Na první pohled vypadají stejně.
Ale pečlivější prozkoumání s Porovnat plán zobrazení odhaluje, co je skutečně uvnitř.
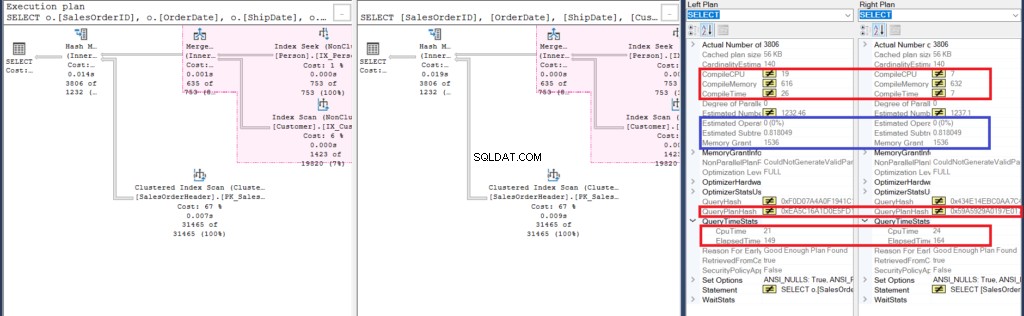
Obrázek 6:Podrobnosti porovnávacího plánu ukázek pro druhý příklad
Začněme analýzou několika podobností:
- Růžové zvýraznění v plánu provádění odhaluje podobné operace pro oba dotazy. Protože vnitřní dotaz používá spojení namísto vnořování poddotazů, je to celkem pochopitelné.
- Odhadované náklady na operátora a podstrom jsou stejné.
Dále se podívejme na rozdíly:
- Za prvé, kompilace trvala déle, když jsme použili spojení. Můžete to zkontrolovat v části Compile CPU a Compile Time. Dotaz s poddotazem však zabral vyšší kompilační paměť v KB.
- Pak se QueryPlanHash obou dotazů liší, což znamená, že mají odlišný plán provádění.
- Uplynulý čas a čas CPU k provedení plánu jsou rychlejší pomocí spojení než pomocí poddotazu.
Poddotaz vs. Join Performance Takeaway
Pravděpodobně budete čelit příliš mnoha dalším problémům souvisejícím s dotazem, které lze vyřešit pomocí spojení nebo poddotazu.
Ale sečteno a podtrženo je, že poddotaz není ve srovnání se spojeními ze své podstaty špatný. A neexistuje žádné obecné pravidlo, že v konkrétní situaci je spojení lepší než dílčí dotaz nebo naopak.
Abyste se ujistili, že máte nejlepší volbu, zkontrolujte prováděcí plány. Účelem je získat přehled o tom, jak SQL Server zpracuje konkrétní dotaz.
Pokud se však rozhodnete použít dílčí dotaz, uvědomte si, že mohou nastat problémy, které prověří vaši dovednost.
Běžná upozornění při používání poddotazů SQL
Existují 2 běžné problémy, které mohou způsobit, že se vaše dotazy budou chovat divoce při použití poddotazů SQL.
Bolest rozlišení názvů sloupců
Tento problém vnáší do vašich dotazů logické chyby a jejich nalezení může být velmi složité. Tento problém může dále objasnit příklad.
Začněme vytvořením tabulky pro demo účely a naplněním dat.
USE [AdventureWorks]
GO
-- Create the table for our demonstration based on Vendors
CREATE TABLE Purchasing.MyVendors
(
BusinessEntity_id int,
AccountNumber nvarchar(15),
Name nvarchar(50)
)
GO
-- Populate some data to our new table
INSERT INTO Purchasing.MyVendors
SELECT BusinessEntityID, AccountNumber, Name
FROM Purchasing.Vendor
WHERE BusinessEntityID IN (SELECT BusinessEntityID
FROM Purchasing.ProductVendor)
AND BusinessEntityID like '14%'
GONyní, když je tabulka nastavena, spustíme pomocí ní několik poddotazů. Než však provedete níže uvedený dotaz, nezapomeňte, že ID dodavatele, která jsme použili z předchozího kódu, začínají na „14“.
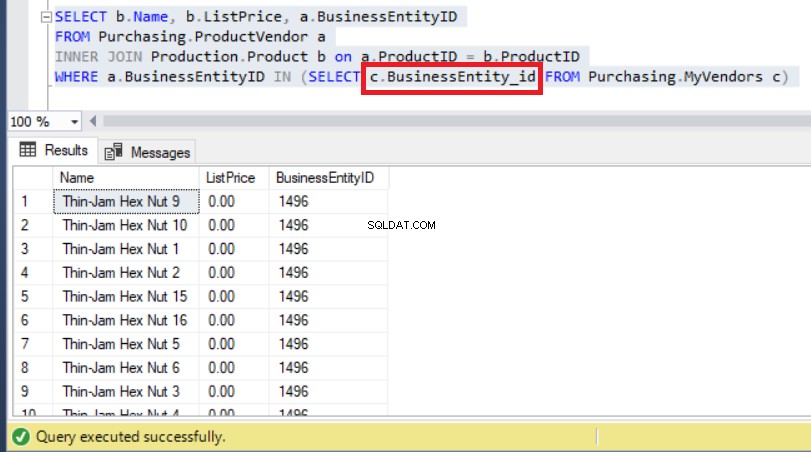
SELECT b.Name, b.ListPrice, a.BusinessEntityID
FROM Purchasing.ProductVendor a
INNER JOIN Production.Product b on a.ProductID = b.ProductID
WHERE a.BusinessEntityID IN (SELECT BusinessEntityID
FROM Purchasing.MyVendors)Výše uvedený kód běží bez chyb, jak můžete vidět níže. Každopádně věnujte pozornost seznamu BusinessEntityID .
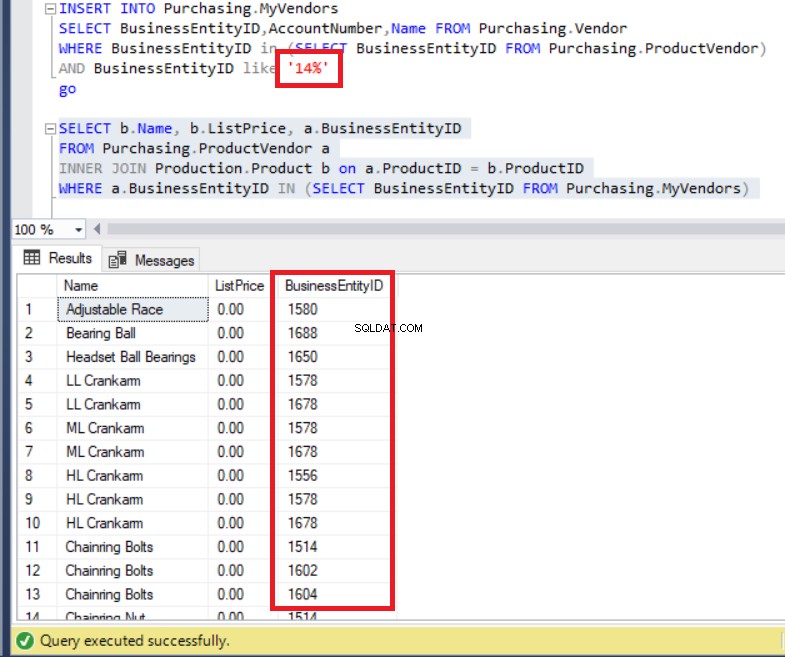
Obrázek 7:BusinessEntityID sady výsledků nejsou konzistentní se záznamy tabulky MyVendors
Nevložili jsme data pomocí BusinessEntityID? začínající na „14“? O co tedy jde? Ve skutečnosti můžeme vidět BusinessEntityIDs které začínají na „15“ a „16“. Kde se to vzalo?
Ve skutečnosti dotaz obsahoval všechna data od ProductVendor tabulka.
V takovém případě si můžete myslet, že tento problém vyřeší alias, takže bude odkazovat na MyVendors tabulka stejně jako ta níže:
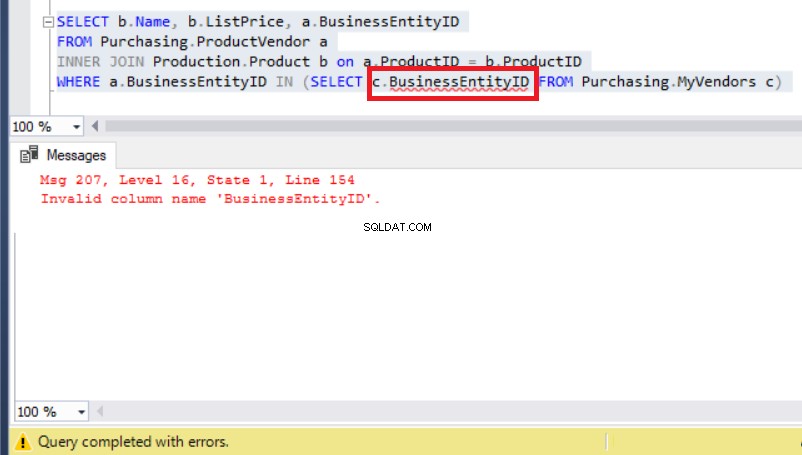
Obrázek 8:Přidání aliasu k BusinessEntityID vede k chybě
Až na to, že teď se skutečný problém objevil kvůli chybě běhu.
Zkontrolujte MyVendors znovu a uvidíte, že místo BusinessEntityID , název sloupce musí být BusinessEntity_id (s podtržítkem).
Použití správného názvu sloupce tedy tento problém konečně vyřeší, jak můžete vidět níže:
Obrázek 9:Změna dílčího dotazu se správným názvem sloupce problém vyřešila
Jak můžete vidět výše, nyní můžeme pozorovat BusinessEntityID počínaje „14“, jak jsme očekávali dříve.
Můžete se ale divit:Proč vůbec SQL Server umožnil úspěšné spuštění dotazu?
Tady je kicker:Rozlišení názvů sloupců bez aliasů funguje v kontextu poddotazu od samotného k vnějšímu dotazu. Proto odkaz na BusinessEntityID uvnitř poddotazu nespustilo chybu, protože bylo nalezeno mimo poddotaz – v ProductVendor tabulka.
Jinými slovy, SQL Server hledá sloupec bez aliasu BusinessEntityID v MyVendors stůl. Protože tam není, podíval se ven a našel ho v ProductVendor stůl. Blázen, že?
Možná byste řekli, že je to chyba v SQL Serveru, ale ve skutečnosti je to záměrné ve standardu SQL a Microsoft se jí řídil.
Dobře, to je jasné, se standardem nemůžeme nic dělat, ale jak se můžeme vyhnout chybě?
- Nejprve přidejte před názvy sloupců název tabulky nebo použijte alias. Jinými slovy, vyhněte se názvům tabulek bez prefixů nebo aliasů.
- Zadruhé mějte konzistentní pojmenování sloupců. Nepoužívejte obě ID_podniku a BusinessEntity_id , například.
To zní dobře? Jo, to vnáší do situace trochu rozumu.
Ale tím to nekončí.
Šílené hodnoty NULL
Jak jsem již zmínil, je toho více. T-SQL používá 3-hodnotovou logiku, protože podporuje NULL . A NULL může nás téměř přivést k šílenství, když používáme poddotazy SQL s NOT IN .
Dovolte mi začít představením tohoto příkladu:
SELECT b.Name, b.ListPrice, a.BusinessEntityID
FROM Purchasing.ProductVendor a
INNER JOIN Production.Product b on a.ProductID = b.ProductID
WHERE a.BusinessEntityID NOT IN (SELECT c.BusinessEntity_id
FROM Purchasing.MyVendors c)Výstup dotazu nás vede k seznamu produktů, které nejsou v MyVendors tabulka., jak je vidět níže:
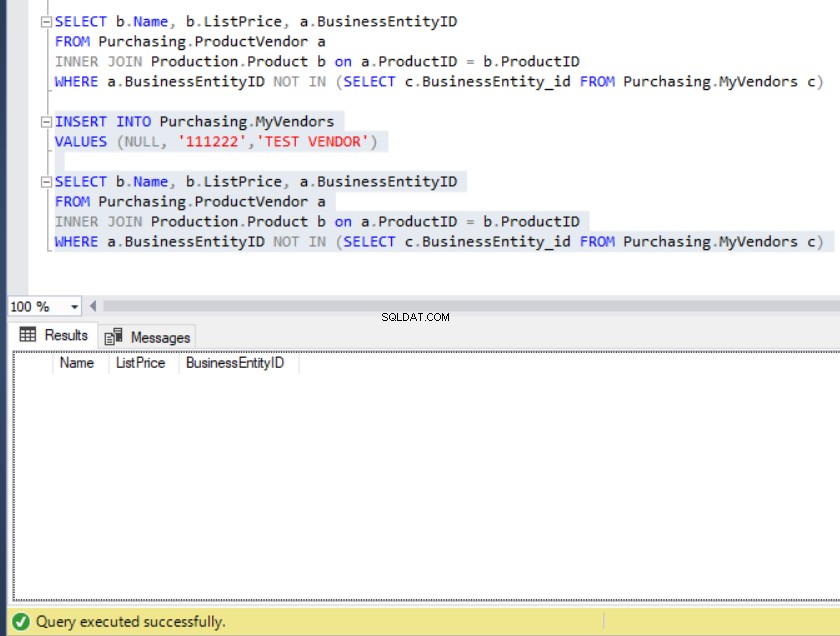
Obrázek 10:Výstup ukázkového dotazu pomocí NOT IN
Nyní předpokládejme, že někdo neúmyslně vložil záznam do MyVendors tabulka s NULL BusinessEntity_id . Co s tím budeme dělat?
Obrázek 11:Po vložení NULL BusinessEntity_id do MyVendors se sada výsledků vyprázdní
Kam zmizela všechna data?
Vidíte, NE operátor negoval IN predikát. Takže NEPRAVDA bude nyní NEPRAVDA . Ale NE NULL je NEZNÁMÝ. To způsobilo, že filtr vyřadil řádky, které jsou NEZNÁMÉ, a to je viník.
Aby se vám to nestalo:
- Buď ve sloupci tabulky zakažte NULL pokud by data takto neměla být.
- Nebo přidejte název_sloupce NENÍ NULL na vaše KDE doložka. V našem případě je poddotaz následující:
SELECT b.Name, b.ListPrice, a.BusinessEntityID
FROM Purchasing.ProductVendor a
INNER JOIN Production.Product b on a.ProductID = b.ProductID
WHERE a.BusinessEntityID NOT IN (SELECT c.BusinessEntity_id
FROM Purchasing.MyVendors c
WHERE c.BusinessEntity_id IS NOT NULL)Takové věci
Hodně jsme mluvili o dílčích dotazech a nastal čas poskytnout hlavní poznatky tohoto příspěvku ve formě souhrnného seznamu:
Dílčí dotaz:
- je dotaz v dotazu.
- je uzavřeno v závorkách.
- může nahradit výraz kdekoli.
- lze použít v SELECT , INSERT , AKTUALIZOVAT , DELETE, nebo jiné příkazy T-SQL.
- mohou být samostatné nebo korelované.
- vydává jednotlivé, vícenásobné nebo tabulkové hodnoty.
- funguje na operátorech porovnání jako =, <>,>, <,>=, <=a logických operátorech jako IN /NENÍ V a EXISTUJE /NEEXISTUJE .
- není špatný nebo zlý. Může mít lepší nebo horší výkon než JOIN s v závislosti na situaci. Dej tedy na mou radu a vždy si prověřuj prováděcí plány.
- může mít nepříjemné chování na NULL s při použití s NOT IN a když sloupec není explicitně identifikován tabulkou nebo aliasem tabulky.
Seznamte se s několika dalšími odkazy pro vaše potěšení ze čtení:
- Discussion of Subqueries from Microsoft.
- IN (Transact-SQL)
- EXISTS (Transact-SQL)
- ALL (Transact-SQL)
- SOME | ANY (Transact-SQL)
- Comparison Operators