Snímek obrazovky č.1 ukazuje několik bodů k rozlišení mezi Merge Join transformation a Lookup transformation .
Ohledně vyhledávání:
Pokud chcete najít řádky odpovídající ve zdroji 2 na základě vstupu zdroje 1 a pokud víte, že pro každý vstupní řádek bude pouze jedna shoda, navrhoval bych použít operaci vyhledávání. Příkladem můžete být vy OrderDetails a chcete najít odpovídající Order Id a Customer Number , pak je lepší volbou Lookup.
Ohledně sloučení spojení:
Pokud chcete provádět spojení, jako je načítání všech adres (domů, práce, jiné) z Address tabulky pro daného zákazníka v Customer tabulky, pak musíte přejít na Merge Join, protože zákazník k nim může mít přiřazenu 1 nebo více adres.
Příklad k porovnání:
Zde je scénář demonstrující výkonnostní rozdíly mezi Merge Join a Lookup . Zde použitá data jsou spojením jedna ku jedné, což je jediný společný scénář, který lze mezi nimi porovnat.
-
Mám tři tabulky s názvem
dbo.ItemPriceInfo,dbo.ItemDiscountInfoadbo.ItemAmount. Vytvořte skripty pro tyto tabulky v sekci SQL skripty. -
Tabulky
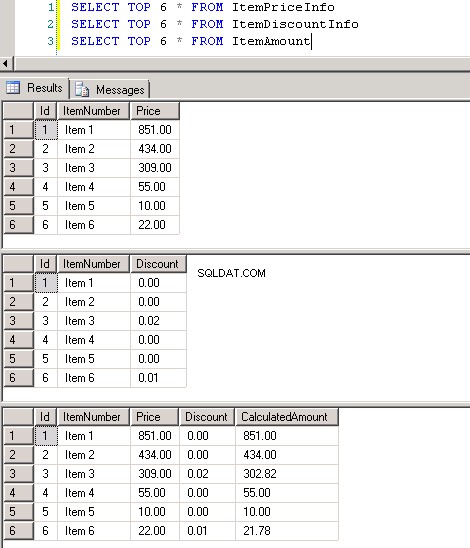
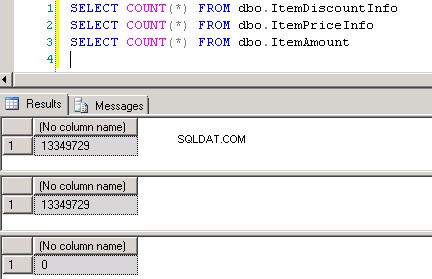
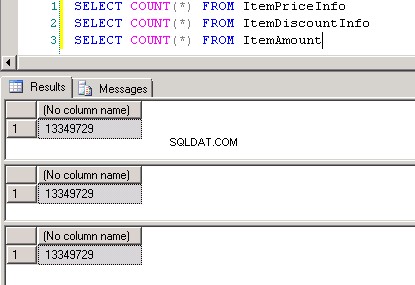
dbo.ItemPriceInfoadbo.ItemDiscountInfooba mají 13 349 729 řádků. Obě tabulky mají jako společný sloupec ItemNumber. ItemPriceInfo obsahuje informace o ceně a ItemDiscountInfo obsahuje informace o slevě. Snímek obrazovky č.2 zobrazuje počet řádků v každé z těchto tabulek. Snímek obrazovky č.3 zobrazuje prvních 6 řádků, aby poskytl představu o datech přítomných v tabulkách. -
Vytvořil jsem dva balíčky SSIS pro porovnání výkonu transformací Merge Join a Lookup. Oba balíčky musí přebírat informace z tabulek
dbo.ItemPriceInfoadbo.ItemDiscountInfo, vypočítejte celkovou částku a uložte ji do tabulkydbo.ItemAmount. -
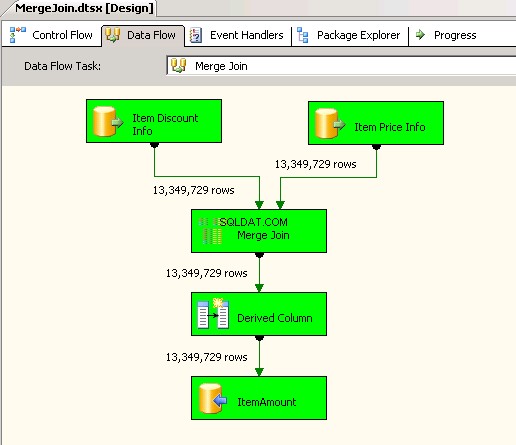
První balíček používal
Merge Jointransformace a uvnitř toho použil INNER JOIN ke spojení dat. Snímky obrazovky #4 a #5 zobrazit ukázkové provedení balíčku a dobu trvání provedení. Trvalo to05minut14sekund719milisekundy ke spuštění balíčku založeného na transformaci Merge Join. -
Druhý balíček používá
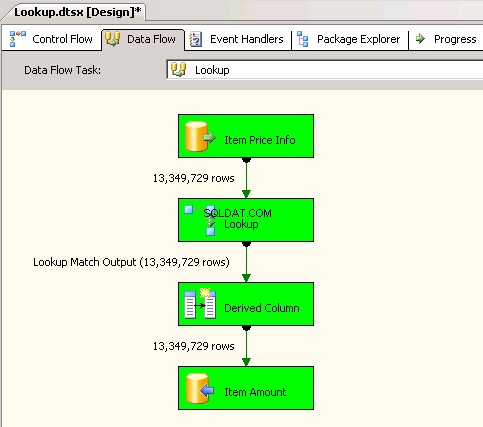
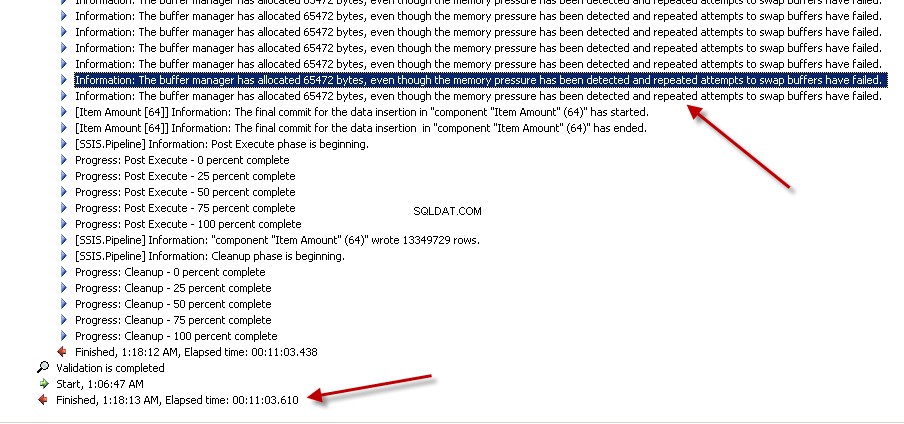
Lookuptransformace pomocí Full cache (což je výchozí nastavení). snímky obrazovky #6 a #7 zobrazit ukázkové provedení balíčku a dobu trvání provedení. Trvalo to11minut03sekund610milisekundy ke spuštění balíčku založeného na transformaci vyhledávání. Můžete se setkat s varovnou zprávou Informace:The buffer manager has allocated nnnnn bytes, even though the memory pressure has been detected and repeated attempts to swap buffers have failed.Zde je odkaz který hovoří o tom, jak vypočítat velikost mezipaměti vyhledávání. Během tohoto spouštění balíčku, i když byla úloha toku dat dokončena rychleji, čištění potrubí zabralo spoustu času. -
Toto není střední transformace vyhledávání je špatná. Jen se to musí používat s rozumem. Používám to docela často ve svých projektech, ale zase se nezabývám 10+ miliony řádků pro vyhledávání každý den. Moje úlohy obvykle zvládají 2 až 3 miliony řádků a na to je výkon opravdu dobrý. Až 10 milionů řádků, oba fungovaly stejně dobře. Většinu času jsem si všiml, že úzkým hrdlem je spíše cílová složka než transformace. Můžete to překonat tím, že budete mít více destinací. Zde je příklad, který ukazuje implementaci více cílů.
-
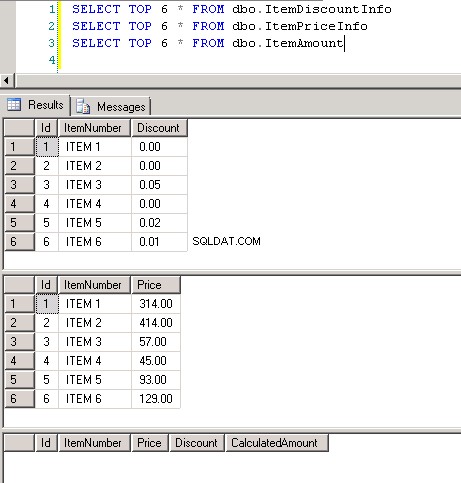
Snímek obrazovky č.8 zobrazuje počet záznamů ve všech třech tabulkách. Snímek obrazovky č.9 zobrazuje 6 nejlepších záznamů v každé z tabulek.
Doufám, že to pomůže.
Skripty SQL:
CREATE TABLE [dbo].[ItemAmount](
[Id] [int] IDENTITY(1,1) NOT NULL,
[ItemNumber] [nvarchar](30) NOT NULL,
[Price] [numeric](18, 2) NOT NULL,
[Discount] [numeric](18, 2) NOT NULL,
[CalculatedAmount] [numeric](18, 2) NOT NULL,
CONSTRAINT [PK_ItemAmount] PRIMARY KEY CLUSTERED ([Id] ASC)) ON [PRIMARY]
GO
CREATE TABLE [dbo].[ItemDiscountInfo](
[Id] [int] IDENTITY(1,1) NOT NULL,
[ItemNumber] [nvarchar](30) NOT NULL,
[Discount] [numeric](18, 2) NOT NULL,
CONSTRAINT [PK_ItemDiscountInfo] PRIMARY KEY CLUSTERED ([Id] ASC)) ON [PRIMARY]
GO
CREATE TABLE [dbo].[ItemPriceInfo](
[Id] [int] IDENTITY(1,1) NOT NULL,
[ItemNumber] [nvarchar](30) NOT NULL,
[Price] [numeric](18, 2) NOT NULL,
CONSTRAINT [PK_ItemPriceInfo] PRIMARY KEY CLUSTERED ([Id] ASC)) ON [PRIMARY]
GO
Snímek obrazovky č. 1:

Snímek obrazovky č. 2:
Snímek obrazovky č. 3:
Snímek obrazovky č. 4:
Snímek obrazovky č. 5:

Snímek obrazovky č. 6:
Snímek obrazovky č. 7:
Snímek obrazovky č. 8:
Snímek obrazovky č. 9: