Krátké shrnutí
- Výkon metody dílčích dotazů závisí na distribuci dat.
- Výkon podmíněné agregace nezávisí na distribuci dat.
Metoda poddotazů může být rychlejší nebo pomalejší než podmíněná agregace, záleží na distribuci dat.
Přirozeně, pokud má tabulka vhodný index, pak z něj pravděpodobně budou těžit poddotazy, protože index by umožnil skenovat pouze relevantní část tabulky namísto úplného skenování. Je nepravděpodobné, že by vhodný index významně prospěl metodě podmíněné agregace, protože stejně prohledá celý index. Jedinou výhodou by bylo, kdyby byl index užší než tabulka a engine by musel číst méně stránek do paměti.
S tímto vědomím se můžete rozhodnout, kterou metodu zvolíte.
První test
Udělal jsem větší testovací stůl s 5M řádky. Na stole nebyly žádné indexy. Měřil jsem statistiky IO a CPU pomocí SQL Sentry Plan Explorer. Pro tyto testy jsem použil SQL Server 2014 SP1-CU7 (12.0.4459.0) Express 64bitový.
Vaše původní dotazy se skutečně chovaly tak, jak jste popsali, tj. poddotazy byly rychlejší, i když čtení bylo 3krát vyšší.
Po několika pokusech na tabulce bez indexu jsem přepsal váš podmíněný agregát a přidal proměnné tak, aby obsahovaly hodnotu DATEADD výrazy.
Celkový čas se výrazně zrychlil.
Potom jsem nahradil SUM s COUNT a bylo to zase o něco rychlejší.
Koneckonců, podmíněná agregace byla téměř stejně rychlá jako dílčí dotazy.
Zahřejte mezipaměť (CPU=375)
SELECT -- warm cache
COUNT(*) AS all_cnt
FROM LogTable
OPTION (RECOMPILE);
Poddotazy (CPU=1031)
SELECT -- subqueries
(
SELECT count(*) FROM LogTable
) all_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,-1,GETDATE())
) last_year_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,-10,GETDATE())
) last_ten_year_cnt
OPTION (RECOMPILE);
Původní podmíněná agregace (CPU=1641)
SELECT -- conditional original
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > DATEADD(year,-1,GETDATE())
THEN 1 ELSE 0 END) AS last_year_cnt,
SUM(CASE WHEN datesent > DATEADD(year,-10,GETDATE())
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Podmíněná agregace s proměnnými (CPU=1078)
DECLARE @VarYear1 datetime = DATEADD(year,-1,GETDATE());
DECLARE @VarYear10 datetime = DATEADD(year,-10,GETDATE());
SELECT -- conditional variables
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > @VarYear1
THEN 1 ELSE 0 END) AS last_year_cnt,
SUM(CASE WHEN datesent > @VarYear10
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Podmíněná agregace s proměnnými a COUNT namísto SUM (CPU=1062)
SELECT -- conditional variable, count, not sum
COUNT(*) AS all_cnt,
COUNT(CASE WHEN datesent > @VarYear1
THEN 1 ELSE NULL END) AS last_year_cnt,
COUNT(CASE WHEN datesent > @VarYear10
THEN 1 ELSE NULL END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);

Na základě těchto výsledků odhaduji, že CASE vyvoláno DATEADD pro každý řádek, zatímco WHERE byl dost chytrý, aby to jednou spočítal. Plus COUNT je o něco málo efektivnější než SUM .
Podmíněná agregace je nakonec jen o něco pomalejší než dílčí dotazy (1062 vs 1031), možná proto, že WHERE je o něco efektivnější než CASE samo o sobě a kromě toho WHERE odfiltruje poměrně dost řádků, takže COUNT musí zpracovat méně řádků.
V praxi bych použil podmíněnou agregaci, protože si myslím, že počet přečtení je důležitější. Pokud je vaše tabulka malá, aby se vešla a zůstala ve fondu vyrovnávacích pamětí, bude jakýkoli dotaz pro koncového uživatele rychlý. Pokud je však tabulka větší než dostupná paměť, pak očekávám, že čtení z disku výrazně zpomalí poddotazy.
Druhý test
Na druhou stranu je také důležité odfiltrovat řádky co nejdříve.
Zde je malá obměna testu, která to demonstruje. Zde jsem nastavil práh na GETDATE() + 100 let, abych se ujistil, že žádné řádky nesplňují kritéria filtru.
Zahřejte mezipaměť (CPU=344)
SELECT -- warm cache
COUNT(*) AS all_cnt
FROM LogTable
OPTION (RECOMPILE);
Poddotazy (CPU=500)
SELECT -- subqueries
(
SELECT count(*) FROM LogTable
) all_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,100,GETDATE())
) last_year_cnt
OPTION (RECOMPILE);
Původní podmíněná agregace (CPU=937)
SELECT -- conditional original
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > DATEADD(year,100,GETDATE())
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Podmíněná agregace s proměnnými (CPU=750)
DECLARE @VarYear100 datetime = DATEADD(year,100,GETDATE());
SELECT -- conditional variables
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > @VarYear100
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Podmíněná agregace s proměnnými a COUNT namísto SUM (CPU=750)
SELECT -- conditional variable, count, not sum
COUNT(*) AS all_cnt,
COUNT(CASE WHEN datesent > @VarYear100
THEN 1 ELSE NULL END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
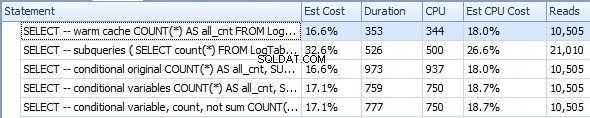
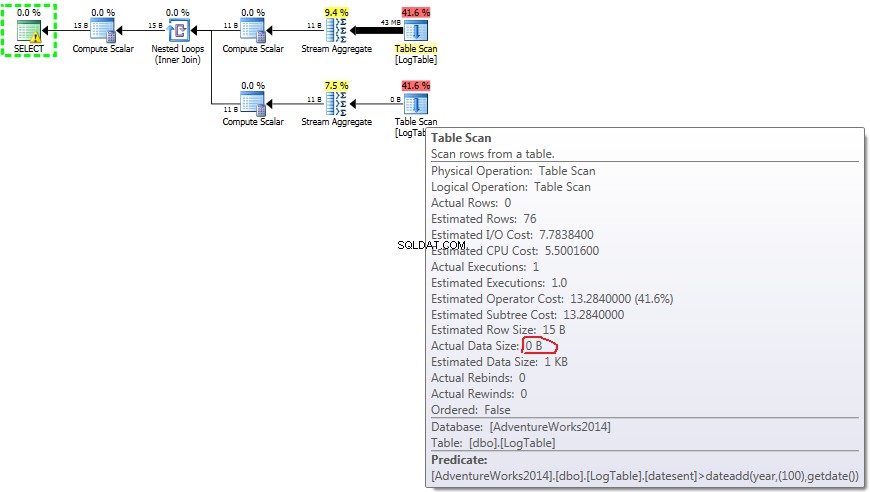
Níže je plán s dílčími dotazy. Můžete vidět, že v druhém dílčím dotazu do Stream Aggregate šlo 0 řádků, všechny byly odfiltrovány v kroku Skenování tabulky.
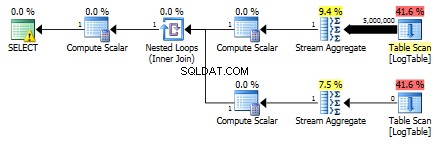
Díky tomu jsou poddotazy opět rychlejší.
Třetí test
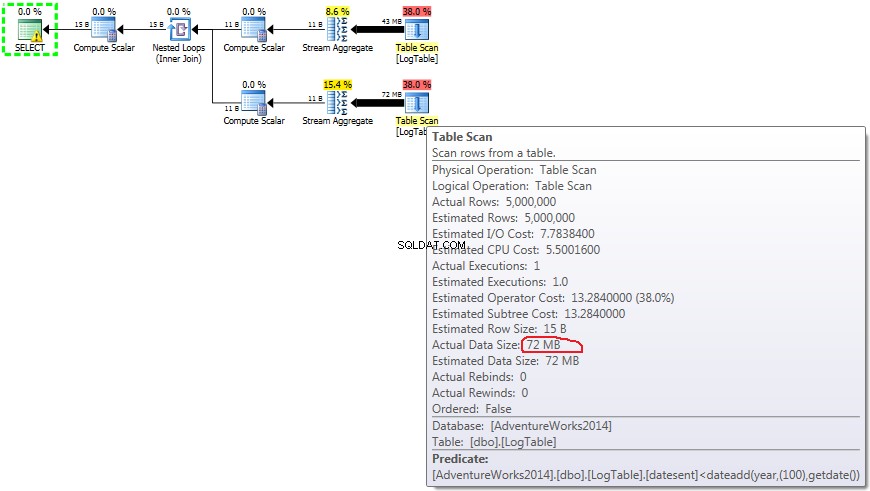
Zde jsem změnil kritéria filtrování předchozího testu:vše > byly nahrazeny < . Výsledkem je podmíněné COUNT počítal všechny řádky místo žádné. Překvapení, překvapení! Podmíněný agregační dotaz trval stejně 750 ms, zatímco poddotazy se staly 813 namísto 500.

Zde je plán pro dílčí dotazy:
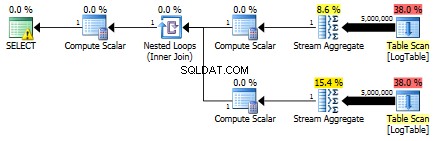
Mohl byste mi uvést příklad, kde podmíněná agregace výrazně převyšuje výkon řešení poddotazů?
Tady to je. Výkon metody poddotazů závisí na distribuci dat. Výkon podmíněné agregace nezávisí na distribuci dat.
Metoda poddotazů může být rychlejší nebo pomalejší než podmíněná agregace, záleží na distribuci dat.
S tímto vědomím se můžete rozhodnout, kterou metodu zvolíte.
Podrobnosti o bonusu
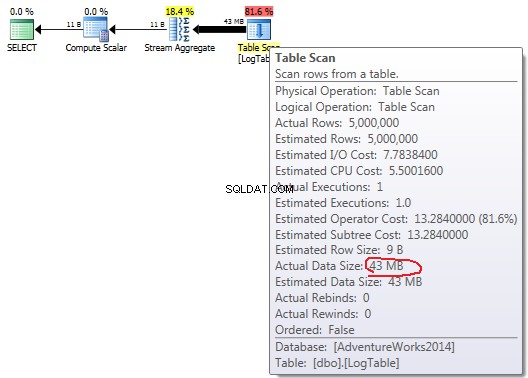
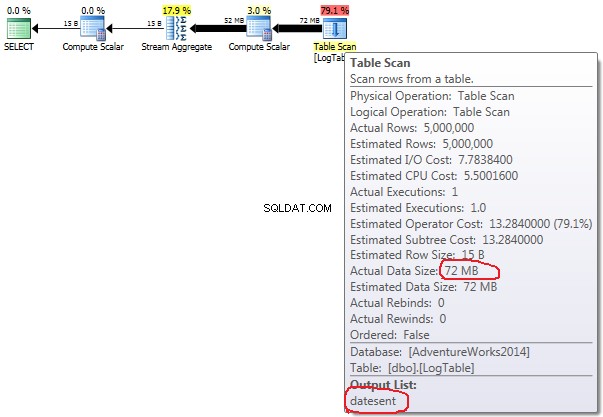
Pokud najedete myší na Table Scan operátora můžete vidět Actual Data Size v různých variantách.
- Jednoduché
COUNT(*):
- Podmíněná agregace:
- Poddotaz v testu 2:
- Poddotaz v testu 3:
Nyní je jasné, že rozdíl ve výkonu je pravděpodobně způsoben rozdílem v množství dat, které plánem protékají.
V případě jednoduchého COUNT(*) neexistuje žádný Output list (nejsou potřeba žádné hodnoty sloupců) a velikost dat je nejmenší (43 MB).
V případě podmíněné agregace se tato částka mezi testy 2 a 3 nemění, vždy je 72 MB. Output list má jeden sloupec datesent .
V případě dílčích dotazů tato částka dělá měnit v závislosti na distribuci dat.