Toto je součástí série SQL Server Internals Problematic Operators. Určitě si přečtěte Kalenův první a druhý příspěvek na toto téma.
SQL Server existuje více než 30 let a já pracuji se serverem SQL Server téměř stejně dlouho. V průběhu let (a desetiletí!) a verzí tohoto neuvěřitelného produktu jsem viděl mnoho změn. V těchto příspěvcích se s vámi podělím o to, jak se dívám na některé funkce nebo aspekty SQL Serveru, někdy spolu s trochou historické perspektivy.
Minule jsem mluvil o hašování v plánu dotazů SQL Server jako o potenciálně problematickém operátoru v diagnostice serveru SQL. Hašování se často používá pro spojení a agregaci, když neexistuje žádný užitečný index. A stejně jako skenování (o kterých jsem mluvil v prvním příspěvku této série), jsou chvíle, kdy je hašování ve skutečnosti lepší volbou než alternativy. Pro hash joiny je jednou z alternativ LOOP JOIN, o které jsem vám také říkal minule.
V tomto příspěvku vám řeknu o další alternativě pro hashování. Většina alternativ k hašování vyžaduje třídění dat, takže buď plán musí zahrnovat operátor SORT, nebo musí být požadovaná data již setříděna kvůli existujícím indexům.
Různé typy spojení pro diagnostiku SQL Server
Pro operace JOIN je nejběžnějším a nejužitečnějším typem JOIN LOOP JOIN. Algoritmus pro LOOP JOIN jsem popsal v předchozím příspěvku. Ačkoli data samotná nemusí být tříděna pro LOOP JOIN, přítomnost indexu ve vnitřní tabulce činí spojení mnohem efektivnější a jak byste měli vědět, přítomnost indexu implikuje určité třídění. Zatímco seskupený index třídí data sám, neseskupený index třídí sloupce klíče indexu. Ve skutečnosti se ve většině případů bez indexu optimalizátor SQL Serveru rozhodne použít algoritmus HASH JOIN. Minule jsme to viděli v příkladu, že bez indexů byl zvolen HASH JOIN as indexy jsme dostali LOOP JOIN.
Třetím typem spojení je MERGE JOIN. Tento algoritmus pracuje na dvou již seřazených datových sadách. Pokud se pokoušíme zkombinovat (nebo JOIN) dvě sady dat, které jsou již setříděny, stačí jeden průchod každou sadou, abychom našli odpovídající řádky. Zde je pseudokód pro algoritmus sloučení:
get first row R1 from input 1
get first row R2 from input 2
while not at the end of either input
begin
if R1 joins with R2
begin
output (R1, R2)
get next row R2 from input 2
end
else if R1 < R2
get next row R1 from input 1
else
get next row R2 from input 2
end
Ačkoli je MERGE JOIN velmi účinný algoritmus, vyžaduje, aby obě vstupní datové sady byly seřazeny podle spojovacího klíče, což obvykle znamená mít na spojovacím klíči seskupený index pro obě tabulky. Vzhledem k tomu, že pro každou tabulku získáte pouze jeden klastrovaný index, výběr sloupce klastrovaného klíče jen proto, aby došlo k MERGE JOINS, nemusí být celkově nejlepší volbou pro klastrovací klíč.
Obvykle tedy nedoporučuji, abyste se pokoušeli vytvářet indexy pouze pro účely MERGE JOINS, ale pokud nakonec získáte MERGE JOIN kvůli již existujícím indexům, je to obvykle dobrá věc. Kromě požadavku, aby byly obě vstupní datové sady seřazeny, MERGE JOIN také vyžaduje, aby alespoň jedna datová sada měla jedinečné hodnoty pro klíč spojení.
Podívejme se na příklad. Nejprve znovu vytvoříme Záhlaví a Podrobnosti tabulky:
USE AdventureWorks2016;
GO
DROP TABLE IF EXISTS Details;
GO
SELECT * INTO Details FROM Sales.SalesOrderDetail;
GO
DROP TABLE IF EXISTS Headers;
GO
SELECT * INTO Headers FROM Sales.SalesOrderHeader;
GO
CREATE CLUSTERED INDEX Header_index on Headers(SalesOrderID);
GO
CREATE CLUSTERED INDEX Detail_index on Details(SalesOrderID);
GO
Dále se podívejte na plán spojení mezi těmito tabulkami:
SELECT *
FROM Details d JOIN Headers h
ON d.SalesOrderID = h.SalesOrderID;
GO
Zde je plán:

Všimněte si, že i se seskupeným indexem na obou tabulkách získáme HASH JOIN. Můžeme přestavět jeden z indexů, aby byl UNIKÁTNÍ. V tomto případě to musí být index v Hlavičkách tabulka, protože ta je jediná, která má jedinečné hodnoty pro SalesOrderID.
CREATE UNIQUE CLUSTERED INDEX Header_index on Headers(SalesOrderID) WITH DROP_EXISTING;
GO
Nyní spusťte dotaz znovu a všimněte si, že plán dělá jak MERGE JOIN.

Tyto plány těží z toho, že data jsou již roztříděna v indexu, protože prováděcí plán může třídění využít. Někdy však SQL Server musí provést třídění jako součást provádění dotazu. Občas můžete vidět, že se operátor SORT objeví v plánu, i když nepožádáte o seřazený výstup. Pokud se SQL Server domnívá, že MERGE JOIN by mohla být dobrá volba, ale jedna z tabulek nemá vhodný seskupený index a je dostatečně malá, aby bylo řazení velmi levné, lze provést SORT, aby bylo možné MERGE JOIN použité.
Ale obvykle se operátor SORT objeví v dotazech, kde jsme požádali o seřazená data pomocí ORDER BY, jako v následujícím příkladu.
SELECT * FROM Details
ORDER BY ProductID;
GO

Clusterový index je skenován (což je stejné jako skenování tabulky) a poté jsou řádky seřazeny podle požadavků.
Zacházení s již seřazeným seskupeným indexem
Ale co když jsou data již seřazena v seskupeném indexu a dotaz obsahuje ORDER BY ve sloupci seskupeného klíče? Ve výše uvedeném příkladu jsme vytvořili seskupený index na SalesOrderID v tabulce Podrobnosti. Podívejte se na následující dva dotazy:
SELECT * FROM Details;
GO
SELECT * FROM Details
ORDER BY SalesOrderID;
GO
Pokud tyto dotazy spustíme společně, okno analýzy Quest Spotlight Tuning Pack ukazuje, že oba plány mají stejnou cenu; každý je 50 % z celkového počtu. Jaký je tedy mezi nimi vlastně rozdíl?
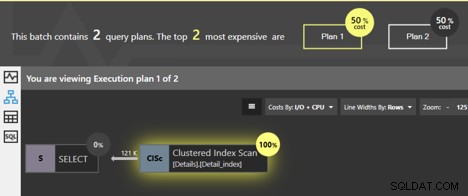
Oba dotazy skenují seskupený index a SQL Server ví, že pokud jsou stránky na úrovni listu sledovány v pořadí, data se vrátí v pořadí seskupených klíčů. Není třeba provádět žádné další třídění, takže do plánu není přidán žádný operátor SORT. Ale je tu rozdíl. Můžeme kliknout na operátor Clustered Index Scan a získáme nějaké podrobné informace.
Nejprve se podívejte na podrobné informace pro první plán, pro dotaz bez ORDER BY.

Podrobnosti nám říkají, že vlastnost „Ordered“ je False. Není zde žádný požadavek, aby se data vracela v seřazeném pořadí. Ukazuje se, že ve většině případů je nejjednodušším způsobem, jak získat data, sledovat stránky seskupeného indexu, takže data se nakonec vrátí v pořádku, ale neexistuje žádná záruka. Vlastnost False znamená, že není vyžadováno, aby SQL Server sledoval uspořádané stránky, aby vrátil výsledek. Ve skutečnosti existují další způsoby, jak může SQL Server získat všechny řádky tabulky, aniž by se musel řídit seskupeným indexem. Pokud se během provádění SQL Server rozhodne použít k získání řádků jinou metodu, neuvidíme seřazené výsledky.
U druhého dotazu vypadají podrobnosti takto:
 Protože dotaz obsahoval ORDER BY, existuje požadavek, aby byla data vrácena v seřazeném pořadí a SQL Server bude následovat stránky seskupeného indexu v daném pořadí.
Protože dotaz obsahoval ORDER BY, existuje požadavek, aby byla data vrácena v seřazeném pořadí a SQL Server bude následovat stránky seskupeného indexu v daném pořadí.
Nejdůležitější věcí, kterou je třeba si pamatovat, je, že BEZ garancí seřazených dat, pokud do dotazu nezahrnete ORDER BY. Jen proto, že máte seskupený index, stále neexistuje žádná záruka! I když pokaždé, když jste za loňský rok provedli dotaz, dostali jste data zpět v pořádku bez ORDER BY, není zaručeno, že budete i nadále mít data v pořádku. Použití ORDER BY je jediný způsob, jak zaručit pořadí, ve kterém budou vráceny vaše výsledky.
Tipy pro používání operací řazení
Je tedy SORT operací, které je třeba se vyhnout v diagnostice serveru SQL? Stejně jako u skenování a hašovacích operací je odpověď samozřejmě „záleží“. Třídění může být velmi nákladné, zejména na velkých souborech dat. Správné indexování pomáhá serveru SQL Server vyhnout se provádění operací SORT, protože index v podstatě znamená, že jsou vaše data předtříděna. Indexování však něco stojí. Pro každý index jsou kromě nákladů na údržbu také náklady na skladování. Pokud jsou vaše data intenzivně aktualizována, musíte počet indexů omezit na minimum.
Pokud zjistíte, že některé z vašich pomalu běžících dotazů ve svých plánech zobrazují operace SORT a pokud tyto SORT patří mezi nejdražší operátory v plánu, můžete zvážit vytvoření indexů, které SQL Serveru umožní vyhnout se řazení. Budete však muset provést důkladné testování, abyste se ujistili, že dodatečné indexy nezpomalí další dotazy, které jsou klíčové pro celkový výkon vaší aplikace.