Vidím tam spoustu rad, které říkají něco ve smyslu:"Změňte svůj kurzor na operaci založenou na množině; bude to rychlejší." I když tomu tak často může být, není to vždy pravda. Jeden případ použití, který vidím, kde kurzor opakovaně překonává typický přístup založený na množinách, je výpočet průběžných součtů. Je to proto, že přístup založený na množinách se obvykle musí podívat na určitou část podkladových dat více než jednou, což může být exponenciálně špatná věc, protože se data zvětšují; zatímco kurzor – jakkoli bolestivě to může znít – může projít každým řádkem/hodnotou právě jednou.
Toto jsou naše základní možnosti ve většině běžných verzí SQL Server. V SQL Server 2012 však bylo provedeno několik vylepšení funkcí oken a klauzule OVER, většinou pocházejících z několika skvělých návrhů, které předložil kolega MVP Itzik Ben-Gan (zde je jeden z jeho návrhů). Itzik má ve skutečnosti novou knihu MS-Press, která pokrývá všechna tato vylepšení mnohem podrobněji, s názvem „Microsoft SQL Server 2012 High-Performance T-SQL Using Window Functions.“
Tak přirozeně jsem byl zvědavý; způsobila by nová funkce oken zastaralé techniky kurzoru a automatického připojení? Bylo by jednodušší je kódovat? Byli by rychlejší v jakémkoli (nevadí ve všech) případech? Jaké další přístupy by mohly být platné?
Nastavení
Chcete-li provést nějaké testování, vytvořte databázi:
USE [master];
GO
IF DB_ID('RunningTotals') IS NOT NULL
BEGIN
ALTER DATABASE RunningTotals SET SINGLE_USER WITH ROLLBACK IMMEDIATE;
DROP DATABASE RunningTotals;
END
GO
CREATE DATABASE RunningTotals;
GO
USE RunningTotals;
GO
SET NOCOUNT ON;
GO A pak vyplňte tabulku 10 000 řádky, které můžeme použít k porovnání průběžných součtů. Nic složitého, jen souhrnná tabulka s řádkem pro každé datum a číslem, které představuje počet vydaných pokut za překročení rychlosti. Už několik let jsem neměl pokutu za překročení rychlosti, takže nevím, proč to byla moje podvědomá volba pro zjednodušený datový model, ale je to tak.
CREATE TABLE dbo.SpeedingTickets ( [Date] DATE NOT NULL, TicketCount INT ); GO ALTER TABLE dbo.SpeedingTickets ADD CONSTRAINT pk PRIMARY KEY CLUSTERED ([Date]); GO ;WITH x(d,h) AS ( SELECT TOP (250) ROW_NUMBER() OVER (ORDER BY [object_id]), CONVERT(INT, RIGHT([object_id], 2)) FROM sys.all_objects ORDER BY [object_id] ) INSERT dbo.SpeedingTickets([Date], TicketCount) SELECT TOP (10000) d = DATEADD(DAY, x2.d + ((x.d-1)*250), '19831231'), x2.h FROM x CROSS JOIN x AS x2 ORDER BY d; GO SELECT [Date], TicketCount FROM dbo.SpeedingTickets ORDER BY [Date]; GO
Zkrácené výsledky:
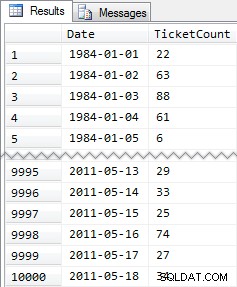
Takže opět 10 000 řádků docela jednoduchých dat – malé hodnoty INT a řada dat od roku 1984 do května 2011.
Přístupy
Nyní je můj úkol poměrně jednoduchý a typický pro mnoho aplikací:vrátit sadu výsledků, která má všech 10 000 dat, spolu s kumulativním součtem všech pokut za překročení rychlosti do tohoto data včetně. Většina lidí by nejprve zkusila něco takového (budeme tomu říkat „vnitřní spojení " metoda):
SELECT st1.[Date], st1.TicketCount, RunningTotal = SUM(st2.TicketCount) FROM dbo.SpeedingTickets AS st1 INNER JOIN dbo.SpeedingTickets AS st2 ON st2.[Date] <= st1.[Date] GROUP BY st1.[Date], st1.TicketCount ORDER BY st1.[Date];
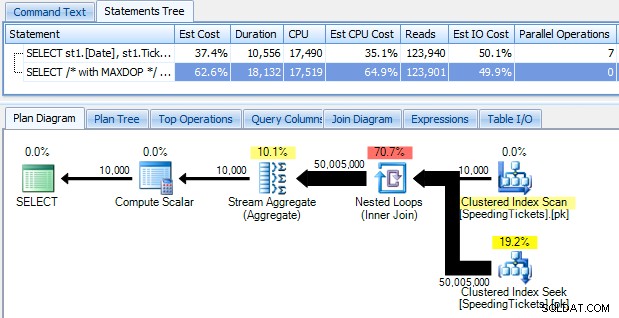
…a budete šokováni, když zjistíte, že spuštění trvá téměř 10 sekund. Pojďme rychle prozkoumat proč zobrazením grafického prováděcího plánu pomocí SQL Sentry Plan Explorer:

Velké tlusté šipky by měly okamžitě naznačit, co se děje:vnořená smyčka čte jeden řádek pro první agregaci, dva řádky pro druhý, tři řádky pro třetí a dále a dále přes celou sadu 10 000 řádků. To znamená, že bychom měli vidět zhruba ((10 000 * (10 000 + 1)) / 2) řádků zpracovaných, jakmile se projde celá sada, a zdá se, že to odpovídá počtu řádků zobrazených v plánu.
Všimněte si, že spuštění dotazu bez paralelismu (pomocí nápovědy dotazu OPTION (MAXDOP 1)) trochu zjednoduší tvar plánu, ale vůbec nepomůže ani v době provádění, ani v I/O; jak je znázorněno v plánu, trvání se ve skutečnosti téměř zdvojnásobí a čtení se sníží pouze o velmi malé procento. V porovnání s předchozím plánem:
Existuje spousta dalších přístupů, kterými se lidé snažili získat efektivní průběžné součty. Jedním z příkladů je „metoda poddotazu ", který pouze používá korelovaný poddotaz v podstatě stejným způsobem jako metoda vnitřního spojení popsaná výše:
SELECT [Date], TicketCount, RunningTotal = TicketCount + COALESCE( ( SELECT SUM(TicketCount) FROM dbo.SpeedingTickets AS s WHERE s.[Date] < o.[Date]), 0 ) FROM dbo.SpeedingTickets AS o ORDER BY [Date];
Porovnání těchto dvou plánů:
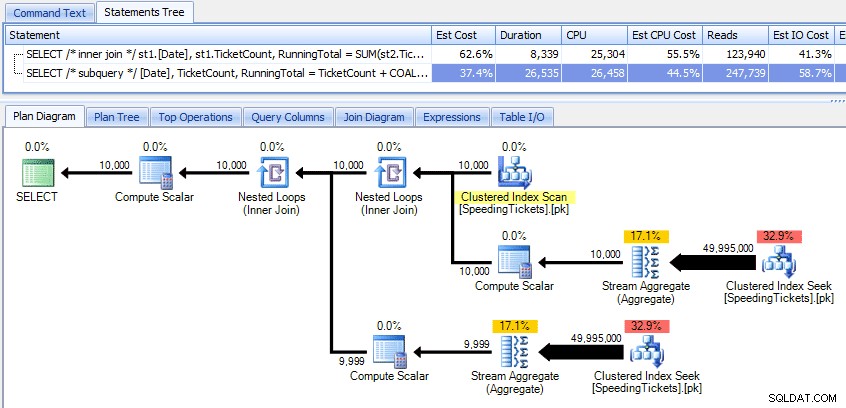
I když se tedy zdá, že metoda poddotazu má efektivnější celkový plán, horší je tam, kde na tom záleží:trvání a I/O. Můžeme vidět, co k tomu přispívá, když se do plánů ponoříme trochu hlouběji. Přesunutím na kartu Top Operations můžeme vidět, že v metodě vnitřního spojení je hledání clusteru indexu provedeno 10 000krát a všechny ostatní operace jsou provedeny pouze několikrát. V metodě dílčího dotazu se však několik operací provede 9 999 nebo 10 000krát:
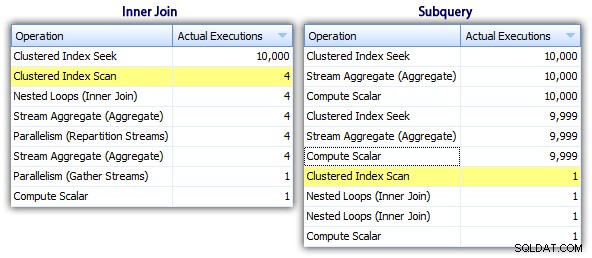
Zdá se tedy, že přístup poddotazu je horší, nikoli lepší. Další metodu, kterou vyzkoušíme, budu nazývat „podivná aktualizace " metoda. Není zaručeno, že to bude fungovat, a nikdy bych ji nedoporučoval pro produkční kód, ale pro úplnost ji uvádím. V podstatě tato svérázná aktualizace využívá toho, že během aktualizace můžete přesměrovat zadání a matematiku, takže že proměnná se zvyšuje za scénou při aktualizaci každého řádku.
DECLARE @st TABLE ( [Date] DATE PRIMARY KEY, TicketCount INT, RunningTotal INT ); DECLARE @RunningTotal INT = 0; INSERT @st([Date], TicketCount, RunningTotal) SELECT [Date], TicketCount, RunningTotal = 0 FROM dbo.SpeedingTickets ORDER BY [Date]; UPDATE @st SET @RunningTotal = RunningTotal = @RunningTotal + TicketCount FROM @st; SELECT [Date], TicketCount, RunningTotal FROM @st ORDER BY [Date];
Znovu zopakuji, že nevěřím, že tento přístup je bezpečný pro výrobu, bez ohledu na svědectví, která uslyšíte od lidí, kteří říkají, že „nikdy neselže“. Pokud není chování zdokumentováno a zaručeno, snažím se vyhýbat domněnkám založeným na pozorovaném chování. Nikdy nevíte, kdy nějaká změna cesty rozhodování optimalizátoru (na základě změny statistiky, změny dat, aktualizace Service Pack, příznaku trasování, nápovědy k dotazu, co máte) drasticky změní plán a potenciálně povede k jinému pořadí. Pokud se vám tento neintuitivní přístup opravdu líbí, můžete se trochu zlepšit použitím možnosti dotazu FORCE ORDER (a to se pokusí použít uspořádané skenování PK, protože to je jediný vhodný index v proměnné tabulky):
UPDATE @st SET @RunningTotal = RunningTotal = @RunningTotal + TicketCount FROM @st OPTION (FORCE ORDER);
Pro trochu větší jistotu při mírně vyšších vstupních/výstupních nákladech můžete vrátit do hry původní stůl a zajistit, aby byl použit PK na základním stole:
UPDATE st SET @RunningTotal = st.RunningTotal = @RunningTotal + t.TicketCount FROM dbo.SpeedingTickets AS t WITH (INDEX = pk) INNER JOIN @st AS st ON t.[Date] = st.[Date] OPTION (FORCE ORDER);
Osobně si nemyslím, že je to o tolik zaručenější, protože část operace SET by mohla potenciálně ovlivnit optimalizátor nezávisle na zbytku dotazu. Opět tento postup nedoporučuji, pouze uvádím srovnání pro úplnost. Zde je plán z tohoto dotazu:
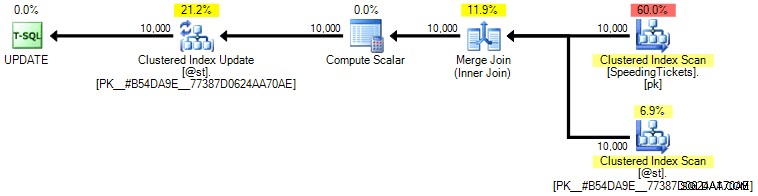
Na základě počtu poprav, které vidíme na záložce Top Operations (ušetřím vám snímek obrazovky; je to 1 pro každou operaci), je jasné, že i když provedeme spojení, abychom měli lepší pocit z objednávání, podivné aktualizace umožňuje vypočítat průběžné součty v jediném průchodu dat. Ve srovnání s předchozími dotazy je mnohem efektivnější, i když nejprve vypíše data do proměnné tabulky a rozdělí se do několika operací:

Tím se dostáváme k „rekurzivnímu CTE " metoda. Tato metoda používá hodnotu data a spoléhá na předpoklad, že neexistují žádné mezery. Protože jsme tato data vyplnili výše, víme, že jde o plně souvislou řadu, ale v mnoha scénářích to nelze předpoklad. Takže, i když jsem to pro úplnost zahrnul, tento přístup nebude vždy platný. V každém případě se používá rekurzivní CTE s prvním (známým) datem v tabulce jako kotva a rekurzivní část určená přidáním jednoho dne (přidáním možnosti MAXRECURSION, protože přesně víme, kolik řádků máme):
;WITH x AS ( SELECT [Date], TicketCount, RunningTotal = TicketCount FROM dbo.SpeedingTickets WHERE [Date] = '19840101' UNION ALL SELECT y.[Date], y.TicketCount, x.RunningTotal + y.TicketCount FROM x INNER JOIN dbo.SpeedingTickets AS y ON y.[Date] = DATEADD(DAY, 1, x.[Date]) ) SELECT [Date], TicketCount, RunningTotal FROM x ORDER BY [Date] OPTION (MAXRECURSION 10000);
Tento dotaz funguje zhruba stejně efektivně jako bizarní metoda aktualizace. Můžeme to porovnat s metodami poddotazu a vnitřního spojení:

Stejně jako podivnou metodu aktualizace bych tento přístup CTE ve výrobě nedoporučoval, pokud nemůžete absolutně zaručit, že váš klíčový sloupec nemá žádné mezery. Pokud máte mezery v datech, můžete vytvořit něco podobného pomocí ROW_NUMBER(), ale nebude to o nic efektivnější než výše uvedená metoda self-join.
A pak tu máme „kurzor " přístup:
DECLARE @st TABLE
(
[Date] DATE PRIMARY KEY,
TicketCount INT,
RunningTotal INT
);
DECLARE
@Date DATE,
@TicketCount INT,
@RunningTotal INT = 0;
DECLARE c CURSOR
LOCAL STATIC FORWARD_ONLY READ_ONLY
FOR
SELECT [Date], TicketCount
FROM dbo.SpeedingTickets
ORDER BY [Date];
OPEN c;
FETCH NEXT FROM c INTO @Date, @TicketCount;
WHILE @@FETCH_STATUS = 0
BEGIN
SET @RunningTotal = @RunningTotal + @TicketCount;
INSERT @st([Date], TicketCount, RunningTotal)
SELECT @Date, @TicketCount, @RunningTotal;
FETCH NEXT FROM c INTO @Date, @TicketCount;
END
CLOSE c;
DEALLOCATE c;
SELECT [Date], TicketCount, RunningTotal
FROM @st
ORDER BY [Date]; …což je mnohem více kódu, ale na rozdíl od toho, co by mohlo naznačovat obecné mínění, se vrátí za 1 sekundu. Z některých podrobností plánu výše vidíme proč:většina ostatních přístupů končí čtením stejných dat znovu a znovu, zatímco přístup pomocí kurzoru čte každý řádek jednou a udržuje průběžný součet v proměnné namísto výpočtu součtu. a znovu. Můžeme to vidět, když se podíváme na příkazy zachycené generováním skutečného plánu v Průzkumníku plánů:
Vidíme, že bylo shromážděno přes 20 000 příkazů, ale pokud seřadíme podle odhadovaných nebo skutečných řádků sestupně, zjistíme, že existují pouze dvě operace, které zpracovávají více než jeden řádek. Což je na hony vzdáleno několika výše uvedeným metodám, které způsobují exponenciální čtení kvůli opakovanému čtení stejných předchozích řádků pro každý nový řádek.
Nyní se podívejme na nová vylepšení oken v SQL Server 2012. Konkrétně nyní můžeme vypočítat SUM OVER() a určit sadu řádků vzhledem k aktuálnímu řádku. Takže například:
SELECT [Date], TicketCount, SUM(TicketCount) OVER (ORDER BY [Date] RANGE UNBOUNDED PRECEDING) FROM dbo.SpeedingTickets ORDER BY [Date]; SELECT [Date], TicketCount, SUM(TicketCount) OVER (ORDER BY [Date] ROWS UNBOUNDED PRECEDING) FROM dbo.SpeedingTickets ORDER BY [Date];
Tyto dva dotazy náhodou dávají stejnou odpověď se správnými průběžnými součty. Ale fungují úplně stejně? Plány naznačují, že ne. Verze s ŘÁDKY má dalšího operátora, projekt sekvence s 10 000 řádky:
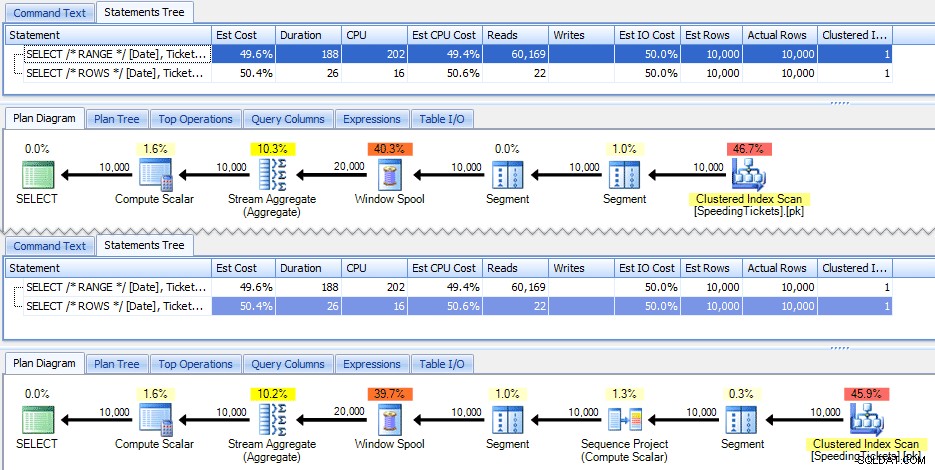
A to je asi rozsah rozdílu v grafickém plánu. Ale když se podíváte trochu blíže na skutečné metriky běhu, uvidíte drobné rozdíly v trvání a CPU a obrovský rozdíl ve čteních. Proč je to? Je to proto, že RANGE používá zařazování na disku, zatímco ROWS používá zařazování v paměti. U malých sad je rozdíl pravděpodobně zanedbatelný, ale náklady na cívku na disku mohou být jistě zjevnější, když se sady zvětší. Nechci spoilerovat konec, ale můžete mít podezření, že jedno z těchto řešení bude fungovat lépe než druhé v důkladnějším testu.
Kromě toho následující verze dotazu poskytuje stejné výsledky, ale funguje jako pomalejší verze RANGE výše:
SELECT [Date], TicketCount, SUM(TicketCount) OVER (ORDER BY [Date]) FROM dbo.SpeedingTickets ORDER BY [Date];
Takže když si hrajete s novými funkcemi oken, budete chtít mít na paměti takové drobnosti:zkrácená verze dotazu nebo ta, kterou jste náhodou napsali jako první, nemusí být nutně ta, kterou chcete tlačit do výroby.
Aktuální testy
Abychom provedli spravedlivé testy, vytvořil jsem uloženou proceduru pro každý přístup a výsledky jsem změřil zachycením příkazů na serveru, kde jsem již monitoroval pomocí SQL Sentry (pokud nepoužíváte náš nástroj, můžete shromažďovat události SQL:BatchCompleted podobným způsobem pomocí SQL Server Profiler).
„Spravedlivými testy“ mám na mysli, že například nepředvídatelná metoda aktualizace vyžaduje skutečnou aktualizaci statických dat, což znamená změnu základního schématu nebo použití dočasné tabulky / proměnné tabulky. Takže jsem strukturoval uložené procedury tak, aby každá vytvořila svou vlastní proměnnou tabulky a buď tam uložila výsledky, nebo tam uložila nezpracovaná data a pak aktualizovala výsledek. Dalším problémem, který jsem chtěl odstranit, bylo vracení dat klientovi – takže každá procedura má parametr ladění určující, zda nemají vrátit žádné výsledky (výchozí), horní/dolní 5 nebo všechny. V testech výkonu jsem nastavil, aby nevracel žádné výsledky, ale samozřejmě jsem každý ověřil, abych se ujistil, že vracejí správné výsledky.
Všechny uložené procedury jsou modelovány tímto způsobem (připojil jsem skript, který vytváří databázi a uložené procedury, takže zde pro stručnost uvádím šablonu):
CREATE PROCEDURE [dbo].[RunningTotals_]
@debug TINYINT = 0
-- @debug = 1 : show top/bottom 3
-- @debug = 2 : show all 50k
AS
BEGIN
SET NOCOUNT ON;
DECLARE @st TABLE
(
[Date] DATE PRIMARY KEY,
TicketCount INT,
RunningTotal INT
);
INSERT @st([Date], TicketCount, RunningTotal)
-- one of seven approaches used to populate @t
IF @debug = 1 -- show top 3 and last 3 to verify results
BEGIN
;WITH d AS
(
SELECT [Date], TicketCount, RunningTotal,
rn = ROW_NUMBER() OVER (ORDER BY [Date])
FROM @st
)
SELECT [Date], TicketCount, RunningTotal
FROM d
WHERE rn < 4 OR rn > 9997
ORDER BY [Date];
END
IF @debug = 2 -- show all
BEGIN
SELECT [Date], TicketCount, RunningTotal
FROM @st
ORDER BY [Date];
END
END
GO A nazval jsem je v dávce takto:
EXEC dbo.RunningTotals_DateCTE @debug = 0; GO EXEC dbo.RunningTotals_Cursor @debug = 0; GO EXEC dbo.RunningTotals_Subquery @debug = 0; GO EXEC dbo.RunningTotals_InnerJoin @debug = 0; GO EXEC dbo.RunningTotals_QuirkyUpdate @debug = 0; GO EXEC dbo.RunningTotals_Windowed_Range @debug = 0; GO EXEC dbo.RunningTotals_Windowed_Rows @debug = 0; GO
Rychle jsem si uvědomil, že některá z těchto volání se v Top SQL neobjevují, protože výchozí práh je 5 sekund. Změnil jsem to na 100 milisekund (něco, co byste v produkčním systému nikdy nechtěli dělat!) následovně:
Budu opakovat:toto chování není u produkčních systémů tolerováno!
Stále jsem zjistil, že jeden z výše uvedených příkazů nebyl zachycen prahem Top SQL; byla to verze Windowed_Rows. Takže jsem do této dávky přidal pouze následující:
EXEC dbo.RunningTotals_Windowed_Rows @debug = 0; WAITFOR DELAY '00:00:01'; GO
A teď se mi v Top SQL vrátilo všech 7 řádků. Zde jsou seřazeny podle využití CPU sestupně:
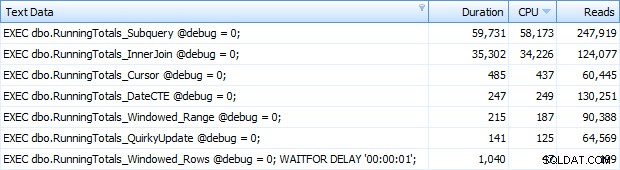
Můžete vidět další sekundu, kterou jsem přidal do dávky Windowed_Rows; nebyl zachycen prahem Top SQL, protože byl dokončen za pouhých 40 milisekund! Toto je jednoznačně náš nejlepší výkon, a pokud máme k dispozici SQL Server 2012, měla by to být metoda, kterou používáme. Kurzor také není napůl špatný vzhledem k výkonu nebo jiným problémům se zbývajícími řešeními. Vykreslit dobu trvání do grafu je docela nesmyslné – dva nejvyšší body a pět nerozeznatelných nejnižších bodů. Ale pokud je I/O vaším úzkým hrdlem, může být vizualizace čtení zajímavá:
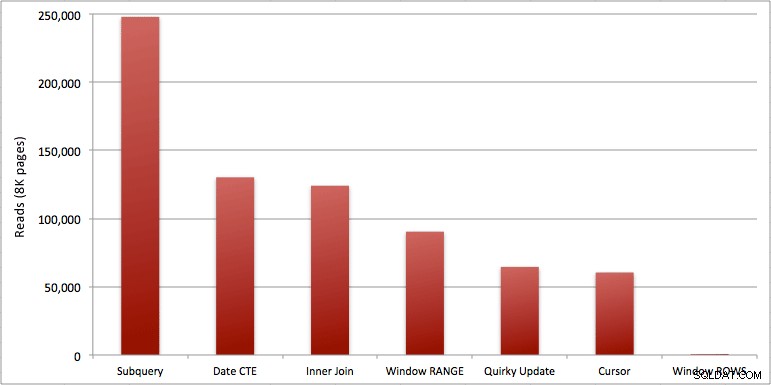
Závěr
Z těchto výsledků můžeme vyvodit několik závěrů:
- Okenní agregace v SQL Server 2012 znepokojivě zefektivňují problémy s výkonem při spouštění součtových výpočtů (a mnoha dalších problémů s dalšími řádky/předchozími řádky). Když jsem viděl ten nízký počet přečtení, s jistotou jsem si myslel, že došlo k nějakému omylu, že jsem musel zapomenout skutečně provést nějakou práci. Ale ne, stejný počet přečtení získáte, pokud vaše uložená procedura pouze provede obyčejný SELECT z tabulky SpeedingTickets. (Neváhejte si to sami otestovat pomocí STATISTICS IO.)
- Problémy, na které jsem poukázal dříve ohledně RANGE vs. ROWS, poskytují mírně odlišné doby běhu (rozdíl v délce asi 6x – nezapomeňte ignorovat druhý, který jsem přidal pomocí WAITFOR), ale rozdíly ve čtení jsou astronomické kvůli cívce na disku. Pokud lze váš okenní agregát vyřešit pomocí ROWS, vyhněte se RANGE, ale měli byste otestovat, že oba poskytují stejný výsledek (nebo alespoň že ROWS dává správnou odpověď). Měli byste si také uvědomit, že pokud používáte podobný dotaz a nezadáte RANGE ani ROWS, plán bude fungovat, jako byste zadali RANGE).
- Metody poddotazu a vnitřního spojení jsou poměrně propastné. 35 sekund až minuta na vygenerování těchto průběžných součtů? A to bylo na jediném, hubeném stole bez vracení výsledků klientovi. Tato srovnání lze použít k tomu, aby lidem ukázali, proč řešení založené na čistě množinách není vždy tou nejlepší odpovědí.
- Z rychlejších přístupů, za předpokladu, že ještě nejste připraveni na SQL Server 2012, a za předpokladu, že zahodíte jak svéráznou metodu aktualizace (nepodporovaná), tak metodu data CTE (nemůže zaručit souvislou sekvenci), provede pouze kurzor přijatelně. Má nejvyšší trvání z „rychlejších“ řešení, ale nejmenší počet přečtení.
Doufám, že tyto testy pomohou lépe zhodnotit vylepšení oken, která společnost Microsoft přidala do SQL Server 2012. Nezapomeňte prosím poděkovat Itzikovi, pokud ho uvidíte online nebo osobně, protože byl hnací silou těchto změn. Navíc doufám, že to pomůže otevřít některé myšlenky tam venku, že kurzor nemusí být vždy tím zlým a obávaným řešením, za které je často zobrazován.
(Dodatečně jsem testoval funkci CLR nabízenou Pavlem Pawlowským a výkonnostní charakteristiky byly téměř totožné s řešením SQL Server 2012 pomocí ROWS. Čtení byla identická, CPU bylo 78 vs. 47 a celková doba trvání byla 73 místo 40. Pokud tedy v blízké budoucnosti nebudete přecházet na SQL Server 2012, možná budete chtít přidat Pavlovo řešení do svých testů.)
Přílohy:RunningTotals_Demo.sql.zip (2 kb)