Princip „Neopakuj se“ naznačuje, že byste měli opakování omezit. Tento týden jsem narazil na případ, kdy by se SUCHÉ mělo vyhodit z okna. Existují i jiné případy (například skalární funkce), ale tento byl zajímavý, který zahrnoval bitovou logiku.
Představme si následující tabulku:
CREATE TABLE dbo.CarOrders
(
OrderID INT PRIMARY KEY,
WheelFlag TINYINT,
OrderDate DATE
--, ... other columns ...
);
CREATE INDEX IX_WheelFlag ON dbo.CarOrders(WheelFlag); Bity "WheelFlag" představují následující možnosti:
0 = stock wheels 1 = 17" wheels 2 = 18" wheels 4 = upgraded tires
Možné kombinace jsou tedy:
0 = no upgrade 1 = upgrade to 17" wheels only 2 = upgrade to 18" wheels only 4 = upgrade tires only 5 = 1 + 4 = upgrade to 17" wheels and better tires 6 = 2 + 4 = upgrade to 18" wheels and better tires
Ponechme stranou argumenty, alespoň pro tuto chvíli, o tom, zda by to mělo být v první řadě zabaleno do jednoho TINYINT, nebo uloženo jako samostatné sloupce, nebo použít model EAV… oprava designu je samostatný problém. Tady jde o práci s tím, co máte.
Aby byly příklady užitečné, vyplňte tuto tabulku hromadou náhodných dat. (A pro zjednodušení budeme předpokládat, že tato tabulka obsahuje pouze objednávky, které ještě nebyly odeslány.) Tím se vloží 50 000 řádků zhruba rovnoměrného rozdělení mezi šest kombinací možností:
;WITH n AS
(
SELECT n,Flag FROM (VALUES(1,0),(2,1),(3,2),(4,4),(5,5),(6,6)) AS n(n,Flag)
)
INSERT dbo.CarOrders
(
OrderID,
WheelFlag,
OrderDate
)
SELECT x.rn, n.Flag, DATEADD(DAY, x.rn/100, '20100101')
FROM n
INNER JOIN
(
SELECT TOP (50000)
n = (ABS(s1.[object_id]) % 6) + 1,
rn = ROW_NUMBER() OVER (ORDER BY s2.[object_id])
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
) AS x
ON n.n = x.n; Pokud se podíváme na členění, můžeme vidět toto rozdělení. Všimněte si, že vaše výsledky se mohou mírně lišit od mých v závislosti na objektech ve vašem systému:
SELECT WheelFlag, [Count] = COUNT(*) FROM dbo.CarOrders GROUP BY WheelFlag;
Výsledky:
WheelFlag Count --------- ----- 0 7654 1 8061 2 8757 4 8682 5 8305 6 8541
Nyní řekněme, že je úterý a my jsme právě dostali zásilku 18" kol, která dříve nebyla skladem. To znamená, že jsme schopni uspokojit všechny objednávky, které vyžadují 18" kola – jak ty, které upgradovaly pneumatiky (6), a ti, kteří ne (2). Takže bychom *mohli* napsat dotaz jako následující:
SELECT OrderID
FROM dbo.CarOrders
WHERE WheelFlag IN (2,6); Ve skutečném životě to samozřejmě nemůžete udělat; co když se později přidají další možnosti, jako jsou zámky kol, doživotní záruka na kola nebo více možností pneumatik? Nechcete, abyste museli psát řadu hodnot IN() pro každou možnou kombinaci. Místo toho můžeme napsat operaci BITWISE AND, abychom našli všechny řádky, kde je nastaven 2. bit, jako například:
DECLARE @Flag TINYINT = 2;
SELECT OrderID
FROM dbo.CarOrders
WHERE WheelFlag & @Flag = @Flag; To mi dává stejné výsledky jako dotaz IN(), ale když je porovnám pomocí SQL Sentry Plan Explorer, výkon je docela odlišný:

Je snadné pochopit proč. První používá hledání indexu k izolaci řádků, které vyhovují dotazu, pomocí filtru ve sloupci WheelFlag:
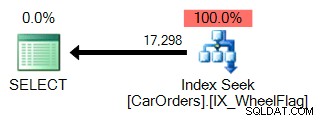

Druhý používá skenování spojené s implicitním převodem a strašně nepřesné statistiky. Vše kvůli operátorovi BITWISE AND:
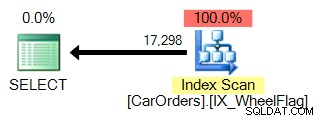


Co to tedy znamená? V jádru nám to říká, že operace BITWISE AND není proměnlivá .
Ale veškerá naděje není ztracena.
Pokud na chvíli ignorujeme princip DRY, můžeme napsat o něco efektivnější dotaz tím, že budeme trochu redundantní, abychom mohli využít výhod indexu ve sloupci WheelFlag. Za předpokladu, že hledáme jakoukoli možnost WheelFlag nad 0 (žádný upgrade), můžeme dotaz přepsat tímto způsobem a říct SQL Serveru, že hodnota WheelFlag musí být alespoň stejná jako příznak (což eliminuje 0 a 1 ) a poté přidáním doplňujících informací, které také musí obsahovat tento příznak (čímž se eliminuje 5).
SELECT OrderID FROM dbo.CarOrders WHERE WheelFlag >= @Flag AND WheelFlag & @Flag = @Flag;
Část>=této klauzule je zjevně pokryta částí BITWISE, takže zde porušujeme DRY. Ale protože tato klauzule, kterou jsme přidali, je proměnlivá, přeřazení operace BITWISE AND na sekundární podmínku vyhledávání stále vede ke stejnému výsledku a celkový dotaz poskytuje lepší výkon. Vidíme podobné hledání indexu jako pevně zakódovaná verze výše uvedeného dotazu, a přestože jsou odhady ještě dále (něco, co lze řešit jako samostatný problém), čtení je stále nižší než u samotné operace BITWISE AND:

Můžeme také vidět, že proti indexu je použit filtr, což jsme neviděli při použití samotné operace BITWISE AND:

Závěr
Nebojte se opakovat. Jsou chvíle, kdy tyto informace mohou pomoci optimalizátoru; i když nemusí být zcela intuitivní *přidávat* kritéria za účelem zlepšení výkonu, je důležité pochopit, kdy další klauzule pomáhají snížit data pro konečný výsledek, spíše než aby optimalizátor „snadno“ našel přesné řádky. sám o sobě.