Ve svém posledním příspěvku jsem zahájil sérii proaktivních kontrol stavu, které jsou pro váš SQL Server zásadní. Začali jsme s místem na disku a v tomto příspěvku budeme diskutovat o úkolech údržby. Jednou ze základních povinností správce DBA je zajistit, aby následující úlohy údržby probíhaly pravidelně:
- Zálohy
- Kontrola integrity
- Údržba indexu
- Aktualizace statistik
Vsadím se, že pro správu těchto úkolů již máte připravené úkoly. A také bych se vsadil, že máte nakonfigurována upozornění, aby vám a vašemu týmu poslali e-mail, pokud se úloha nezdaří. Pokud jsou obě pravdivé, pak již jednáte aktivně o údržbu. A pokud neděláte obojí, je třeba to hned teď napravit – přestaňte to číst, stáhněte si skripty Oly Hallengrenové, naplánujte je a ujistěte se, že jste nastavili upozornění. (Další alternativou specifickou pro údržbu indexu, kterou také zákazníkům doporučujeme, je SQL Sentry Fragmentation Manager.)
Pokud nevíte, zda jsou vaše úlohy nastaveny tak, aby vám v případě selhání poslaly e-mail, použijte tento dotaz:
SELECT [Name], [Description] FROM [dbo].[sysjobs] WHERE [enabled] = 1 AND [notify_level_email] NOT IN (2,3) ORDER BY [Name];
Proaktivní přístup k údržbě však jde ještě o krok dále. Kromě toho, že vaše práce běží, musíte vědět, jak dlouho to trvá. Toto můžete sledovat pomocí systémových tabulek v msdb:
SELECT
[j].[name] AS [JobName],
[h].[step_id] AS [StepID],
[h].[step_name] AS [StepName],
CONVERT(CHAR(10), CAST(STR([h].[run_date],8, 0) AS DATETIME), 121) AS [RunDate],
STUFF(STUFF(RIGHT('000000' + CAST ( [h].[run_time] AS VARCHAR(6 ) ) ,6),5,0,':'),3,0,':')
AS [RunTime],
(([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60)
AS [RunDuration_Minutes],
CASE [h].[run_status]
WHEN 0 THEN 'Failed'
WHEN 1 THEN 'Succeeded'
WHEN 2 THEN 'Retry'
WHEN 3 THEN 'Cancelled'
WHEN 4 THEN 'In Progress'
END AS [ExecutionStatus],
[h].[message] AS [MessageGenerated]
FROM [msdb].[dbo].[sysjobhistory] [h]
INNER JOIN [msdb].[dbo].[sysjobs] [j]
ON [h].[job_id] = [j].[job_id]
WHERE [j].[name] = 'DatabaseBackup - SYSTEM_DATABASES – FULL'
AND [step_id] = 0
ORDER BY [RunDate]; Nebo, pokud používáte Oly skripty a informace protokolování, můžete se zeptat na jeho tabulku CommandLog:
SELECT [DatabaseName], [CommandType], [StartTime], [EndTime], DATEDIFF(MINUTE, [StartTime], [EndTime]) AS [Duration_Minutes] FROM [master].[dbo].[CommandLog] WHERE [DatabaseName] = 'AdventureWorks2014' AND [Command] LIKE 'BACKUP DATABASE%' ORDER BY [StartTime];
Výše uvedený skript uvádí trvání zálohování pro každou plnou zálohu pro databázi AdventureWorks2014. Můžete očekávat, že trvání úloh údržby se bude časem pomalu prodlužovat, jak se databáze zvětšují. Jako takový hledáte velké zvýšení nebo neočekávané snížení trvání. Měl jsem například klienta s průměrnou dobou zálohování méně než 30 minut. Najednou začne zálohování trvat déle než hodinu. Databáze se výrazně nezměnila co do velikosti, nezměnila se žádná nastavení pro instanci nebo databázi, nic se nezměnilo s konfigurací hardwaru nebo disku. O několik týdnů později doba zálohování klesla zpět na méně než půl hodiny. Měsíc na to šli znovu nahoru. Nakonec jsme korelovali změnu v trvání zálohování s převzetím služeb při selhání mezi uzly clusteru. Na jednom uzlu zálohování trvalo méně než půl hodiny. Na druhou stranu jim to trvalo přes hodinu. Trochu prozkoumání konfigurace síťových karet a sítě SAN a podařilo se nám určit problém.
Důležité je také pochopení průměrné doby provádění operací CHECKDB. To je něco, o čem Paul mluví v naší události High Availability and Disaster Recovery Immersion Event:musíte vědět, jak dlouho normálně trvá CHECKDB, aby se spustil, takže když zjistíte poškození a spustíte kontrolu celé databáze, víte, jak dlouho by měla trvat pro dokončení CHECKDB. Když se váš šéf zeptá:"Jak dlouho bude trvat, než budeme znát rozsah problému?" budete schopni poskytnout kvantitativní odpověď na minimální dobu, kterou budete muset čekat. Pokud CHECKDB trvá déle než obvykle, pak víte, že se něco našlo (což nemusí být nutně poškození; vždy musíte nechat kontrolu dokončit).
Nyní, pokud spravujete stovky databází, nechcete spouštět výše uvedený dotaz pro každou databázi nebo každou úlohu. Místo toho můžete chtít najít zakázky, které o určité procento nepřekračují průměrnou dobu trvání, což můžete získat pomocí tohoto dotazu:
SELECT
[j].[name] AS [JobName],
[h].[step_id] AS [StepID],
[h].[step_name] AS [StepName],
CONVERT(CHAR(10), CAST(STR([h].[run_date],8, 0) AS DATETIME), 121) AS [RunDate],
STUFF(STUFF(RIGHT('000000' + CAST ( [h].[run_time] AS VARCHAR(6 ) ) ,6),5,0,':'),3,0,':')
AS [RunTime],
(([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60)
AS [RunDuration_Minutes],
[avdur].[Avg_RunDuration_Minutes]
FROM [dbo].[sysjobhistory] [h]
INNER JOIN [dbo].[sysjobs] [j]
ON [h].[job_id] = [j].[job_id]
INNER JOIN
(
SELECT
[j].[name] AS [JobName],
AVG((([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60))
AS [Avg_RunDuration_Minutes]
FROM [dbo].[sysjobhistory] [h]
INNER JOIN [dbo].[sysjobs] [j]
ON [h].[job_id] = [j].[job_id]
WHERE [step_id] = 0
AND CONVERT(DATE, RTRIM(h.run_date)) >= DATEADD(DAY, -60, GETDATE())
GROUP BY [j].[name]
) AS [avdur]
ON [avdur].[JobName] = [j].[name]
WHERE [step_id] = 0
AND (([run_duration]/10000*3600 + ([run_duration]/100)%100*60 + [run_duration]%100 + 31 ) / 60)
> ([avdur].[Avg_RunDuration_Minutes] + ([avdur].[Avg_RunDuration_Minutes] * .25))
ORDER BY [j].[name], [RunDate]; Tento dotaz uvádí úlohy, které trvaly o 25 % déle, než je průměr. Dotaz bude vyžadovat určité úpravy, aby poskytl konkrétní požadované informace – některé úlohy s krátkým trváním (např. méně než 5 minut) se zobrazí, pokud zaberou jen pár minut navíc – to nemusí být problém. Přesto je tento dotaz dobrým začátkem a uvědomte si, že existuje mnoho způsobů, jak najít odchylky – můžete také porovnat každé provedení s předchozím a hledat úlohy, které trvaly o určité procento déle než předchozí.
Trvání úlohy je samozřejmě nejlogičtějším identifikátorem, který lze použít pro potenciální problémy – ať už jde o úlohu zálohování, kontrolu integrity nebo úlohu, která odstraňuje fragmentaci a aktualizuje statistiky. Zjistil jsem, že největší variace v trvání je obvykle v úkolech odstranit fragmentaci a aktualizovat statistiky. V závislosti na vašich prahových hodnotách pro přestavbu versus přestavbu a volatilitě vašich dat můžete dny s většinou přeorganizací a pak se náhle spustí několik přestaveb indexu u velkých stolů, kde tato přestavba zcela změní průměrnou dobu trvání. Možná budete chtít změnit své prahové hodnoty pro některé indexy nebo upravit faktor plnění tak, aby k přestavbám docházelo častěji nebo méně často – v závislosti na indexu a úrovni fragmentace. Chcete-li provést tyto úpravy, musíte se podívat na to, jak často je každý index přestavován nebo reorganizován, což můžete provést pouze tehdy, pokud používáte skripty Oly a přihlašujete se do tabulky CommandLog, nebo pokud jste zavedli vlastní řešení a protokolujete každou reorg nebo přestavbu. Chcete-li se na to podívat pomocí tabulky CommandLog, můžete začít tím, že zkontrolujete, které indexy se mění nejčastěji:
SELECT [DatabaseName], [ObjectName], [IndexName], COUNT(*) FROM [master].[dbo].[CommandLog] [c] WHERE [DatabaseName] = 'AdventureWorks2014' AND [Command] LIKE 'ALTER INDEX%' GROUP BY [DatabaseName], [ObjectName], [IndexName] ORDER BY COUNT(*) DESC;
Z tohoto výstupu můžete začít zjišťovat, které tabulky (a tedy indexy) mají největší volatilitu, a pak určit, zda je třeba upravit práh pro reorganizaci versus přestavbu, nebo zda je třeba upravit faktor plnění.
Usnadnění života
Nyní existuje jednodušší řešení než psaní vlastních dotazů, pokud používáte SQL Sentry Event Manager (EM). Nástroj sleduje všechny úlohy agenta nastavené na instanci a pomocí zobrazení kalendáře můžete rychle zjistit, které úlohy selhaly, byly zrušeny nebo probíhaly déle než obvykle:
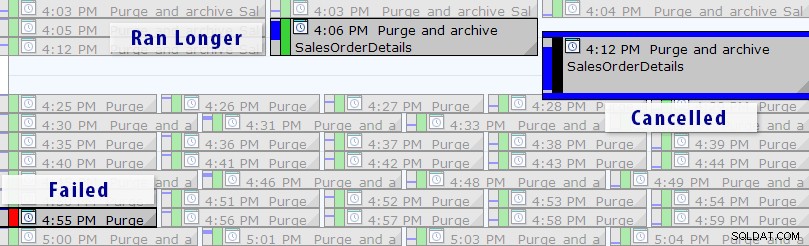 Zobrazení kalendáře SQL Sentry Event Manager (s přidanými štítky ve Photoshopu)
Zobrazení kalendáře SQL Sentry Event Manager (s přidanými štítky ve Photoshopu)
Můžete také procházet jednotlivými provedeními, abyste viděli, jak dlouho trvalo spuštění úlohy, a jsou zde také užitečné grafy za běhu, které vám umožňují rychle vizualizovat jakékoli vzory v anomáliích trvání nebo poruchových stavech. V tomto případě vidím, že každých 15 minut doba běhu této konkrétní úlohy vyskočila téměř o 400 %:
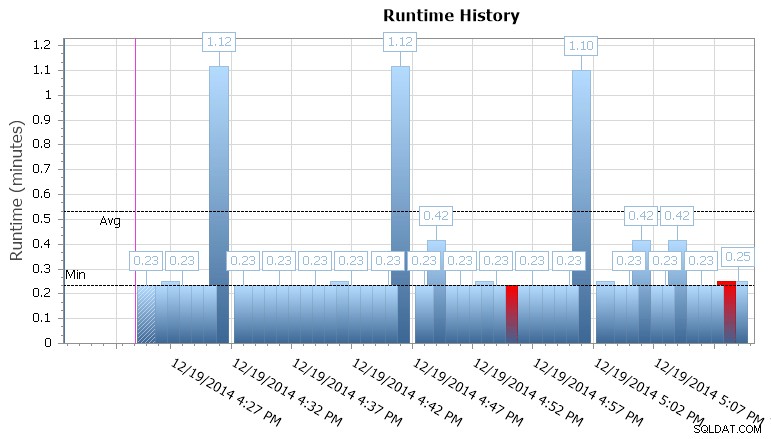 Běhový graf správce událostí SQL Sentry
Běhový graf správce událostí SQL Sentry
To mi dává vodítko, že bych se měl podívat na další naplánované úlohy, které zde mohou způsobovat určité problémy se souběžností. Mohl bych si kalendář znovu oddálit, abych viděl, jaké další úlohy běží ve stejnou dobu, nebo se možná ani nemusím dívat, abych poznal, že se jedná o nějakou reportovací nebo zálohovací úlohu, která běží proti této databázi.
Shrnutí
Vsadil bych se, že většina z vás již má potřebné údržbářské práce na místě a že máte také nastavena upozornění na selhání úloh. Pokud nejste obeznámeni s průměrnou dobou trvání vašich pracovních míst, pak je to váš další krok k tomu, abyste byli proaktivní. Poznámka:Možná budete také muset zkontrolovat, jak dlouho uchováváte historii úloh. Když hledám odchylky v délce trvání zaměstnání, raději se dívám na data za několik měsíců než na několik týdnů. Nemusíte si tyto doby běhu pamatovat, ale jakmile ověříte, že uchováváte dostatek dat, abyste měli historii k použití pro výzkum, pak začněte pravidelně hledat varianty. V ideálním případě vás delší doba běhu může upozornit na potenciální problém, což vám umožní jej vyřešit dříve, než dojde k problému ve vašem produkčním prostředí.