SQL Server 2008 zavedl řídké sloupce jako metodu, jak snížit úložiště pro hodnoty null a poskytnout rozšiřitelnější schémata. Kompromisem je, že při ukládání a načítání hodnot, které nejsou NULL, vzniká další režie. Po rozhovoru se zákazníkem, který používal tento datový typ ve zkušebním prostředí, mě zajímaly náklady na ukládání hodnot, které nejsou NULL. Chtějí optimalizovat výkon zápisu a zajímalo by mě, zda má použití řídkých sloupců nějaký účinek, protože jejich metoda vyžadovala vložení řádku do tabulky a jeho aktualizaci. Vytvořil jsem pro toto demo příklad vysvětlený níže, abych zjistil, zda je to pro ně dobrá metodika.
Interní kontrola
Pro rychlý přehled si pamatujte, že když vytvoříte sloupec pro tabulku, která umožňuje hodnoty NULL, pokud se jedná o sloupec s pevnou délkou (např. INT), vždy zabere celou šířku sloupce na stránce, i když je sloupec NULA. Pokud se jedná o sloupec s proměnnou délkou (např. VARCHAR), při hodnotě NULL spotřebuje alespoň dva bajty v poli posunu sloupců, pokud nejsou sloupce za posledním naplněným sloupcem (viz příspěvek na blogu Kimberly Na pořadí sloupců nezáleží...obecně , ale – ZÁLEŽÍ). Řídký sloupec nevyžaduje na stránce žádné místo pro hodnoty NULL, ať už se jedná o sloupec s pevnou délkou nebo proměnnou délkou, a bez ohledu na to, jaké další sloupce jsou v tabulce vyplněny. Kompromisem je, že když je naplněn řídký sloupec, zabírá o čtyři (4) více bajtů úložiště než neřídký sloupec. Například:
| Typ sloupce | Požadavek na úložiště |
|---|---|
| Sloupec BIGINT, neřídký, s ne hodnota | 8 bajtů |
| Sloupec BIGINT, neřídký, s hodnotu | 8 bajtů |
| VELKÝ sloupec, řídký, s ne hodnota | 0 bajtů |
| BIGINT sloupec, řídký, s hodnotu | 12 bajtů |
Proto je nezbytné potvrdit, že přínos úložiště převáží potenciální zásah do výkonu při načítání – který může být zanedbatelný na základě rovnováhy čtení a zápisů oproti datům. Odhadovaná úspora místa pro různé typy dat je zdokumentována ve výše uvedeném odkazu Books Online.
Testovací scénáře
Pro testování jsem nastavil čtyři různé scénáře popsané níže a každá tabulka měla sloupec ID (INT), sloupec Název (VARCHAR(100) a sloupec Typ (INT) a poté 997 sloupců s NULLABLE.
| ID testu | Popis tabulky | Operace DML |
|---|---|---|
| 1 | 997 sloupců datového typu INT, NULLABLE, non-sparse | Vkládejte jeden řádek po druhém, vyplňte ID, Název, Typ a deset (10) náhodných sloupců s hodnotou Null |
| 2 | 997 sloupců datového typu INT, NULLABLE, sparse | Vkládejte jeden řádek po druhém, vyplňte ID, Název, Typ a deset (10) náhodných sloupců s hodnotou Null |
| 3 | 997 sloupců datového typu INT, NULLABLE, non-sparse | Vkládejte jeden řádek po druhém, vyplňte pouze ID, Název, Typ, poté aktualizujte řádek přidáním hodnot pro deset (10) náhodných sloupců s hodnotou NULLABLE |
| 4 | 997 sloupců datového typu INT, NULLABLE, sparse | Vkládejte jeden řádek po druhém, vyplňte pouze ID, Název, Typ, poté aktualizujte řádek přidáním hodnot pro deset (10) náhodných sloupců s hodnotou NULLABLE |
| 5 | 997 sloupců datového typu VARCHAR, NULLABLE, non-sparse | Vkládejte jeden řádek po druhém, vyplňte ID, Název, Typ a deset (10) náhodných sloupců s hodnotou Null |
| 6 | 997 sloupců datového typu VARCHAR, NULLABLE, sparse | Vkládejte jeden řádek po druhém, vyplňte ID, Název, Typ a deset (10) náhodných sloupců s hodnotou Null |
| 7 | 997 sloupců datového typu VARCHAR, NULLABLE, non-sparse | Vkládejte jeden řádek po druhém, vyplňte pouze ID, Název, Typ, poté aktualizujte řádek přidáním hodnot pro deset (10) náhodných sloupců s hodnotou NULLABLE |
| 8 | 997 sloupců datového typu VARCHAR, NULLABLE, sparse | Vkládejte jeden řádek po druhém, vyplňte pouze ID, Název, Typ, poté aktualizujte řádek přidáním hodnot pro deset (10) náhodných sloupců s hodnotou NULLABLE |
Každý test byl proveden dvakrát se sadou dat 10 milionů řádků. Přiložené skripty lze použít k replikaci testování a kroky byly pro každý test následující:
- Vytvořte novou databázi s předem nastavenými daty a soubory protokolů
- Vytvořte příslušnou tabulku
- Snímek statistik čekání a statistiky souborů
- Poznamenejte si čas zahájení
- Spustit DML (jedna vložka nebo jedna vložka a jedna aktualizace) pro 10 milionů řádků
- Poznamenejte si čas zastavení
- Snímejte statistiky čekání a statistiky souborů a zapisujte je do protokolovací tabulky v samostatné databázi na samostatném úložišti
- Snímek dm_db_index_physical_stats
- Zrušte databázi
Testování bylo provedeno na Dell PowerEdge R720 s 64 GB paměti a 12 GB přidělených instanci SQL Server 2014 SP1 CU4. Pro ukládání dat databázových souborů byly použity Fusion-IO SSD.
Výsledky
Výsledky testů jsou uvedeny níže pro každý testovací scénář.
Trvání
Ve všech případech trvalo méně času (průměrně 11,6 minut) naplnění tabulky, když byly použity řídké sloupce, i když byl řádek nejprve vložen a poté aktualizován. Když byl řádek poprvé vložen a poté aktualizován, test trval téměř dvakrát déle než při vložení řádku, protože bylo provedeno dvakrát tolik úprav dat.
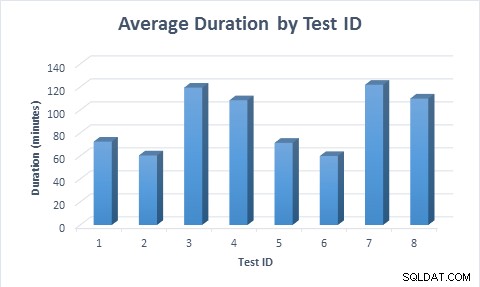 Průměrná doba trvání každého testovacího scénáře
Průměrná doba trvání každého testovacího scénáře
Statistika čekání
| ID testu | Průměrné procento | Průměrné čekání (v sekundách) |
|---|---|---|
| 1 | 16,47 | 0,0001 |
| 2 | 14:00 | 0,0001 |
| 3 | 16,65 | 0,0001 |
| 4 | 15.07 | 0,0001 |
| 5 | 12,80 | 0,0001 |
| 6 | 13,99 | 0,0001 |
| 7 | 14,85 | 0,0001 |
| 8 | 15.02 | 0,0001 |
Statistiky čekání byly konzistentní pro všechny testy a na základě těchto údajů nelze dělat žádné závěry. Hardware dostatečně vyhovoval nárokům na zdroje ve všech testovacích případech.
Statistika souborů
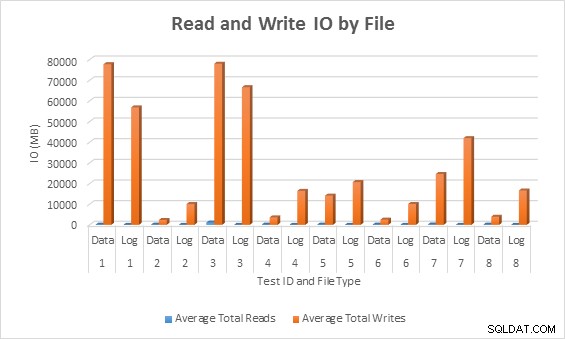 Průměrná IO (čtení a zápis) na databázový soubor
Průměrná IO (čtení a zápis) na databázový soubor
Ve všech případech testy s řídkými sloupci generovaly méně IO (zejména zápisů) ve srovnání s neřídkými sloupci.
Index fyzické statistiky
| Testovací případ | Počet řádků | Celkový počet stránek (shlukovaný index) | Celkový prostor (GB) | Průměrný prostor použitý pro listové stránky v CI (%) | Průměrná velikost záznamu (bajty) |
|---|---|---|---|---|---|
| 1 | 10 000 000 | 10 037 312 | 76 | 51,70 | 4 184,49 |
| 2 | 10 000 000 | 301 429 | 2 | 98,51 | 237,50 |
| 3 | 10 000 000 | 10 037 312 | 76 | 51,70 | 4 184,50 |
| 4 | 10 000 000 | 460 960 | 3 | 64,41 | 237,50 |
| 5 | 10 000 000 | 1 823 083 | 13 | 90,31 | 1 326,08 |
| 6 | 10 000 000 | 324 162 | 2 | 98,40 | 255,28 |
| 7 | 10 000 000 | 3 161 224 | 24 | 52,09 | 1 326,39 |
| 8 | 10 000 000 | 503 592 | 3 | 63,33 | 255,28 |
Mezi řídkými a řídkými tabulkami existují značné rozdíly ve využití prostoru. To je nejpozoruhodnější při pohledu na testovací případy 1 a 3, kde byl použit datový typ s pevnou délkou (INT), ve srovnání s testovacími případy 5 a 7, kde byl použit datový typ s proměnnou délkou (VARCHAR(255)). Celočíselné sloupce zabírají místo na disku, i když jsou NULL. Sloupce s proměnnou délkou zabírají méně místa na disku, protože v poli offsetu pro sloupce NULL se používají pouze dva bajty a žádné bajty pro sloupce NULL, které jsou za posledním naplněným sloupcem v řádku.
Dále proces vložení řádku a jeho aktualizace způsobí fragmentaci pro test sloupců s proměnnou délkou (případ 7) ve srovnání s prostým vložením řádku (případ 5). Velikost tabulky se téměř zdvojnásobí, když po vložení následuje aktualizace, kvůli rozdělení stránek, ke kterým dochází při aktualizaci řádků, a stránky tak zůstávají z poloviny plné (oproti 90 % plné).
Shrnutí
Závěrem lze říci, že při použití řídkých sloupců vidíme výrazné snížení místa na disku a vstupů a výstupů a v našich jednoduchých testech modifikace dat si vedou o něco lépe než neřídké sloupce (všimněte si, že je třeba vzít v úvahu také výkon načítání; možná předmět jiného příspěvek).
Řídké sloupce mají velmi specifický scénář použití a je důležité prozkoumat množství ušetřeného místa na disku na základě datového typu pro sloupec a počtu sloupců, které budou obvykle v tabulce vyplněny. V našem příkladu jsme měli 997 řídkých sloupců a naplnili jsme pouze 10 z nich. V případě, kdy byl použitý datový typ celé číslo, by řádek na úrovni listu seskupeného indexu spotřeboval maximálně 188 bajtů (4 bajty pro ID, maximálně 100 bajtů pro název, 4 bajty pro typ a pak 80 bajtů pro 10 sloupců). Když bylo 997 sloupců neřídkých, pak byly pro každý sloupec přiděleny 4 bajty, i když NULL, takže každý řádek měl na úrovni listu alespoň 4 000 bajtů. V našem scénáři jsou řídké sloupce naprosto přijatelné. Ale pokud naplníme 500 nebo více řídkých sloupců hodnotami pro sloupec INT, pak dojde ke ztrátě úspory místa a výkon úprav již nemusí být lepší.
V závislosti na typu dat pro vaše sloupce a očekávaném počtu sloupců, které mají být naplněny z celkového počtu, možná budete chtít provést podobné testování, abyste zajistili, že při použití řídkých sloupců bude výkon vkládání a úložiště srovnatelné nebo lepší než při použití ne -řídké sloupce. V případech, kdy nejsou naplněny všechny sloupce, rozhodně stojí za zvážení řídké sloupce.