Minulý týden jsem provedl několik rychlých srovnání výkonu a postavil jsem nové STRING_AGG() funkce proti tradiční FOR XML PATH přístup, který používám věky. Testoval jsem jak nedefinované/libovolné pořadí, tak i explicitní pořadí a STRING_AGG() vyšel v obou případech na vrcholu:
- SQL Server v. Další:STRING_AGG() Výkon, část 1
U těchto testů jsem vynechal několik věcí (ne všechny záměrně):
- Mikael Eriksson a Grzegorz Łyp poukázali na to, že nepoužívám absolutně nejúčinnější
FOR XML PATHkonstruovat (a aby bylo jasno, nikdy jsem to neudělal). - Neprováděl jsem žádné testy na Linuxu; pouze na Windows. Neočekávám, že se budou výrazně lišit, ale protože Grzegorz viděl velmi odlišná trvání, stojí za to to dále prozkoumat.
- Testoval jsem také pouze tehdy, když výstupem bude konečný řetězec bez LOB – což je podle mého názoru nejběžnější případ použití (nemyslím si, že by lidé běžně zřetězovali každý řádek v tabulce do jednoho čárkou odděleného řetězec, ale proto jsem se ve svém předchozím příspěvku zeptal na vaše případy použití).
- Pro testy řazení jsem nevytvořil index, který by mohl být užitečný (ani nezkoušel nic, kde by všechna data pocházela z jediné tabulky).
V tomto příspěvku se budu zabývat několika z těchto položek, ale ne všemi.
PRO CESTA XML
Používal jsem následující:
... FOR XML PATH, TYPE).value(N'.[1]', ...
Po tomto komentáři od Mikaela jsem aktualizoval svůj kód, aby místo toho používal tento mírně odlišný konstrukt:
... FOR XML PATH(''), TYPE).value(N'text()[1]', ... Linux vs. Windows
Zpočátku jsem se pouze obtěžoval spustit testy na Windows:
Microsoft SQL Server vNext (CTP1.1) - 14.0.100.187 (X64) Dec 10 2016 02:51:11 Copyright (C) 2016 Microsoft Corporation. All rights reserved. Developer Edition (64-bit) on Windows Server 2016 Datacenter 6.3(Build 14393: ) (Hypervisor)
Ale Grzegorz řekl spravedlivě, že on (a pravděpodobně mnoho dalších) měl přístup pouze k Linuxové verzi CTP 1.1. Takže jsem do své testovací matrice přidal Linux:
Microsoft SQL Server vNext (CTP1.1) - 14.0.100.187 (X64) Dec 10 2016 02:51:11 Copyright (C) 2016 Microsoft Corporation. All rights reserved. on Linux (Ubuntu 16.04.1 LTS)
Několik zajímavých, ale zcela tečných postřehů:
@@VERSIONv tomto sestavení nezobrazuje vydání, aleSERVERPROPERTY('Edition')vrátí očekávanouDeveloper Edition (64-bit).- Na základě doby sestavení zakódované do binárních souborů se zdá, že verze pro Windows a Linux jsou nyní kompilovány ve stejnou dobu a ze stejného zdroje. Nebo to byla jedna šílená náhoda.
Neuspořádané testy
Začal jsem testováním libovolně uspořádaného výstupu (kde není explicitně definované řazení pro zřetězené hodnoty). Po Grzegorzovi jsem použil WideWorldImporters (Standard), ale provedl jsem spojení mezi Sales.Orders a Sales.OrderLines . Smyšleným požadavkem je zde vytisknout seznam všech objednávek a spolu s každou objednávkou i seznam každého StockItemID .
Od StockItemID je celé číslo, můžeme použít definovaný varchar , což znamená, že řetězec může mít 8000 znaků, než se budeme muset starat o to, že potřebujeme MAX. Protože int může mít maximální délku 11 (skutečně 10, pokud není podepsáno) plus čárku, znamená to, že objednávka by v nejhorším případě musela podporovat asi 8 000/12 (666) skladových položek (např. všechny hodnoty StockItemID mají 11 číslic). V našem případě je nejdelší ID 3 číslice, takže dokud nebudou přidána data, budeme ve skutečnosti potřebovat 8 000/4 (2 000) jedinečných skladových položek v každé jednotlivé objednávce, abychom ospravedlnili MAX. V našem případě je celkem pouze 227 skladových položek, takže MAX není nutný, ale měli byste si to hlídat. Pokud je ve vašem scénáři možný tak velký řetězec, budete muset použít varchar(max) místo výchozího (STRING_AGG() vrátí nvarchar(max) , ale zkrátí se na 8 000 bajtů, pokud není vstup je typu MAX).
Počáteční dotazy (k zobrazení ukázkového výstupu a ke sledování trvání jednotlivých spuštění):
SET STATISTICS TIME ON;
GO
SELECT o.OrderID, StockItemIDs = STRING_AGG(ol.StockItemID, ',')
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO
SELECT o.OrderID,
StockItemIDs = STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,'')
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO
SET STATISTICS TIME OFF;
/*
Sample output:
OrderID StockItemIDs
======= ============
1 67
2 50,10
3 114
4 206,130,50
5 128,121,155
Important SET STATISTICS TIME metrics (SQL Server Execution Times):
Windows:
STRING_AGG: CPU time = 217 ms, elapsed time = 405 ms.
FOR XML PATH: CPU time = 1954 ms, elapsed time = 2097 ms.
Linux:
STRING_AGG: CPU time = 627 ms, elapsed time = 472 ms.
FOR XML PATH: CPU time = 2188 ms, elapsed time = 2223 ms.
*/
Úplně jsem ignoroval analýzu a kompilaci časových údajů, protože byly vždy přesně nulové nebo dostatečně blízko, aby byly irelevantní. U každého běhu byly drobné odchylky v dobách provádění, ale ne moc – výše uvedené komentáře odrážejí typický rozdíl v běhovém prostředí (STRING_AGG Zdálo se, že tam trochu využívá paralelismus, ale pouze na Linuxu, zatímco FOR XML PATH ne na žádné platformě). Oba stroje měly jednu patici, přidělený čtyřjádrový procesor, 8 GB paměti, přednastavenou konfiguraci a žádnou jinou aktivitu.
Pak jsem chtěl testovat ve velkém měřítku (jednoduše jedna relace, která provedla stejný dotaz 500krát). Nechtěl jsem vrátit celý výstup, jako ve výše uvedeném dotazu, 500krát, protože by to přemohlo SSMS – a doufejme, že to stejně nepředstavuje scénáře dotazů v reálném světě. Takže jsem přiřadil výstup k proměnným a jen změřil celkový čas pro každou dávku:
SELECT sysdatetime();
GO
DECLARE @i int, @x varchar(8000);
SELECT @i = o.OrderID, @x = STRING_AGG(ol.StockItemID, ',')
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime();
GO
DECLARE @i int, @x varchar(8000);
SELECT @i = o.OrderID,
@x = STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,'')
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime(); Provedl jsem tyto testy třikrát a rozdíl byl hluboký – téměř o řád. Zde je průměrná doba trvání všech tří testů:
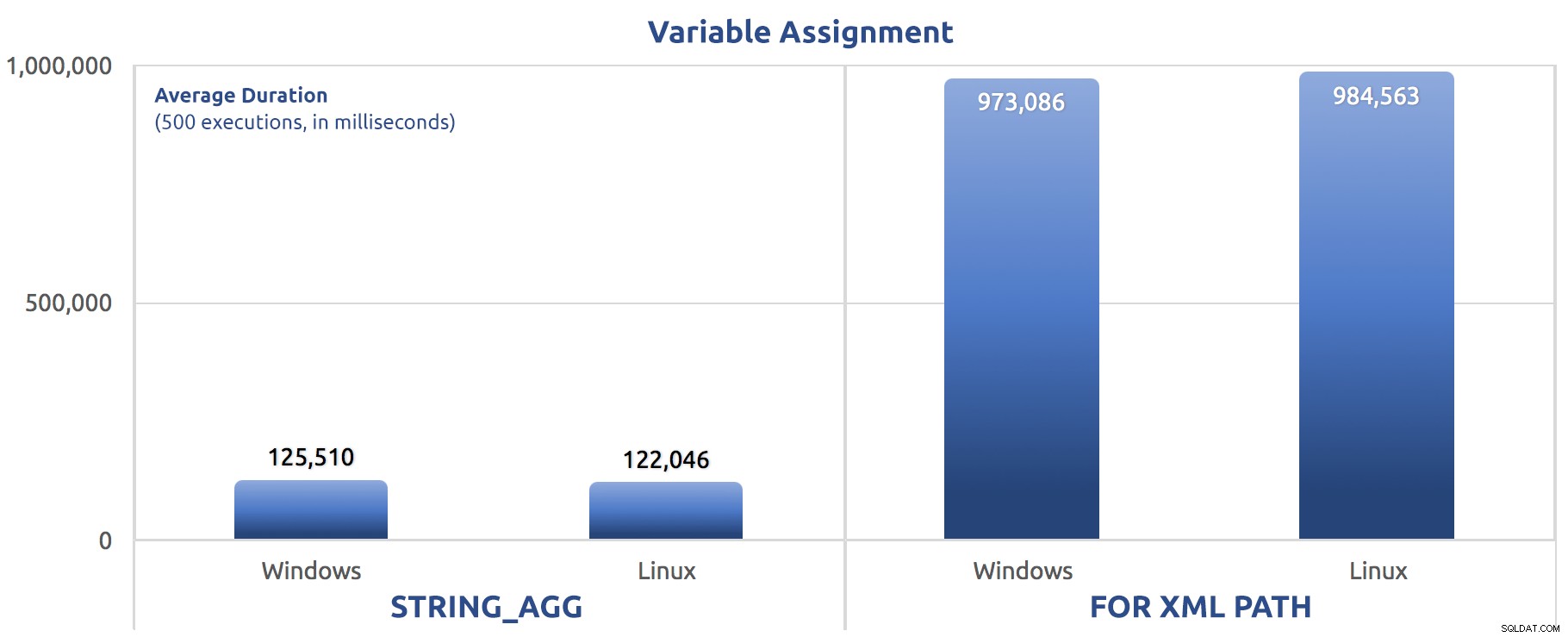 Průměrná doba trvání v milisekundách pro 500 provedení přiřazení proměnné
Průměrná doba trvání v milisekundách pro 500 provedení přiřazení proměnné
Tímto způsobem jsem také testoval řadu dalších věcí, většinou proto, abych se ujistil, že pokrývám typy testů, které Grzegorz spouštěl (bez části LOB).
- Výběr pouze délky výstupu
- Získání maximální délky výstupu (libovolného řádku)
- Výběr veškerého výstupu do nové tabulky
Výběr pouze délky výstupu
Tento kód pouze projde každou objednávkou, zřetězí všechny hodnoty StockItemID a poté vrátí pouze délku.
SET STATISTICS TIME ON;
GO
SELECT LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO
SELECT LEN(STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO
SET STATISTICS TIME OFF;
/*
Windows:
STRING_AGG: CPU time = 142 ms, elapsed time = 351 ms.
FOR XML PATH: CPU time = 1984 ms, elapsed time = 2120 ms.
Linux:
STRING_AGG: CPU time = 310 ms, elapsed time = 191 ms.
FOR XML PATH: CPU time = 2149 ms, elapsed time = 2167 ms.
*/ Pro dávkovou verzi jsem opět použil přiřazení proměnných, spíše než abych se snažil vrátit mnoho sad výsledků do SSMS. Přiřazení proměnné by skončilo na libovolném řádku, ale to stále vyžaduje úplné skenování, protože libovolný řádek není vybrán jako první.
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = LEN(STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime(); Metriky výkonu 500 spuštění:
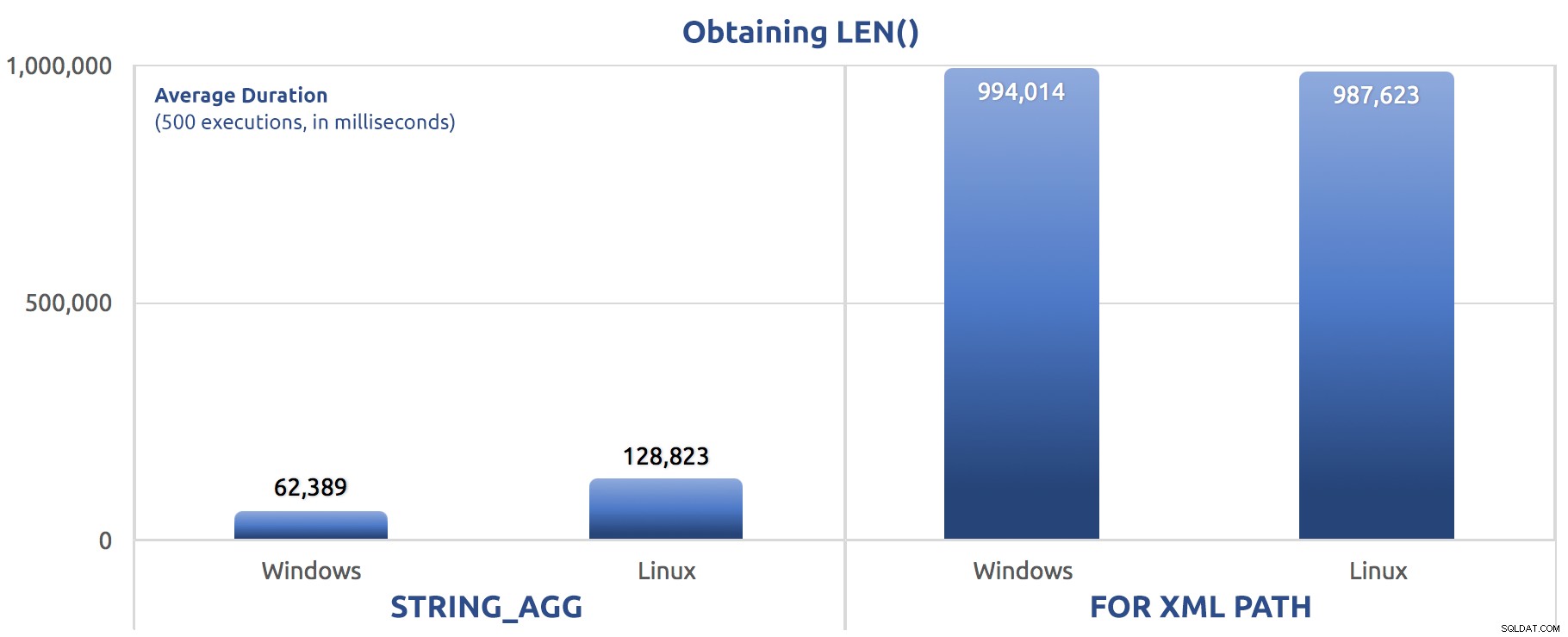 500 spuštění přiřazení LEN() k proměnné
500 spuštění přiřazení LEN() k proměnné
Opět vidíme FOR XML PATH je mnohem pomalejší, na Windows i Linuxu.
Výběr maximální délky výstupu
Mírná variace na předchozí test, tento pouze načítá maximum délka zřetězeného výstupu:
SET STATISTICS TIME ON;
GO
SELECT MAX(s) FROM (SELECT s = LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID) AS x;
GO
SELECT MAX(s) FROM (SELECT s = LEN(STUFF(
(SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),
1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID) AS x;
GO
SET STATISTICS TIME OFF;
/*
Windows:
STRING_AGG: CPU time = 188 ms, elapsed time = 48 ms.
FOR XML PATH: CPU time = 1891 ms, elapsed time = 907 ms.
Linux:
STRING_AGG: CPU time = 270 ms, elapsed time = 83 ms.
FOR XML PATH: CPU time = 2725 ms, elapsed time = 1205 ms.
*/ A ve velkém měřítku tento výstup opět přiřadíme proměnné:
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = MAX(s) FROM (SELECT s = LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID) AS x;
GO 500
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = MAX(s) FROM (SELECT s = LEN(STUFF
(
(SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),
1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID) AS x;
GO 500
SELECT sysdatetime(); Výsledky výkonu pro 500 spuštění, zprůměrované ve třech spuštěních:
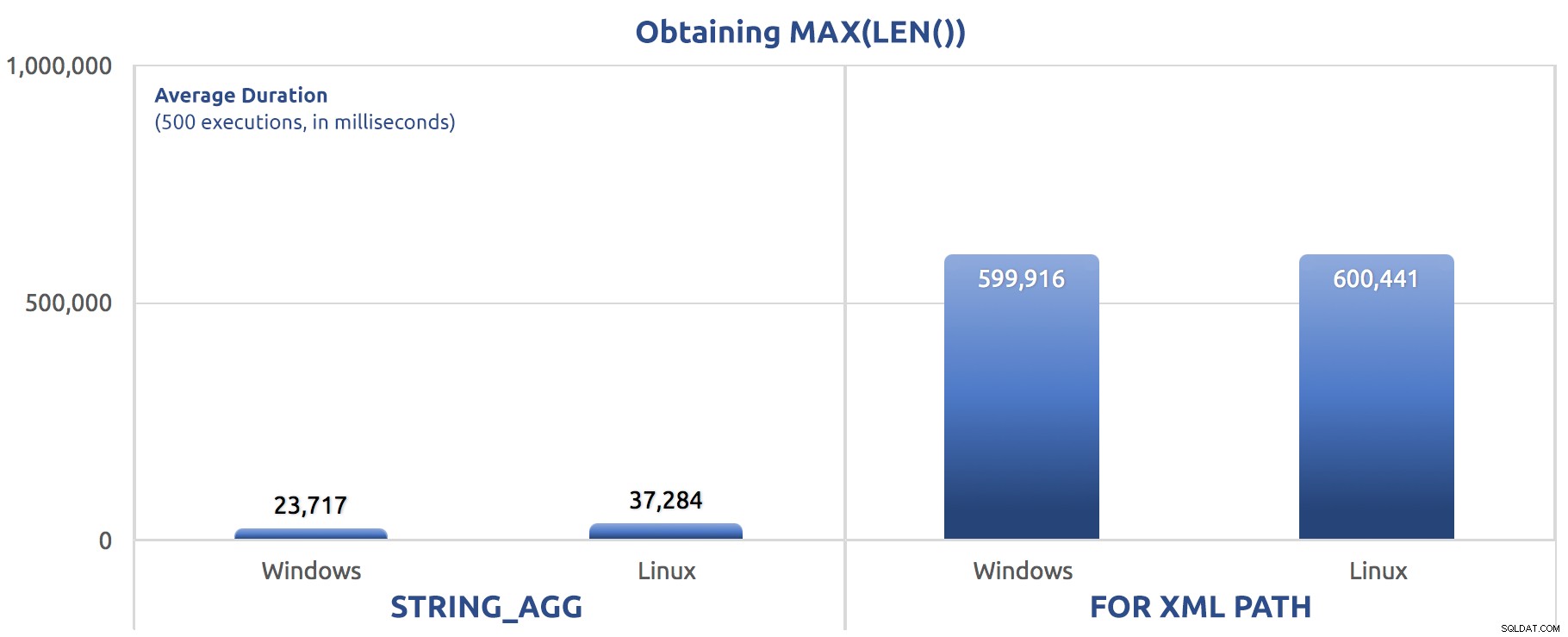 500 spuštění přiřazení MAX(LEN()) k proměnné
500 spuštění přiřazení MAX(LEN()) k proměnné
Můžete si v těchto testech všimnout určitého vzoru – FOR XML PATH je vždy pes, dokonce i se zlepšením výkonu navrženým v mém předchozím příspěvku.
VYBRAT DO
Chtěl jsem zjistit, zda má metoda zřetězení nějaký vliv na psaní data zpět na disk, jak je tomu v některých jiných scénářích:
SET NOCOUNT ON;
GO
SET STATISTICS TIME ON;
GO
DROP TABLE IF EXISTS dbo.HoldingTank_AGG;
SELECT o.OrderID, x = STRING_AGG(ol.StockItemID, ',')
INTO dbo.HoldingTank_AGG
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO
DROP TABLE IF EXISTS dbo.HoldingTank_XML;
SELECT o.OrderID, x = STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,'')
INTO dbo.HoldingTank_XML
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO
SET STATISTICS TIME OFF;
/*
Windows:
STRING_AGG: CPU time = 218 ms, elapsed time = 90 ms.
FOR XML PATH: CPU time = 4202 ms, elapsed time = 1520 ms.
Linux:
STRING_AGG: CPU time = 277 ms, elapsed time = 108 ms.
FOR XML PATH: CPU time = 4308 ms, elapsed time = 1583 ms.
*/
V tomto případě vidíme, že možná SELECT INTO dokázal využít trochu paralelismu, ale přesto vidíme FOR XML PATH bojují s běhovými dobami řádově delšími než STRING_AGG .
Dávková verze právě vyměnila příkazy SET STATISTICS za SELECT sysdatetime(); a přidal stejný GO 500 po dvou hlavních várkách jako u předchozích testů. Zde je návod, jak to dopadlo (opět mi řekněte, jestli jste to už někdy slyšeli):
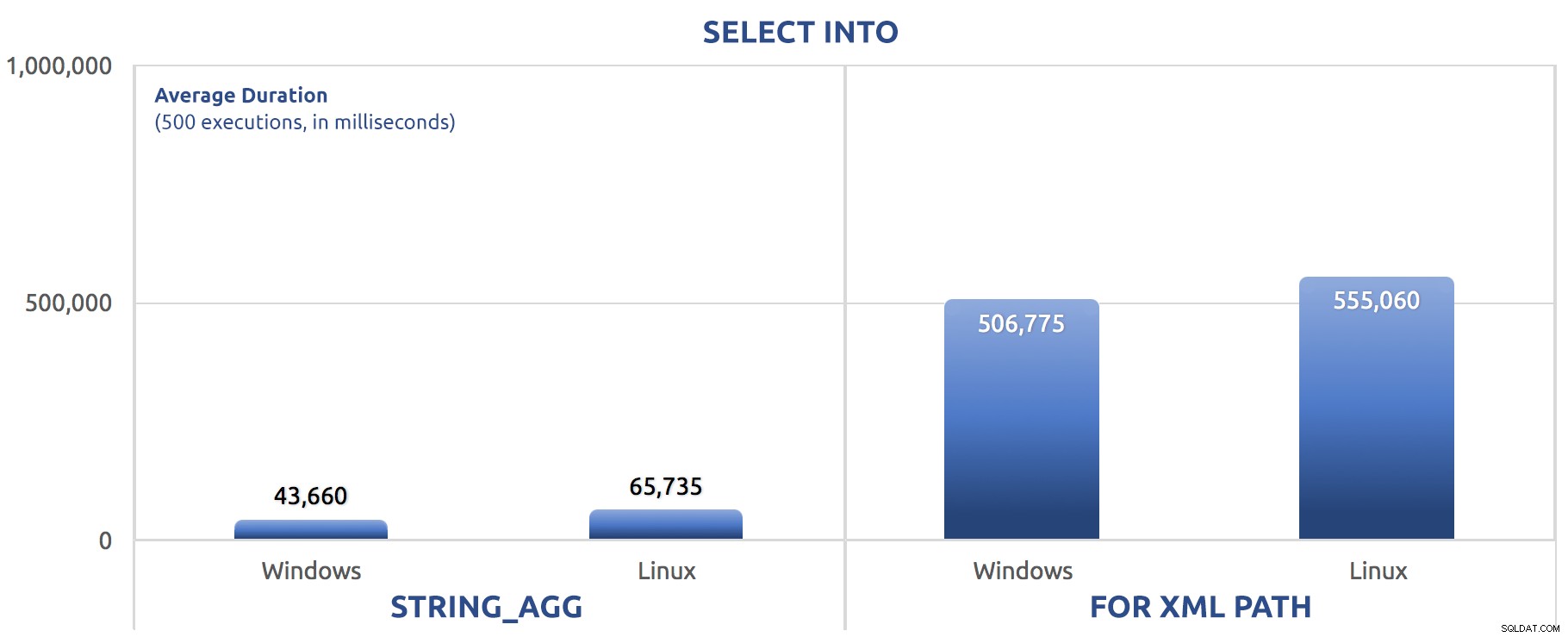 500 spuštění SELECT INTO
500 spuštění SELECT INTO
Objednané testy
Provedl jsem stejné testy pomocí uspořádané syntaxe, např.:
... STRING_AGG(ol.StockItemID, ',')
WITHIN GROUP (ORDER BY ol.StockItemID) ...
... WHERE ol.OrderID = o.OrderID
ORDER BY ol.StockItemID
FOR XML PATH('') ... To mělo jen velmi malý dopad na cokoli – stejná sada čtyř testovacích zařízení vykazovala téměř identické metriky a vzory napříč všemi hranicemi.
Budu zvědavý, jestli se to liší, když je zřetězený výstup v non-LOB nebo kde zřetězení potřebuje seřadit řetězce (s nebo bez podpůrného indexu).
Závěr
Pro řetězce jiné než LOB , je mi jasné, že STRING_AGG má definitivní výkonnostní výhodu oproti FOR XML PATH , na Windows i Linuxu. Všimněte si, že abyste se vyhnuli požadavku varchar(max) nebo nvarchar(max) , nepoužil jsem nic podobného testům, které provedl Grzegorz, což by znamenalo jednoduše zřetězit všechny hodnoty ze sloupce přes celou tabulku do jednoho řetězce. V mém dalším příspěvku se podívám na případ použití, kdy by výstup zřetězeného řetězce mohl být větší než 8 000 bajtů, a tak by se musely používat typy LOB a konverze.