Zatímco SQL Server na Linuxu ukradl téměř všechny titulky o v.Next, v další verzi naší oblíbené databázové platformy přichází několik dalších zajímavých vylepšení. Na frontě T-SQL máme konečně vestavěný způsob, jak provádět seskupené zřetězení řetězců:STRING_AGG() .
Řekněme, že máme následující jednoduchou strukturu tabulky:
CREATE TABLE dbo.Objects( [id_objektu] int, [jméno_objektu] nvarchar(261), CONSTRAINT PK_Objects PRIMARY KEY([id_objektu])); CREATE TABLE dbo.Columns( [id_objektu] int NOT NULL ODKAZY NA CIZÍ KLÍČ dbo.Objects([id_objektu]), název_sloupce sysname, CONSTRAINT PRIMÁRNÍ KLÍČ PK_Columns ([id_objektu], název_sloupce));
Pro testy výkonu to naplníme pomocí sys.all_objects a sys.all_columns . Ale pro jednoduchou ukázku nejprve přidejte následující řádky:
INSERT dbo.Objects([id_objektu],[jméno_objektu]) VALUES(1,N'Employees'),(2,N'Orders'); INSERT dbo.Columns([id_objektu],název_sloupce) VALUES(1,N'ID zaměstnance'),(1,N'CurrentStatus'), (2,N'ID objednávky'),(2,N'Datum objednávky'),(2 ,N'CustomerID');
Pokud jsou fóra nějakým náznakem, je velmi častým požadavkem vrátit řádek pro každý objekt spolu se seznamem názvů sloupců oddělených čárkami. (Extrapolujte to na jakékoli typy entit, které tímto způsobem modelujete – názvy produktů spojené s objednávkou, názvy dílů zapojených do sestavování produktu, podřízení podřízení vedoucímu atd.) Takže například s výše uvedenými údaji bychom chcete výstup takto:
sloupce objektu--------- ----------------------------Zaměstnanci ČísloZaměstnance, Aktuální stavObjednávky ID objednávky, Datum objednávky, Číslo zákazníka
Způsob, jakým bychom toho dosáhli v aktuálních verzích SQL Serveru, je pravděpodobně použití FOR XML PATH , jak jsem v tomto dřívějším příspěvku ukázal, že je nejúčinnější mimo CLR. V tomto příkladu by to vypadalo takto:
SELECT [object] =o.[object_name], [columns] =STUFF( (SELECT N',' + c.column_name FROM dbo.Columns AS c WHERE c.[id_objektu] =o.[id_objektu] PRO XML PATH, TYPE ).value(N'.[1]',N'nvarchar(max)'),1,1,N'')FROM dbo.Objects AS o;
Předvídatelně dostaneme stejný výstup ukázaný výše. V SQL Server v.Next to budeme moci vyjádřit jednodušeji:
SELECT [object] =o.[object_name], [columns] =STRING_AGG(c.column_name, N',')FROM dbo.Objects AS OINNER JOIN dbo.Columns AS cON o.[id_object] =c.[ object_id]GROUP BY o.[object_name];
Opět to vytváří přesně stejný výstup. A dokázali jsme to udělat pomocí nativní funkce, čímž jsme se vyhnuli drahému FOR XML PATH lešení a STUFF() funkce použitá k odstranění první čárky (to se děje automaticky).
A co Objednávka?
Jedním z problémů mnoha složitých řešení seskupeného zřetězení je to, že řazení seznamu odděleného čárkami by mělo být považováno za libovolné a nedeterministické.
Pro XML PATH řešení jsem v jiném dřívějším příspěvku ukázal, že přidání ORDER BY je triviální a zaručený. V tomto příkladu bychom tedy mohli seřadit seznam sloupců podle názvu sloupce abecedně, místo abychom jej ponechali na SQL Server, aby jej seřadil (nebo ne):
SELECT [object] =[object_name], [columns] =STUFF( (SELECT N',' +c.column_name FROM dbo.Columns AS c WHERE c.[id_objektu] =o.[id_objektu] ORDER BY c. název_sloupce -- změnit pouze PRO CESTA XML, TYP ).value(N'.[1]',N'nvarchar(max)'),1,1,N'')FROM dbo.Objects AS o;
Výstup:
sloupce objektů--------- ----------------------------Zaměstnanci Aktuální stav,ZaměstnanecIDOobjednávky Číslo zákazníka,Datum objednávky, ID objednávky
CTP 1.1 přidává WITHIN GROUP na STRING_AGG() , takže pomocí nového přístupu můžeme říci:
SELECT [object] =o.[object_name], [columns] =STRING_AGG(c.column_name, N',') WITHIN GROUP (ORDER BY c.column_name) -- only changeFROM dbo.Objects AS OINNER JOIN dbo. Sloupce JAKO cON o.[id_objektu] =c.[id_objektu]GROUP BY o.[jméno_objektu];
Nyní dostáváme stejné výsledky. Všimněte si, že stejně jako normální ORDER BY klauzule, můžete přidat více sloupců nebo výrazů řazení uvnitř WITHIN GROUP () .
Dobře, výkon již!
Pomocí čtyřjádrových 2,6 GHz procesorů, 8 GB paměti a SQL Serveru CTP1.1 (14.0.100.187) jsem vytvořil novou databázi, znovu vytvořil tyto tabulky a přidal řádky z sys.all_objects a sys.all_columns . Ujistil jsem se, že zahrnu pouze objekty, které mají alespoň jeden sloupec:
INSERT dbo.Objects([id_objektu], [jméno_objektu]) -- 656 řádků SELECT [id_objektu], QUOTENAME(jméno) + N'.' + CITÁTNÍ NÁZEV(o.name) ZE sys.all_objects JAKO o VNITŘNÍ PŘIPOJENÍ k sys.schemas JAKO s ON o.[schéma_id] =s.[schéma_id] KDE EXISTUJE ( VYBERTE 1 Z sys.all_columns WHERE [id_objektu] =o.[id_objektu ]); INSERT dbo.Columns([id_objektu], název_sloupce) -- 8 085 řádků SELECT [id_objektu], název FROM sys.all_columns JAKO c WHERE EXISTS ( SELECT 1 FROM dbo.Objects WHERE [id_objektu] =c.[id_objektu] );V mém systému to poskytlo 656 objektů a 8 085 sloupců (váš systém může poskytnout mírně odlišná čísla).
Plány
Nejprve porovnejme plány a karty I/O tabulky pro naše dva neuspořádané dotazy pomocí Průzkumníka plánů. Zde jsou celkové metriky za běhu:
Běhové metriky pro XML PATH (nahoře) a STRING_AGG() (dole)
Grafický plán a tabulka I/O z
FOR XML PATHdotaz:
Plán a tabulka I/O pro XML PATH, bez objednávky
A z
STRING_AGGverze:
Plán a tabulka I/O za STRING_AGG, bez objednávání
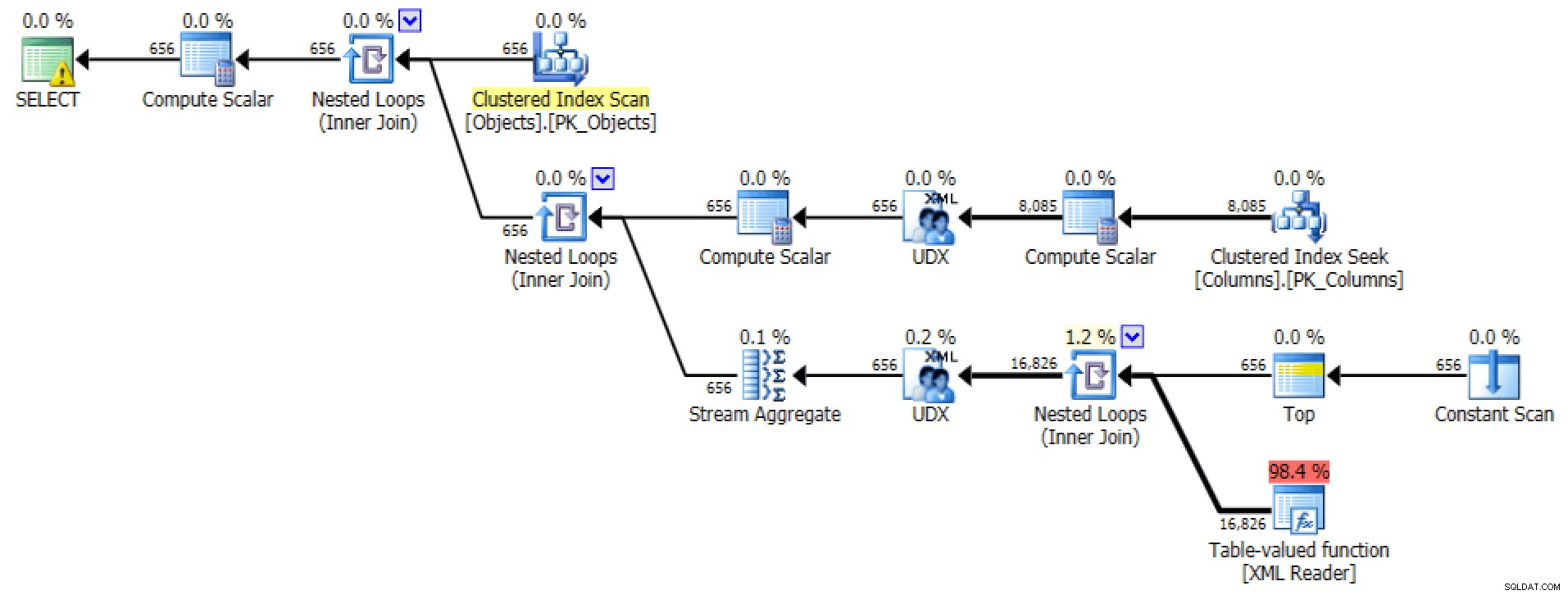
U posledně jmenovaného se mi hledání clusteru indexu zdá trochu znepokojivé. Zdálo se to jako dobrý případ pro testování zřídka používaného
FORCESCANnápověda (a ne, to by určitě nepomohloFOR XML PATHdotaz):SELECT [object] =o.[object_name], [columns] =STRING_AGG(c.column_name, N',')FROM dbo.Objects AS OINNER JOIN dbo.Columns AS c WITH (FORCESCAN) -- přidán hintON o .[id_objektu] =c.[id_objektu]GROUP BY o.[jméno_objektu];Nyní vypadá karta plánu a tabulky I/O hodně lepší, alespoň na první pohled:
Plán a tabulka I/O pro STRING_AGG(), bez objednání, s FORCESCAN
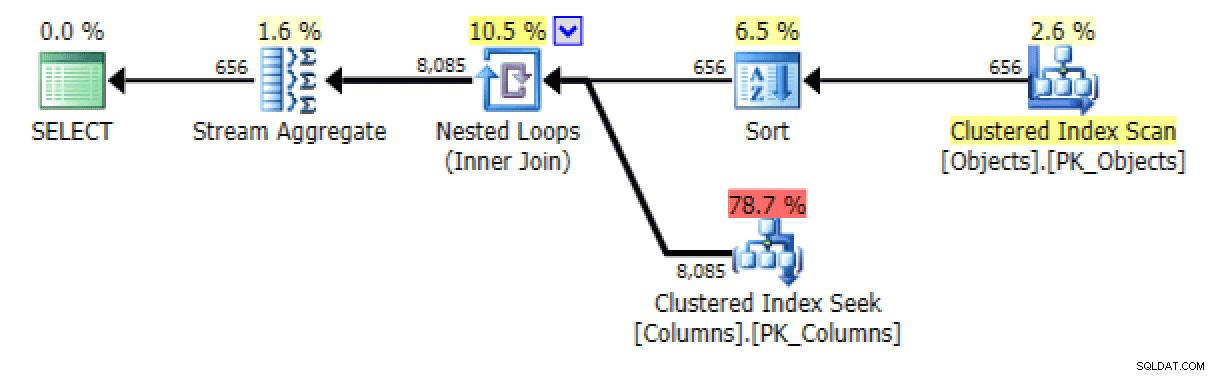
Seřazené verze dotazů generují zhruba stejné plány. Pro
FOR XML PATHverze, je přidáno řazení:
Přidáno řazení ve verzi FOR XML PATH
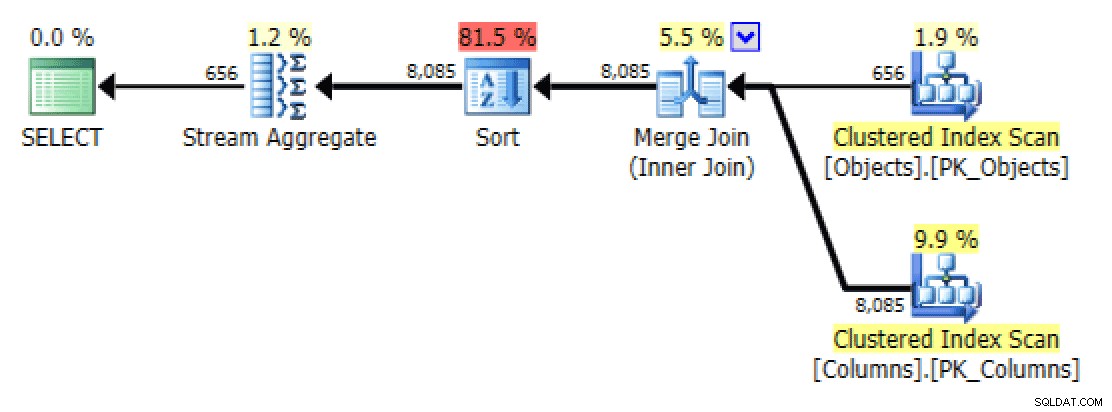
Pro
STRING_AGG(), je v tomto případě zvoleno skenování i bezFORCESCANnápověda a není potřeba žádná další operace řazení – takže plán vypadá stejně jakoFORCESCANverze.Ve měřítku
Když se podíváme na plán a jednorázové metriky doby běhu, můžeme získat představu o tom, zda
STRING_AGG()funguje lépe než stávajícíFOR XML PATHřešení, ale větší test by mohl mít větší smysl. Co se stane, když provedeme seskupené zřetězení 5000krát?SELECT SYSDATETIME();GO DECLARE @x nvarchar(max);SELECT @x =STRING_AGG(c.column_name, N',') FROM dbo.Objects AS o INNER JOIN dbo.Columns AS c ON o.[object_id ] =c.[id_objektu] GROUP BY o.[jméno_objektu];GO 5000SELECT [řetězec_agg, neuspořádané] =SYSDATETIME();GO DECLARE @x nvarchar(max);SELECT @x =STRING_AGG(jméno c.sloupce, N',' ) FROM dbo.Objects AS o INNER JOIN dbo.Columns AS c WITH (FORCESCAN) ON o.[id_objektu] =c.[id_objektu] GROUP BY o.[jméno_objektu];GO 5000SELECT [string_agg, neuspořádané, forcecan] =SYSDATETIME( ); GODECLARE @x nvarchar(max);SELECT @x =STUFF((SELECT N',' +c.jméno_sloupce FROM dbo.Columns AS c WHERE c.[id_objektu] =o.[id_objektu] PRO cestu XML, TYP.hodnota (N'.[1]',N'nvarchar(max)'),1,1,N'')FROM dbo.Objects AS o;GO 5000SELECT [pro cestu xml, neuspořádané] =SYSDATETIME(); GODECLARE @x nvarchar(max);SELECT @x =STRING_AGG(c.column_name, N',') WITHIN GROUP (ORDER BY c.column_name) FROM dbo.Objects AS o INNER JOIN dbo.Columns AS c ON o.[object_id ] =c.[id_objektu] GROUP BY o.[jméno_objektu];GO 5000SELECT [řetězec_agg, seřazeno] =SYSDATETIME(); GODECLARE @x nvarchar(max);SELECT @x =STUFF((SELECT N',' +c.jméno_sloupce FROM dbo.Columns AS c WHERE c.[id_objektu] =o.[id_objektu] ORDER BY c.column_name FOR XML PATH , TYPE).value(N'.[1]',N'nvarchar(max)'),1,1,N'')FROM dbo.Objects AS oORDER BY o.[object_name];GO 5000SELECT [for xml path , objednané] =SYSDATETIME();Po pětinásobném spuštění tohoto skriptu jsem zprůměroval čísla trvání a zde jsou výsledky:
Délka (milisekundy) pro různé přístupy seskupeného zřetězení
Vidíme, že naše
FORCESCANnápověda skutečně věci zhoršila – i když jsme přesunuli náklady z hledání seskupených indexů, řazení bylo ve skutečnosti mnohem horší, i když je odhadované náklady považovaly za relativně ekvivalentní. Ještě důležitější je, že vidíme, žeSTRING_AGG()nabízí výkonnostní výhodu bez ohledu na to, zda je nutné zřetězené řetězce objednávat specifickým způsobem. Stejně jako uSTRING_SPLIT(), na který jsem se díval v březnu, jsem docela ohromen tím, že tato funkce je dobře škálovatelná před "v1."Mám naplánované další testy, možná pro budoucí příspěvek:
- Když všechna data pocházejí z jediné tabulky, s indexem a bez něj, který podporuje řazení
- Podobné testy výkonu v systému Linux
Pokud mezitím máte konkrétní případy použití pro seskupené zřetězení, podělte se o ně níže (nebo mi pošlete e-mail na adresu abertrand@sentryone.com). Jsem vždy otevřený tomu, abych se ujistil, že mé testy jsou co nejvíce reálné.