Před několika týdny jsem udělal velkou věc ohledně SQL Server 2016 Service Pack 1. Mnoho funkcí dříve vyhrazených pro Enterprise Edition bylo uvolněno pro nižší edice a byl jsem nadšený, když jsem se o těchto změnách dozvěděl.
Nicméně vidím pár lidí, kteří jsou, řekněme, o něco méně nadšení než já.
Je důležité mít na paměti, že zde uvedené změny nebyly zamýšleny tak, aby poskytovaly úplnou paritu funkcí ve všech edicích; byly pro konkrétní účel vytvoření konzistentnější programovací plochy. Nyní mohou zákazníci používat funkce jako In-Memory OLTP, Columnstore a komprese, aniž by se museli starat o cílové edice – pouze o to, jak dobře se budou škálovat. Otevřelo se také několik bezpečnostních prvků, které ve skutečnosti neměly s edicí nic společného. Ten, kterému jsem rozuměl nejméně, byl Always Encrypted; Nemohl jsem pochopit, proč pouze zákazníci Enterprise potřebují chránit věci, jako jsou údaje o kreditních kartách. Transparent Data Encryption je stále pouze pro podniky ve verzích starších než SQL Server 2019, protože to ve skutečnosti není programovatelná funkce (buď je zapnutá, nebo není).
Co to tedy skutečně znamená pro zákazníky standardní verze?
Myslím, že největším problémem většiny lidí je, že maximální paměť ve Standard Edition je stále omezena na 128 GB. Podívají se na to a řeknou:"Jé, díky za všechny funkce, ale omezená paměť znamená, že je opravdu nemůžu používat."
Nicméně změny plochy přinášejí příležitosti ke zlepšení výkonu, i když to nebyl jejich původní záměr (nebo i kdyby byl – na žádném z těch setkání jsem nebyl). Podívejme se blíže na malou část drobného písma (z oficiálních dokumentů):
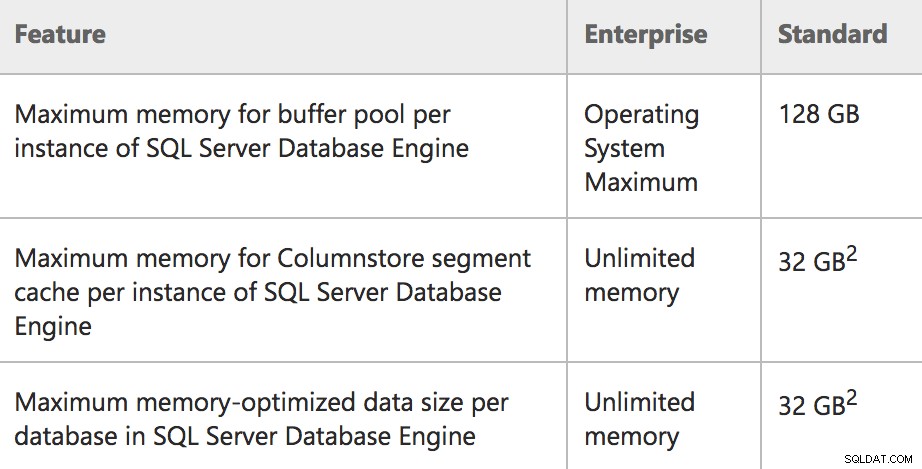 Omezení paměti pro Enterprise/Standard v SQL Server 2016 SP1
Omezení paměti pro Enterprise/Standard v SQL Server 2016 SP1
Bystrý čtenář si všimne, že znění limitu vyrovnávací paměti se změnilo z:
Paměť:Maximální využitá paměť na instanciKomu:
Paměť:Maximální velikost fondu vyrovnávací paměti za instanciToto je lepší popis toho, co se skutečně děje ve standardní edici:limit 128 GB pouze pro fond vyrovnávacích pamětí a další rezervace paměti mohou být nad ním (myslím, že fondy jako mezipaměť plánu). Ve skutečnosti by tedy server Standard Edition mohl využívat 128 GB vyrovnávací paměti, pak by maximální paměť serveru mohla být vyšší a podporovat více paměti použité pro jiné rezervace. Podobně je nyní řádně zdokumentováno Express Edition pro použití 1,4 GB pro fond vyrovnávacích pamětí.
Můžete si také všimnout velmi specifického znění ve sloupci zcela vlevo (např. „na instanci“ a „na databázi“) pro funkce, které jsou ve Standard Edition vystaveny poprvé. Abych byl konkrétnější:
- Instance je omezena na 128 GB paměti pro fond vyrovnávacích pamětí .
- Instance může mít další 32 GB přidělených objektům Columnstore, nad limit fondu vyrovnávacích pamětí.
- Každá uživatelská databáze v instanci může mít další 32 GB přidělených tabulkám s optimalizovanou pamětí, nad limit fondu vyrovnávací paměti.
A aby bylo jasno:Tyto limity paměti pro ColumnStore a In-Memory OLTP NEJSOU odečteny od limitu fondu vyrovnávací paměti , pokud má server k dispozici více než 128 GB paměti. Pokud má server méně než 128 GB, uvidíte, že tyto technologie soutěží s pamětí vyrovnávací paměti a ve skutečnosti jsou omezeny na % maximální paměti serveru. Další podrobnosti jsou k dispozici v tomto příspěvku od Parikshita Savjaniho společnosti Microsoft.
Nemám po ruce hardware, abych otestoval rozsah tohoto, ale pokud byste měli stroj s 256GB nebo 512GB pamětí, mohli byste jej teoreticky použít vše s jedinou instancí Standard Edition, pokud byste například mohli rozšířit své In -Paměťová data napříč databázemi v <=32GB blocích, celkem 128GB + (32GB * (počet databází)). Pokud byste chtěli místo In-Memory použít ColumnStore, mohli byste svá data rozložit do více instancí, čímž získáte (128 GB + 32 GB) * (počet instancí). Tyto strategie můžete kombinovat pro ((128 GB + 32 GB ColumnStore) * (počet instancí)) + (32 GB v paměti * (počet databází * počet instancí)).
Nejsem si jistý, zda je rozdělení vašich dat tímto způsobem pro vaši aplikaci praktické; Jen naznačuji, že je to možné. Někteří z vás již možná dělají některé z těchto věcí, aby lépe využívali Standard Edition na serverech s více než 128 GB paměti.
S ColumnStore konkrétně, kromě toho, že můžete používat 32 GB navíc k fondu vyrovnávacích pamětí, mějte na paměti, že komprese, kterou zde můžete získat, znamená, že se do limitu 32 GB často vejde mnohem více, než byste mohli se stejnými daty v tradičním řadový obchod. A pokud z jakéhokoli důvodu nemůžete použít ColumnStore (nebo se stále nevejde do 32 GB), můžete nyní implementovat tradiční kompresi stránek nebo řádků – možná vám to neumožní vměstnat celou databázi do 128GB fondu vyrovnávací paměti, ale může to umožnit, aby bylo v paměti v kteroukoli chvíli uloženo více vašich dat.
Podobné věci jsou možné v Express (v nižším měřítku), kde můžete mít 1,4 GB pro buffer pool, ale dalších ~352 MB na instanci pro ColumnStore a ~352 MB na databázi pro In-Memory OLTP.
Ale Enterprise Edition má stále spoustu výhod
Kromě neomezených paměťových limitů všude kolem existuje mnoho dalších odlišujících prvků, díky kterým je zájem o Enterprise Edition udržovat – od online přestaveb a kolotočových skenů až po plnohodnotné skupiny dostupnosti a všechna práva na virtualizaci, nad kterými můžete zatřást. Dokonce i indexy ColumnStore mají dobře definovaná vylepšení výkonu vyhrazená pro Enterprise Edition.
Takže jen proto, že existují některé techniky, které vám umožní získat více ze standardní edice, neznamená to, že se magicky rozšíří tak, aby vyhovovala vašim výkonnostním potřebám. Stejně jako ostatní mé příspěvky o „dělání s omezeným rozpočtem“ (např. rozdělení na oddíly a čitelné sekundární položky), určitě můžete strávit čas a úsilí skládáním řešení, ale dostanete se tak daleko. Účelem tohoto příspěvku bylo jednoduše ukázat, že se Standard Edition v 2016 SP1 můžete dostat dále, než kdy předtím.