
V tomto článku prozkoumáme, kdy a jak použít klauzuli SQL PARTITION BY, a porovnáme to s použitím klauzule GROUP BY.
Vysvětlení funkce okna
Uživatelé databáze používají k provádění analýzy dat agregační funkce, jako je MAX(), MIN(), AVERAGE() a COUNT(). Tyto funkce pracují s celou tabulkou a vracejí jednotlivá agregovaná data pomocí klauzule GROUP BY. Někdy požadujeme agregované hodnoty přes malou sadu řádků. V tomto případě funkce Window kombinovaná s agregační funkcí pomáhá dosáhnout požadovaného výstupu. Funkce Window používá klauzuli OVER() a může zahrnovat následující funkce:
- Rozdělit podle: Tím se řádky nebo sada výsledků dotazu rozdělí na malé oddíly.
- Objednat podle: To uspořádá řádky ve vzestupném nebo sestupném pořadí pro okno oddílu. Výchozí pořadí je vzestupné.
- Řádek nebo rozsah: Řádky v oddílu můžete dále omezit zadáním počátečního a koncového bodu.
V tomto článku se zaměříme na prozkoumání klauzule SQL PARTITION BY.
Příprava ukázkových dat
Předpokládejme, že máme tabulku [SalesLT].[Orders], která ukládá podrobnosti o zákaznických objednávkách. Obsahuje sloupec [City], který uvádí město zákazníka, kde byla zadána objednávka.
CREATE TABLE [SalesLT].[Orders] ( orderid INT, orderdate DATE, customerName VARCHAR(100), City VARCHAR(50), amount MONEY ) INSERT INTO [SalesLT].[Orders] SELECT 1,'01/01/2021','Mohan Gupta','Alwar',10000 UNION ALL SELECT 2,'02/04/2021','Lucky Ali','Kota',20000 UNION ALL SELECT 3,'03/02/2021','Raj Kumar','Jaipur',5000 UNION ALL SELECT 4,'04/02/2021','Jyoti Kumari','Jaipur',15000 UNION ALL SELECT 5,'05/03/2021','Rahul Gupta','Jaipur',7000 UNION ALL SELECT 6,'06/04/2021','Mohan Kumar','Alwar',25000 UNION ALL SELECT 7,'07/02/2021','Kashish Agarwal','Alwar',15000 UNION ALL SELECT 8,'08/03/2021','Nagar Singh','Kota',2000 UNION ALL SELECT 9,'09/04/2021','Anil KG','Alwar',1000 Go
Řekněme, že chceme znát celkovou hodnotu objednávek podle místa (města). Pro tento účel používáme funkce SUM() a GROUP BY, jak je uvedeno níže.
SELECT City AS CustomerCity ,sum(amount) AS totalamount FROM [SalesLT].[Orders] GROUP BY city ORDER BY city
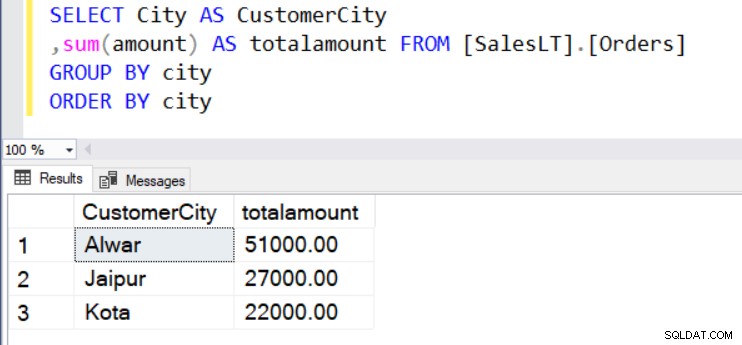
V sadě výsledků nemůžeme v příkazu SELECT použít neagregované sloupce. Například nemůžeme zobrazit [CustomerName] ve výstupu, protože není zahrnuto v klauzuli GROUP BY.
SQL Server zobrazí následující chybovou zprávu, pokud se pokusíte použít neagregovaný sloupec v seznamu sloupců.
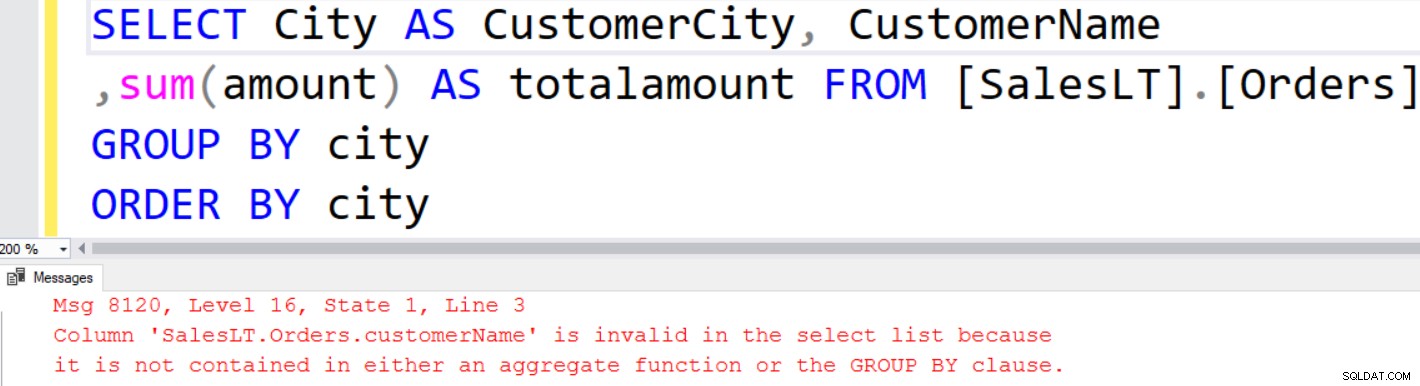
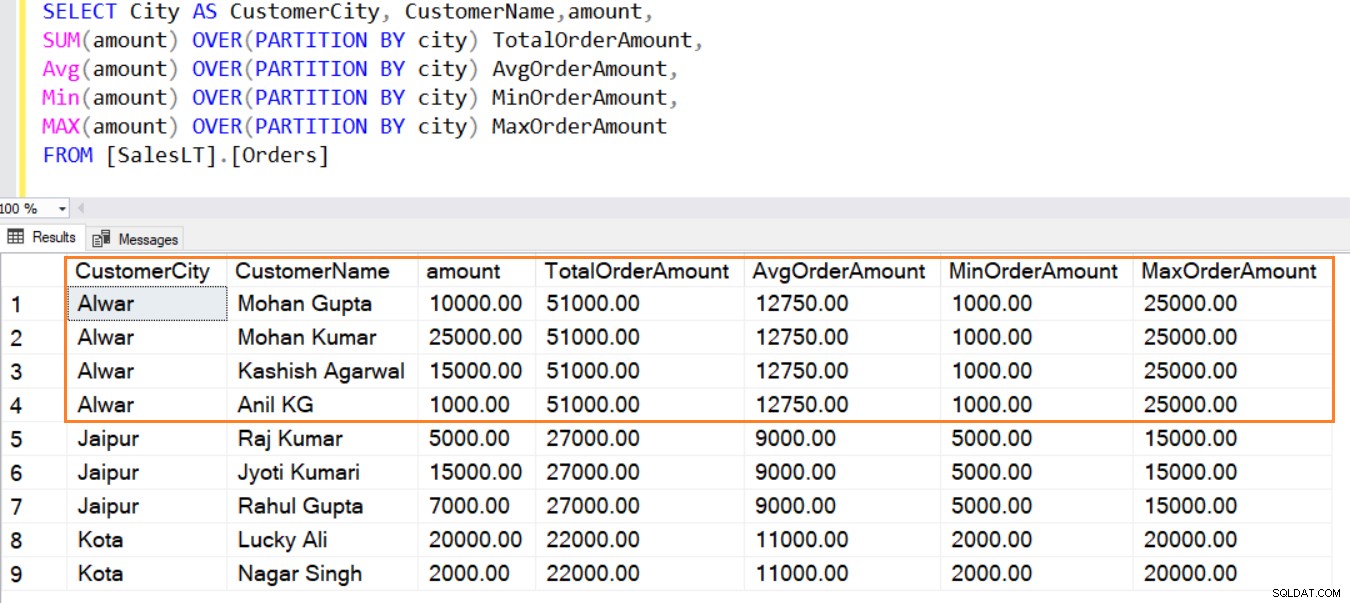
SELECT City AS CustomerCity, CustomerName,amount, SUM(amount) OVER(PARTITION BY city) TotalOrderAmount FROM [SalesLT].[Orders]
Jak je ukázáno níže, klauzule PARTITION BY vytvoří menší okno (množinu datových řádků), provede agregaci a zobrazí ji. V tomto výstupu můžete také zobrazit neagregované sloupce.
Podobně můžete použít funkce AVG(), MIN(), MAX() k výpočtu průměrné, minimální a maximální částky z řádků v okně.
SELECT City AS CustomerCity, CustomerName,amount, SUM(amount) OVER(PARTITION BY city) TotalOrderAmount, Avg(amount) OVER(PARTITION BY city) AvgOrderAmount, Min(amount) OVER(PARTITION BY city) MinOrderAmount, MAX(amount) OVER(PARTITION BY city) MaxOrderAmount FROM [SalesLT].[Orders]
Použití klauzule SQL PARTITION BY s funkcí ROW_NUMBER()
Dříve jsme získávali agregované hodnoty v okně pomocí klauzule PARTITION BY. Předpokládejme, že místo součtu požadujeme kumulativní součet v oddílu.
Kumulativní součet funguje následujícím způsobem.
| Řádek | Kumulativní součet |
| 1 | Pořadí 1+ 2 |
| 2 | Pořadí 2+3 |
| 3 | Pořadí 3+4 |
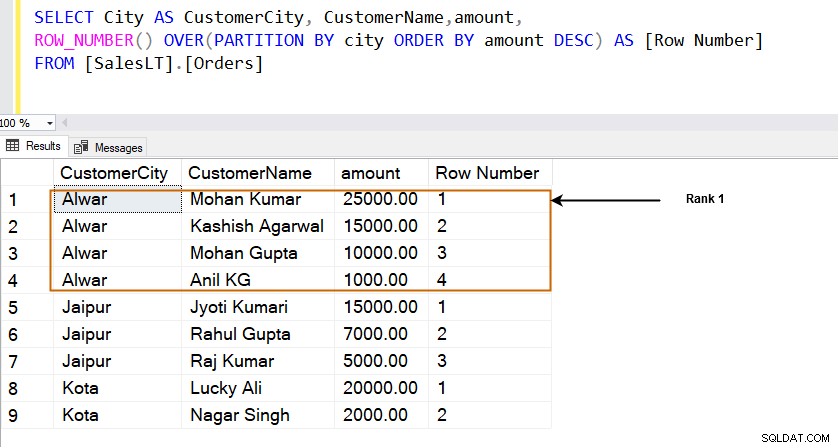
Pořadí řádku se vypočítá pomocí funkce ROW_NUMBER(). Nejprve použijeme tuto funkci a zobrazíme pořadí řádků.
- Funkce ROW_NUMBER() používá klauzuli OVER a PARTITION BY a řadí výsledky ve vzestupném nebo sestupném pořadí. Začne seřazovat řádky od 1 v pořadí řazení.
SELECT City AS CustomerCity, CustomerName,amount, ROW_NUMBER() OVER(PARTITION BY city ORDER BY amount DESC) AS [Row Number] FROM [SalesLT].[Orders]
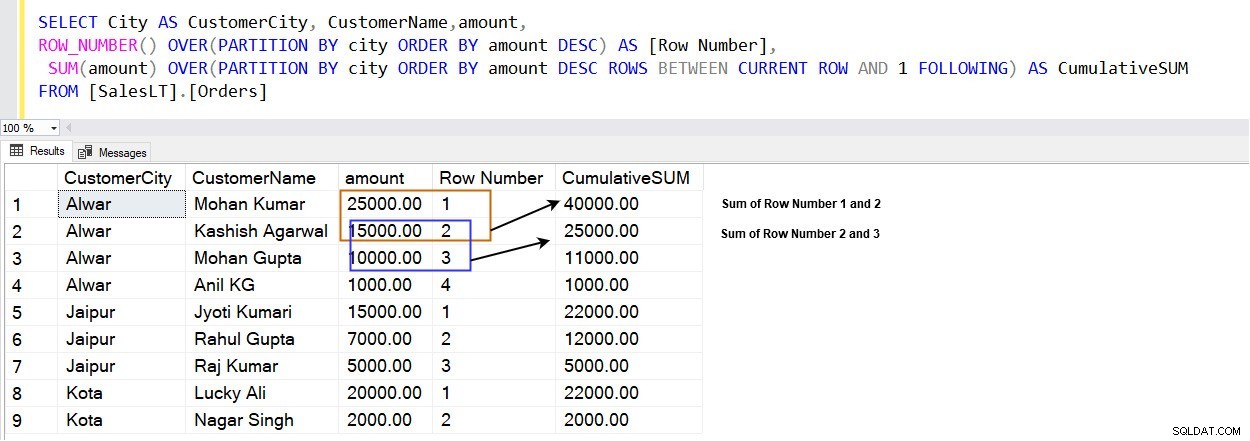
Například ve městě [Alwar] je řádek s nejvyšší částkou (25000,00) na řádku 1. Jak je znázorněno níže, řadí řádky v okně určeném klauzulí PARTITION BY. Například máme tři různá města [Alwar], [Džajpur] a [Kota] a každé okno (město) má své řady.
K výpočtu kumulativního součtu používáme následující argumenty.
- AKTUÁLNÍ ŘÁDEK:Určuje počáteční a koncový bod v určeném rozsahu.
- 1 následující:Určuje počet řádků (1), které mají následovat od aktuálního řádku.
SELECT City AS CustomerCity, CustomerName,amount, ROW_NUMBER() OVER(PARTITION BY city ORDER BY amount DESC) AS [Row Number], SUM(amount) OVER(PARTITION BY city ORDER BY amount DESC ROWS BETWEEN CURRENT ROW AND 1 FOLLOWING) AS CumulativeSUM FROM [SalesLT].[Orders]
Následující obrázek ukazuje, že v okně určeném klauzulí PARTITION BY získáte kumulativní součet namísto celkového součtu.
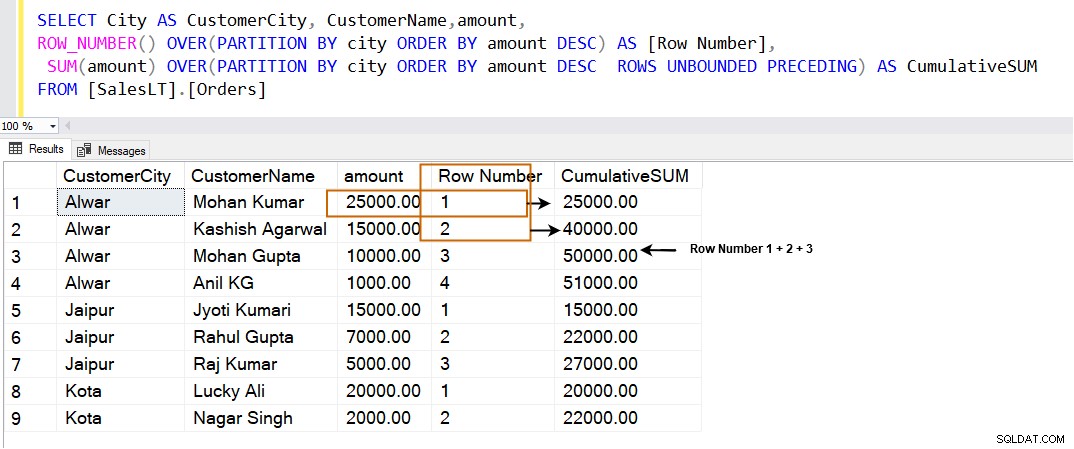
Pokud použijeme ROWS NEBOUNDED PRECEDING v klauzuli SQL PARTITION BY vypočítá kumulativní součet následujícím způsobem. Používá aktuální řádky spolu s řádky s nejvyššími hodnotami v zadaném okně.
| Řádek | Kumulativní součet |
| 1 | Pořadí 1 |
| 2 | Pořadí 1+2 |
| 3 | Pořadí 1+2+3 |
SELECT City AS CustomerCity, CustomerName,amount, ROW_NUMBER() OVER(PARTITION BY city ORDER BY amount DESC) AS [Row Number], SUM(amount) OVER(PARTITION BY city ORDER BY amount DESC ROWS UNBOUNDED PRECEDING) AS CumulativeSUM FROM [SalesLT].[Orders]
Porovnání klauzule GROUP BY a SQL PARTITION BY
| GROUP BY | PARTITION BY |
| Po výpočtu souhrnných hodnot vrátí jeden řádek na skupinu. | Vrátí všechny řádky z příkazu SELECT spolu s dalšími sloupci agregovaných hodnot. |
| Nemůžeme použít neagregovaný sloupec v příkazu SELECT. | V příkazu SELECT můžeme použít požadované sloupce a pro neagregovaný sloupec to nevyvolá žádné chyby. |
| Vyžaduje použití klauzule HAVING k filtrování záznamů z příkazu SELECT. | Funkce PARTITION může mít v klauzuli WHERE kromě sloupců použitých v příkazu SELECT další predikáty. |
| Skupina GROUP BY se používá v běžných agregátech. | PARTITION BY se používá v okénkových agregacích. |
| Nemůžeme jej použít pro výpočet čísel řádků nebo jejich pořadí. | Umí vypočítat čísla řádků a jejich pořadí v menším okně. |
Použití
Při práci s více skupinami dat pro agregované hodnoty v jednotlivé skupině se doporučuje použít klauzuli SQL PARTITION BY. Podobně jej lze použít k zobrazení původních řádků s dodatečným sloupcem agregovaných hodnot.