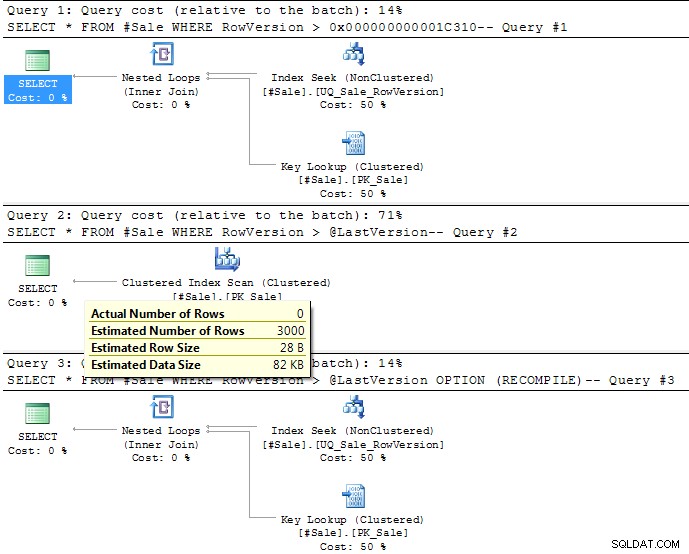
Dotaz 2 používá proměnnou.
V době kompilace dávky SQL Server nezná hodnotu proměnné, takže se vrátí k heuristice velmi podobné OPTIMIZE FOR (UNKNOWN)
Pro > bude předpokládat, že 30 % řádků se nakonec shoduje (nebo 3 000 řádků ve vašich vzorových datech). To lze vidět na obrázku prováděcího plánu, jak je uvedeno níže. To je výrazně více než 12 řádků (0,12 %), což je bod zlomu
pro tento dotaz v tom, zda používá skenování indexu v clusteru nebo hledání indexu bez clusteru a vyhledávání klíčů.
Budete muset použít OPTION (RECOMPILE) abyste jej přiměli vzít v úvahu skutečnou hodnotu proměnné, jak je znázorněno ve třetím plánu níže.
Skript
CREATE TABLE #Sale
(
SaleId INT IDENTITY(1, 1)
CONSTRAINT PK_Sale PRIMARY KEY,
Test1 VARCHAR(10) NULL,
RowVersion rowversion NOT NULL
CONSTRAINT UQ_Sale_RowVersion UNIQUE
)
/*A better way of populating the table!*/
INSERT INTO #Sale (Test1)
SELECT TOP 10000 NULL
FROM master..spt_values v1, master..spt_values v2
GO
SELECT *
FROM #Sale
WHERE RowVersion > 0x000000000001C310-- Query #1
DECLARE @LastVersion rowversion = 0x000000000001C310
SELECT *
FROM #Sale
WHERE RowVersion > @LastVersion-- Query #2
SELECT *
FROM #Sale
WHERE RowVersion > @LastVersion
OPTION (RECOMPILE)-- Query #3
DROP TABLE #Sale