Optimalizátor SQL Server obsahuje logiku pro odstranění nadbytečných spojení, ale existují omezení a spojení musí být prokazatelně nadbytečné . Abych to shrnul, spojení může mít čtyři efekty:
- Může přidat další sloupce (ze spojené tabulky)
- Může přidat další řádky (spojená tabulka může odpovídat zdrojovému řádku více než jednou)
- Může odstranit řádky (spojená tabulka nemusí mít shodu)
- Může zavést
NULLs (proRIGHTneboFULL JOIN)
Pro úspěšné odstranění redundantního spojení musí dotaz (nebo pohled) zohledňovat všechny čtyři možnosti. Když se to udělá správně, efekt může být ohromující. Například:
USE AdventureWorks2012;
GO
CREATE VIEW dbo.ComplexView
AS
SELECT
pc.ProductCategoryID, pc.Name AS CatName,
ps.ProductSubcategoryID, ps.Name AS SubCatName,
p.ProductID, p.Name AS ProductName,
p.Color, p.ListPrice, p.ReorderPoint,
pm.Name AS ModelName, pm.ModifiedDate
FROM Production.ProductCategory AS pc
FULL JOIN Production.ProductSubcategory AS ps ON
ps.ProductCategoryID = pc.ProductCategoryID
FULL JOIN Production.Product AS p ON
p.ProductSubcategoryID = ps.ProductSubcategoryID
FULL JOIN Production.ProductModel AS pm ON
pm.ProductModelID = p.ProductModelID
Optimalizátor může úspěšně zjednodušit následující dotaz:
SELECT
c.ProductID,
c.ProductName
FROM dbo.ComplexView AS c
WHERE
c.ProductName LIKE N'G%';
Komu:

Rob Farley psal o těchto nápadech do hloubky v původní knize MVP Deep Dives a existuje záznam jeho prezentace na toto téma na SQLBits.
Hlavní omezení spočívá v tom, že vztahy cizích klíčů musí být založeno na jediném klíči přispět k procesu zjednodušení a doba kompilace dotazů proti takovému pohledu se může značně prodloužit, zejména s rostoucím počtem spojení. Mohlo by to být docela náročné napsat 100-tabulkový pohled, který by měl veškerou sémantiku přesně správnou. Byl bych nakloněn najít alternativní řešení, možná pomocí dynamického SQL .
To znamená, že konkrétní vlastnosti vaší denormalizované tabulky mohou znamenat, že pohled je poměrně jednoduchý na sestavení a vyžaduje pouze vynucené FOREIGN KEYs jiné než NULL schopné odkazované sloupce a vhodné UNIQUE omezení, aby toto řešení fungovalo tak, jak byste doufali, bez režie 100 fyzických operátorů spojení v plánu.
Příklad
Použití deseti tabulek místo stovky:
-- Referenced tables
CREATE TABLE dbo.Ref01 (col01 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref02 (col02 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref03 (col03 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref04 (col04 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref05 (col05 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref06 (col06 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref07 (col07 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref08 (col08 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref09 (col09 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref10 (col10 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
Definice nadřazené tabulky (s kompresí stránky):
CREATE TABLE dbo.Normalized
(
pk integer IDENTITY NOT NULL,
col01 tinyint NOT NULL REFERENCES dbo.Ref01,
col02 tinyint NOT NULL REFERENCES dbo.Ref02,
col03 tinyint NOT NULL REFERENCES dbo.Ref03,
col04 tinyint NOT NULL REFERENCES dbo.Ref04,
col05 tinyint NOT NULL REFERENCES dbo.Ref05,
col06 tinyint NOT NULL REFERENCES dbo.Ref06,
col07 tinyint NOT NULL REFERENCES dbo.Ref07,
col08 tinyint NOT NULL REFERENCES dbo.Ref08,
col09 tinyint NOT NULL REFERENCES dbo.Ref09,
col10 tinyint NOT NULL REFERENCES dbo.Ref10,
CONSTRAINT PK_Normalized
PRIMARY KEY CLUSTERED (pk)
WITH (DATA_COMPRESSION = PAGE)
);
Pohled:
CREATE VIEW dbo.Denormalized
WITH SCHEMABINDING AS
SELECT
item01 = r01.item,
item02 = r02.item,
item03 = r03.item,
item04 = r04.item,
item05 = r05.item,
item06 = r06.item,
item07 = r07.item,
item08 = r08.item,
item09 = r09.item,
item10 = r10.item
FROM dbo.Normalized AS n
JOIN dbo.Ref01 AS r01 ON r01.col01 = n.col01
JOIN dbo.Ref02 AS r02 ON r02.col02 = n.col02
JOIN dbo.Ref03 AS r03 ON r03.col03 = n.col03
JOIN dbo.Ref04 AS r04 ON r04.col04 = n.col04
JOIN dbo.Ref05 AS r05 ON r05.col05 = n.col05
JOIN dbo.Ref06 AS r06 ON r06.col06 = n.col06
JOIN dbo.Ref07 AS r07 ON r07.col07 = n.col07
JOIN dbo.Ref08 AS r08 ON r08.col08 = n.col08
JOIN dbo.Ref09 AS r09 ON r09.col09 = n.col09
JOIN dbo.Ref10 AS r10 ON r10.col10 = n.col10;
Hackněte statistiky, aby si optimalizátor myslel, že tabulka je velmi velká:
UPDATE STATISTICS dbo.Normalized WITH ROWCOUNT = 100000000, PAGECOUNT = 5000000;
Příklad uživatelského dotazu:
SELECT
d.item06,
d.item07
FROM dbo.Denormalized AS d
WHERE
d.item08 = 'Banana'
AND d.item01 = 'Green';
Dává nám tento plán provádění:
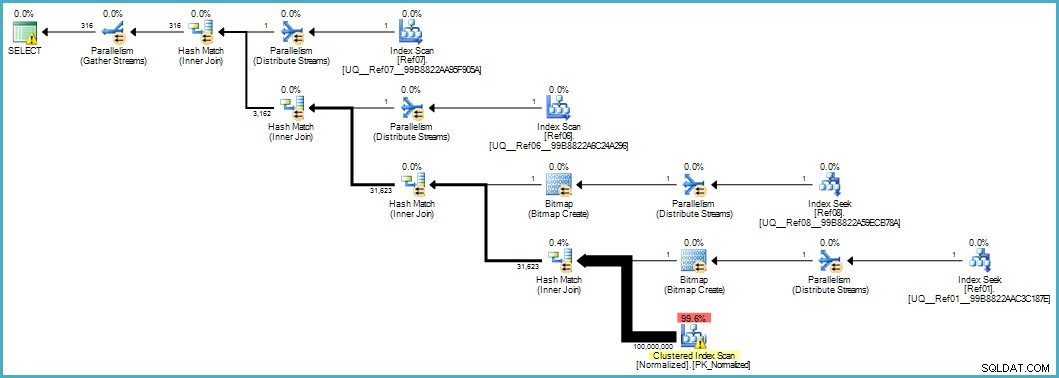
Skenování normalizované tabulky vypadá špatně, ale obě bitmapy Bloom-filtru jsou během skenování použity úložným modulem (takže řádky, které se nemohou shodovat, se ani nevynoří až k procesoru dotazu). To může ve vašem případě stačit k dosažení přijatelného výkonu a rozhodně lepší než skenování původní tabulky s přeplněnými sloupci.
Pokud jste schopni v určité fázi upgradovat na SQL Server 2012 Enterprise, máte další možnost:vytvoření indexu úložiště sloupců v normalizované tabulce:
CREATE NONCLUSTERED COLUMNSTORE INDEX cs
ON dbo.Normalized (col01,col02,col03,col04,col05,col06,col07,col08,col09,col10);
Prováděcí plán je:
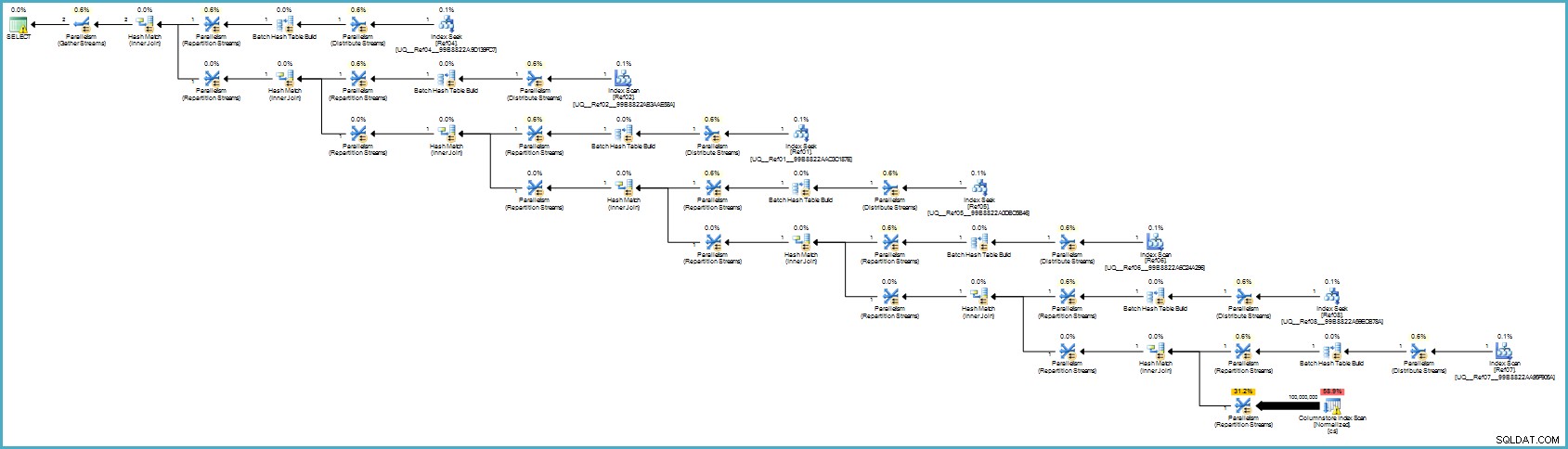
To se vám pravděpodobně zdá horší, ale úložiště sloupců poskytuje výjimečnou kompresi a celý plán provádění běží v dávkovém režimu s filtry pro všechny přispívající sloupce. Pokud má server k dispozici dostatek vláken a paměti, může tato alternativa skutečně létat.
Nakonec si nejsem jistý, zda je tato normalizace správným přístupem, vezmeme-li v úvahu počet tabulek a pravděpodobnost, že získáte špatný plán provádění nebo bude vyžadovat příliš dlouhou dobu kompilace. Pravděpodobně bych nejprve opravil schéma denormalizované tabulky (správné datové typy a tak dále), případně použil kompresi dat...obvyklé věci.
Pokud data skutečně patří do hvězdicového schématu, pravděpodobně to vyžaduje více návrhové práce než pouhé rozdělení opakujících se datových prvků do samostatných tabulek.