Náklady na podstrom by se měly brát s velkou rezervou (a zvláště když máte velké chyby mohutnosti). SET STATISTICS IO ON; SET STATISTICS TIME ON; výstup je lepším ukazatelem skutečného výkonu.
Řazení s nulovým řádkem nezabere 87 % zdrojů. Tento problém ve vašem plánu je jedním ze statistických odhadů. Náklady uvedené ve skutečném plánu jsou stále odhadované náklady. Neupravuje je, aby zohlednily, co se skutečně stalo.
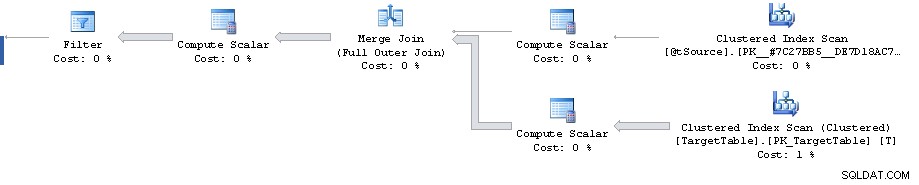
V plánu je bod, kdy filtr sníží 1 911 721 řádků na 0, ale odhadovaný počet řádků vpřed je 1 860 310. Poté jsou všechny náklady falešné a vyvrcholí 87% odhadovanými náklady na 3 348 560 řádků.
Chybu odhadu mohutnosti lze reprodukovat mimo Merge pohledem na odhadovaný plán pro Full Outer Join s ekvivalentními predikáty (poskytuje stejný odhad 1 860 310 řádků).
SELECT *
FROM TargetTable T
FULL OUTER JOIN @tSource S
ON S.Key1 = T.Key1 and S.Key2 = T.Key2
WHERE
CASE WHEN S.Key1 IS NOT NULL
/*Matched by Source*/
THEN CASE WHEN T.Key1 IS NOT NULL
/*Matched by Target*/
THEN CASE WHEN [T].[Data1]<>S.[Data1] OR
[T].[Data2]<>S.[Data2] OR
[T].[Data3]<>S.[Data3]
THEN (1)
END
/*Not Matched by Target*/
ELSE (4)
END
/*Not Matched by Source*/
ELSE CASE WHEN [T].[Key1]example@sqldat.com
THEN (3)
END
END IS NOT NULL
To znamená, že plán až po samotný filtr vypadá docela neoptimálně. Provádí úplné skenování indexu clusteru, když možná chcete plán se 2 hledáními rozsahu clusteru. Jeden pro načtení jednoho řádku shodného s primárním klíčem ze spojení na zdroji a druhý pro načtení T.Key1 = @id rozsah (i když je to možná proto, aby se později nemuselo třídit do seskupeného klíče?)
Možná byste mohli zkusit toto přepsání a zjistit, zda to funguje lépe nebo hůře
;WITH FilteredTarget AS
(
SELECT T.*
FROM TargetTable AS T WITH (FORCESEEK)
JOIN @tSource S
ON (T.Key1 = S.Key1
AND S.Key2 = T.Key2)
OR T.Key1 = @id
)
MERGE FilteredTarget AS T
USING @tSource S
ON (T.Key1 = S.Key1
AND S.Key2 = T.Key2)
-- Only update if the Data columns do not match
WHEN MATCHED AND S.Key1 = T.Key1 AND S.Key2 = T.Key2 AND
(T.Data1 <> S.Data1 OR
T.Data2 <> S.Data2 OR
T.Data3 <> S.Data3) THEN
UPDATE SET T.Data1 = S.Data1,
T.Data2 = S.Data2,
T.Data3 = S.Data3
-- Note from original poster: This extra "safety clause" turned out not to
-- affect the behavior or the execution plan, so I removed it and it works
-- just as well without, but if you find yourself in a similar situation
-- you might want to give it a try.
-- WHEN MATCHED AND (S.Key1 <> T.Key1 OR S.Key2 <> T.Key2) AND T.Key1 = @id THEN
-- DELETE
-- Insert when missing in the target
WHEN NOT MATCHED BY TARGET THEN
INSERT (Key1, Key2, Data1, Data2, Data3)
VALUES (Key1, Key2, Data1, Data2, Data3)
WHEN NOT MATCHED BY SOURCE AND T.Key1 = @id THEN
DELETE;