Monitorování změn schématu databáze v MySQL/MariaDB poskytuje obrovskou pomoc, protože šetří čas při analýze růstu databáze, změn definic tabulek, velikosti dat, velikosti indexu nebo velikosti řádků. Pro MySQL/MariaDB vám spuštění dotazu odkazujícího na information_schema spolu s performance_schema poskytne souhrnné výsledky pro další analýzu. Schéma sys vám poskytuje pohledy, které slouží jako společné metriky, které jsou velmi užitečné pro sledování změn v databázi nebo aktivity.
Pokud máte mnoho databázových serverů, bylo by únavné neustále spouštět dotaz. Tento výsledek také musíte strávit do čitelnějšího a snáze pochopitelného.
V tomto blogu vytvoříme automatizaci, která by byla užitečná jako nástroj pro sledování vaší stávající databáze a shromažďování metrik týkajících se změn databáze nebo operací změn schématu.
Vytvoření automatizace pro kontrolu objektu schématu databáze
V tomto cvičení budeme sledovat následující metriky:
-
Žádné tabulky primárních klíčů
-
Duplicitní indexy
-
Vygenerujte graf pro celkový počet řádků v našich databázových schématech
-
Vygenerujte graf pro celkovou velikost našich databázových schémat
Toto cvičení vám poskytne přehled a lze jej upravit tak, aby shromáždilo pokročilejší metriky z vaší databáze MySQL/MariaDB.
Použití Puppet pro naše IaC a automatizaci
Toto cvičení bude používat Puppet k zajištění automatizace a generování očekávaných výsledků na základě metrik, které chceme monitorovat. Nebudeme se zabývat instalací a nastavením Puppet, včetně serveru a klienta, takže očekávám, že budete vědět, jak Puppet používat. Možná budete chtít navštívit náš starý blog Automated Deployment of MySQL Galera Cluster to Amazon AWS with Puppet, který pokrývá nastavení a instalaci Puppet.
V tomto cvičení použijeme nejnovější verzi Puppet, ale protože náš kód obsahuje základní syntaxi, fungoval by i pro starší verze Puppet.
Preferovaný databázový server MySQL
V tomto cvičení použijeme Percona Server 8.0.22-13, protože Percona Server preferuji především pro testování a některá menší nasazení, ať už pro firemní nebo osobní použití.
Nástroj pro tvorbu grafů
Existuje spousta možností, které lze použít zejména v prostředí Linuxu. V tomto blogu použiji to nejjednodušší, co jsem našel, a opensource nástroj https://quickchart.io/.
Pojďme si hrát s loutkou
Předpoklad, který jsem zde uvedl, je, že máte nastaven hlavní server s registrovaným klientem, který je připraven komunikovat s hlavním serverem a přijímat automatická nasazení.
Než budeme pokračovat, zde jsou informace o mém serveru:
Hlavní server:192.168.40.200
Server klienta/agenta:192.168.40.160
V tomto blogu běží náš databázový server na našem serveru typu klient/agent. V reálném světě to nemusí být speciálně pro monitorování. Pokud je schopen bezpečně komunikovat do cílového uzlu, pak je to také perfektní nastavení.
Nastavení modulu a kódu
-
Přejděte na hlavní server a v cestě /etc/puppetlabs/code/environments/production/module, pojďme vytvořit požadované adresáře pro toto cvičení:
mkdir schema_change_mon/{files,manifests}
-
Vytvořte soubory, které potřebujeme
touch schema_change_mon/files/graphing_gen.sh
touch schema_change_mon/manifests/init.pp
-
Vyplňte skript init.pp následujícím obsahem:
class schema_change_mon (
$db_provider = "mysql",
$db_user = "root",
$db_pwd = "example@sqldat.com",
$db_schema = []
) {
$dbs = ['pauldb', 'sbtest']
service { $db_provider :
ensure => running,
enable => true,
hasrestart => true,
hasstatus => true
}
exec { "mysql-without-primary-key" :
require => Service['mysql'],
command => "/usr/bin/sudo MYSQL_PWD=\"${db_pwd}\" /usr/bin/mysql -u${db_user} -Nse \"select concat(tables.table_schema,'.',tables.table_name,', ', tables.engine) from information_schema.tables left join ( select table_schema , table_name from information_schema.statistics group by table_schema , table_name , index_name having sum( case when non_unique = 0 and nullable != 'YES' then 1 else 0 end ) = count(*) ) puks on tables.table_schema = puks.table_schema and tables.table_name = puks.table_name where puks.table_name is null and tables.table_type = 'BASE TABLE' and tables.table_schema not in ('performance_schema', 'information_schema', 'mysql');\" >> /opt/schema_change_mon/assets/no-pk.log"
}
$dbs.each |String $db| {
exec { "mysql-duplicate-index-$db" :
require => Service['mysql'],
command => "/usr/bin/sudo MYSQL_PWD=\"${db_pwd}\" /usr/bin/mysql -u${db_user} -Nse \"SELECT concat(t.table_schema,'.', t.table_name, '.', t.index_name, '(', t.idx_cols,')') FROM ( SELECT table_schema, table_name, index_name, Group_concat(column_name) idx_cols FROM ( SELECT table_schema, table_name, index_name, column_name FROM statistics WHERE table_schema='${db}' ORDER BY index_name, seq_in_index) t GROUP BY table_name, index_name) t JOIN ( SELECT table_schema, table_name, index_name, Group_concat(column_name) idx_cols FROM ( SELECT table_schema, table_name, index_name, column_name FROM statistics WHERE table_schema='pauldb' ORDER BY index_name, seq_in_index) t GROUP BY table_name, index_name) u where t.table_schema = u.table_schema AND t.table_name = u.table_name AND t.index_name<>u.index_name AND locate(t.idx_cols,u.idx_cols);\" information_schema >> /opt/schema_change_mon/assets/dupe-indexes.log"
}
}
$genscript = "/tmp/graphing_gen.sh"
file { "${genscript}" :
ensure => present,
owner => root,
group => root,
mode => '0655',
source => 'puppet:///modules/schema_change_mon/graphing_gen.sh'
}
exec { "generate-graph-total-rows" :
require => [Service['mysql'],File["${genscript}"]],
path => [ '/bin/', '/sbin/' , '/usr/bin/', '/usr/sbin/' ],
provider => "shell",
logoutput => true,
command => "/tmp/graphing_gen.sh total_rows"
}
exec { "generate-graph-total-len" :
require => [Service['mysql'],File["${genscript}"]],
path => [ '/bin/', '/sbin/' , '/usr/bin/', '/usr/sbin/' ],
provider => "shell",
logoutput => true,
command => "/tmp/graphing_gen.sh total_len"
}
}
-
Vyplňte soubor graphing_gen.sh. Tento skript se spustí na cílovém uzlu a vygeneruje grafy pro celkový počet řádků v naší databázi a také celkovou velikost naší databáze. U tohoto skriptu jej zjednodušíme a povolme pouze databáze typu MyISAM nebo InnoDB.
#!/bin/bash
graph_ident="${1:-total_rows}"
unset json myisam innodb nmyisam ninnodb; json='' myisam='' innodb='' nmyisam='' ninnodb='' url=''; json=$(MYSQL_PWD="example@sqldat.com" mysql -uroot -Nse "select json_object('dbschema', concat(table_schema,' - ', engine), 'total_rows', sum(table_rows), 'total_len', sum(data_length+data_length), 'fragment', sum(data_free)) from information_schema.tables where table_schema not in ('performance_schema', 'sys', 'mysql', 'information_schema') and engine in ('myisam','innodb') group by table_schema, engine;" | jq . | sed ':a;N;$!ba;s/\n//g' | sed 's|}{|},{|g' | sed 's/^/[/g'| sed 's/$/]/g' | jq '.' ); innodb=""; myisam=""; for r in $(echo $json | jq 'keys | .[]'); do if [[ $(echo $json| jq .[$r].'dbschema') == *"MyISAM"* ]]; then nmyisam=$(echo $nmyisam || echo '')$(echo $json| jq .[$r]."${graph_ident}")','; myisam=$(echo $myisam || echo '')$(echo $json| jq .[$r].'dbschema')','; else ninnodb=$(echo $ninnodb || echo '')$(echo $json| jq .[$r]."${graph_ident}")','; innodb=$(echo $innodb || echo '')$(echo $json| jq .[$r].'dbschema')','; fi; done; myisam=$(echo $myisam|sed 's/,$//g'); nmyisam=$(echo $nmyisam|sed 's/,$//g'); innodb=$(echo $innodb|sed 's/,$//g');ninnodb=$(echo $ninnodb|sed 's/,$//g'); echo $myisam "|" $nmyisam; echo $innodb "|" $ninnodb; url=$(echo "{type:'bar',data:{labels:['MyISAM','InnoDB'],datasets:[{label:[$myisam],data:[$nmyisam]},{label:[$innodb],data:[$ninnodb]}]},options:{title:{display:true,text:'Database Schema Total Rows Graph',fontSize:20,}}}"); curl -L -o /vagrant/schema_change_mon/assets/db-${graph_ident}.png -g https://quickchart.io/chart?c=$(python -c "import urllib,os,sys; print urllib.quote(os.environ['url'])")
-
Nakonec přejděte do adresáře cesty modulu nebo /etc/puppetlabs/code/environments /produkce v mém nastavení. Pojďme vytvořit soubor manifests/schema_change_mon.pp.
touch manifests/schema_change_mon.pp-
Potom vyplňte soubor manifests/schema_change_mon.pp následujícím obsahem,
node 'pupnode16.puppet.local' { # Applies only to mentioned node. If nothing mentioned, applies to all.
class { 'schema_change_mon':
}
}
Pokud jste hotovi, měli byste mít následující stromovou strukturu jako já,
example@sqldat.com:/etc/puppetlabs/code/environments/production/modules# tree schema_change_mon
schema_change_mon
├── files
│ └── graphing_gen.sh
└── manifests
└── init.ppCo náš modul dělá?
Náš modul, který se nazývá schema_change_mon, shromažďuje následující,
exec { "mysql-without-primary-key" :...
Který provede příkaz mysql a spustí dotaz pro načtení tabulek bez primárních klíčů. Potom,
$dbs.each |String $db| {
exec { "mysql-duplicate-index-$db" :který shromažďuje duplicitní indexy, které existují v databázových tabulkách.
Čáry dále generují grafy na základě shromážděných metrik. Toto jsou následující řádky,
exec { "generate-graph-total-rows" :
...
exec { "generate-graph-total-len" :
…Jakmile se dotaz úspěšně spustí, vygeneruje graf, který závisí na rozhraní API poskytovaném na https://quickchart.io/.
Zde jsou následující výsledky grafu:
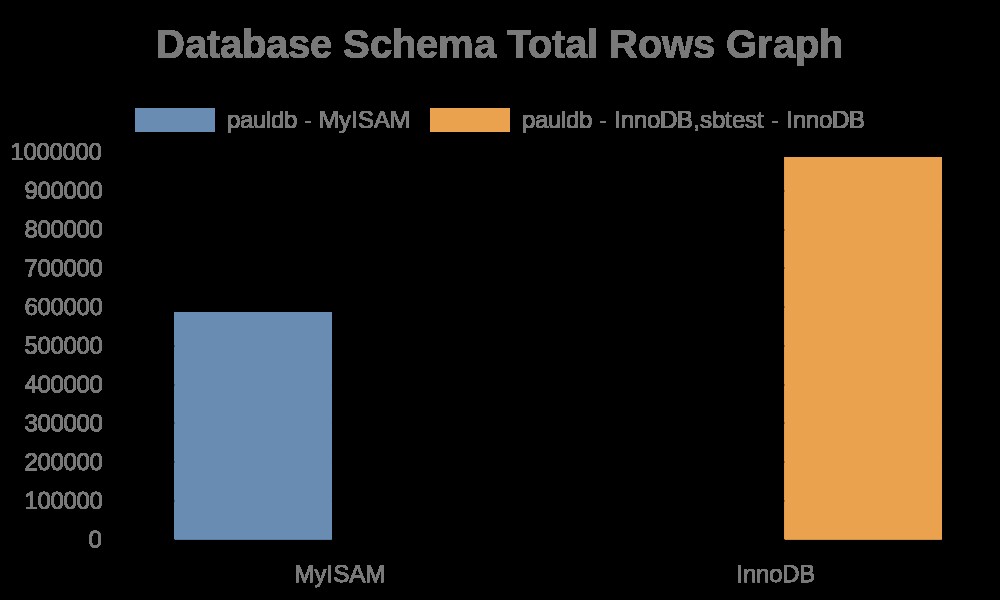
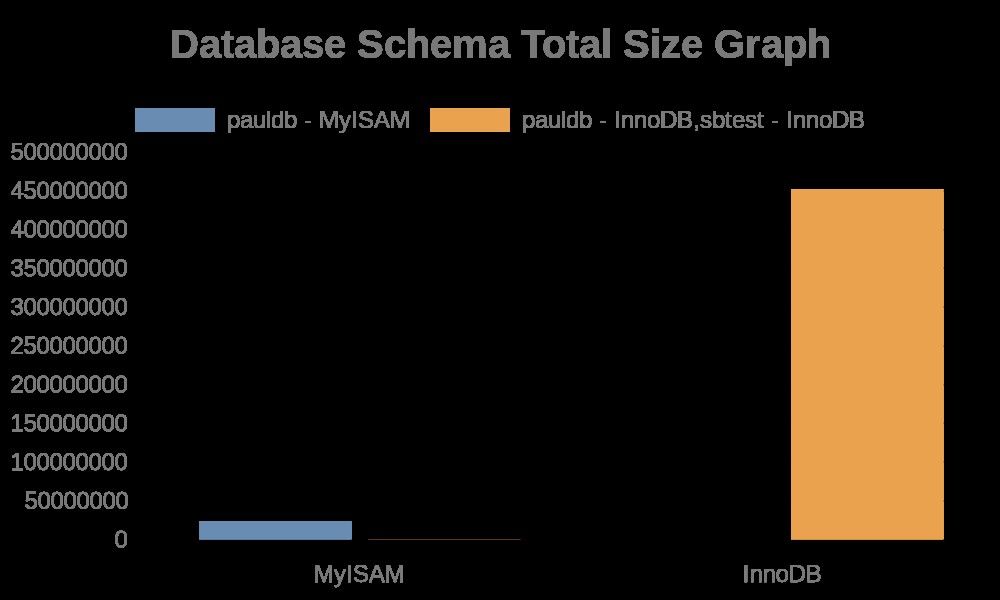
Protože protokoly souborů jednoduše obsahují řetězce s názvy tabulek, názvy indexů. Podívejte se na výsledek níže,
example@sqldat.com:~# tail -n+1 /opt/schema_change_mon/assets/*.log
==> /opt/schema_change_mon/assets/dupe-indexes.log <==
pauldb.c.my_index(n,i)
pauldb.c.my_index2(n,i)
pauldb.d.a_b(a,b)
pauldb.d.a_b2(a,b)
pauldb.d.a_b3(a)
pauldb.d.a_b3(a)
pauldb.t3.b(b)
pauldb.c.my_index(n,i)
pauldb.c.my_index2(n,i)
pauldb.d.a_b(a,b)
pauldb.d.a_b2(a,b)
pauldb.d.a_b3(a)
pauldb.d.a_b3(a)
pauldb.t3.b(b)
==> /opt/schema_change_mon/assets/no-pk.log <==
pauldb.b, MyISAM
pauldb.c, InnoDB
pauldb.t2, InnoDB
pauldb.d, InnoDB
pauldb.b, MyISAM
pauldb.c, InnoDB
pauldb.t2, InnoDB
pauldb.d, InnoDBProč nepoužít ClusterControl?
Naše cvičení ukazuje automatizaci a získávání statistik schémat databáze, jako jsou změny nebo operace, ClusterControl poskytuje i toto. Kromě toho existují další funkce a nemusíte znovu vynalézat kolo. ClusterControl může poskytovat protokoly transakcí, jako jsou uváznutí, jak je uvedeno výše, nebo dlouhotrvající dotazy, jak je uvedeno níže:
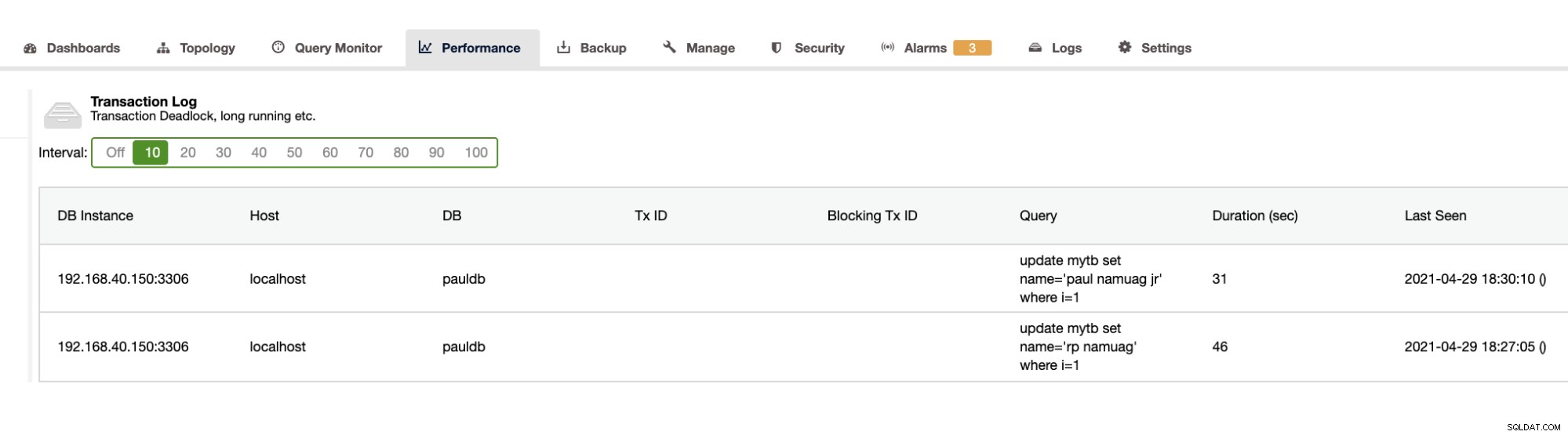
ClusterControl také ukazuje růst DB, jak je uvedeno níže,
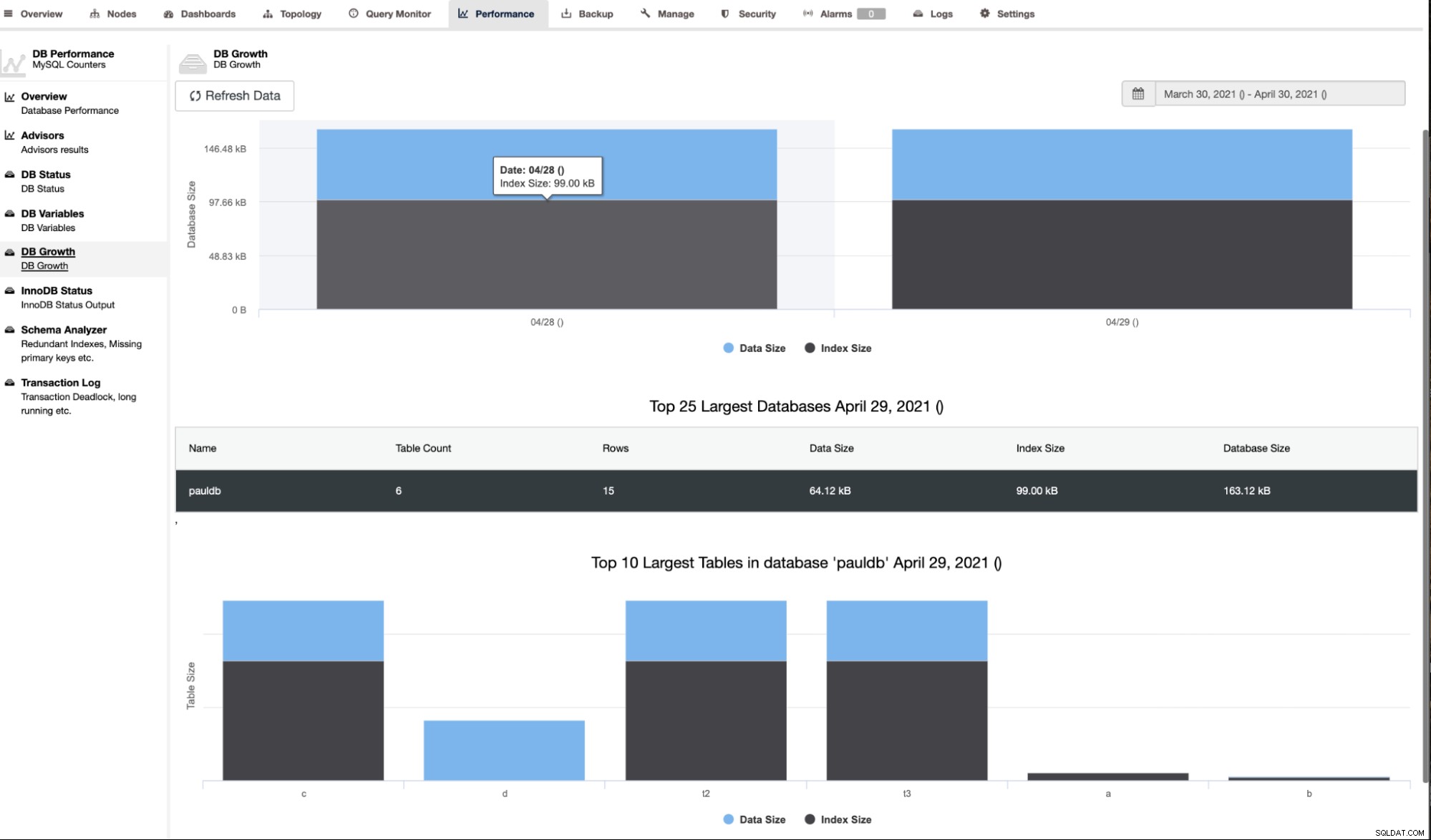
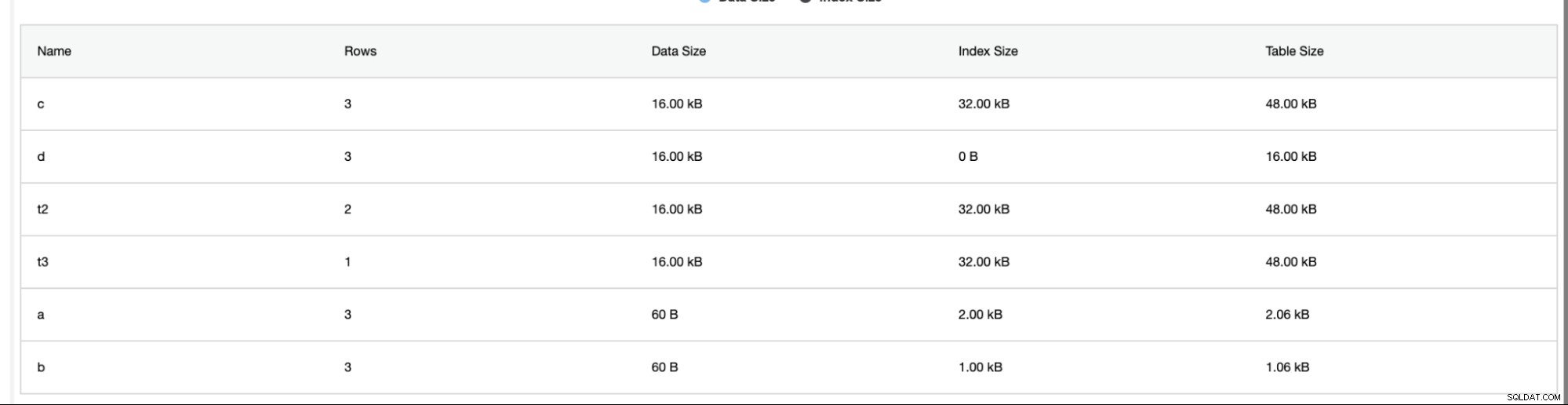
ClusterControl také poskytuje další informace, jako je počet řádků, velikost disku, velikost indexu a celková velikost.
Velmi užitečný je analyzátor schémat na kartě Výkon -> Analyzátor schémat. Poskytuje tabulky bez primárních klíčů, tabulky MyISAM a duplicitní indexy

Poskytuje také alarmy v případě, že jsou zjištěny duplicitní indexy nebo tabulky bez primárního kláves jako níže,

Další informace o ClusterControl a jeho dalších funkcích najdete na stránce našeho produktu.
Závěr
Poskytování automatizace pro sledování změn databáze nebo jakýchkoli statistik schémat, jako jsou zápisy, duplicitní indexy, aktualizace operací, jako jsou změny DDL, a mnoho databázových aktivit je pro správce databází velmi přínosné. Pomáhá rychle identifikovat slabé odkazy a problematické dotazy, které by vám poskytly přehled o možné příčině chybných dotazů, které by zablokovaly vaši databázi nebo ji zablokovaly.