Tyto testy (databáze AdventureWorks2008R2) ukazují, co se stane:
SET NOCOUNT ON;
SET STATISTICS IO ON;
PRINT 'Test #1';
SELECT p.BusinessEntityID, p.LastName
FROM Person.Person p
WHERE p.LastName LIKE '%be%';
PRINT 'Test #2';
DECLARE @Pattern NVARCHAR(50);
SET @Pattern=N'%be%';
SELECT p.BusinessEntityID, p.LastName
FROM Person.Person p
WHERE p.LastName LIKE @Pattern;
SET STATISTICS IO OFF;
SET NOCOUNT OFF;
Výsledky:
Test #1
Table 'Person'. Scan count 1, logical reads 106
Test #2
Table 'Person'. Scan count 1, logical reads 106
Výsledky z SET STATISTICS IO ukazuje, že LIO jsou stejné .Ale prováděcí plány jsou zcela odlišné: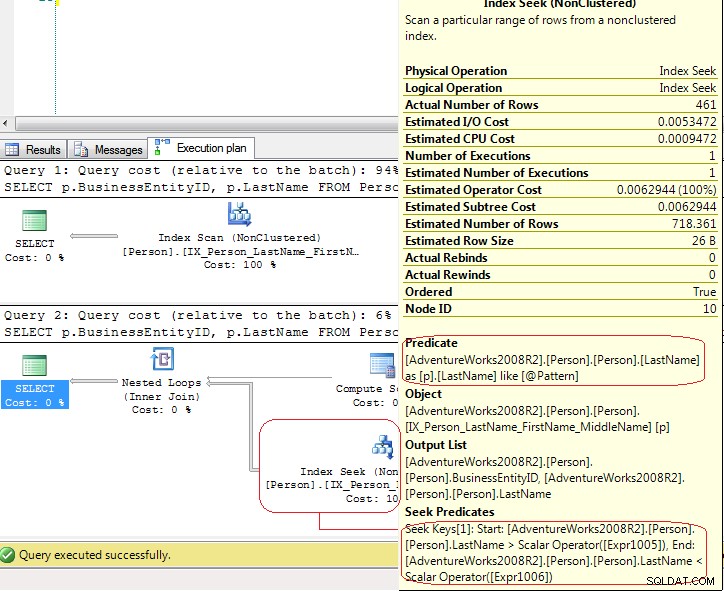
V prvním testu používá SQL Server Index Scan explicitní, ale ve druhém testu SQL Server používá Index Seek což je Index Seek - range scan . V posledním případě SQL Server používá Compute Scalar operátor generovat tyto hodnoty
[Expr1005] = Scalar Operator(LikeRangeStart([@Pattern])),
[Expr1006] = Scalar Operator(LikeRangeEnd([@Pattern])),
[Expr1007] = Scalar Operator(LikeRangeInfo([@Pattern]))
a Index Seek operátor používá Seek Predicate (optimalizováno) pro range scan (LastName > LikeRangeStart AND LastName < LikeRangeEnd ) plus další neoptimalizovaný Predicate (LastName LIKE @pattern ).
Moje odpověď:není to "skutečné" Index Seek . Je to Index Seek - range scan který má v tomto případě stejný výkon jako Index Scan .
Podívejte se také na rozdíl mezi Index Seek a Index Scan (podobná debata):Takže...je to hledání nebo skenování?
.
Úprava 1: Plán provádění pro OPTION(RECOMPILE) (viz Aaronovo doporučení prosím) ukazuje také Index Scan (místo Index Seek ):