Výkon je extrémně důležitý u mnoha spotřebitelských produktů, jako je elektronický obchod, platební systémy, hry, dopravní aplikace a tak dále. Ačkoli jsou databáze interně optimalizovány pomocí různých mechanismů, aby splňovaly jejich požadavky na výkon v moderním světě, hodně záleží také na vývojáři aplikace – koneckonců jen vývojář ví, jaké dotazy musí aplikace provádět.
Vývojáři, kteří se zabývají relačními databázemi, použili nebo alespoň slyšeli o indexování a je to velmi běžný koncept ve světě databází. Nejdůležitější je však pochopit, co indexovat a jak indexování prodlouží dobu odezvy na dotaz. K tomu musíte pochopit, jak budete dotazovat databázové tabulky. Správný index lze vytvořit pouze tehdy, když přesně víte, jak vypadají vaše dotazy a vzory přístupu k datům.
V jednoduché terminologii index mapuje vyhledávací klíče na odpovídající data na disku pomocí různých datových struktur v paměti a na disku. Index se používá k urychlení vyhledávání snížením počtu záznamů, které se mají hledat.
Většinou se index vytváří na sloupcích uvedených v WHERE klauzule dotazu, protože databáze načítá a filtruje data z tabulek na základě těchto sloupců. Pokud index nevytvoříte, databáze prohledá všechny řádky, odfiltruje odpovídající řádky a vrátí výsledek. S miliony záznamů může tato operace skenování trvat mnoho sekund a tato vysoká doba odezvy činí API a aplikace pomalejšími a nepoužitelnými. Podívejme se na příklad —
MySQL použijeme s výchozím databázovým strojem InnoDB, ačkoli koncepty vysvětlené v tomto článku jsou víceméně stejné na jiných databázových serverech, jako je Oracle, MSSQL atd.
Vytvořte tabulku s názvem index_demo s následujícím schématem:
CREATE TABLE index_demo (
name VARCHAR(20) NOT NULL,
age INT,
pan_no VARCHAR(20),
phone_no VARCHAR(20)
);Jak ověříme, že používáme InnoDB engine?
Spusťte níže uvedený příkaz:
SHOW TABLE STATUS WHERE name = 'index_demo' \G;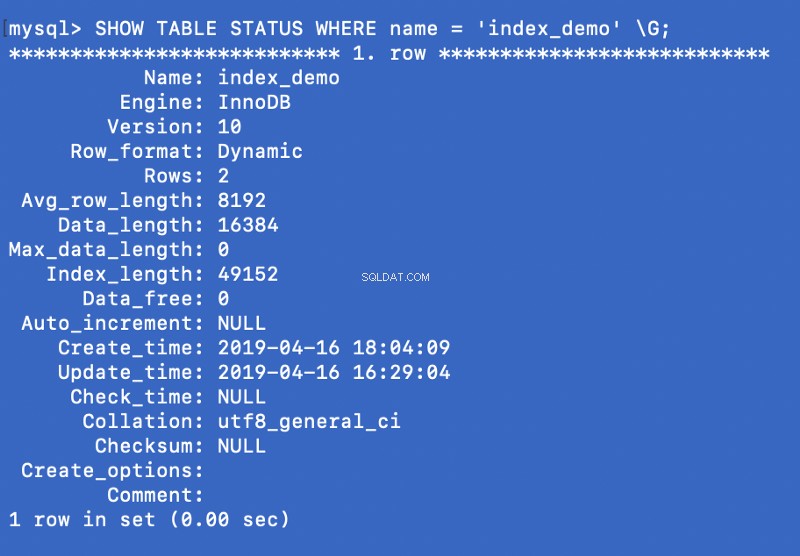
Engine sloupec na výše uvedeném snímku obrazovky představuje stroj, který se používá k vytvoření tabulky. Zde InnoDB se používá.
Nyní vložte do tabulky nějaká náhodná data, moje tabulka s 5 řádky vypadá takto:
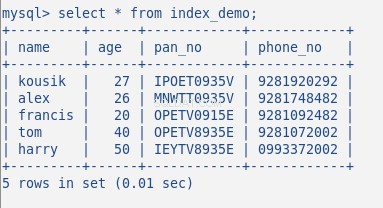
Dosud jsem na této tabulce nevytvořil žádný index. Ověříme to příkazem:SHOW INDEX . Vrátí 0 výsledků.

V tuto chvíli, pokud spustíme jednoduchý SELECT dotaz, protože neexistuje žádný uživatelsky definovaný index, dotaz prohledá celou tabulku, aby zjistil výsledek:
EXPLAIN SELECT * FROM index_demo WHERE name = 'alex';
EXPLAIN ukazuje, jak dotazovací stroj plánuje provést dotaz. Na výše uvedeném snímku obrazovky můžete vidět, že rows sloupec vrátí 5 &possible_keys vrátí null . possible_keys představuje všechny dostupné indexy, které lze v tomto dotazu použít. key sloupec představuje, který index bude skutečně použit ze všech možných indexů v tomto dotazu.
Primární klíč:
Výše uvedený dotaz je velmi neefektivní. Pojďme tento dotaz optimalizovat. Vytvoříme phone_no sloupec a PRIMARY KEY za předpokladu, že v našem systému nemohou existovat dva uživatelé se stejným telefonním číslem. Při vytváření primárního klíče vezměte v úvahu následující:
- Primární klíč by měl být součástí mnoha důležitých dotazů ve vaší aplikaci.
- Primární klíč je omezení, které jednoznačně identifikuje každý řádek v tabulce. Pokud je součástí primárního klíče více sloupců, měla by být tato kombinace pro každý řádek jedinečná.
- Primární klíč by neměl být null. Nikdy nepoužívejte pole s možností null jako primární klíč. Podle standardů ANSI SQL by primární klíče měly být vzájemně srovnatelné a určitě byste měli být schopni říct, zda je hodnota sloupce primárního klíče pro konkrétní řádek větší, menší nebo stejná jako v jiném řádku. Od
NULLznamená nedefinovanou hodnotu ve standardech SQL, nemůžete deterministicky porovnávatNULLs jakoukoli jinou hodnotou, takže logickyNULLnení povoleno. - Ideálním typem primárního klíče by mělo být číslo jako
INTneboBIGINTprotože porovnávání celých čísel je rychlejší, takže procházení indexem bude velmi rychlé.
Často definujeme id pole jako AUTO INCREMENT v tabulkách a použijte jej jako primární klíč, ale výběr primárního klíče závisí na vývojářích.
Co když si žádný primární klíč nevytvoříte sami?
Vytvoření primárního klíče není povinné. Pokud jste nedefinovali žádný primární klíč, InnoDB vám ho implicitně vytvoří, protože InnoDB musí mít primární klíč v každé tabulce. Jakmile tedy později pro tuto tabulku vytvoříte primární klíč, InnoDB smaže dříve automaticky definovaný primární klíč.
Protože zatím nemáme definován žádný primární klíč, podívejme se, co pro nás InnoDB ve výchozím nastavení vytvořilo:
SHOW EXTENDED INDEX FROM index_demo;
EXTENDED zobrazuje všechny indexy, které nejsou použitelné pro uživatele, ale jsou plně spravovány MySQL.
Zde vidíme, že MySQL definovalo složený index (o složených indexech se budeme bavit později) na DB_ROW_ID , DB_TRX_ID , DB_ROLL_PTR a všechny sloupce definované v tabulce. V případě nepřítomnosti uživatelem definovaného primárního klíče se tento index používá k jedinečnému nalezení záznamů.
Jaký je rozdíl mezi klíčem a indexem?
Ačkoli výrazy key &index se používají zaměnitelně, key znamená omezení uvalené na chování sloupu. V tomto případě je omezením, že primárním klíčem je pole bez možnosti null, které jednoznačně identifikuje každý řádek. Na druhou stranu index je speciální datová struktura, která usnadňuje vyhledávání dat v tabulce.
Nyní vytvoříme primární index na phone_no &prozkoumat vytvořený index:
ALTER TABLE index_demo ADD PRIMARY KEY (phone_no);
SHOW INDEXES FROM index_demo;
Všimněte si, že CREATE INDEX nelze použít k vytvoření primárního indexu, ale ALTER TABLE se používá.

Na výše uvedeném snímku obrazovky vidíme, že jeden primární index je vytvořen ve sloupci phone_no . Sloupce následujících obrázků jsou popsány následovně:
Table :Tabulka, ve které je vytvořen index.
Non_unique :Pokud je hodnota 1, index není jedinečný, pokud je hodnota 0, index je jedinečný.
Key_name :Název vytvořeného indexu. Název primárního indexu je vždy PRIMARY v MySQL, bez ohledu na to, zda jste při vytváření indexu zadali nějaké jméno indexu či nikoli.
Seq_in_index :Pořadové číslo sloupce v indexu. Pokud je součástí indexu více sloupců, bude pořadové číslo přiřazeno na základě toho, jak byly sloupce seřazeny během vytváření indexu. Pořadové číslo začíná od 1.
Collation :jak je sloupec řazen v indexu. A znamená vzestupně, D znamená sestupně, NULL znamená neseřazeno.
Cardinality :Odhadovaný počet jedinečných hodnot v indexu. Větší mohutnost znamená vyšší pravděpodobnost, že optimalizátor dotazů vybere index pro dotazy.
Sub_part :Předpona indexu. Je to NULL pokud je indexován celý sloupec. Jinak zobrazuje počet indexovaných bajtů v případě, že je sloupec částečně indexován. Částečný index definujeme později.
Packed :Označuje, jak je klíč zabalen; NULL pokud tomu tak není.
Null :YES pokud sloupec může obsahovat NULL hodnoty a prázdné, pokud tomu tak není.
Index_type :Označuje, která datová struktura indexování se používá pro tento index. Někteří možní kandidáti jsou — BTREE , HASH , RTREE nebo FULLTEXT .
Comment :Informace o indexu, které nejsou popsány ve vlastním sloupci.
Index_comment :Komentář pro index zadaný při vytváření indexu pomocí COMMENT atribut.
Nyní se podívejme, zda tento index snižuje počet řádků, které budou prohledány pro dané phone_no v WHERE klauzule dotazu.
EXPLAIN SELECT * FROM index_demo WHERE phone_no = '9281072002';
Na tomto snímku si všimněte, že rows sloupec vrátil 1 pouze possible_keys &key oba vrátí PRIMARY . Takže to v podstatě znamená, že pomocí primárního indexu s názvem PRIMARY (název se automaticky přiřadí, když vytvoříte primární klíč), optimalizátor dotazů přejde přímo k záznamu a načte jej. Je to velmi efektivní. Přesně k tomu slouží index – minimalizovat rozsah vyhledávání za cenu dalšího prostoru.
Shlukovaný index:
clustered index je umístěna s daty ve stejném tabulkovém prostoru nebo na stejném disku. Můžete zvážit, že seskupený index je B-Tree index, jehož listové uzly jsou skutečnými datovými bloky na disku, protože index a data jsou umístěny společně. Tento druh indexu fyzicky organizuje data na disku podle logického pořadí indexového klíče.
Co znamená fyzická organizace dat?
Fyzicky jsou data organizována na disku přes tisíce nebo miliony diskových / datových bloků. U seskupeného indexu není povinné, aby byly všechny bloky disku uloženy nakažlivě. Fyzické datové bloky OS neustále přesouvá sem a tam, kdykoli je to nutné. Databázový systém nemá žádnou absolutní kontrolu nad tím, jak je spravován fyzický datový prostor, ale uvnitř datového bloku lze záznamy ukládat nebo spravovat v logickém pořadí indexového klíče. Vysvětluje to následující zjednodušený diagram:
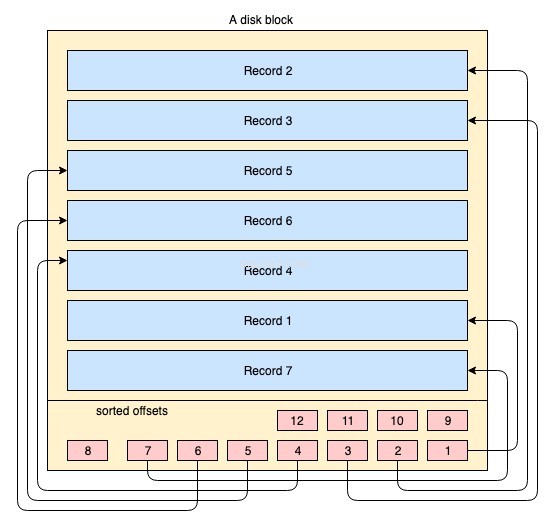
- Žlutý velký obdélník představuje diskový blok / blok dat
- modře zbarvené obdélníky představují data uložená jako řádky uvnitř daného bloku
- oblast zápatí představuje index bloku, kde se nacházejí červené malé obdélníky seřazené podle konkrétního klíče. Tyto malé bloky nejsou nic jiného než jakési ukazatele ukazující na offsety záznamů.
Záznamy se ukládají na diskový blok v libovolném pořadí. Kdykoli jsou přidány nové záznamy, přidají se na další dostupné místo. Kdykoli je existující záznam aktualizován, OS rozhodne, zda se tento záznam může stále vejít na stejnou pozici, nebo je pro tento záznam třeba alokovat novou pozici.
Pozice záznamů je tedy plně řízena OS a neexistuje žádný určitý vztah mezi pořadím jakýchkoli dvou záznamů. Aby bylo možné načíst záznamy v logickém pořadí klíče, stránky disku obsahují sekci indexu v zápatí, index obsahuje seznam ukazatelů posunu v pořadí podle klíče. Při každé změně nebo vytvoření záznamu se index upraví.
Tímto způsobem se opravdu nemusíte starat o skutečné uspořádání fyzického záznamu v určitém pořadí, spíše se v tomto pořadí udržuje malá sekce indexu a načítání nebo údržba záznamů je velmi snadná.
Výhoda seskupeného indexu:
Toto řazení nebo společné umístění souvisejících dat ve skutečnosti zrychluje seskupený index. Když jsou data načtena z disku, systém čte celý blok obsahující data, protože náš diskový IO systém zapisuje a čte data v blocích. Takže v případě dotazů na rozsah je docela možné, že se sdružená data ukládají do paměti. Řekněme, že spustíte následující dotaz:
SELECT * FROM index_demo WHERE phone_no > '9010000000' AND phone_no < '9020000000'
Datový blok je načten do paměti při provádění dotazu. Řekněme, že datový blok obsahuje phone_no v rozsahu od 9010000000 na 9030000000 . Jakýkoli rozsah, který jste v dotazu požadovali, je tedy pouze podmnožinou dat přítomných v bloku. Pokud nyní spustíte další dotaz, abyste získali všechna telefonní čísla v rozsahu, řekněme z 9015000000 na 9019000000 , nemusíte načítat žádné další bloky z disku. Kompletní data lze nalézt v aktuálním bloku dat, tedy clustered_index snižuje počet vstupů a výstupů disku tím, že související data co nejvíce uspořádá do stejného datového bloku. Toto snížení IO disku způsobuje zlepšení výkonu.
Takže pokud máte primární klíč dobře promyšlený a vaše dotazy jsou založeny na primárním klíči, výkon bude super rychlý.
Omezení sdruženého indexu:
Protože seskupený index ovlivňuje fyzickou organizaci dat, může existovat pouze jeden seskupený index na tabulku.
Vztah mezi primárním klíčem a seskupeným indexem:
Clusterový index nemůžete vytvořit ručně pomocí InnoDB v MySQL. MySQL to vybere za vás. Ale jak se vybírá? Následující výňatky jsou z dokumentace MySQL:
Když definujetePRIMARY KEYna vašem stole,InnoDBpoužívá jej jako seskupený index. Definujte primární klíč pro každou tabulku, kterou vytvoříte. Pokud neexistuje žádný logický jedinečný a nenulový sloupec nebo sada sloupců, přidejte nový sloupec s automatickým přírůstkem, jehož hodnoty se doplní automaticky.
Pokud nedefinujetePRIMARY KEYpro vaši tabulku MySQL najde prvníUNIQUEindex, kde všechny klíčové sloupce jsouNOT NULLaInnoDBpoužívá jej jako seskupený index.
Pokud tabulka nemáPRIMARY KEYnebo vhodnéUNIQUEindex,InnoDBinterně generuje skrytý seskupený index s názvemGEN_CLUST_INDEXna syntetický sloupec obsahující hodnoty ID řádku. Řádky jsou seřazeny podle ID, kteréInnoDBpřiřadí k řádkům v takové tabulce. ID řádku je 6bajtové pole, které se monotónně zvětšuje při vkládání nových řádků. Řádky seřazené podle ID řádku jsou tedy fyzicky v pořadí vložení.
Stručně řečeno, jádro MySQL InnoDB ve skutečnosti spravuje primární index jako seskupený index pro zlepšení výkonu, takže primární klíč a skutečný záznam na disku jsou seskupeny dohromady.
Struktura primárního klíče (seskupeného) indexu:
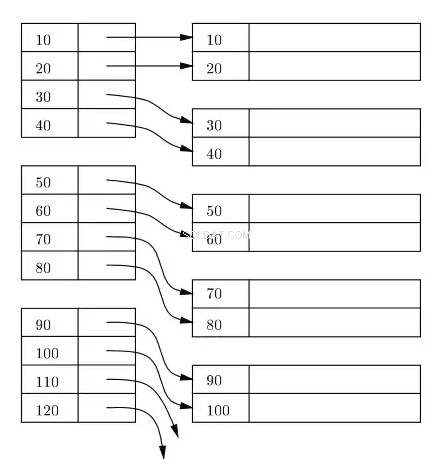
Index je obvykle udržován jako strom B+ na disku a v paměti a jakýkoli index je uložen v blocích na disku. Tyto bloky se nazývají indexové bloky. Záznamy v indexovém bloku jsou vždy seřazeny podle indexu/klíče vyhledávání. Blok listového indexu indexu obsahuje lokátor řádků. Pro primární index odkazuje lokátor řádků na virtuální adresu odpovídajícího fyzického umístění datových bloků na disku, kde se nacházejí řádky, které jsou seřazeny podle klíče indexu.
V následujícím diagramu představují obdélníky na levé straně indexové bloky na úrovni listu a obdélníky na pravé straně představují datové bloky. Logicky se zdá, že datové bloky jsou zarovnány v seřazeném pořadí, ale jak již bylo popsáno dříve, skutečná fyzická umístění mohou být rozptýlena sem a tam.
Je možné vytvořit primární index na neprimárním klíči?
V MySQL se automaticky vytvoří primární index a jak si MySQL vybírá primární index, jsme již popsali výše. Ale v databázovém světě ve skutečnosti není nutné vytvářet index ve sloupci primárního klíče – primární index lze vytvořit také na libovolném sloupci jiného než primárního klíče. Ale když jsou vytvořeny na primárním klíči, všechny položky klíče jsou v indexu jedinečné, zatímco v druhém případě může mít primární index také duplicitní klíč.
Je možné smazat primární klíč?
Primární klíč je možné smazat. Když odstraníte primární klíč, související seskupený index i vlastnost jedinečnosti tohoto sloupce se ztratí.
ALTER TABLE `index_demo` DROP PRIMARY KEY;
- If the primary key does not exist, you get the following error:
"ERROR 1091 (42000): Can't DROP 'PRIMARY'; check that column/key exists"Výhody primárního indexu:
- Dotazy na rozsah založené na primárním indexu jsou velmi účinné. Může existovat možnost, že blok disku, který databáze načetla z disku, obsahuje všechna data patřící k dotazu, protože primární index je seskupený a záznamy jsou uspořádány fyzicky. Lokalitu dat tedy může poskytnout primární index.
- Jakýkoli dotaz, který využívá primární klíč, je velmi rychlý.
Nevýhody primárního indexu:
- Vzhledem k tomu, že primární index obsahuje přímý odkaz na adresu datového bloku prostřednictvím virtuálního adresového prostoru a diskové bloky jsou fyzicky organizovány v pořadí podle indexového klíče, pokaždé, když OS rozdělí nějakou stránku na disku kvůli
DMLoperace jakoINSERT/UPDATE/DELETE, je třeba aktualizovat i primární index. TakžeDMLoperace vyvíjí určitý tlak na výkon primárního indexu.
Sekundární index:
Jakýkoli index jiný než seskupený index se nazývá sekundární index. Sekundární indexy neovlivňují umístění fyzického úložiště na rozdíl od primárních indexů.
Kdy potřebujete sekundární index?
Ve své aplikaci můžete mít několik případů použití, kdy se do databáze nedotazujete primárním klíčem. V našem příkladu phone_no je primární klíč, ale možná budeme muset do databáze zadat dotaz pomocí pan_no , nebo name . V takových případech potřebujete sekundární indexy na těchto sloupcích, pokud je frekvence takových dotazů velmi vysoká.
Jak vytvořit sekundární index v MySQL?
Následující příkaz vytvoří sekundární index v name ve sloupci index_demo tabulka.
CREATE INDEX secondary_idx_1 ON index_demo (name);
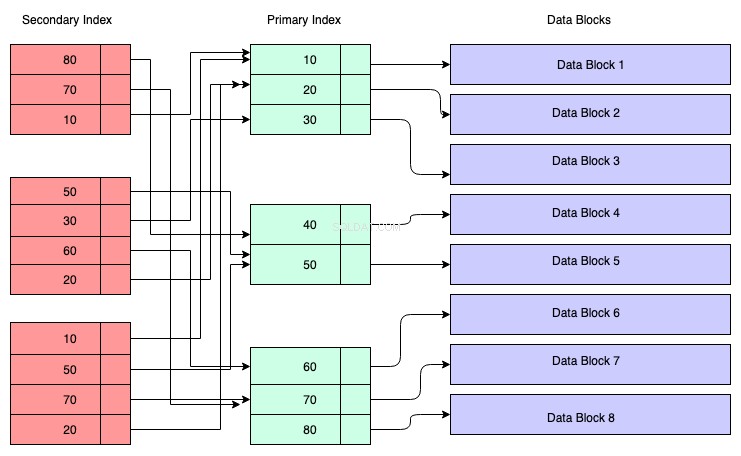
Struktura sekundárního indexu:
V níže uvedeném diagramu představují červeně zbarvené obdélníky sekundární indexové bloky. Sekundární index je také udržován ve Stromu B+ a je řazen podle klíče, na kterém byl index vytvořen. Listové uzly obsahují kopii klíče odpovídajících dat v primárním indexu.
Abychom to pochopili, můžete předpokládat, že sekundární index odkazuje na adresu primárního klíče, i když tomu tak není. Získávání dat prostřednictvím sekundárního indexu znamená, že musíte procházet dva stromy B+ – jeden je samotný sekundární index indexu B+ a druhý je primární strom indexu B+.
Výhody sekundárního indexu:
Logicky můžete vytvořit tolik sekundárních indexů, kolik chcete. Ale ve skutečnosti, kolik indexů je skutečně potřeba, vyžaduje seriózní myšlenkový proces, protože každý index má svůj vlastní postih.
Nevýhody sekundárního indexu:
Pomocí DML operace jako DELETE / INSERT , je také potřeba aktualizovat sekundární index, aby bylo možné odstranit/vložit kopii sloupce primárního klíče. V takových případech může existence velkého množství sekundárních indexů způsobit problémy.
Také, pokud je primární klíč velmi velký jako URL Protože sekundární indexy obsahují kopii hodnoty sloupce primárního klíče, může být z hlediska úložiště neefektivní. Více sekundárních klíčů znamená větší počet duplicitních kopií hodnoty sloupce primárního klíče, takže větší úložiště v případě velkého primárního klíče. Také samotný primární klíč ukládá klíče, takže kombinovaný účinek na úložiště bude velmi vysoký.
Uvážení před odstraněním primárního indexu:
V MySQL můžete odstranit primární index vypuštěním primárního klíče. Již jsme viděli, že sekundární index závisí na primárním indexu. Pokud tedy odstraníte primární index, všechny sekundární indexy se musí aktualizovat, aby obsahovaly kopii nového primárního indexového klíče, který MySQL automaticky upraví.
Tento proces je drahý, pokud existuje několik sekundárních indexů. Také jiné tabulky mohou mít odkaz na cizí klíč na primární klíč, takže před odstraněním primárního klíče musíte tyto odkazy na cizí klíč odstranit.
Když je primární klíč smazán, MySQL automaticky vytvoří další primární klíč interně, a to je nákladná operace.
JEDINEČNÝ index klíče:
Stejně jako primární klíče mohou jedinečné klíče také jednoznačně identifikovat záznamy s jedním rozdílem – sloupec jedinečného klíče může obsahovat null hodnoty.
Na rozdíl od jiných databázových serverů může mít v MySQL sloupec jedinečného klíče tolik null hodnoty, jak je to možné. Ve standardu SQL null znamená nedefinovanou hodnotu. Pokud tedy MySQL musí obsahovat pouze jeden null hodnotu ve sloupci jedinečného klíče, musí předpokládat, že všechny hodnoty null jsou stejné.
Ale logicky to není správné, protože null znamená nedefinováno – a nedefinované hodnoty nelze vzájemně porovnávat, je to povaha null . Protože MySQL nemůže potvrdit, zda jsou všechny null s znamená totéž, umožňuje více null hodnoty ve sloupci.
Následující příkaz ukazuje, jak vytvořit jedinečný index klíče v MySQL:
CREATE UNIQUE INDEX unique_idx_1 ON index_demo (pan_no);
Složený index:
MySQL vám umožňuje definovat indexy ve více sloupcích, až 16 sloupcích. Tento index se nazývá Multi-column / Composite / Compound index.
Řekněme, že máme index definovaný na 4 sloupcích — col1 , col2 , col3 , col4 . Díky složenému indexu máme možnost vyhledávání na col1 , (col1, col2) , (col1, col2, col3) , (col1, col2, col3, col4) . Můžeme tedy použít libovolnou levou předponu indexovaných sloupců, ale nemůžeme vynechat sloupec uprostřed a použít to jako — (col1, col3) nebo (col1, col2, col4) nebo col3 nebo col4 atd. Toto jsou neplatné kombinace.
Následující příkazy vytvoří v naší tabulce 2 složené indexy:
CREATE INDEX composite_index_1 ON index_demo (phone_no, name, age);
CREATE INDEX composite_index_2 ON index_demo (pan_no, name, age);
Pokud máte dotazy obsahující WHERE klauzuli na více sloupcích, zapište klauzuli v pořadí sloupců složeného indexu. Index bude pro tento dotaz přínosem. Ve skutečnosti při rozhodování o sloupcích pro složený index můžete analyzovat různé případy použití vašeho systému a pokusit se přijít s pořadím sloupců, které bude ku prospěchu většiny vašich případů použití.
Složené indexy vám mohou pomoci v JOIN &SELECT také dotazy. Příklad:v následujícím SELECT * dotaz, composite_index_2 se používá.

Když je definováno několik indexů, optimalizátor dotazů MySQL vybere ten index, který eliminuje největší počet řádků nebo prohledává co nejméně řádků pro lepší efektivitu.
Proč používáme složené indexy ? Proč nedefinovat více sekundárních indexů ve sloupcích, které nás zajímají?
MySQL používá pouze jeden index na tabulku a dotaz kromě UNION. (V UNIONu je každý logický dotaz spuštěn samostatně a výsledky jsou sloučeny.) Takže definování více indexů ve více sloupcích nezaručuje, že tyto indexy budou použity, i když jsou součástí dotazu.
MySQL udržuje něco, čemu se říká indexová statistika, která pomáhá MySQL odvodit, jak data v systému vypadají. Statistika indexu je sice zobecněním, ale na základě těchto metadat MySQL rozhodne, který index je vhodný pro aktuální dotaz.
Jak složený index funguje?
Sloupce používané ve složených indexech jsou zřetězeny dohromady a tyto zřetězené klíče jsou uloženy v setříděném pořadí pomocí B+ stromu. Když provádíte vyhledávání, zřetězení vašich vyhledávacích klíčů se porovnává s klíči složeného indexu. Pokud potom dojde k nějakému nesouladu mezi řazením vašich vyhledávacích klíčů a řazením sloupců složeného indexu, index nelze použít.
V našem příkladu pro následující záznam je složený indexový klíč vytvořen zřetězením pan_no , name , age — HJKXS9086Wkousik28 .
+--------+------+------------+------------+
name
age
pan_no
phone_no
+--------+------+------------+------------+
kousik
28
HJKXS9086W
9090909090Jak zjistit, zda potřebujete složený index:
- Nejprve analyzujte své dotazy podle vašich případů použití. Pokud uvidíte, že se určitá pole v mnoha dotazech objevují společně, můžete zvážit vytvoření složeného indexu.
- Pokud vytváříte index v
col1&složený index v (col1,col2), pak by měl být v pořádku pouze složený index.col1samotný složený index může být obsluhován samotným složeným indexem, protože se jedná o levou předponu indexu. - Zvažte mohutnost. Pokud mají sloupce použité ve složeném indexu dohromady vysokou mohutnost, jsou vhodnými kandidáty pro složený index.
Krycí index:
Krycí index je speciální druh složeného indexu, kde všechny sloupce zadané v dotazu někde v indexu existují. Optimalizátor dotazů tedy nemusí zasáhnout databázi, aby získal data – spíše získá výsledek ze samotného indexu. Příklad:již jsme definovali složený index pro (pan_no, name, age) , takže nyní zvažte následující dotaz:
SELECT age FROM index_demo WHERE pan_no = 'HJKXS9086W' AND name = 'kousik'
Sloupce uvedené v SELECT &WHERE doložky jsou součástí složeného indexu. Takže v tomto případě můžeme skutečně získat hodnotu age sloupec ze samotného složeného indexu. Podívejme se, co je EXPLAIN příkaz zobrazí pro tento dotaz:
EXPLAIN FORMAT=JSON SELECT age FROM index_demo WHERE pan_no = 'HJKXS9086W' AND name = '111kousik1';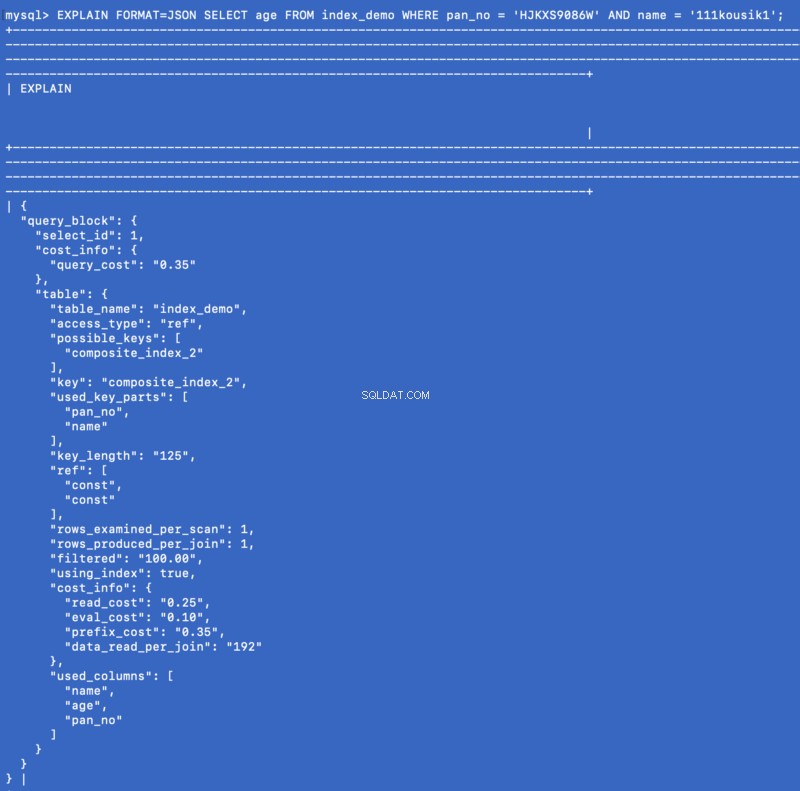
Ve výše uvedené odpovědi si všimněte, že existuje klíč — using_index která je nastavena na true což znamená, že k zodpovězení dotazu byl použit krycí index.
Nevím, jak moc jsou krycí indexy oceňovány v produkčním prostředí, ale zdá se, že je to dobrá optimalizace pro případ, že by dotaz vyhovoval.
Částečný index:
Již víme, že indexy zrychlují naše dotazy za cenu místa. Čím více indexů máte, tím větší jsou požadavky na úložiště. Již jsme vytvořili index nazvaný secondary_idx_1 ve sloupci name . Sloupec name může obsahovat velké hodnoty libovolné délky. Také v indexu mají metadata lokátorů řádků nebo ukazatelů řádků svou vlastní velikost. Celkově tedy index může mít vysoké zatížení úložiště a paměti.
V MySQL je také možné vytvořit index na prvních několika bytech dat. Příklad:následující příkaz vytvoří index na prvních 4 bajtech názvu. Ačkoli tato metoda snižuje režii paměti o určitou hodnotu, index nemůže odstranit mnoho řádků, protože v tomto příkladu mohou být první 4 bajty společné pro mnoho jmen. Obvykle je tento druh indexování prefixů podporován na CHAR ,VARCHAR , BINARY , VARBINARY typ sloupců.
CREATE INDEX secondary_index_1 ON index_demo (name(4));Co se stane pod pokličkou, když definujeme index?
Spusťte SHOW EXTENDED příkaz znovu:
SHOW EXTENDED INDEXES FROM index_demo;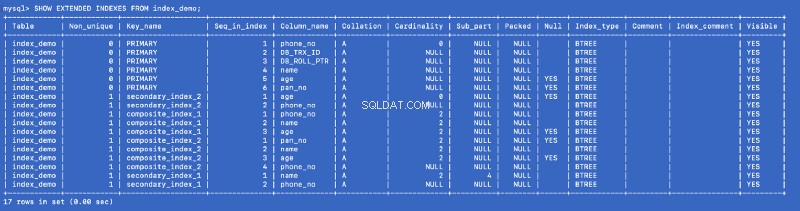
Definovali jsme secondary_index_1 na name , ale MySQL vytvořilo složený index na (name , phone_no ), kde phone_no je sloupec primárního klíče. Vytvořili jsme secondary_index_2 na age &MySQL vytvořil složený index na (age , phone_no ). Vytvořili jsme composite_index_2 zapnuto (pan_no , name , age ) &MySQL vytvořilo složený index na (pan_no , name , age , phone_no ). Složený index composite_index_1 již má phone_no jako jeho součást.
Ať už tedy vytvoříme jakýkoli index, MySQL na pozadí vytvoří podpůrný složený index, který obratem ukazuje na primární klíč. To znamená, že primární klíč je prvotřídní občan ve světě indexování MySQL. It also proves that all the indexes are backed by a copy of the primary index —but I am not sure whether a single copy of the primary index is shared or different copies are used for different indexes.
There are many other indices as well like Spatial index and Full Text Search index offered by MySQL. I have not yet experimented with those indices, so I’m not discussing them in this post.
General Indexing guidelines:
- Since indices consume extra memory, carefully decide how many &what type of index will suffice your need.
- With
DMLoperations, indices are updated, so write operations are quite costly with indexes. The more indices you have, the greater the cost. Indexes are used to make read operations faster. So if you have a system that is write heavy but not read heavy, think hard about whether you need an index or not. - Cardinality is important — cardinality means the number of distinct values in a column. If you create an index in a column that has low cardinality, that’s not going to be beneficial since the index should reduce search space. Low cardinality does not significantly reduce search space.
Example:if you create an index on a boolean (int1or0only ) type column, the index will be very skewed since cardinality is less (cardinality is 2 here). But if this boolean field can be combined with other columns to produce high cardinality, go for that index when necessary. - Indices might need some maintenance as well if old data still remains in the index. They need to be deleted otherwise memory will be hogged, so try to have a monitoring plan for your indices.
In the end, it’s extremely important to understand the different aspects of database indexing. It will help while doing low level system designing. Many real-life optimizations of our applications depend on knowledge of such intricate details. A carefully chosen index will surely help you boost up your application’s performance.
Please do clap &share with your friends &on social media if you like this article. :)
References:
- https://dev.mysql.com/doc/refman/5.7/en/innodb-index-types.html
- https://www.quora.com/What-is-difference-between-primary-index-and-secondary-index-exactly-And-whats-advantage-of-one-over-another
- https://dev.mysql.com/doc/refman/8.0/en/create-index.html
- https://www.oreilly.com/library/view/high-performance-mysql/0596003064/ch04.html
- https://www.unofficialmysqlguide.com/covering-indexes.html
- https://dev.mysql.com/doc/refman/8.0/en/multiple-column-indexes.html
- https://dev.mysql.com/doc/refman/8.0/en/show-index.html
- https://dev.mysql.com/doc/refman/8.0/en/create-index.html