V předchozím příspěvku jsme diskutovali o tom, jak ověřit, že replikace MySQL je v dobrém stavu. Podívali jsme se také na některé typické problémy. V tomto příspěvku se podíváme na některé další problémy, se kterými se můžete setkat při řešení replikace MySQL.
Chybějící nebo duplicitní záznamy
To je něco, co by se nemělo stávat, přesto se to stává velmi často – situace, kdy SQL příkaz provedený na masteru uspěje, ale stejný příkaz provedený na jednom z slave selže. Hlavním důvodem je slave drift - něco (obvykle chybné transakce, ale také jiné problémy nebo chyby v replikaci) způsobuje, že se slave liší od svého mastera. Například řádek, který existoval na masteru, neexistuje na slave a nelze jej odstranit ani aktualizovat. Jak často se tento problém objeví, závisí především na vašem nastavení replikace. Stručně řečeno, existují tři způsoby, jak MySQL ukládá události binárního protokolu. Za prvé, „příkaz“ znamená, že SQL je zapsán jako prostý text, stejně jako byl spuštěn na masteru. Toto nastavení má nejvyšší toleranci na slave drift, ale také nemůže zaručit slave konzistenci – je těžké ho doporučit ve výrobě. Druhý formát, „řádek“, ukládá výsledek dotazu místo příkazu dotazu. Událost může vypadat například takto:
### UPDATE `test`.`tab`
### WHERE
### @1=2
### @2=5
### SET
### @1=2
### @2=4To znamená, že aktualizujeme řádek v tabulce 'tab' ve schématu 'test', kde první sloupec má hodnotu 2 a druhý sloupec má hodnotu 5. První sloupec nastavíme na 2 (hodnota se nemění) a druhý sloupec na 4. Jak vidíte, není zde moc prostoru pro interpretaci - je přesně definováno, který řádek se používá a jak se mění. Výsledkem je, že tento formát je skvělý pro konzistenci slave, ale jak si dokážete představit, je velmi zranitelný, pokud jde o posun dat. Přesto je to doporučený způsob spouštění replikace MySQL.
Konečně třetí, „smíšený“, funguje tak, že události, které lze bezpečně zapsat ve formě příkazů, používají formát „příkaz“. Ty, které by mohly způsobit posun dat, budou používat „řádkový“ formát.
Jak je odhalíte?
Jako obvykle nám SHOW SLAVE STATUS pomůže identifikovat problém.
Last_SQL_Errno: 1032
Last_SQL_Error: Could not execute Update_rows event on table test.tab; Can't find record in 'tab', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000021, end_log_pos 970 Last_SQL_Errno: 1062
Last_SQL_Error: Could not execute Write_rows event on table test.tab; Duplicate entry '3' for key 'PRIMARY', Error_code: 1062; handler error HA_ERR_FOUND_DUPP_KEY; the event's master log binlog.000021, end_log_pos 1229Jak vidíte, chyby jsou jasné a samozřejmé (a jsou v zásadě totožné mezi MySQL a MariaDB.
Jak problém vyřešíte?
To je bohužel ta složitá část. Nejprve musíte určit zdroj pravdy. Který hostitel obsahuje správná data? Pán nebo otrok? Obvykle byste předpokládali, že je to hlavní, ale nepředpokládáte to ve výchozím nastavení - prozkoumejte! Je možné, že po převzetí služeb při selhání některá část vydávané aplikace stále zapisuje do starého hlavního serveru, který nyní funguje jako slave. Je možné, že pouze pro čtení nebylo na tomto hostiteli správně nastaveno, nebo možná aplikace používá k připojení k databázi superuživatele (ano, viděli jsme to v produkčním prostředí). V takovém případě by otrok mohl být zdrojem pravdy – alespoň do určité míry.
V závislosti na tom, která data by měla zůstat a která by měla odejít, by nejlepším postupem bylo určit, co je potřeba k obnovení synchronizace replikace. Za prvé, replikace je rozbitá, takže se tomu musíte věnovat. Přihlaste se do hlavního serveru a zkontrolujte binární protokol, i když způsobil přerušení replikace.
Retrieved_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1106672
Executed_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1-1106671Jak vidíte, chybí nám jedna událost:5d1e2227-07c6-11e7-8123-080027495a77:1106672. Zkontrolujeme to v binárních protokolech hlavního:
mysqlbinlog -v --include-gtids='5d1e2227-07c6-11e7-8123-080027495a77:1106672' /var/lib/mysql/binlog.000021
#170320 20:53:37 server id 1 end_log_pos 1066 CRC32 0xc582a367 GTID last_committed=3 sequence_number=4
SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106672'/*!*/;
# at 1066
#170320 20:53:37 server id 1 end_log_pos 1138 CRC32 0x6f33754d Query thread_id=5285 exec_time=0 error_code=0
SET TIMESTAMP=1490043217/*!*/;
SET @@session.pseudo_thread_id=5285/*!*/;
SET @@session.foreign_key_checks=1, @@session.sql_auto_is_null=0, @@session.unique_checks=1, @@session.autocommit=1/*!*/;
SET @@session.sql_mode=1436549152/*!*/;
SET @@session.auto_increment_increment=1, @@session.auto_increment_offset=1/*!*/;
/*!\C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
SET @@session.lc_time_names=0/*!*/;
SET @@session.collation_database=DEFAULT/*!*/;
BEGIN
/*!*/;
# at 1138
#170320 20:53:37 server id 1 end_log_pos 1185 CRC32 0xa00b1f59 Table_map: `test`.`tab` mapped to number 571
# at 1185
#170320 20:53:37 server id 1 end_log_pos 1229 CRC32 0x5597e50a Write_rows: table id 571 flags: STMT_END_F
BINLOG '
UUHQWBMBAAAALwAAAKEEAAAAADsCAAAAAAEABHRlc3QAA3RhYgACAwMAAlkfC6A=
UUHQWB4BAAAALAAAAM0EAAAAADsCAAAAAAEAAgAC//wDAAAABwAAAArll1U=
'/*!*/;
### INSERT INTO `test`.`tab`
### SET
### @1=3
### @2=7
# at 1229
#170320 20:53:37 server id 1 end_log_pos 1260 CRC32 0xbbc3367c Xid = 5224257
COMMIT/*!*/;Vidíme, že to byla vložka, která nastavuje první sloupec na 3 a druhý na 7. Pojďme si ověřit, jak naše tabulka nyní vypadá:
mysql> SELECT * FROM test.tab;
+----+------+
| id | b |
+----+------+
| 1 | 2 |
| 2 | 4 |
| 3 | 10 |
+----+------+
3 rows in set (0.01 sec)Nyní máme dvě možnosti podle toho, která data by měla převažovat. Pokud jsou na masteru správná data, můžeme jednoduše smazat řádek s id=3 na slave. Jen se ujistěte, že jste zakázali binární protokolování, abyste se vyhnuli zavádění chybných transakcí. Na druhou stranu, pokud jsme se rozhodli, že správná data jsou na slave, musíme spustit příkaz REPLACE na masteru, abychom nastavili řádek s id=3 na opravu obsahu (3, 10) z aktuálního (3, 7). Na podřízeném zařízení však budeme muset přeskočit aktuální GTID (nebo přesněji budeme muset vytvořit prázdnou událost GTID), abychom mohli replikaci restartovat.
Smazání řádku na podřízeném je jednoduché:
SET SESSION log_bin=0; DELETE FROM test.tab WHERE id=3; SET SESSION log_bin=1;Vložení prázdného GTID je téměř stejně jednoduché:
mysql> SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106672';
Query OK, 0 rows affected (0.00 sec)mysql> BEGIN;
Query OK, 0 rows affected (0.00 sec)mysql> COMMIT;
Query OK, 0 rows affected (0.00 sec)mysql> SET @@SESSION.GTID_NEXT=automatic;
Query OK, 0 rows affected (0.00 sec)Další metodou řešení tohoto konkrétního problému (pokud přijímáme master jako zdroj pravdy) je použití nástrojů jako pt-table-checksum a pt-table-sync k identifikaci toho, kde slave není konzistentní se svým masterem a co SQL musí být proveden na master, aby se slave vrátil zpět do synchronizace. Bohužel je tato metoda spíše náročná – do hlavního serveru se přidává velké zatížení a do replikačního proudu se zapisuje spousta dotazů, což může ovlivnit zpoždění na podřízených zařízeních a obecný výkon nastavení replikace. To platí zejména v případě, že existuje značný počet řádků, které je třeba synchronizovat.
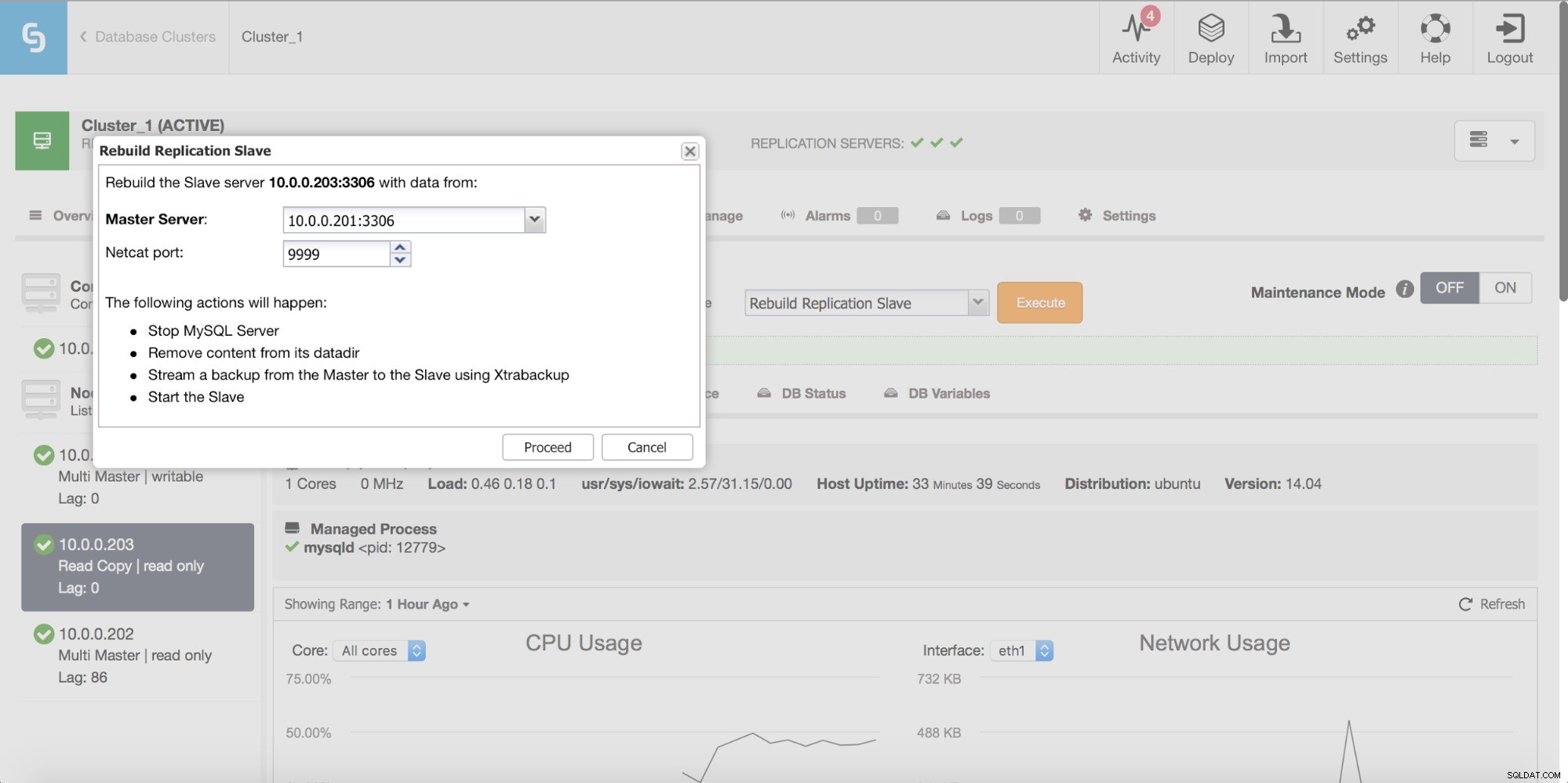
Nakonec, jako vždy, můžete znovu sestavit svého slave pomocí dat z mastera - tímto způsobem si můžete být jisti, že slave bude aktualizován nejnovějšími a aktuálními daty. To ve skutečnosti nemusí být nutně špatný nápad - když mluvíme o velkém počtu řádků, které se mají synchronizovat pomocí pt-table-checksum/pt-table-sync, přináší to značnou režii ve výkonu replikace, celkovém CPU a I/O. zatížení a člověkohodin.
ClusterControl vám umožňuje přestavět slave zařízení pomocí nové kopie hlavních dat.
Kontrola konzistence
Jak jsme zmínili v předchozí kapitole, konzistence se může stát vážným problémem a může způsobit mnoho bolestí hlavy uživatelům, kteří používají nastavení replikace MySQL. Podívejme se, jak můžete ověřit, že jsou vaši podřízení MySQL synchronizováni s hlavním serverem a co s tím můžete dělat.
Jak zjistit nekonzistentní Slave
Bohužel typickým způsobem, jak uživatel zjistí, že slave je nekonzistentní, je narazit na jeden z problémů, které jsme zmínili v předchozí kapitole. Aby se předešlo tomu, že je vyžadováno proaktivní monitorování konzistence slave. Pojďme se podívat, jak to lze provést.
Použijeme nástroj z Percona Toolkit:pt-table-checksum. Je navržen tak, aby skenoval replikační cluster a identifikoval případné nesrovnalosti.
Vytvořili jsme vlastní scénář pomocí sysbench a zavedli jsme trochu nekonzistence na jednom z otroků. Co je důležité (pokud to chcete otestovat jako my), musíte použít níže uvedenou opravu, která přinutí pt-table-checksum rozpoznat schéma „sbtest“ jako nesystémové schéma:
--- pt-table-checksum 2016-12-15 14:31:07.000000000 +0000
+++ pt-table-checksum-fix 2017-03-21 20:32:53.282254794 +0000
@@ -7614,7 +7614,7 @@
my $filter = $self->{filters};
- if ( $db =~ m/information_schema|performance_schema|lost\+found|percona|percona_schema|test/ ) {
+ if ( $db =~ m/information_schema|performance_schema|lost\+found|percona|percona_schema|^test/ ) {
PTDEBUG && _d('Database', $db, 'is a system database, ignoring');
return 0;
}Nejprve provedeme pt-table-checksum následujícím způsobem:
master:~# ./pt-table-checksum --max-lag=5 --user=sbtest --password=sbtest --no-check-binlog-format --databases='sbtest'
TS ERRORS DIFFS ROWS CHUNKS SKIPPED TIME TABLE
03-21T20:33:30 0 0 1000000 15 0 27.103 sbtest.sbtest1
03-21T20:33:57 0 1 1000000 17 0 26.785 sbtest.sbtest2
03-21T20:34:26 0 0 1000000 15 0 28.503 sbtest.sbtest3
03-21T20:34:52 0 0 1000000 18 0 26.021 sbtest.sbtest4
03-21T20:35:34 0 0 1000000 17 0 42.730 sbtest.sbtest5
03-21T20:36:04 0 0 1000000 16 0 29.309 sbtest.sbtest6
03-21T20:36:42 0 0 1000000 15 0 38.071 sbtest.sbtest7
03-21T20:37:16 0 0 1000000 12 0 33.737 sbtest.sbtest8Několik důležitých poznámek o tom, jak jsme nástroj vyvolali. Za prvé, uživatel, kterého nastavíme, musí existovat na všech podřízených zařízeních. Pokud chcete, můžete také použít „--slave-user“ k definování jiného, méně privilegovaného uživatele pro přístup k podřízeným. Další věc, která stojí za vysvětlení - používáme replikaci založenou na řádcích, která není plně kompatibilní s kontrolním součtem pt-table-checksum. Pokud máte replikaci založenou na řádcích, stane se to, že pt-table-checksum změní binární formát protokolu na úrovni relace na „příkaz“, protože toto je jediný podporovaný formát. Problém je v tom, že taková změna bude fungovat pouze na první úrovni podřízených jednotek, které jsou přímo připojeny k masteru. Pokud máte středně pokročilé mastery (tedy více než jednu úroveň slave), použití pt-table-checksum může přerušit replikaci. To je důvod, proč ve výchozím nastavení, pokud nástroj zjistí replikaci založenou na řádcích, ukončí se a vypíše chybu:
„Replika slave1 má binlog_format ROW, což by mohlo způsobit přerušení replikace kontrolním součtem tabulky pt. Přečtěte si prosím "Repliky používající replikaci založenou na řádcích" v části OMEZENÍ dokumentace nástroje. Pokud rozumíte rizikům, zadejte --no-check-binlog-format pro zakázání této kontroly.“
Použili jsme pouze jednu úroveň otroků, takže bylo bezpečné zadat „--no-check-binlog-format“ a jít vpřed.
Nakonec jsme nastavili maximální zpoždění na 5 sekund. Pokud bude tohoto prahu dosaženo, pt-table-checksum se pozastaví na dobu potřebnou k tomu, aby se zpoždění dostalo pod prahovou hodnotu.
Jak jste mohli vidět z výstupu,
03-21T20:33:57 0 1 1000000 17 0 26.785 sbtest.sbtest2v tabulce sbtest.sbtest2 byla zjištěna nekonzistence.
Ve výchozím nastavení pt-table-checksum ukládá kontrolní součty do tabulky percona.checksums. Tato data lze použít pro jiný nástroj z Percona Toolkit, pt-table-sync, k identifikaci, které části tabulky by měly být podrobně zkontrolovány, aby se zjistil přesný rozdíl v datech.
Jak opravit Inconsistent Slave
Jak bylo uvedeno výše, použijeme k tomu pt-table-sync. V našem případě použijeme data shromážděná pomocí pt-table-checksum, i když je také možné nasměrovat pt-table-sync na dva hostitele (master a slave) a porovná všechna data na obou hostitelích. Je to rozhodně časově a na zdroje náročnější proces, takže pokud již máte data z kontrolního součtu pt-table-checksum, je mnohem lepší jej používat. Takto jsme to provedli, abychom otestovali výstup:
master:~# ./pt-table-sync --user=sbtest --password=sbtest --databases=sbtest --replicate percona.checksums h=master --printREPLACE INTO `sbtest`.`sbtest2`(`id`, `k`, `c`, `pad`) VALUES ('1', '434041', '61753673565-14739672440-12887544709-74227036147-86382758284-62912436480-22536544941-50641666437-36404946534-73544093889', '23608763234-05826685838-82708573685-48410807053-00139962956') /*percona-toolkit src_db:sbtest src_tbl:sbtest2 src_dsn:h=10.0.0.101,p=...,u=sbtest dst_db:sbtest dst_tbl:sbtest2 dst_dsn:h=10.0.0.103,p=...,u=sbtest lock:1 transaction:1 changing_src:percona.checksums replicate:percona.checksums bidirectional:0 pid:25776 user:root host:vagrant-ubuntu-trusty-64*/;Jak můžete vidět, v důsledku toho bylo vygenerováno nějaké SQL. Důležité je poznamenat, že proměnná --replicate. Zde se stane, že nasměrujeme pt-table-sync na tabulku vygenerovanou pt-table-checksum. Také jej nasměrujeme na master.
Pro ověření, zda SQL dává smysl, jsme použili volbu --print. Vezměte prosím na vědomí, že vygenerovaný SQL je platný pouze v době, kdy byl vygenerován – nemůžete ho ve skutečnosti někam uložit, zkontrolovat a poté spustit. Jediné, co můžete udělat, je ověřit, zda má SQL nějaký smysl, a ihned poté znovu spustit nástroj s příznakem --execute:
master:~# ./pt-table-sync --user=sbtest --password=sbtest --databases=sbtest --replicate percona.checksums h=10.0.0.101 --executeTo by mělo zajistit synchronizaci slave s masterem. Můžeme to ověřit pomocí pt-table-checksum:
example@sqldat.com:~# ./pt-table-checksum --max-lag=5 --user=sbtest --password=sbtest --no-check-binlog-format --databases='sbtest'
TS ERRORS DIFFS ROWS CHUNKS SKIPPED TIME TABLE
03-21T21:36:04 0 0 1000000 13 0 23.749 sbtest.sbtest1
03-21T21:36:26 0 0 1000000 7 0 22.333 sbtest.sbtest2
03-21T21:36:51 0 0 1000000 10 0 24.780 sbtest.sbtest3
03-21T21:37:11 0 0 1000000 14 0 19.782 sbtest.sbtest4
03-21T21:37:42 0 0 1000000 15 0 30.954 sbtest.sbtest5
03-21T21:38:07 0 0 1000000 15 0 25.593 sbtest.sbtest6
03-21T21:38:27 0 0 1000000 16 0 19.339 sbtest.sbtest7
03-21T21:38:44 0 0 1000000 15 0 17.371 sbtest.sbtest8Jak můžete vidět, v tabulce sbtest.sbtest2 již nejsou žádné rozdíly.
Doufáme, že pro vás byl tento příspěvek na blogu informativní a užitečný. Kliknutím sem se dozvíte více o replikaci MySQL. Pokud máte nějaké dotazy nebo návrhy, neváhejte nás kontaktovat prostřednictvím komentářů níže.