Replikace je jedním z nejběžnějších způsobů, jak dosáhnout vysoké dostupnosti pro MySQL a MariaDB. S přidáním GTID se stal mnohem robustnějším a je důkladně testován tisíci a tisíci uživatelů. Replikace MySQL však není vlastnost „nastav a zapomeň“, je třeba ji monitorovat kvůli potenciálním problémům a udržovat ji, aby zůstala v dobrém stavu. V tomto příspěvku na blogu bychom se rádi podělili o několik tipů a triků, jak udržovat, odstraňovat a opravovat problémy s replikací MySQL.
Jak zjistit, zda je replikace MySQL v dobrém stavu?
Toto je nejdůležitější dovednost, kterou musí mít každý, kdo se stará o nastavení replikace MySQL. Pojďme se podívat, kde hledat informace o stavu replikace. Mezi MySQL a MariaDB je malý rozdíl a budeme o tom také diskutovat.
ZOBRAZIT STAV SLAVE
Toto je nejběžnější metoda kontroly stavu replikace na podřízeném hostiteli – máme ji odjakživa a je to obvykle první místo, kam jdeme, pokud očekáváme, že s replikací dojde k nějakému problému.
mysql> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.0.101
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000002
Read_Master_Log_Pos: 767658564
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 405
Relay_Master_Log_File: binlog.000002
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 767658564
Relay_Log_Space: 606
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_UUID: 5d1e2227-07c6-11e7-8123-080027495a77
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1-394233
Auto_Position: 1
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
1 row in set (0.00 sec)Některé detaily se mohou mezi MySQL a MariaDB lišit, ale většina obsahu bude vypadat stejně. Změny budou viditelné v sekci GTID, protože MySQL a MariaDB to dělají jiným způsobem. Z SHOW SLAVE STATUS můžete odvodit některé informace - který master se používá, který uživatel a který port se používá pro připojení k master. Máme nějaké údaje o aktuální pozici binárního logu (už to není tak důležité, protože můžeme použít GTID a zapomenout na binlogy) a stavu vláken SQL a I/O replikace. Poté můžete vidět, zda a jak je nakonfigurováno filtrování. Můžete také najít nějaké informace o chybách, zpoždění replikace, nastavení SSL a GTID. Výše uvedený příklad pochází z MySQL 5.7 slave, který je ve zdravém stavu. Podívejme se na nějaký příklad, kde je replikace přerušena.
MariaDB [test]> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.0.104
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000003
Read_Master_Log_Pos: 636
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 765
Relay_Master_Log_File: binlog.000003
Slave_IO_Running: Yes
Slave_SQL_Running: No
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 1032
Last_Error: Could not execute Update_rows_v1 event on table test.tab; Can't find record in 'tab', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000003, end_log_pos 609
Skip_Counter: 0
Exec_Master_Log_Pos: 480
Relay_Log_Space: 1213
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: NULL
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 1032
Last_SQL_Error: Could not execute Update_rows_v1 event on table test.tab; Can't find record in 'tab', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000003, end_log_pos 609
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 0-1-73243
Replicate_Do_Domain_Ids:
Replicate_Ignore_Domain_Ids:
Parallel_Mode: conservative
1 row in set (0.00 sec)Tato ukázka je převzata z MariaDB 10.1, změny můžete vidět ve spodní části výstupu, aby fungoval s MariaDB GTID. Pro nás je důležitá chyba – ve vláknu SQL můžete vidět, že něco není v pořádku:
Last_SQL_Error: Could not execute Update_rows_v1 event on table test.tab; Can't find record in 'tab', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000003, end_log_pos 609Tento konkrétní problém probereme později, prozatím postačí, když uvidíte, jak můžete zkontrolovat, zda v replikaci nejsou nějaké chyby pomocí SHOW SLAVE STATUS.
Další důležitou informací, která pochází z SHOW SLAVE STATUS, je - jak moc náš otrok zaostává. Můžete to zkontrolovat ve sloupci „Seconds_Behind_Master“. Tuto metriku je zvláště důležité sledovat, pokud víte, že vaše aplikace je citlivá, pokud jde o zastaralé čtení.
V ClusterControl můžete tato data sledovat v sekci „Přehled“:
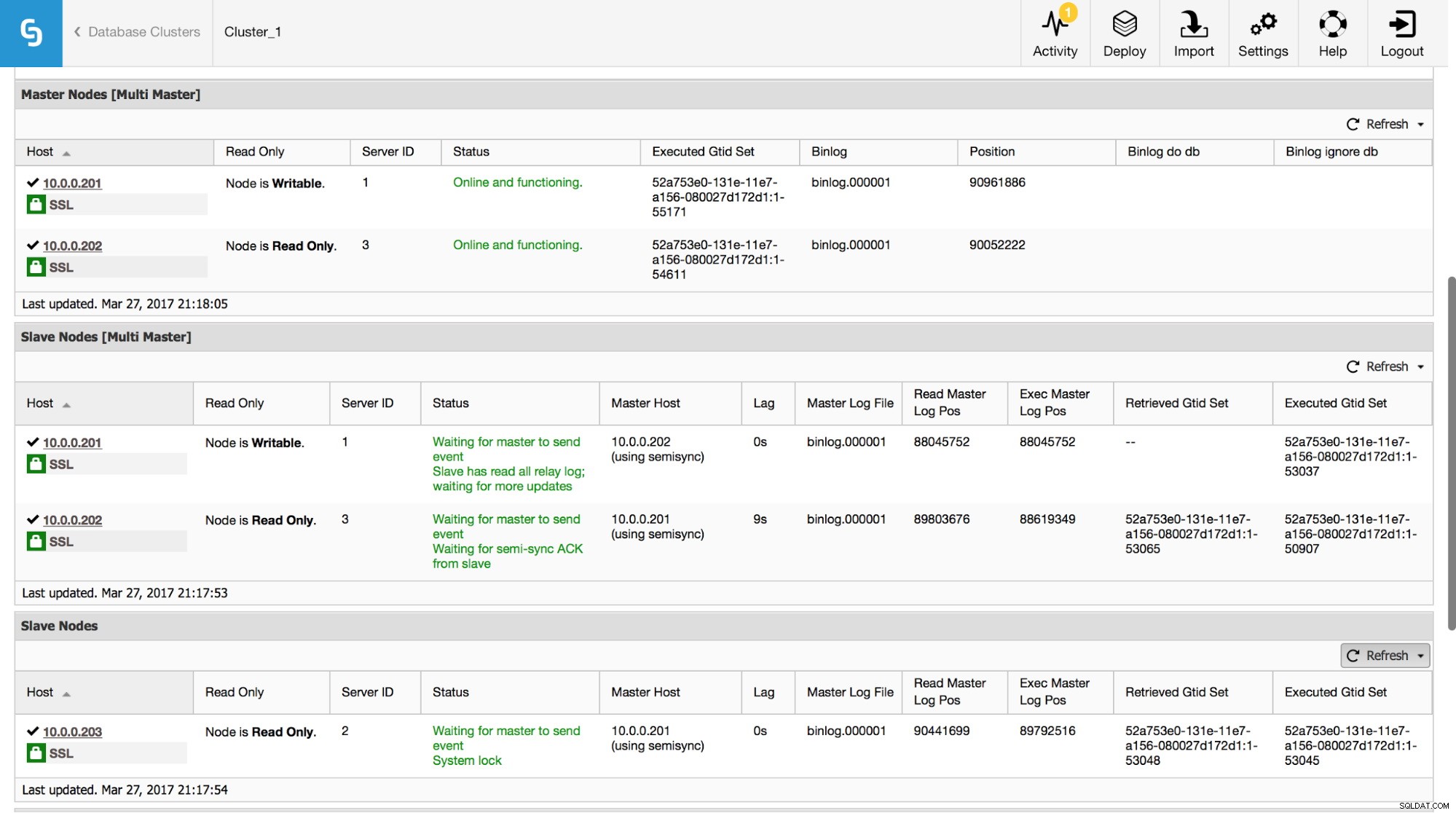
Zviditelnili jsme všechny nejdůležitější informace z příkazu SHOW SLAVE STATUS. Můžete zkontrolovat stav replikace, kdo je hlavní, zda existuje zpoždění replikace nebo ne, pozice binárního protokolu. Můžete také najít získaná a provedená GTID.
Schéma výkonu
Dalším místem, kde můžete hledat informace o replikaci, je performance_schema. To platí pouze pro Oracle MySQL 5.7 – starší verze a MariaDB tato data neshromažďují.
mysql> SHOW TABLES FROM performance_schema LIKE 'replication%';
+---------------------------------------------+
| Tables_in_performance_schema (replication%) |
+---------------------------------------------+
| replication_applier_configuration |
| replication_applier_status |
| replication_applier_status_by_coordinator |
| replication_applier_status_by_worker |
| replication_connection_configuration |
| replication_connection_status |
| replication_group_member_stats |
| replication_group_members |
+---------------------------------------------+
8 rows in set (0.00 sec)Níže naleznete některé příklady dat dostupných v některých z těchto tabulek.
mysql> select * from replication_connection_status\G
*************************** 1. row ***************************
CHANNEL_NAME:
GROUP_NAME:
SOURCE_UUID: 5d1e2227-07c6-11e7-8123-080027495a77
THREAD_ID: 32
SERVICE_STATE: ON
COUNT_RECEIVED_HEARTBEATS: 1
LAST_HEARTBEAT_TIMESTAMP: 2017-03-17 19:41:34
RECEIVED_TRANSACTION_SET: 5d1e2227-07c6-11e7-8123-080027495a77:715599-724966
LAST_ERROR_NUMBER: 0
LAST_ERROR_MESSAGE:
LAST_ERROR_TIMESTAMP: 0000-00-00 00:00:00
1 row in set (0.00 sec)mysql> select * from replication_applier_status_by_worker\G
*************************** 1. row ***************************
CHANNEL_NAME:
WORKER_ID: 0
THREAD_ID: 31
SERVICE_STATE: ON
LAST_SEEN_TRANSACTION: 5d1e2227-07c6-11e7-8123-080027495a77:726086
LAST_ERROR_NUMBER: 0
LAST_ERROR_MESSAGE:
LAST_ERROR_TIMESTAMP: 0000-00-00 00:00:00
1 row in set (0.00 sec)Jak vidíte, můžeme ověřit stav replikace, poslední chybu, sadu přijatých transakcí a některá další data. Co je důležité – pokud jste povolili replikaci s více vlákny, v tabulce replication_applier_status_by_worker uvidíte stav každého jednotlivého pracovníka – to vám pomůže pochopit stav replikace pro každé z pracovních vláken.
Prodleva replikace
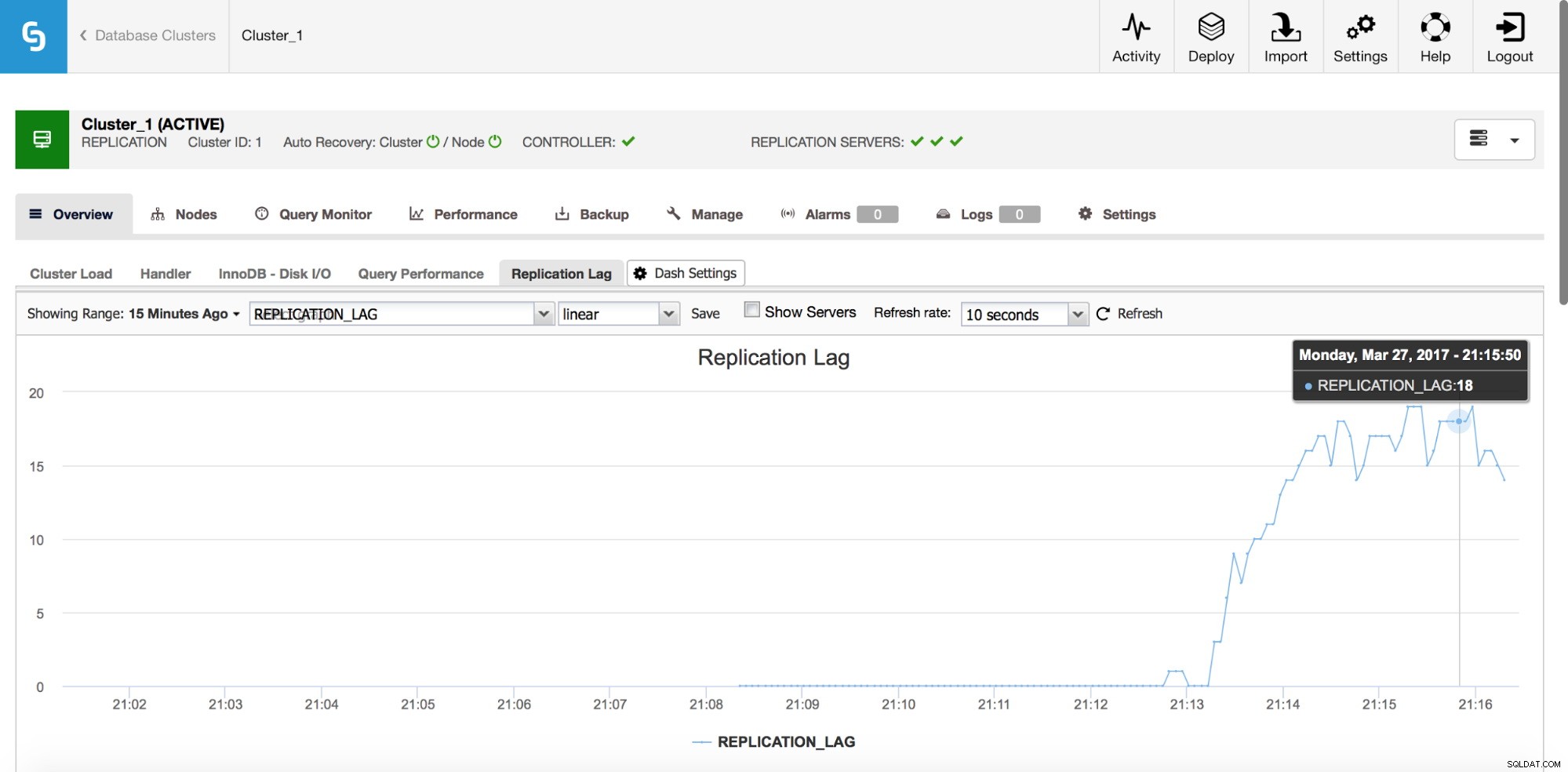
Prodleva je rozhodně jedním z nejčastějších problémů, se kterými se budete potýkat při práci s replikací MySQL. Zpoždění replikace se objeví, když jeden z podřízených jednotek není schopen držet krok s množstvím operací zápisu prováděných masterem. Důvody mohou být různé – jiná hardwarová konfigurace, větší zátěž na slave, vysoký stupeň paralelizace zápisu na masteru, který musí být serializován (když pro replikaci používáte jediné vlákno) nebo zápisy nelze paralelizovat ve stejném rozsahu jako doposud. byl na hlavním serveru (když používáte replikaci s více vlákny).
Jak to zjistit?
Existuje několik metod, jak zjistit zpoždění replikace. Nejprve můžete zaškrtnout „Seconds_Behind_Master“ ve výstupu SHOW SLAVE STATUS – to vám řekne, zda se slave zpožďuje nebo ne. Ve většině případů to funguje dobře, ale ve složitějších topologiích, když používáte mezilehlé mastery, na hostitelích někde níže v řetězci replikace, to nemusí být přesné. Dalším, lepším řešením je spolehnout se na externí nástroje, jako je pt-heartbeat. Myšlenka je jednoduchá – vytvoří se tabulka, mimo jiné se sloupcem časového razítka. Tento sloupec je na hlavním serveru v pravidelných intervalech aktualizován. Na otroku pak můžete porovnat časové razítko z tohoto sloupce s aktuálním časem – řekne vám, jak daleko za otrokem je.
Bez ohledu na způsob výpočtu zpoždění se ujistěte, že jsou vaši hostitelé časově synchronizovaní. Použijte ntpd nebo jiný způsob synchronizace času – pokud dojde k časovému posunu, uvidíte u svých otroků „falešné“ zpoždění.
Jak snížit zpoždění?
Na tuto otázku není snadné odpovědět. Stručně řečeno, záleží na tom, co způsobuje zpoždění a co se stalo úzkým hrdlem. Existují dva typické vzory – slave je I/O vázán, což znamená, že jeho I/O subsystém nezvládá množství operací zápisu a čtení. Za druhé – slave je vázán na CPU, což znamená, že vlákno replikace využívá veškerý CPU, který může (jedno vlákno může používat pouze jedno jádro CPU) a stále to nestačí na zpracování všech operací zápisu.
Když je CPU úzkým hrdlem, řešení může být stejně jednoduché jako použití vícevláknové replikace. Zvyšte počet pracovních vláken, abyste umožnili vyšší paralelizaci. Není to však vždy možné - v takovém případě si možná budete chtít pohrát s proměnnými skupinového potvrzení (jak pro MySQL, tak pro MariaDB), abyste zpozdili potvrzení o nepatrnou dobu (zde mluvíme o milisekundách) a tímto způsobem , zvýšit paralelizaci odevzdání.
Pokud je problém v I/O, je o něco těžší problém vyřešit. Samozřejmě byste měli zkontrolovat nastavení I/O InnoDB – možná je zde prostor pro vylepšení. Pokud ladění my.cnf nepomůže, nemáte příliš mnoho možností – zlepšit své dotazy (kde je to možné) nebo upgradovat I/O subsystém na něco schopnějšího.
Většina serverů proxy (například všechny servery proxy, které lze nasadit z ClusterControl:ProxySQL, HAProxy a MaxScale) vám dává možnost odebrat slave mimo rotaci, pokud zpoždění replikace překročí určitou předem definovanou hranici. Toto v žádném případě není způsob, jak zkrátit zpoždění, ale může být užitečné vyhnout se zastaralým čtením a jako vedlejší efekt snížit zatížení podřízeného zařízení, což by mu mělo pomoci dohnat.
Řešením v obou případech může být samozřejmě ladění dotazů – vždy je dobré vylepšit dotazy, které jsou náročné na CPU nebo I/O.
Chybné transakce
Chybné transakce jsou transakce, které byly provedeny pouze na podřízeném zařízení, nikoli na hlavním zařízení. Zkrátka dělají otroka v rozporu s pánem. Při použití replikace založené na GTID to může způsobit vážné problémy, pokud je slave povýšen na master. Máme podrobný příspěvek na toto téma a doporučujeme vám, abyste se na něj podívali a seznámili se s tím, jak odhalit a opravit problémy s chybnými transakcemi. Zahrnuli jsme také informace o tom, jak ClusterControl zjišťuje a zpracovává chybné transakce.
Žádný soubor Binlog na hlavním serveru
Jak identifikovat problém?
Za určitých okolností se může stát, že se slave připojí k masteru a požádá o neexistující binární log soubor. Jedním z důvodů může být chybná transakce – v určitém okamžiku byla transakce provedena na podřízeném zařízení a později se tento podřízený stal nadřízeným. Ostatní hostitelé, kteří jsou nakonfigurováni tak, aby slavili tohoto mastera, požádají o chybějící transakci. Pokud byl spuštěn před dlouhou dobou, existuje šance, že binární soubory protokolu již byly vyčištěny.
Další typičtější příklad – chcete zřídit slave pomocí xtrabackup. Zkopírujete zálohu na hostitele, použijete protokol, změníte vlastníka datového adresáře MySQL – typické operace, které provádíte při obnově zálohy. Provedete
SET GLOBAL gtid_purged=na základě dat z xtrabackup_binlog_info a spustíte CHANGE MASTER TO … MASTER_AUTO_POSITION=1 (toto je v MySQL, MariaDB má trochu jiný proces), spustíte slave a pak skončíte s chybou jako:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'v MySQL nebo:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'Could not find GTID state requested by slave in any binlog files. Probably the slave state is too old and required binlog files have been purged.'v MariaDB.
To v podstatě znamená, že master nemá všechny binární protokoly potřebné k provedení všech chybějících transakcí. S největší pravděpodobností je záloha příliš stará a hlavní server již vyčistil některé binární protokoly vytvořené mezi vytvořením zálohy a zřízením podřízeného zařízení.
Jak tento problém vyřešit?
Bohužel v tomto konkrétním případě nemůžete moc dělat. Pokud máte některé hostitele MySQL, kteří ukládají binární protokoly déle než hlavní server, můžete zkusit tyto protokoly použít k přehrání chybějících transakcí na podřízeném zařízení. Pojďme se podívat, jak to lze provést.
Nejprve se podívejme na nejstarší GTID v binárních protokolech hlavního:
mysql> SHOW BINARY LOGS\G
*************************** 1. row ***************************
Log_name: binlog.000021
File_size: 463
1 row in set (0.00 sec)„binlog.000021“ je tedy nejnovější (a jediný) soubor. Podívejme se, jaký je první záznam GTID v tomto souboru:
example@sqldat.com:~# mysqlbinlog /var/lib/mysql/binlog.000021
/*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=1*/;
/*!50003 SET @example@sqldat.com@COMPLETION_TYPE,COMPLETION_TYPE=0*/;
DELIMITER /*!*/;
# at 4
#170320 10:39:51 server id 1 end_log_pos 123 CRC32 0x5644fc9b Start: binlog v 4, server v 5.7.17-11-log created 170320 10:39:51
# Warning: this binlog is either in use or was not closed properly.
BINLOG '
d7HPWA8BAAAAdwAAAHsAAAABAAQANS43LjE3LTExLWxvZwAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAEzgNAAgAEgAEBAQEEgAAXwAEGggAAAAICAgCAAAACgoKKioAEjQA
AZv8RFY=
'/*!*/;
# at 123
#170320 10:39:51 server id 1 end_log_pos 194 CRC32 0x5c096d62 Previous-GTIDs
# 5d1e2227-07c6-11e7-8123-080027495a77:1-1106668
# at 194
#170320 11:21:26 server id 1 end_log_pos 259 CRC32 0xde21b300 GTID last_committed=0 sequence_number=1
SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106669'/*!*/;
# at 259Jak vidíme, nejstarší dostupný záznam binárního protokolu je:5d1e2227-07c6-11e7-8123-080027495a77:1106669
Musíme také zkontrolovat, jaké je poslední GTID zahrnuté v záloze:
example@sqldat.com:~# cat /var/lib/mysql/xtrabackup_binlog_info
binlog.000017 194 5d1e2227-07c6-11e7-8123-080027495a77:1-1106666
Je to:5d1e2227-07c6-11e7-8123-080027495a77:1-1106666, takže nám chybí dvě události:
5d1e2227-07c6-11e7-8123-0800274195a167>066081P677:1667
Uvidíme, zda tyto transakce najdeme na jiném otroku.
mysql> SHOW BINARY LOGS;
+---------------+------------+
| Log_name | File_size |
+---------------+------------+
| binlog.000001 | 1074130062 |
| binlog.000002 | 764366611 |
| binlog.000003 | 382576490 |
+---------------+------------+
3 rows in set (0.00 sec)Zdá se, že ‚binlog.000003‘ je nejnovější binární protokol. Musíme zkontrolovat, zda v něm nelze najít naše chybějící GTID:
slave2:~# mysqlbinlog /var/lib/mysql/binlog.000003 | grep "5d1e2227-07c6-11e7-8123-080027495a77:110666[78]"
SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106667'/*!*/;
SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106668'/*!*/;Mějte prosím na paměti, že možná budete chtít zkopírovat soubory binlog mimo produkční server, protože jejich zpracování může přidat určitou zátěž. Když jsme ověřili, že tato GTID existují, můžeme je extrahovat:
slave2:~# mysqlbinlog --exclude-gtids='5d1e2227-07c6-11e7-8123-080027495a77:1-1106666,5d1e2227-07c6-11e7-8123-080027495a77:1106669' /var/lib/mysql/binlog.000003 > to_apply_on_slave1.sqlPo rychlém scp můžeme tyto události aplikovat na slave
slave1:~# mysql -ppass < to_apply_on_slave1.sqlPo dokončení můžeme ověřit, zda byla tato GTID použita, a to tak, že se podíváme do výstupu příkazu SHOW SLAVE STATUS:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_UUID: 5d1e2227-07c6-11e7-8123-080027495a77
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp: 170320 10:45:04
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1-1106668Executed_GTID_set vypadá dobře, takže můžeme spustit slave vlákna:
mysql> START SLAVE;
Query OK, 0 rows affected (0.00 sec)Pojďme zkontrolovat, zda to fungovalo dobře. Opět použijeme výstup SHOW SLAVE STATUS:
Master_SSL_Crlpath:
Retrieved_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1106669
Executed_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1-1106669Vypadá dobře, funguje to!
Další metodou řešení tohoto problému bude provést zálohu ještě jednou a znovu zřídit podřízenou jednotku pomocí čerstvých dat. To bude pravděpodobně rychlejší a rozhodně spolehlivější. Nestává se často, že byste měli různé zásady čištění binlogu pro master a pro slave)
V dalším příspěvku na blogu budeme pokračovat v diskusi o dalších typech problémů s replikací.