Virtuální IP adresa je IP adresa, která neodpovídá skutečnému fyzickému síťovému rozhraní. Pohybuje se mezi více síťovými rozhraními a pouze jedno aktivní rozhraní bude mít IP adresu pro odolnost proti chybám a mobilitu. ClusterControl využívá Keepalived k zajištění integrace virtuální IP adresy s databázovými nástroji pro vyrovnávání zatížení, aby se eliminoval jakýkoli bod selhání (SPOF) na úrovni nástroje pro vyrovnávání zatížení.
V tomto příspěvku na blogu vám ukážeme, jak ClusterControl konfiguruje virtuální IP adresu a co můžete očekávat, když dojde k převzetí služeb při selhání nebo obnovení služeb při selhání. Pochopení tohoto chování je životně důležité, aby se minimalizovalo jakékoli přerušení služby a aby se usnadnily operace údržby, které je třeba občas provádět.
Požadavky
Pro spuštění Keepalived ve vaší síti existují určité požadavky:
- Síť musí podporovat protokol IP 112 (Virtual Router Redundancy Protocol – VRRP). Některé sítě zakazují podporu VRRP, zejména komunikaci mezi VLAN. Ověřte to prosím u správce sítě.
- Pokud používáte vícesměrové vysílání, musí síť podporovat požadavek vícesměrového vysílání (použijte ip a | grep -i vícesměrové vysílání). Jinak můžete použít unicast přes unicast_src_ip a unicast_peer možnosti. Použití vícesměrového vysílání je užitečné, když máte dynamické prostředí, jako je cloudové prostředí, nebo když se přidělování IP provádí prostřednictvím DHCP.
- Sada instancí VRRP musí používat jedinečné virtual_router_id hodnotu, kterou nelze sdílet mezi jinými instancemi. V opačném případě uvidíte falešné pakety a pravděpodobně přerušíte přepínač master-backup.
- Pokud používáte cloudové prostředí, jako je AWS, pravděpodobně budete muset použít externí skript (nápověda:použijte možnost „upozornit“) k oddělení a přidružení virtuální IP adresy (elastická IP), aby byla rozpoznána a směrována router.
Nasazení Keepalived
Abyste mohli nainstalovat Keepalived prostřednictvím ClusterControl, potřebujete dva nebo více load balancerů nainstalovaných nebo importovaných do ClusterControl. Pro produkční použití důrazně doporučujeme, aby software pro vyrovnávání zatížení běžel na samostatném hostiteli a nebyl umístěn společně s uzly vaší databáze.
Poté, co budete mít alespoň dva nástroje pro vyrovnávání zatížení spravované pomocí ClusterControl a chcete nainstalovat Keepalived a povolit virtuální IP adresu, přejděte na ClusterControl -> vyberte cluster -> Spravovat -> Load Balancer -> Keepalived:
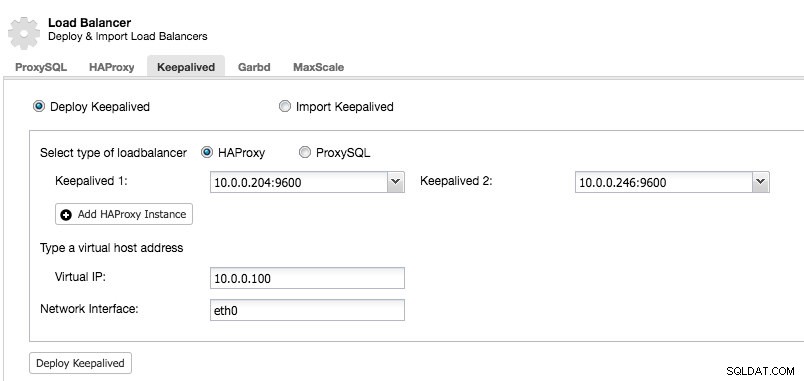
Většina oborů je samovysvětlující. Můžete nasadit novou sadu Keepalived nebo importovat existující instance Keepalived. Mezi důležitá pole patří aktuální virtuální IP adresa a síťové rozhraní, kde bude virtuální IP adresa existovat. Pokud hostitelé používají dva různé názvy rozhraní, zadejte název rozhraní hostitele Keepalived 1 a poté ručně upravte konfigurační soubor na Keepalived 2 se správným názvem rozhraní později.
Instance VRRP
V současné době psaní tohoto článku ClusterControl v1.5.1 instaluje Keepalived v1.3.5 (v závislosti na hostitelském operačním systému) a pro instanci VRRP je nakonfigurováno následující:
vrrp_instance VI_PROXYSQL {
interface eth0 # interface to monitor
state MASTER
virtual_router_id 51 # Assign one ID for this route
priority 100
unicast_src_ip 10.0.0.246
unicast_peer {
10.0.0.204
}
virtual_ipaddress {
10.0.0.100 # the virtual IP
}
track_script {
chk_proxysql
}
# notify /usr/local/bin/notify_keepalived.sh
}ClusterControl nakonfiguruje instanci VRRP pro komunikaci prostřednictvím unicast. S unicastem musíme definovat všechny unicast peery ostatních Keepalived uzlů. Je méně dynamický, ale většinu času funguje. Pomocí vícesměrového vysílání můžete odstranit tyto řádky (unicast_*) a spolehnout se na IP adresu vícesměrového vysílání pro zjišťování hostitele a partnerský vztah. Je to jednodušší, ale je běžně blokováno správci sítě.
Další částí je virtuální IP adresa. Pro každou instanci VRRP můžete zadat více virtuálních IP adres oddělených novým řádkem. Vyvažování zátěže v HAProxy/ProxySQL a Keepalived současně také vyžaduje schopnost vázat se na IP adresu, která je nelokální, což znamená, že není přiřazena k zařízení v lokálním systému. To umožňuje spuštěné instanci nástroje pro vyrovnávání zatížení vázat se na IP, která není místní pro převzetí služeb při selhání. ClusterControl tedy také konfiguruje net.ipv4.ip_nonlocal_bind=1 uvnitř /etc/sysctl.conf.
Další direktivou je track_script , kde můžete specifikovat skript procesu kontroly stavu, který je vysvětlen v další části.
Zdravotní kontroly
ClusterControl konfiguruje Keepalived tak, aby prováděla kontroly stavu zkoumáním chybového kódu vráceného track_scriptem. V konfiguračním souboru Keepalived, který je standardně umístěn na /etc/keepalived/keepalived.conf, byste měli vidět něco takového:
track_script {
chk_proxysql
}Kde volá chk_proxysql, který obsahuje:
vrrp_script chk_proxysql {
script "killall -0 proxysql" # verify the pid existence
interval 2 # check every 2 seconds
weight 2 # add 2 points of prio if OK
}Příkaz "killall -0" vrátí kód ukončení 0, pokud na hostiteli běží proces zvaný "proxysql". V opačném případě by se instance musela sama snížit a začít iniciovat převzetí služeb při selhání, jak je vysvětleno v další části. Vezměte na vědomí, že Keepalived také podporuje komponenty Linux Virtual Server (LVS) k provádění kontrol stavu, kde je také schopen vyvažování zátěže připojení TCP/IP, podobně jako HAProxy, ale to je mimo rozsah tohoto blogového příspěvku.
Simulace převzetí služeb při selhání
U komponent VRRP používá Keepalived ke komunikaci mezi instancemi VRRP protokol VRRP (IP protokol 112). Vyšší hodnota priority MASTER znamená, že master bude mít vždy vyšší oprávnění držet virtuální IP adresu, pokud nenakonfigurujete instanci s "nopreempt". Použijme příklad, abychom lépe vysvětlili tok převzetí služeb při selhání a navrácení při selhání. Zvažte následující diagram:
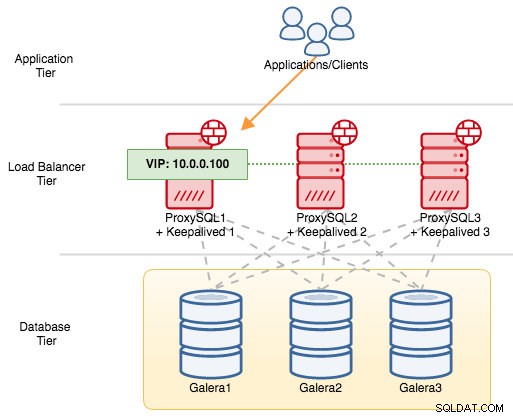
Před třemi uzly MySQL Galera jsou tři instance ProxySQL. Každý hostitel ProxySQL je nakonfigurován s Keepalived jako MASTER s následujícím číslem priority:
- ProxySQL1 – priorita 101
- ProxySQL2 – priorita 100
- ProxySQL3 – priorita 99
Když je Keepalived spuštěn jako MASTER, nejprve oznámí členům prioritní číslo a poté se přiřadí k virtuální IP adrese. Na rozdíl od instance BACKUP bude pouze pozorovat reklamu a virtuální IP adresu přidělí až poté, co potvrdí, že se může povýšit na MASTER.
Uvědomte si, že pokud proces „proxysql“ nebo „haproxy“ zabijete ručně pomocí příkazu kill, správce procesů systemd se ve výchozím nastavení pokusí obnovit proces, který je bezdůvodně zastaven. Také, pokud máte zapnutou automatickou obnovu ClusterControl, ClusterControl se vždy pokusí spustit proces, i když provedete čisté vypnutí přes systemd (systemctl stop proxysql). Pro co nejlepší simulaci selhání doporučujeme uživateli vypnout funkci automatického obnovení ClusterControl nebo jednoduše vypnout ProxySQL server a přerušit komunikaci.
Pokud vypneme ProxySQL1, dojde k selhání virtuální IP adresy na dalšího hostitele, který má v daný čas vyšší prioritu (což je ProxySQL2):
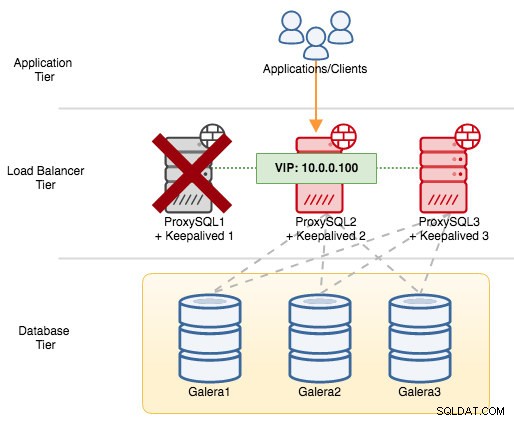
V syslogu neúspěšného uzlu byste viděli následující:
Feb 27 05:21:59 proxysql1 systemd: Unit proxysql.service entered failed state.
Feb 27 05:21:59 proxysql1 Keepalived_vrrp[12589]: /usr/bin/killall -0 proxysql exited with status 1
Feb 27 05:21:59 proxysql1 Keepalived_vrrp[12589]: VRRP_Script(chk_proxysql) failed
Feb 27 05:21:59 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Changing effective priority from 103 to 101
Feb 27 05:22:00 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Received advert with higher priority 102, ours 101
Feb 27 05:22:00 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Entering BACKUP STATE
Feb 27 05:22:00 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) removing protocol VIPs.Na sekundárním uzlu došlo k následujícímu:
Feb 27 05:22:00 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) forcing a new MASTER election
Feb 27 05:22:01 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Transition to MASTER STATE
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Entering MASTER STATE
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) setting protocol VIPs.
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: Sending gratuitous ARP on eth0 for 10.0.0.100
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Sending/queueing gratuitous ARPs on eth0 for 10.0.0.100
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: Sending gratuitous ARP on eth0 for 10.0.0.100
Feb 27 05:22:02 proxysql2 avahi-daemon[346]: Registering new address record for 10.0.0.100 on eth0.IPv4.V tomto případě trvalo převzetí služeb při selhání přibližně 3 sekundy, přičemž maximální doba převzetí služeb při selhání by byla interval + advert_int . V zákulisí se změnil koncový bod databáze a databázový provoz je směrován přes ProxySQL2, aniž by si toho aplikace všimly.
Když se ProxySQL1 vrátí online, vynutí si novou volbu MASTER a převezme IP adresu kvůli vyšší prioritě:
Feb 27 05:38:34 proxysql1 Keepalived_vrrp[12589]: VRRP_Script(chk_proxysql) succeeded
Feb 27 05:38:35 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Changing effective priority from 101 to 103
Feb 27 05:38:36 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) forcing a new MASTER election
Feb 27 05:38:37 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Transition to MASTER STATE
Feb 27 05:38:38 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Entering MASTER STATE
Feb 27 05:38:38 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) setting protocol VIPs.
Feb 27 05:38:38 proxysql1 Keepalived_vrrp[12589]: Sending gratuitous ARP on eth0 for 10.0.0.100
Feb 27 05:38:38 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Sending/queueing gratuitous ARPs on eth0 for 10.0.0.100
Feb 27 05:38:38 proxysql1 avahi-daemon[343]: Registering new address record for 10.0.0.100 on eth0.IPv4.Současně se ProxySQL2 sníží na stav BACKUP a odebere virtuální IP adresu ze síťového rozhraní:
Feb 27 05:38:36 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Received advert with higher priority 103, ours 102
Feb 27 05:38:36 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Entering BACKUP STATE
Feb 27 05:38:36 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) removing protocol VIPs.
Feb 27 05:38:36 proxysql2 avahi-daemon[346]: Withdrawing address record for 10.0.0.100 on eth0.V tomto okamžiku je ProxySQL1 zpět online a stává se aktivním nástrojem pro vyrovnávání zatížení, který obsluhuje připojení z aplikací a klientů. VRRP normálně zabrání serveru s nižší prioritou, když se server s vyšší prioritou dostane do režimu online. Pokud byste chtěli, aby IP adresa zůstala na ProxySQL2 poté, co se ProxySQL1 vrátí online, použijte volbu "nopreempt". To umožňuje počítači s nižší prioritou zachovat hlavní roli, i když se počítač s vyšší prioritou vrátí do režimu online. Aby to však fungovalo, počáteční stav této položky musí být BACKUP. V opačném případě si všimnete následujícího řádku:
Feb 27 05:50:33 proxysql2 Keepalived_vrrp[6298]: (VI_PROXYSQL): Warning - nopreempt will not work with initial state MASTERProtože ve výchozím nastavení ClusterControl konfiguruje všechny uzly jako MASTER, musíte odpovídajícím způsobem nakonfigurovat následující možnost konfigurace pro příslušnou instanci VRRP:
vrrp_instance VI_PROXYSQL {
...
state BACKUP
nopreempt
...
}Restartujte proces Keepalived, aby se tyto změny načetly. Virtuální IP adresa bude převzata při selhání na ProxySQL1 nebo ProxySQL3 (v závislosti na prioritě a na tom, který uzel je v daném okamžiku dostupný), pokud selže kontrola stavu na ProxySQL2. V mnoha případech bude stačit spuštění Keepalived na dvou hostitelích.