Úvod
Při spuštění Galera Cluster je běžnou praxí přidat jeden nebo více asynchronních slave do stejného nebo jiného datového centra. To nám poskytuje pohotovostní plán s nízkou RTO a nízkými provozními náklady. V případě neopravitelného problému v našem clusteru můžeme rychle přejít na selhání, aby aplikace mohly mít nadále přístup k datům.
Při použití tohoto typu nastavení nemůžeme znovu sestavit náš cluster z předchozí zálohy. Protože asynchronní otrok je nyní novým zdrojem pravdy, musíme z něj přestavět cluster.
To neznamená, že máme jen jeden způsob, jak to udělat, možná existuje ještě lepší způsob! Neváhejte a dejte nám své návrhy v sekci komentářů na konci tohoto příspěvku.
Topologie
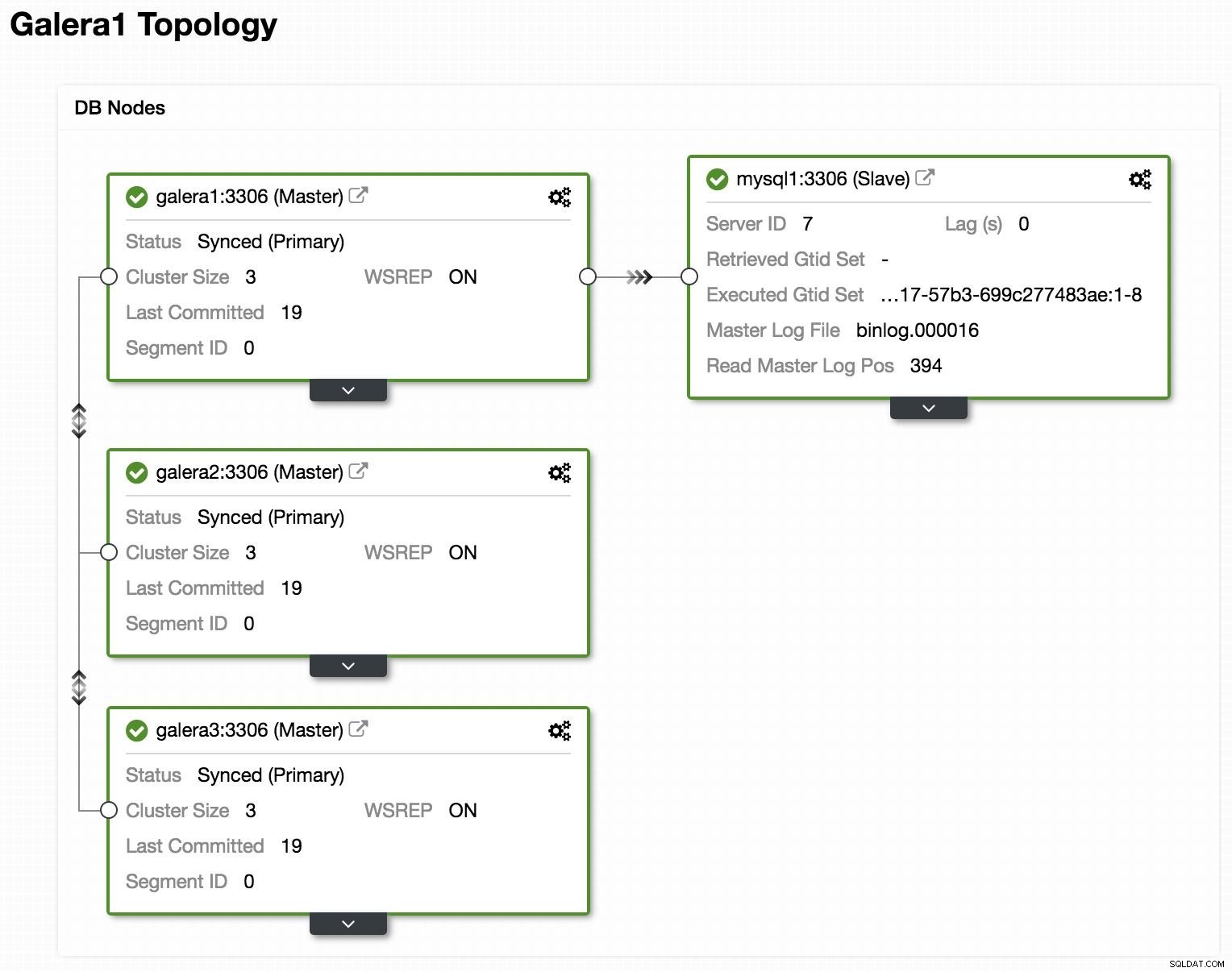 Zobrazení topologie ClusterControl online
Zobrazení topologie ClusterControl online Nahoře můžeme vidět ukázkovou topologii s Galera Cluster a asynchronní replikou/slave.
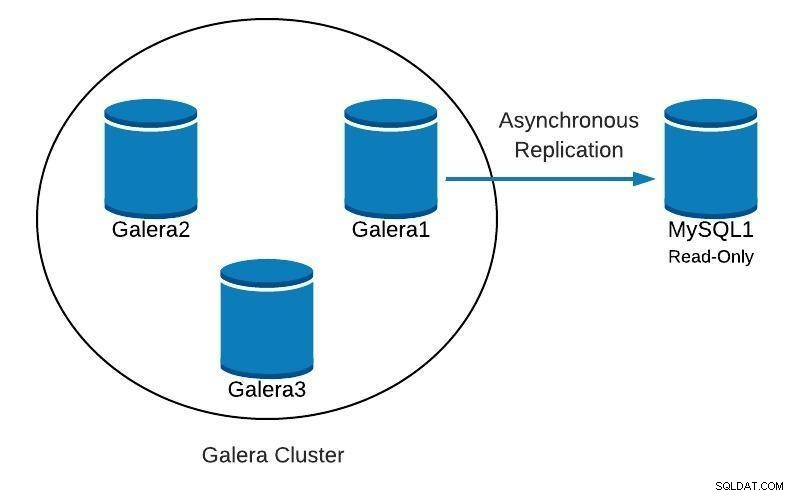 Databázový diagram 1
Databázový diagram 1 Dále uvidíme, jak můžeme znovu vytvořit náš cluster, počínaje otrokem, v případě nalezení něčeho takového:
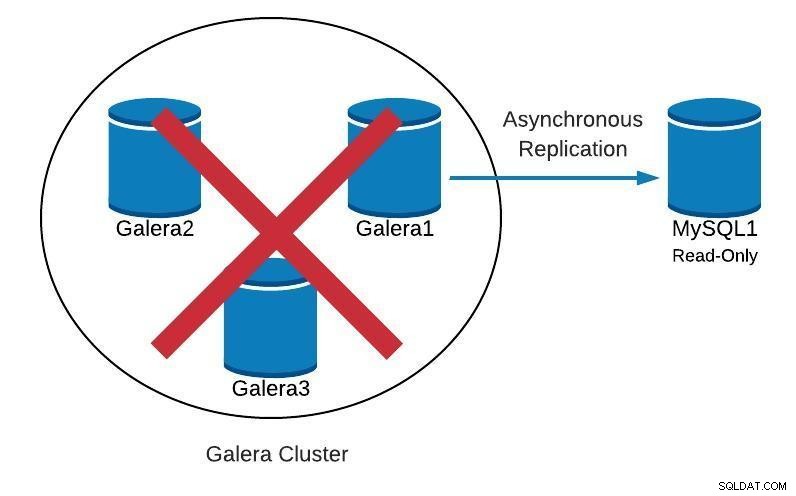 Databázový diagram 2
Databázový diagram 2 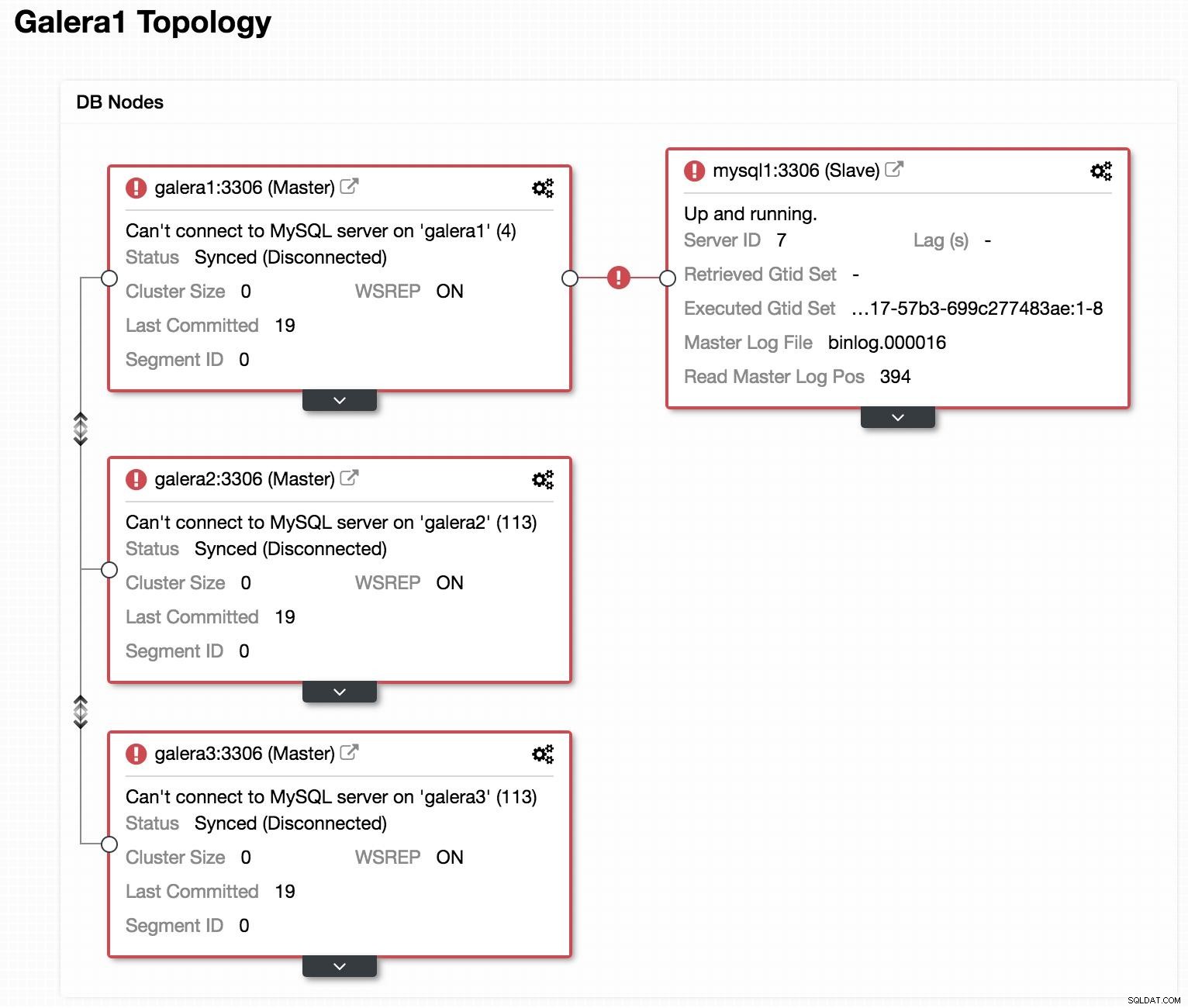 Zobrazení topologie ClusterControl offline
Zobrazení topologie ClusterControl offline Když se podíváme na předchozí obrázek, vidíme, že naše 3 uzly Galera jsou mimo provoz. Náš slave se nemůže připojit k hlavnímu zařízení Galera, ale je ve stavu „Up and running“.
Propagovat Slave
Protože náš otrok funguje správně, můžeme jej povýšit na ovládání a nasměrovat na něj naše aplikace. Za tímto účelem musíme deaktivovat parametr pouze pro čtení v našem slave zařízení a resetovat konfiguraci slave.
V našem otroku (mysql1):
mysql> SET GLOBAL read_only=0;
Query OK, 0 rows affected (0.00 sec)
mysql> STOP SLAVE;
Query OK, 0 rows affected (0.00 sec)
mysql> RESET SLAVE;
Query OK, 0 rows affected (0.18 sec)Vytvořit nový cluster
Dále, abychom zahájili obnovu našeho neúspěšného clusteru, vytvoříme nový cluster Galera. To lze snadno provést pomocí ClusterControl ClusterControl. Přejděte prosím níže v tomto blogu, abyste viděli, jak na to.
Jakmile nasadíme náš nový cluster Galera, měli bychom něco jako následující:
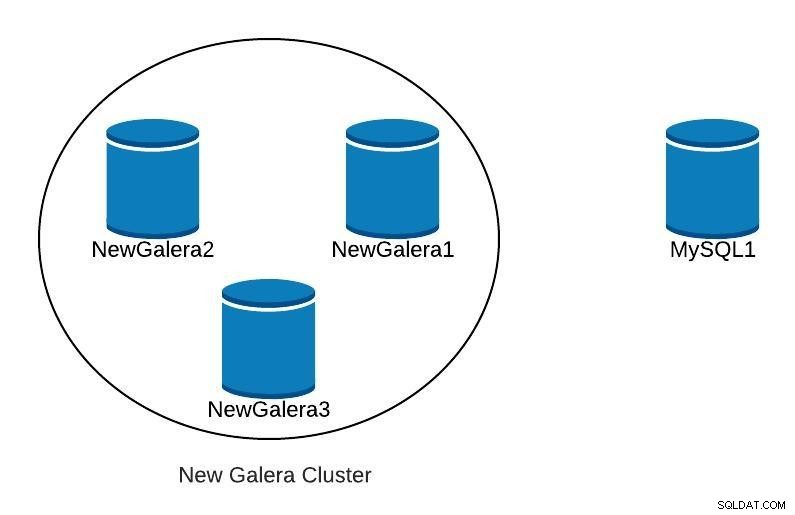 Databázový diagram 3
Databázový diagram 3 Replikace
Musíme zajistit, že máme nakonfigurované parametry replikace.
Pro uzly Galera (galera1, galera2, galera3):
server_id=<ID> # Different value in each node
binlog_format=ROW
log_bin = /var/lib/mysql-binlog/binlog
log_slave_updates = ON
gtid_mode = ON
enforce_gtid_consistency = true
relay_log = relay-bin
expire_logs_days = 7Pro hlavní uzel (mysql1):
server_id=<ID> # Different value in each node
binlog_format=ROW
log_bin=binlog
log_slave_updates=1
gtid_mode=ON
enforce_gtid_consistency=1
relay_log=relay-bin
expire_logs_days=7
read_only=ON
sync_binlog=1
report_host=<HOSTNAME or IP> # Local serverAby se náš nový slave (galera1) mohl připojit k našemu novému masteru (mysql1), musíme v našem masteru vytvořit uživatele s oprávněním k replikaci.
V našem novém masteru (mysql1):
mysql> GRANT REPLICATION SLAVE ON *.* TO 'slave_user'@'%' IDENTIFIED BY 'slave_password';Poznámka:Můžeme nahradit „%“ IP uzlu Galera Cluster, který bude naším otrokem, v našem příkladu galera1.
Záloha
Pokud jej nemáme, musíme vytvořit konzistentní zálohu našeho masteru (mysql1) a načíst jej do našeho nového Galera Clusteru. K tomu můžeme použít nástroj XtraBackup nebo mysqldump. Podívejme se na obě možnosti.
V našem příkladu používáme databázi sakila dostupnou pro testování.
Nástroj XtraBackup
Zálohu vygenerujeme v novém masteru (mysql1). V našem případě jej odešleme do místního adresáře /root/backup:
$ innobackupex /root/backup/Musíme dostat zprávu:
180705 22:08:14 completed OK!Zálohu zkomprimujeme a odešleme do uzlu, který bude naším otrokem (galera1):
$ cd /root/backup
$ tar zcvf 2018-07-05_22-08-07.tar.gz 2018-07-05_22-08-07
$ scp /root/backup/2018-07-05_22-08-07.tar.gz galera1:/root/backup/V galera1 rozbalte zálohu:
$ tar zxvf /root/backup/2018-07-05_22-08-07.tar.gzZastavíme cluster (pokud je spuštěn). Za tímto účelem zastavíme služby mysql 3 uzlů:
$ service mysql stopV galera1 přejmenujeme datový adresář mysql a načteme zálohu:
$ mv /var/lib/mysql /var/lib/mysql.bak
$ innobackupex --copy-back /root/backup/2018-07-05_22-08-07Musíme dostat zprávu:
180705 23:00:01 completed OK!Přidělujeme správná oprávnění k datovému adresáři:
$ chown -R mysql.mysql /var/lib/mysqlPotom musíme inicializovat cluster.
Jakmile je první uzel inicializován, musíme spustit službu MySQL pro zbývající uzly, odstranit jakoukoli předchozí kopii souboru grastate.dat a poté ověřit, zda jsou naše data aktualizována.
$ rm /var/lib/mysql/grastate.dat
$ service mysql startPoznámka:Ověřte, že uživatel používaný XtraBackup je vytvořen v našem inicializovaném uzlu a je v každém uzlu stejný.
mysqldump
Obecně to nedoporučujeme dělat s mysqldump, protože to může být při velkém objemu dat docela pomalé. Ale je to alternativa k provedení úkolu.
Zálohu vygenerujeme v novém hlavním serveru (mysql1):
$ mysqldump -uroot -p --single-transaction --skip-add-locks --triggers --routines --events --databases sakila > /root/backup/sakila_dump.sqlZkomprimujeme jej a odešleme do našeho slave uzlu (galera1):
$ gzip /root/backup/sakila_dump.sql
$ scp /root/backup/sakila_dump.sql.gz galera1:/root/backup/Načteme výpis do galera1.
$ gunzip /root/backup/sakila_dump.sql.gz
$ mysql -p < /root/backup/sakila_dump.sqlKdyž se výpis načte do galera1, musíme restartovat službu MySQL na zbývajících uzlech, odstranit soubor grastate.dat a ověřit, že máme naše data aktualizovaná.
$ rm /var/lib/mysql/grastate.dat
$ service mysql startSpustit slave replikace
Bez ohledu na to, kterou možnost zvolíme, XtraBackup nebo mysqldump, pokud vše proběhlo v pořádku, v tomto kroku již můžeme zapnout replikaci v uzlu, který bude naším otrokem (galera1).
$ mysql> CHANGE MASTER TO MASTER_HOST = 'mysql1', MASTER_PORT = 3306, MASTER_USER = 'slave_user', MASTER_PASSWORD = 'slave_password', MASTER_AUTO_POSITION = 1;
$ mysql> START SLAVE;Ověříme, že slave funguje:
mysql> SHOW SLAVE STATUS\G
Slave_IO_Running: Yes
Slave_SQL_Running: YesV tuto chvíli máme něco jako následující:
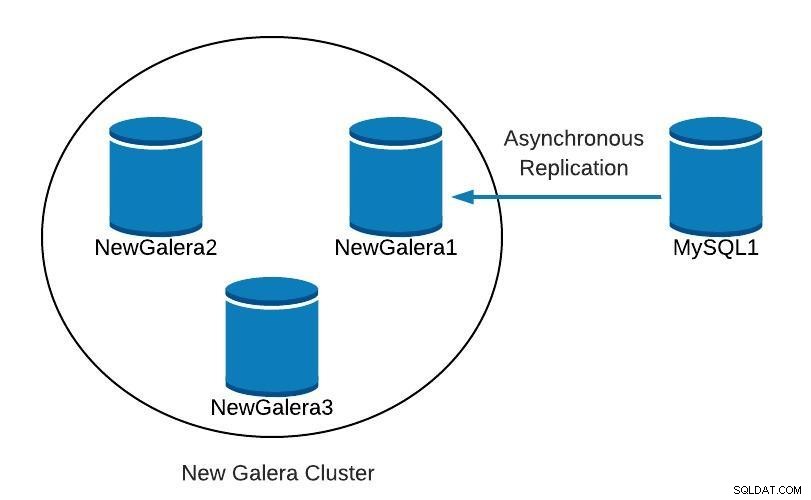 Databázový diagram 4
Databázový diagram 4 Jakmile bude NewGalera1 aktuální, můžeme aplikaci znovu nasměrovat na náš nový cluster galera a překonfigurovat asynchronní replikaci.
ClusterControl
Jak jsme již zmínili dříve, pomocí ClusterControl můžeme provést několik výše uvedených úkolů několika jednoduchými kliknutími. Má také možnosti automatického obnovení pro uzly i cluster. Podívejme se na některé úkoly, se kterými může pomoci.
 Nasazení ClusterControl 1
Nasazení ClusterControl 1 Chcete-li provést nasazení, jednoduše vyberte možnost „Deploy Database Cluster“ a postupujte podle zobrazených pokynů.
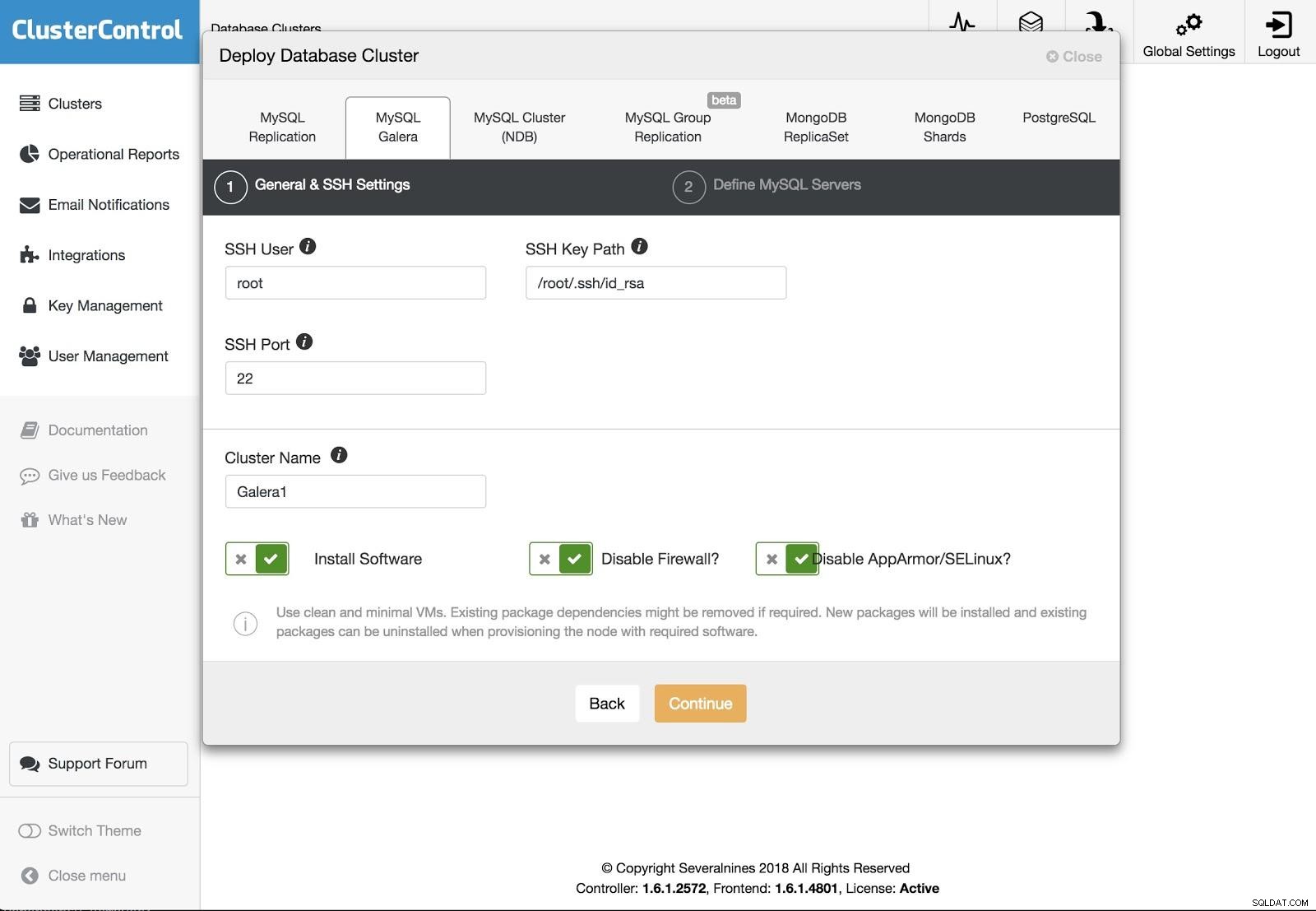 ClusterControl Deployment 2
ClusterControl Deployment 2 Můžeme si vybrat mezi různými druhy technologií a prodejců. Musíme zadat uživatele, klíč nebo heslo a port pro připojení pomocí SSH k našim serverům. Potřebujeme také název našeho nového clusteru a pokud chceme, aby ClusterControl nainstaloval odpovídající software a konfigurace za nás.
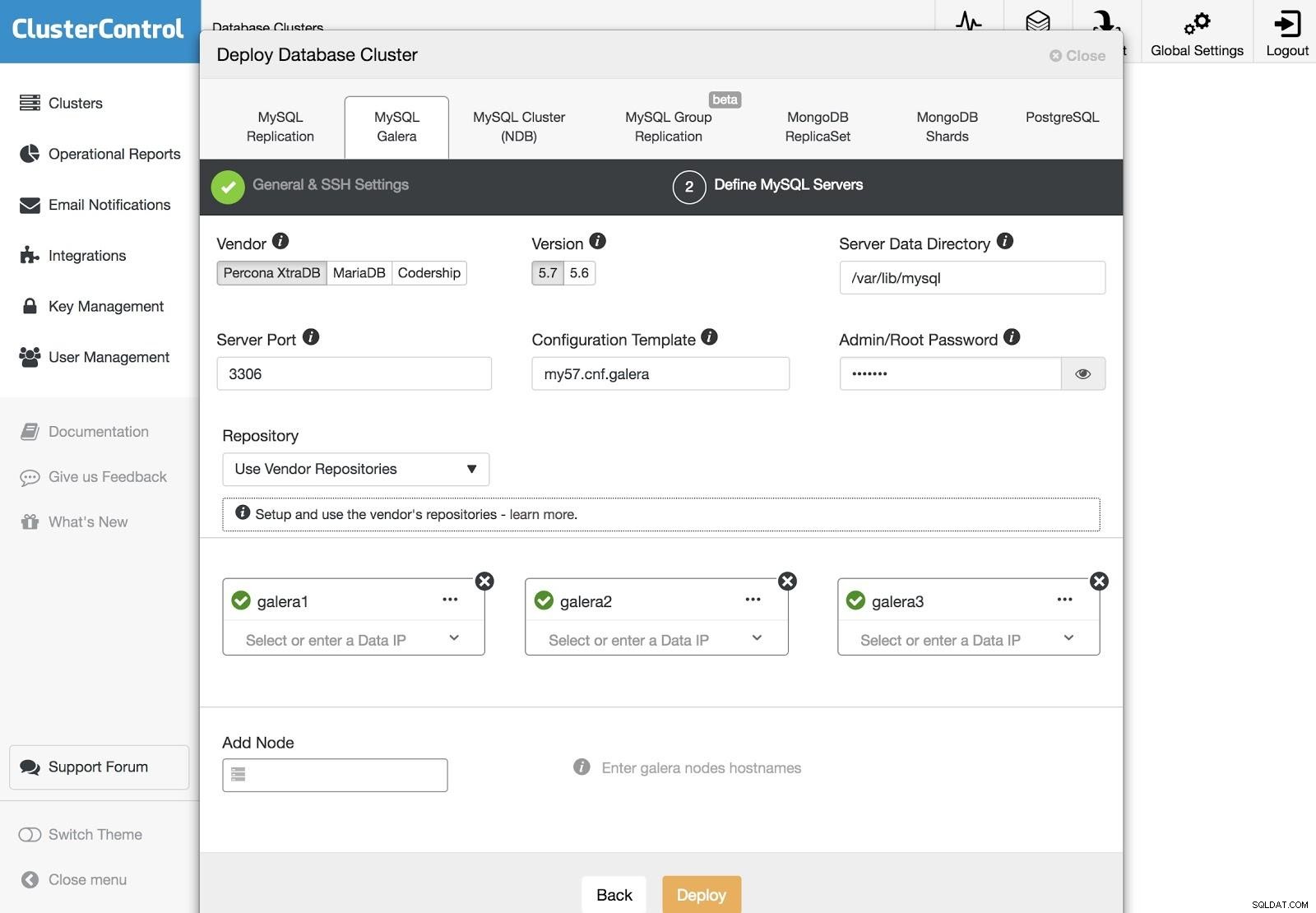 ClusterControl Deployment 3
ClusterControl Deployment 3 Po nastavení přístupových informací SSH musíme definovat uzly v našem clusteru. Můžeme také určit, které úložiště použít. Potřebujeme přidat naše servery do clusteru, který se chystáme vytvořit.
Stav vytváření našeho nového clusteru můžeme sledovat z monitoru aktivity ClusterControl.
Rovněž můžeme provést import našeho aktuálního clusteru nebo databáze podle stejných kroků. V tomto případě ClusterControl nenainstaluje databázový software, protože databáze již běží.
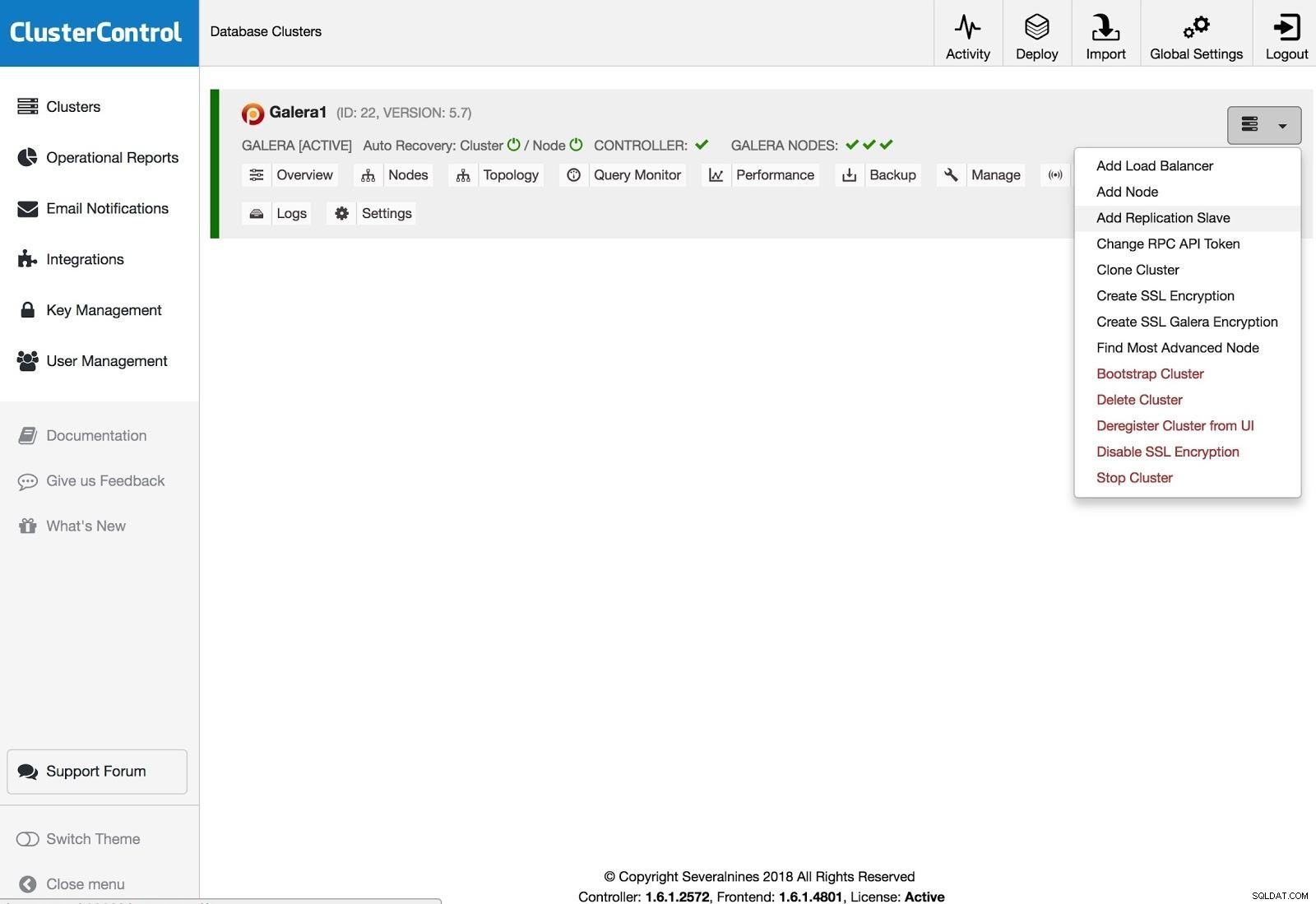 ClusterControl Add Replication Salve
ClusterControl Add Replication Salve Chcete-li přidat replikační slave zařízení, musíte kliknout na Cluster Actions, vybrat Add Replication Slave a přidat informace o přístupu SSH nového serveru. ClusterControl se připojí k serveru a provede potřebné konfigurace pro tuto akci.
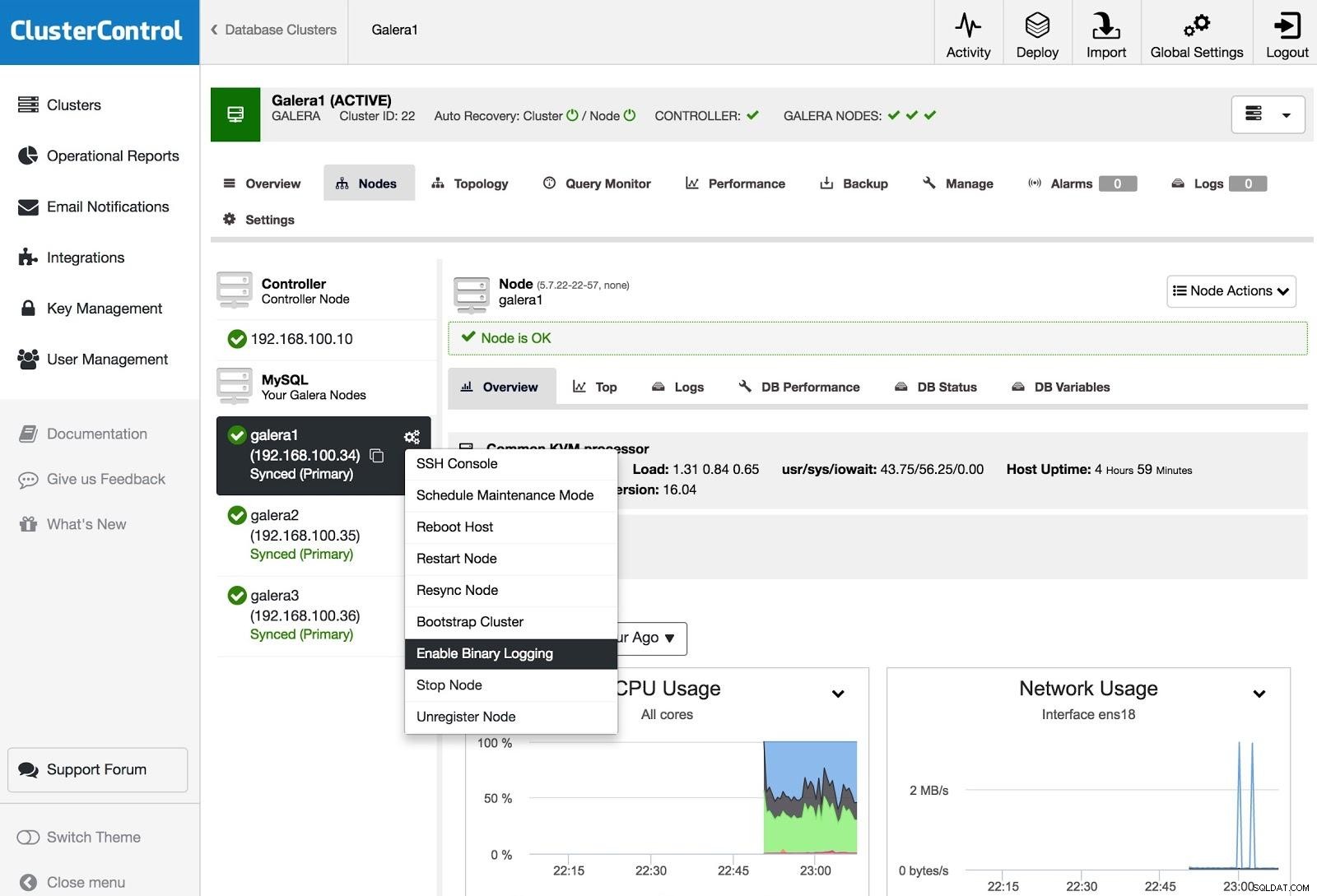 ClusterControl Povolit binární protokolování
ClusterControl Povolit binární protokolování Chcete-li změnit jeden nebo více uzlů Galera na hlavní servery (jako ve smyslu vytváření binlogů), můžete přejít na Akce uzlů a vybrat možnost Povolit binární protokolování.
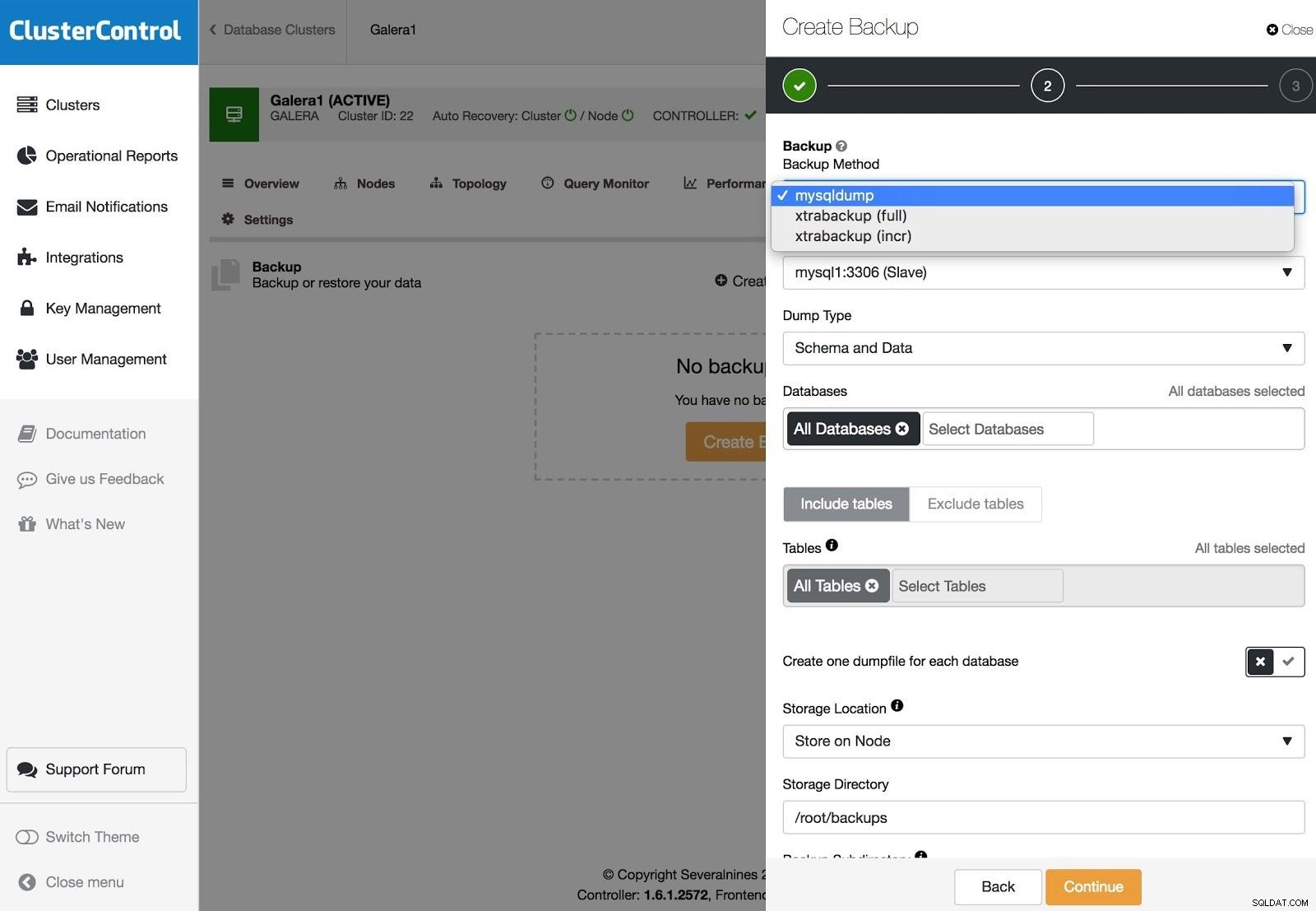 Zálohy ClusterControl
Zálohy ClusterControl Zálohy lze konfigurovat pomocí XtraBackup (úplné nebo přírůstkové) a mysqldump a máte další možnosti, jako je nahrání zálohy do cloudu, šifrování, komprese, plán a další.
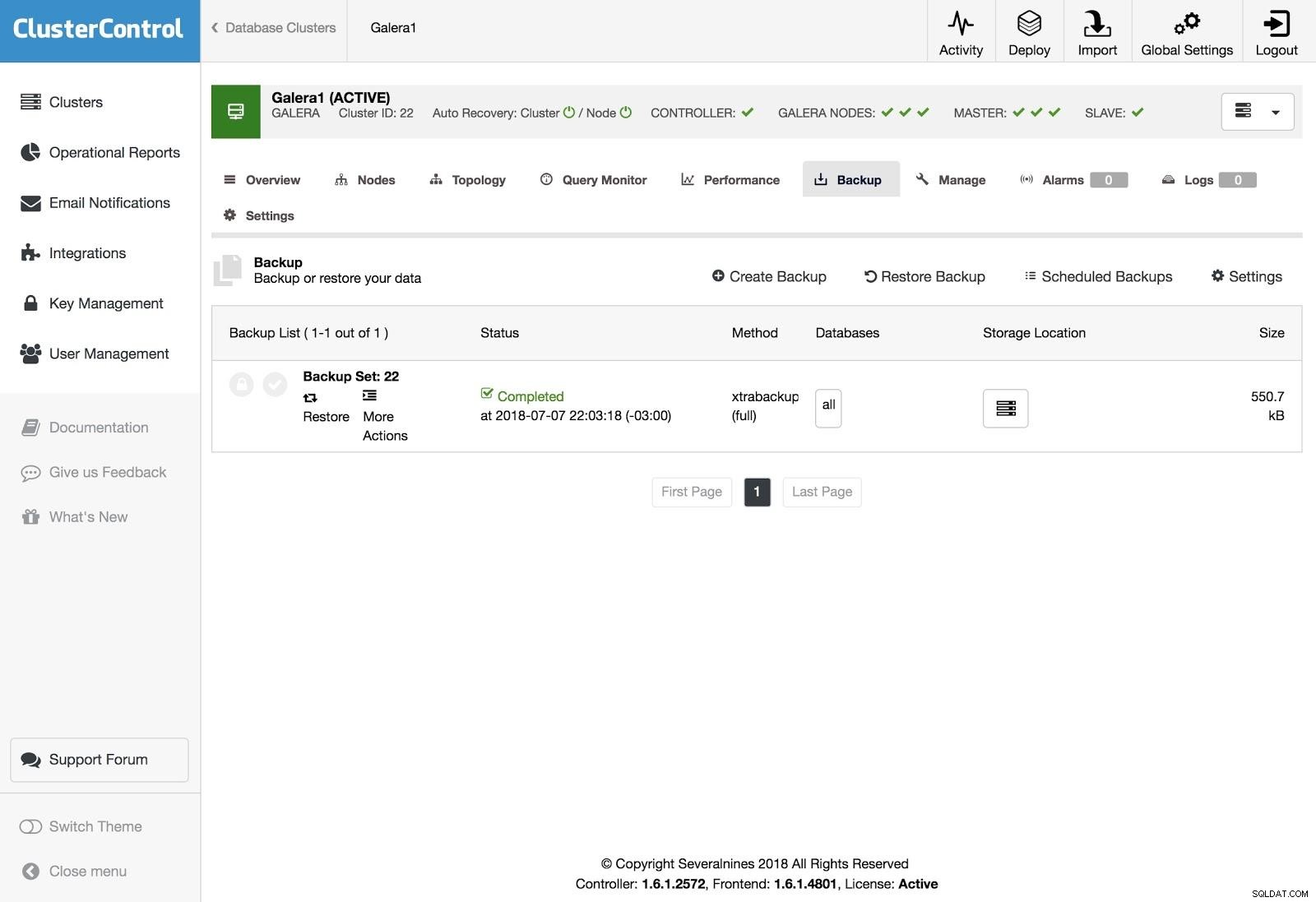 Obnovení ClusterControl
Obnovení ClusterControl Chcete-li zálohu obnovit, přejděte na kartu Záloha a vyberte možnost Obnovit a poté vyberte, na kterém serveru chcete obnovit.
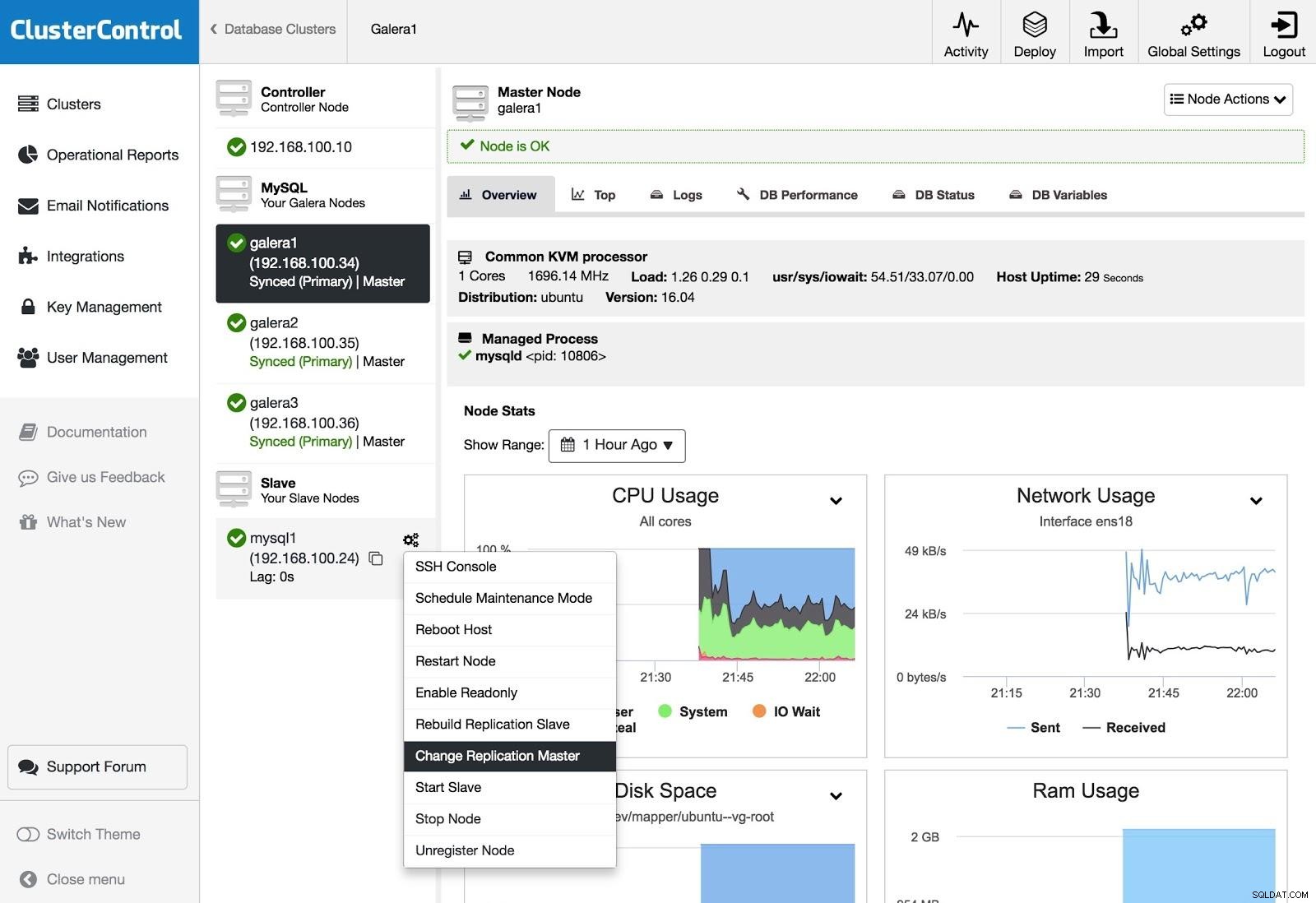 ClusterControl Change Replication Master
ClusterControl Change Replication Master Pokud máte podřízenou jednotku a chcete změnit hlavní server nebo přestavět replikaci, můžete přejít na Node Actions a vybrat možnost.
Závěr
Jak jsme viděli, máme několik způsobů, jak dosáhnout našeho cíle, některé jsou složitější, jiné uživatelsky přívětivější, ale s kterýmkoli z nich můžete znovu vytvořit cluster z asynchronního slave. Xtrabackup by se obnovil rychleji pro větší objemy dat. Chcete-li se chránit před chybou operátora (např. chybnou DROP TABLE), můžete také použít zpožděnou podřízenou jednotku, takže doufejme, že budete mít čas zastavit šíření příkazu.
Doufáme, že tyto informace jsou užitečné a že je nikdy nebudete muset použít ve výrobě;)