Vzhledem k současnému hlavnímu případu použití databáze při získávání dat se stává velmi důležité, aby její výkon byl velmi vysoký a lze jej dosáhnout pouze tehdy, jsou-li data získávána z úložiště co nejefektivnějším způsobem. Bylo provedeno mnoho úspěšných vynálezů a implementací k dosažení stejného cíle. Jedním z dobře známých přístupů přijatých většinou databází je mít v tabulce index.
Co je index databáze?
Database Index, jak název napovídá, udržuje index skutečných dat a tím zlepšuje výkon při načítání dat ze skutečné tabulky. V databázové terminologii index umožňuje načítání stránky obsahující indexovaná data ve velmi minimálním průchodu, protože data jsou řazena v určitém pořadí. Výhoda indexu přichází za cenu dodatečného úložného prostoru pro zápis dalších dat. Indexy jsou specifické pro podkladovou tabulku a sestávají z jednoho nebo více klíčů (tj. jednoho nebo více sloupců zadané tabulky). Primárně existují dva typy indexové architektury
- Shlukovaný index – Data indexu se ukládají spolu s další částí dat a data se třídí na základě klíče indexu. V této kategorii může být pro určitou tabulku nejvýše jeden index.
- Neclusterovaný index – Indexová data se ukládají samostatně a mají ukazatel na úložiště, kde je uložena další část dat. Toto je také známé jako sekundární index. V určité tabulce může být tolik indexů této kategorie, kolik chcete.
Pro implementaci indexů se používají různé datové struktury, mezi které většina databází široce používá, patří B-Tree a Hash.
Co je index PostgreSQL?
PostgreSQL podporuje pouze neklastrovaný index. To znamená indexová data a úplná data (dále jen hromadná data ) jsou uloženy v samostatném skladu. Neshlukované indexy jsou jako „Obsah“ v jakémkoli dokumentu, kde nejprve zkontrolujeme číslo stránky a poté zkontrolujeme čísla stránek, abychom si přečetli celý obsah. Aby bylo možné získat úplná data na základě indexu, udržuje ukazatel na odpovídající data haldy. Je to stejné, jako když znáte číslo stránky, je třeba přejít na tuto stránku a získat skutečný obsah stránky.
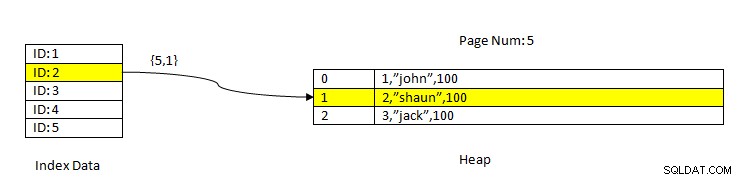 PostgreSQL:Čtení dat pomocí indexu
PostgreSQL:Čtení dat pomocí indexu Vezměme si například tabulku se třemi sloupci a indexem ve sloupci ID . Aby bylo možné ČÍST data na základě klíče ID=2, nejprve se prohledají indexovaná data s hodnotou ID 2. Toto obsahuje ukazatel (nazývaný jako ukazatel položky) ve smyslu čísla stránky (tj. čísla bloku) a offsetu dat na této stránce. V aktuálním příkladu index ukazuje na stránku číslo 5 a druhou řádkovou položku na stránce, která naopak zachovává offset vůči celým datům (2,“Shaun“,100). Všimněte si, že celá data obsahují také indexovaná data, což znamená, že stejná data se opakují ve dvou úložištích.
Jak INDEX pomáhá zlepšit výkon? Aby bylo možné vybrat jakýkoli záznam INDEX, neprohledá všechny stránky sekvenčně, ale pouze musí částečně naskenovat některé stránky pomocí základní datové struktury indexu. Je tu však zvrat, protože každý záznam nalezený z dat indexu musí hledat v datech haldy celá data, což způsobuje mnoho náhodných I/O a má se za to, že pracuje pomaleji než sekvenční I/O. Takže pouze pokud je vybráno malé procento záznamů (což se rozhodlo na základě nákladů na optimalizátor PostgreSQL), pak pouze PostgreSQL zvolí Index Scan, jinak i když je v tabulce index, pokračuje v používání Sequence Scan.
Stručně řečeno, i když vytváření indexu zrychluje výkon, měl by být vybrán pečlivě, protože má režii z hlediska úložiště a snižuje výkon INSERT.
Nyní se můžeme divit, že v případě, že potřebujeme pouze indexovou část dat, můžeme načíst pouze ze stránky úložiště indexu? Odpověď na to přímo souvisí s tím, jak MVCC funguje na úložišti indexu, jak je vysvětleno dále.
Použití MVCC pro indexování
Stejně jako stránky haldy i stránka indexu udržuje několik verzí indexové n-tice, ale neuchovává informace o viditelnosti. Jak je vysvětleno v mém předchozím MVCC blog, aby bylo možné rozhodnout o vhodné viditelné verzi n-tic, vyžaduje porovnání transakcí. Transakce, které vložily/aktualizovaly/odstranily n-tice, jsou udržovány spolu s n-ticí haldy, ale totéž není udržováno s n-tice indexů. Je to čistě kvůli úspoře úložiště a je to kompromis mezi prostorem a výkonem.
Nyní se vracíme k původní otázce, protože informace o viditelnosti v n-tice indexu tam nejsou, je třeba se podívat na odpovídající n-tice haldy, aby se zjistilo, zda jsou vybraná data viditelná. Takže i když nejsou vyžadovány další části dat z n-tice haldy, je stále potřeba přistupovat ke stránkám haldy a zkontrolovat viditelnost. Ale opět dochází ke zvratu v případě, že jsou viditelné všechny n-tice na dané stránce (stránce, na kterou ukazuje index, tj. ItemPointer), pak není nutné odkazovat na každou položku haldy pro „kontrolu viditelnosti“, a proto lze data vrátit pouze ze stránky Index. Tento speciální případ se nazývá „Index Only Scan“. Aby to bylo podporováno, PostgreSQL udržuje mapu viditelnosti pro každou stránku pro kontrolu viditelnosti na úrovni stránky.
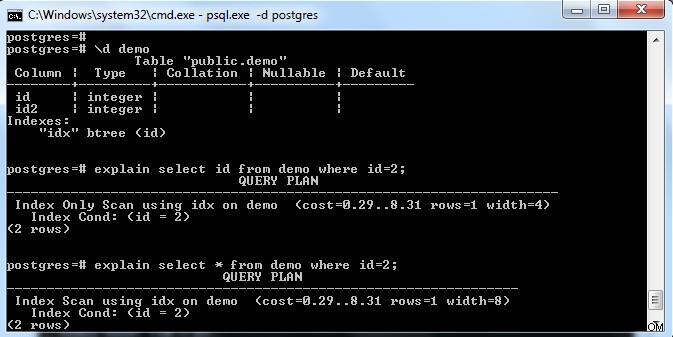
Jak je znázorněno na obrázku výše, na tabulce „demo“ je index s klíčem ve sloupci „id“. Pokud se pokusíme vybrat pouze indexové pole (tj. id), pak zvolilo „Index Only Scan“ (s ohledem na to, že odkazující stránka je plně viditelná).
Shlukovaný index
V PostgreSQL neexistuje žádná podpora přímého klastrovaného indexu, ale existuje nepřímý způsob, jak toho dosáhnout částečně. Toho je dosaženo pomocí níže uvedených příkazů SQL:
CLUSTER [VERBOSE] table_name [ USING index_name ]
CLUSTER [VERBOSE]První příkaz dává databázi pokyn, aby seskupila tabulku (tj. seřadila tabulku) pomocí daného indexu. Tento index by již měl být vytvořen. Toto shlukování je pouze jednorázová operace a jeho dopad nezůstává po následné operaci na této tabulce, tj. pokud je vloženo/aktualizováno více záznamů, tabulka nemusí zůstat uspořádaná. Pokud uživatel potřebuje, aby byla tabulka stále klastrovaná (uspořádaná), může použít první příkaz bez uvedení názvu indexu.
Druhý příkaz je užitečný pouze pro opětovné shlukování tabulky (tj. tabulky, která již byla shlukována pomocí nějakého indexu). Tento příkaz znovu seskupuje všechny tabulky v aktuální databázi viditelné pro aktuálně připojeného uživatele.
Například na obrázku níže vrací první SELECT záznamy v nesetříděném pořadí, protože neexistuje žádný seskupený index. Přestože již existuje index bez klastrů, záznamy se vybírají z oblasti haldy, kde záznamy nejsou seřazeny.
Druhý SELECT vrátí záznamy seřazené podle sloupce „id“, jak byly seskupeny pomocí indexu obsahujícího sloupec „id“.
Třetí SELECT vrací částečné záznamy v seřazeném pořadí, ale nově vložené záznamy nejsou seřazeny. Čtvrtý SELECT opět vrátí všechny záznamy v seřazeném pořadí, protože tabulka byla znovu seskupena
 Příkaz klastru PostgreSQL
Příkaz klastru PostgreSQL Typ indexu
PostgreSQL poskytuje několik typů indexů, jak je uvedeno níže:
- B-strom
- Hash
- GiST
- GIN
- BRIN
Každý typ indexu implementuje různé druhy podkladových datových struktur, které se nejlépe hodí pro různé typy dotazů. Ve výchozím nastavení se vytvoří index B-Tree, což jsou široce používané indexy. Podrobnosti o každém typu indexu budou popsány v budoucím blogu.
Různé:Částečný a výrazový index
Mluvili jsme pouze o indexech v jednom nebo více sloupcích tabulky, ale existují další dva způsoby, jak vytvořit indexy na PostgreSQL
- Částečný index: Částečný index je index vytvořený pomocí podmnožiny klíčového sloupce pro konkrétní tabulku. Podmnožina je definována podmíněným výrazem zadaným při vytváření indexu. Takže s částečným indexem se ušetří úložný prostor pro ukládání dat indexu. Uživatel by tedy měl zvolit podmínku tak, aby se nejednalo o příliš běžné hodnoty, protože pro častější (běžné) hodnoty stejně nebude zvolen index skenování. Zbytek funkcí zůstává stejný jako u normálního indexu. Příklad:Částečný index
- Index výrazu: Indexy výrazů poskytují další druh flexibility v PostgreSQL. Všechny dosud diskutované indexy, včetně dílčích indexů, jsou na konkrétní sadě sloupců. Co když ale dotaz zahrnuje přístup k tabulce na základě výrazu (výraz zahrnující jeden nebo více sloupců), bez indexu výrazu nezvolí skenování indexu. Aby bylo možné rychle přistupovat k tomuto druhu dotazů, PostgreSQL umožňuje vytvořit index na výrazu. Zbytek funkcí zůstává stejný jako u normálního indexu.
 Příklad:Index výrazu
Příklad:Index výrazu
Indexové úložiště v InnoDB
Použití a funkčnost Indexu je většinou stejná jako v PostgreSQL s velkým rozdílem, pokud jde o Clustered Index.
InnoDB podporuje dvě kategorie indexů:
- Shlukovaný index
- Sekundární index
Shlukovaný index
Clustered Index je speciální druh indexu v InnoDB. Zde se indexovaná data neukládají samostatně, ale jsou součástí dat celého řádku. Jinými slovy, seskupený index pouze vynutí fyzické řazení dat tabulky pomocí klíčového sloupce indexu. Lze jej považovat za „Slovník“, kde jsou data řazena podle abecedy.
Protože seskupený index třídí řádky pomocí klíče indexu, může existovat pouze jeden seskupený index. Také musí existovat jeden seskupený index, protože InnoDB jej používá k optimální manipulaci s daty během různých datových operací.
Seskupený index se vytváří automaticky (jako součást vytváření tabulky) pomocí jednoho ze sloupců tabulky podle níže uvedené priority:
- Použití primárního klíče, pokud je primární klíč zmíněn při vytváření tabulky.
- Vybere libovolný jedinečný sloupec, kde všechny klíčové sloupce NEJSOU NULL.
- Jinak interně vygeneruje skrytý seskupený index v systémovém sloupci, který obsahuje ID řádku každého řádku.
Na rozdíl od neshlukovaného indexu PostgreSQL přistupuje InnoDB k řádku pomocí seskupeného indexu rychleji, protože vyhledávání indexu vede přímo na stránku se všemi daty řádků a tím se vyhne náhodným I/O.
Také získání tabulkových dat v setříděném pořadí pomocí seskupeného indexu je velmi rychlé, protože všechna data jsou již setříděna a k dispozici jsou také celá data.
Sekundární index
Index vytvořený explicitně v InnoDB je považován za sekundární index, který je podobný neklastrovanému indexu PostgreSQL. Každý záznam v úložišti sekundárního indexu obsahuje sloupce primárního klíče řádků (které byly použity pro vytvoření Clustered Index) a také sloupce určené k vytvoření sekundárního indexu.
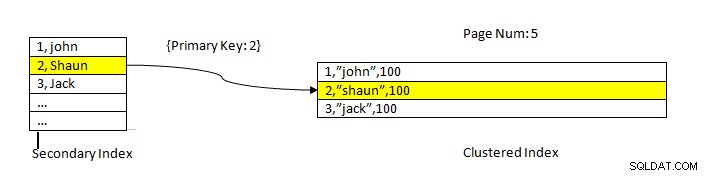 InnoDB:Čtení dat pomocí indexu
InnoDB:Čtení dat pomocí indexu Načítání dat pomocí sekundárního indexu je podobné jako v případě PostgreSQL s tím rozdílem, že vyhledávání sekundárního indexu InnoDB poskytuje primární klíč jako ukazatel pro načtení zbývajících dat z seskupeného indexu.
Například, jak je znázorněno na obrázku výše, seskupený index je ve sloupci ID takže data tabulky jsou seřazeny podle stejného. Sekundární index je ve sloupci „jméno “, takže jak vidíme, sekundární index má hodnotu ID i názvu. Jakmile vyhledáme pomocí sekundárního indexu, najde příslušný slot s odpovídající hodnotou klíče. Poté se příslušný primární klíč použije k odkazování na zbývající část dat ze seskupeného indexu.
MVCC pro index
Klastrovaný index MVCC využívá tradiční InnoDB Undo Model (ve skutečnosti totéž jako MVCC celých dat, protože klastrovaný index není nic jiného než celá data).
Ale sekundární index MVCC používá trochu jiný přístup k udržení MVCC. Při aktualizaci sekundárního indexu je stará položka indexu označena jako vymazání a nové záznamy jsou vloženy do stejného úložiště, tj. UPDATE není na svém místě. Nakonec budou staré položky indexu vyčištěny. Nyní jste si možná všimli, že sekundární index InnoDB MVCC je téměř stejný jako model PostgreSQL MVCC.
Typ indexu
InnoDB podporuje pouze typ indexu B-Strom, a proto není nutné jej specifikovat při vytváření indexu.
Různé:Adaptivní hash indexy
Jak bylo zmíněno v předchozí části, InnoDB podporuje pouze index typu B-Tree, ale existuje zvrat. InnoDB má funkcionalitu pro automatickou detekci, zda dotaz může těžit z vytvoření hash indexu a zda se celá data tabulky vejdou do paměti, pak to automaticky udělá.
Hash index je vytvořen pomocí existujícího indexu B-Strom v závislosti na dotazu. Pokud existuje více sekundárních indexů B-stromu, vybere se ten, který se kvalifikuje podle dotazu. Vytvořený hash index není úplný, pouze vytváří částečný index podle vzoru využití dat.
Toto je jedna z opravdu výkonných funkcí pro dynamické zlepšení výkonu dotazů.
Závěr
Použití jakéhokoli indexu v jakékoli databázi je skutečně užitečné pro zlepšení výkonu READ, ale zároveň snižuje výkon INSERT/UPDATE, protože potřebuje zapisovat další data. Index by tedy měl být vybírán velmi moudře a měl by být vytvořen pouze v případě, že se indexové klíče používají jako predikát k načítání dat.
InnoDB poskytuje velmi dobrou funkci, pokud jde o seskupený index, což může být velmi užitečné v závislosti na případech použití. Také jeho adaptivní indexování hash je velmi výkonné.
Zatímco PostgreSQL poskytuje různé typy indexů, které mohou skutečně poskytnout možnosti dosahu funkcí a jeden nebo všechny lze použít v závislosti na obchodním případu použití. Také dílčí a výrazové indexy jsou docela užitečné v závislosti na případu použití.