V první části tohoto blogu jsme probrali návod k nasazení MySQL InnoDB Cluster s příkladem, jak se mohou aplikace připojit ke clusteru přes vyhrazený port pro čtení/zápis.
V tomto návodu k provozu ukážeme příklady, jak monitorovat, spravovat a škálovat klastr InnoDB jako součást probíhajících operací údržby klastru. Použijeme stejný cluster, jaký jsme nasadili v první části blogu. Následující diagram ukazuje naši architekturu:
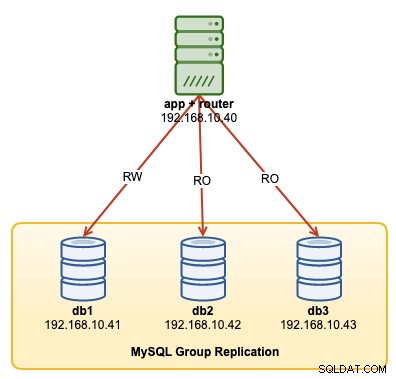
Máme tříuzlovou replikaci skupiny MySQL a jeden aplikační server běžící s MySQL router. Všechny servery běží na Ubuntu 18.04 Bionic.
Možnosti příkazu clusteru MySQL InnoDB
Než přejdeme dále s některými příklady a vysvětleními, je dobré vědět, že vysvětlení každé funkce v clusteru MySQL pro komponentu clusteru můžete získat pomocí funkce help(), jak je uvedeno níže:
$ mysqlsh
MySQL|localhost:3306 ssl|JS> shell.connect("example@sqldat.com:3306");
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster();
<Cluster:my_innodb_cluster>
MySQL|db1:3306 ssl|JS> cluster.help()Následující seznam ukazuje dostupné funkce na MySQL Shell 8.0.18 pro MySQL Community Server 8.0.18:
- addInstance(instance[, options]) – Přidá instanci do clusteru.
- checkInstanceState(instance)- Ověřuje stav gtid instance ve vztahu ke clusteru.
- describe()- Popište strukturu shluku.
- disconnect() – odpojí všechny interní relace používané objektem clusteru.
- dissolve([options])- Deaktivuje replikaci a zruší registraci ReplicaSets z clusteru.
- forceQuorumUsingPartitionOf(instance[, heslo])- Obnoví cluster před ztrátou kvora.
- getName() – Načte název clusteru.
- help([member])- Poskytuje nápovědu k této třídě a jejím členům
- options([options]) – uvádí možnosti konfigurace clusteru.
- rejoinInstance(instance[, options]) – Znovu připojí instanci ke clusteru.
- removeInstance(instance[, options]) – Odebere instanci z clusteru.
- znovu prohledat ([options]) – Znovu prohledá cluster.
- resetRecoveryAccountsPassword(options)- Resetujte heslo účtů pro obnovení clusteru.
- setInstanceOption(instance, option, value)- Změní hodnotu možnosti konfigurace v členu clusteru.
- setOption(option, value)- Změní hodnotu možnosti konfigurace pro celý cluster.
- setPrimaryInstance(instance) – Zvolí konkrétního člena klastru jako nového primárního.
- status([options])- Popište stav clusteru.
- switchToMultiPrimaryMode()- Přepne cluster do multiprimárního režimu.
- switchToSinglePrimaryMode([instance])- Přepne klastr do režimu single-primary.
Prozkoumáme většinu dostupných funkcí, které nám pomohou monitorovat, spravovat a škálovat cluster.
Monitorování operací clusteru MySQL InnoDB
Stav clusteru
Chcete-li zkontrolovat stav clusteru, nejprve použijte příkazový řádek prostředí MySQL a poté se připojte jako example@sqldat.com{one-of-the-db-nodes}:
$ mysqlsh
MySQL|localhost:3306 ssl|JS> shell.connect("example@sqldat.com:3306");Poté vytvořte objekt s názvem „cluster“ a deklarujte jej jako globální objekt „dba“, který poskytuje přístup k funkcím správy clusteru InnoDB pomocí AdminAPI (podívejte se na dokumenty MySQL Shell API):
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster();
<Cluster:my_innodb_cluster>Potom můžeme použít název objektu k volání funkcí API pro objekt "dba":
MySQL|db1:3306 ssl|JS> cluster.status(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"primary": "db1:3306",
"ssl": "REQUIRED",
"status": "OK",
"statusText": "Cluster is ONLINE and can tolerate up to ONE failure.",
"topology": {
"db1:3306": {
"address": "db1:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db2:3306": {
"address": "db2:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": "00:00:09.061918",
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db3:3306": {
"address": "db3:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": "00:00:09.447804",
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
}
},
"topologyMode": "Single-Primary"
},
"groupInformationSourceMember": "db1:3306"
}Výstup je poměrně dlouhý, ale můžeme jej odfiltrovat pomocí struktury mapy. Pokud bychom například chtěli zobrazit zpoždění replikace pouze pro db3, mohli bychom postupovat takto:
MySQL|db1:3306 ssl|JS> cluster.status().defaultReplicaSet.topology["db3:3306"].replicationLag
00:00:09.447804Všimněte si, že zpoždění replikace je něco, co se stane při skupinové replikaci v závislosti na intenzitě zápisu primárního člena v sadě replik a proměnných group_replication_flow_control_*. Nebudeme se zde tímto tématem podrobně zabývat. Podívejte se na tento blogový příspěvek, kde se dozvíte více o výkonu skupinové replikace a řízení toku.
Další podobnou funkcí je funkce description(), ale tato je o něco jednodušší. Popisuje strukturu clusteru včetně všech jeho informací, ReplicaSets a Instance:
MySQL|db1:3306 ssl|JS> cluster.describe(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"topology": [
{
"address": "db1:3306",
"label": "db1:3306",
"role": "HA"
},
{
"address": "db2:3306",
"label": "db2:3306",
"role": "HA"
},
{
"address": "db3:3306",
"label": "db3:3306",
"role": "HA"
}
],
"topologyMode": "Single-Primary"
}
}Podobně můžeme filtrovat výstup JSON pomocí struktury mapy:
MySQL|db1:3306 ssl|JS> cluster.describe().defaultReplicaSet.topologyMode
Single-PrimaryKdyž selhal primární uzel (v tomto případě je to db1), výstup vrátil následující:
MySQL|db1:3306 ssl|JS> cluster.status(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"primary": "db2:3306",
"ssl": "REQUIRED",
"status": "OK_NO_TOLERANCE",
"statusText": "Cluster is NOT tolerant to any failures. 1 member is not active",
"topology": {
"db1:3306": {
"address": "db1:3306",
"mode": "n/a",
"readReplicas": {},
"role": "HA",
"shellConnectError": "MySQL Error 2013 (HY000): Lost connection to MySQL server at 'reading initial communication packet', system error: 104",
"status": "(MISSING)"
},
"db2:3306": {
"address": "db2:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db3:3306": {
"address": "db3:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
}
},
"topologyMode": "Single-Primary"
},
"groupInformationSourceMember": "db2:3306"
}Věnujte pozornost stavu OK_NO_TOLERANCE, kde je cluster stále v provozu, ale nemůže tolerovat žádné další selhání poté, co jeden uzel ze tří není dostupný. Primární roli automaticky převzal db2 a databázová připojení z aplikace budou přesměrována do správného uzlu, pokud se připojí přes MySQL Router. Jakmile se db1 vrátí online, měli bychom vidět následující stav:
MySQL|db1:3306 ssl|JS> cluster.status(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"primary": "db2:3306",
"ssl": "REQUIRED",
"status": "OK",
"statusText": "Cluster is ONLINE and can tolerate up to ONE failure.",
"topology": {
"db1:3306": {
"address": "db1:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db2:3306": {
"address": "db2:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db3:3306": {
"address": "db3:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
}
},
"topologyMode": "Single-Primary"
},
"groupInformationSourceMember": "db2:3306"
}Ukazuje, že db1 je nyní k dispozici, ale slouží jako sekundární s povoleným pouze pro čtení. Primární role je stále přiřazena db2, dokud se v uzlu něco nepokazí, kde bude automaticky převedeno na další dostupný uzel.
Zkontrolujte stav instance
Můžeme zkontrolovat stav uzlu MySQL před plánováním jeho přidání do clusteru pomocí funkce checkInstanceState(). Analyzuje instance spuštěné GTID se spuštěnými/vyčištěnými GTID v clusteru, aby zjistil, zda je instance pro cluster platná.
Následující obrázek ukazuje stav instance db3, když byl v samostatném režimu, před částí klastru:
MySQL|db1:3306 ssl|JS> cluster.checkInstanceState("db3:3306")
Cluster.checkInstanceState: The instance 'db3:3306' is a standalone instance but is part of a different InnoDB Cluster (metadata exists, instance does not belong to that metadata, and Group Replication is not active).Pokud je uzel již součástí clusteru, měli byste získat následující:
MySQL|db1:3306 ssl|JS> cluster.checkInstanceState("db3:3306")
Cluster.checkInstanceState: The instance 'db3:3306' already belongs to the ReplicaSet: 'default'.Sledování jakéhokoli „dotazovatelného“ stavu
S MySQL Shell nyní můžeme použít vestavěný příkaz \show and \watch ke sledování jakéhokoli administrativního dotazu v reálném čase. Například můžeme získat hodnotu připojených vláken v reálném čase pomocí:
MySQL|db1:3306 ssl|JS> \show query SHOW STATUS LIKE '%thread%';Nebo získejte aktuální seznam procesů MySQL:
MySQL|db1:3306 ssl|JS> \show query SHOW FULL PROCESSLISTPotom můžeme použít příkaz \watch ke spuštění sestavy stejným způsobem jako příkaz \show, ale obnovuje výsledky v pravidelných intervalech, dokud příkaz nezrušíte pomocí Ctrl + C. Jak je znázorněno na následující příklady:
MySQL|db1:3306 ssl|JS> \watch query SHOW STATUS LIKE '%thread%';
MySQL|db1:3306 ssl|JS> \watch query --interval=1 SHOW FULL PROCESSLISTVýchozí interval obnovení je 2 sekundy. Hodnotu můžete změnit pomocí parametru --interval a zadáním hodnoty od 0,1 do 86400.
Operace správy clusteru MySQL InnoDB
Primární přechod
Primární instance je uzel, který lze považovat za vedoucího v replikační skupině, který má schopnost provádět operace čtení a zápisu. V režimu jedné primární topologie je povolena pouze jedna primární instance na cluster. Tato topologie je také známá jako sada replik a je doporučeným režimem topologie pro skupinovou replikaci s ochranou proti konfliktům zamykání.
Chcete-li provést přepnutí primární instance, přihlaste se k jednomu z uzlů databáze jako uživatel clusteradmin a pomocí funkce setPrimaryInstance() zadejte uzel databáze, který chcete povýšit:
MySQL|db1:3306 ssl|JS> shell.connect("example@sqldat.com:3306");
MySQL|db1:3306 ssl|JS> cluster.setPrimaryInstance("db1:3306");
Setting instance 'db1:3306' as the primary instance of cluster 'my_innodb_cluster'...
Instance 'db2:3306' was switched from PRIMARY to SECONDARY.
Instance 'db3:3306' remains SECONDARY.
Instance 'db1:3306' was switched from SECONDARY to PRIMARY.
WARNING: The cluster internal session is not the primary member anymore. For cluster management operations please obtain a fresh cluster handle using <Dba>.getCluster().
The instance 'db1:3306' was successfully elected as primary.Právě jsme povýšili db1 jako novou primární komponentu, která nahradí db2, zatímco db3 zůstane jako sekundární uzel.
Vypnutí clusteru
Nejlepší způsob, jak klastr elegantně vypnout, nejprve zastavíte službu MySQL Router (pokud je spuštěna) na aplikačním serveru:
$ myrouter/stop.shVýše uvedený krok poskytuje ochranu clusteru proti náhodnému zápisu aplikací. Poté vypněte jeden databázový uzel po druhém pomocí standardního příkazu MySQL stop nebo proveďte vypnutí systému, jak si přejete:
$ systemctl stop mysqlSpuštění clusteru po vypnutí
Pokud váš cluster trpí úplným výpadkem nebo chcete cluster spustit po čistém vypnutí, můžete se ujistit, že je správně překonfigurován pomocí funkce dba.rebootClusterFromCompleteOutage(). Jednoduše vrátí cluster zpět ONLINE, když jsou všichni členové OFFLINE. V případě, že se klastr úplně zastavil, je třeba spustit instance a teprve potom lze klastr spustit.
Zajistěte tedy, aby byly všechny servery MySQL spuštěny a spuštěny. Na každém databázovém uzlu zkontrolujte, zda běží proces mysqld:
$ ps -ef | grep -i mysqlPoté vyberte jeden databázový server jako primární uzel a připojte se k němu prostřednictvím prostředí MySQL:
MySQL|JS> shell.connect("example@sqldat.com:3306");Spusťte z tohoto hostitele následující příkaz a spusťte je:
MySQL|db1:3306 ssl|JS> cluster = dba.rebootClusterFromCompleteOutage()Zobrazí se vám následující otázky:
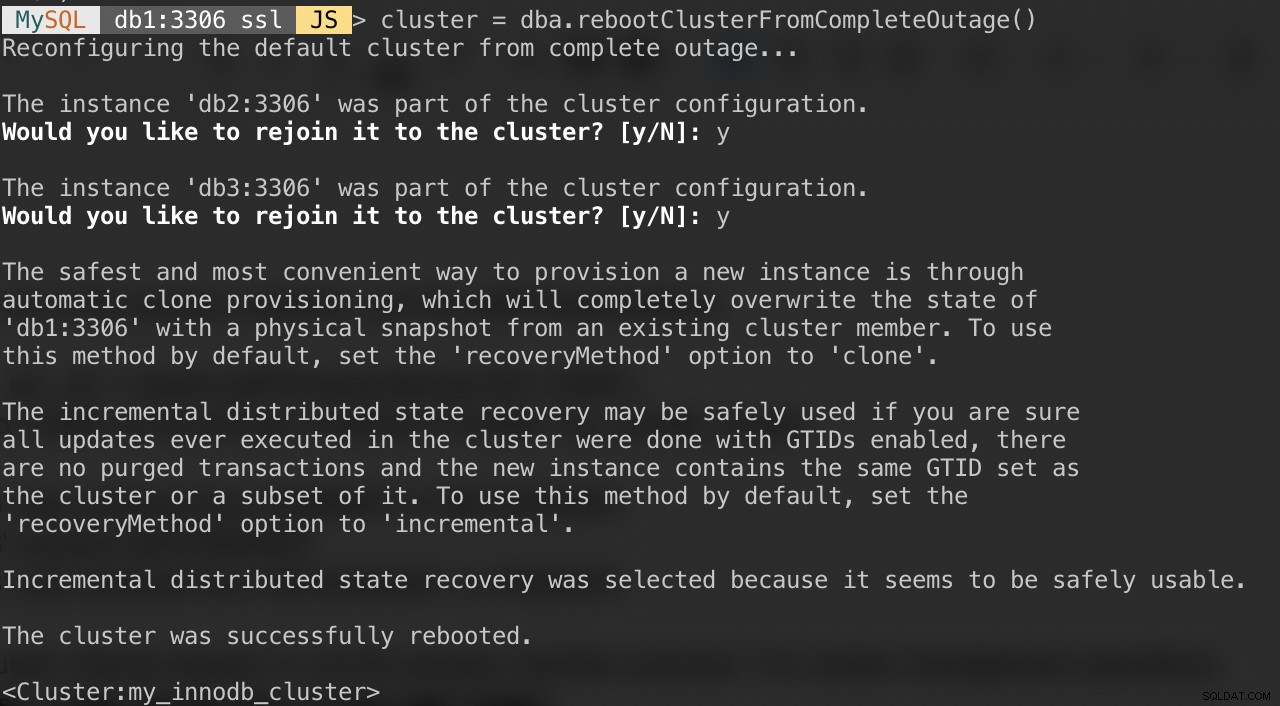
Po dokončení výše uvedeného můžete ověřit stav clusteru:
MySQL|db1:3306 ssl|JS> cluster.status()V tomto okamžiku je db1 primárním uzlem a zapisovatelem. Zbytek budou sekundární členové. Pokud byste chtěli spustit klastr s db2 nebo db3 jako primárním, můžete se pomocí funkce shell.connect() připojit k odpovídajícímu uzlu a provést rebootClusterFromCompleteOutage() z tohoto konkrétního uzlu.
Poté můžete spustit službu MySQL Router (pokud není spuštěna) a nechat aplikaci znovu se připojit ke clusteru.
Nastavení možností členů a clusteru
Chcete-li získat možnosti pro celý cluster, jednoduše spusťte:
MySQL|db1:3306 ssl|JS> cluster.options()Ve výše uvedeném seznamu jsou uvedeny globální možnosti pro sadu replik a také jednotlivé možnosti pro každého člena v clusteru. Tato funkce změní možnost konfigurace klastru InnoDB ve všech členech klastru. Podporované možnosti jsou:
- clusterName:hodnota řetězce pro definování názvu clusteru.
- exitStateAction:řetězcová hodnota označující akci výstupního stavu replikace skupiny.
- memberWeight:celočíselná hodnota s procentuální váhou pro automatické primární volby při převzetí služeb při selhání.
- failoverConsistency:hodnota řetězce udávající záruky konzistence, které cluster poskytuje.
- konzistence: hodnota řetězce udávající záruky konzistence, které cluster poskytuje.
- expelTimeout:celočíselná hodnota k definování časového období v sekundách, po které by členové klastru měli čekat na nereagujícího člena, než jej z klastru vystěhují.
- autoRejoinTries:celočíselná hodnota, která definuje, kolikrát se instance po vyloučení pokusí znovu připojit ke clusteru.
- disableClone:logická hodnota používaná k deaktivaci použití klonu v clusteru.
Podobně jako u jiných funkcí lze výstup filtrovat ve struktuře mapy. Následující příkaz zobrazí pouze možnosti pro db2:
MySQL|db1:3306 ssl|JS> cluster.options().defaultReplicaSet.topology["db2:3306"]Výše uvedený seznam můžete získat také pomocí funkce help():
MySQL|db1:3306 ssl|JS> cluster.help("setOption")Následující příkaz ukazuje příklad nastavení volby s názvem memberWeight na 60 (od 50) u všech členů:
MySQL|db1:3306 ssl|JS> cluster.setOption("memberWeight", 60)
Setting the value of 'memberWeight' to '60' in all ReplicaSet members ...
Successfully set the value of 'memberWeight' to '60' in the 'default' ReplicaSet.Můžeme také provádět správu konfigurace automaticky přes MySQL Shell pomocí funkce setInstanceOption() a podle toho předat hostitele databáze, název možnosti a hodnotu:
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster()
MySQL|db1:3306 ssl|JS> cluster.setInstanceOption("db1:3306", "memberWeight", 90)Podporované možnosti jsou:
- exitStateAction: hodnota řetězce označující akci stavu ukončení replikace skupiny.
- memberWeight:celočíselná hodnota s procentuální váhou pro automatické primární volby při převzetí služeb při selhání.
- autoRejoinTries:celočíselná hodnota, která definuje, kolikrát se instance po vyloučení pokusí znovu připojit ke clusteru.
- označte řetězec identifikátoru instance.
Přepnutí na režim Multi-Primary/Single-Primary
Ve výchozím nastavení je InnoDB Cluster nakonfigurován s jedním primárním členem, který je schopen provádět čtení a zápis v jeden daný čas. Toto je nejbezpečnější a doporučený způsob spuštění clusteru a vhodný pro většinu úloh.
Pokud však aplikační logika zvládne distribuované zápisy, je pravděpodobně dobré přepnout do multiprimárního režimu, kde jsou všichni členové v clusteru schopni zpracovávat čtení i zápis současně. Chcete-li přepnout z jednoho primárního na více primární režim, jednoduše použijte funkci switchToMultiPrimaryMode():
MySQL|db1:3306 ssl|JS> cluster.switchToMultiPrimaryMode()
Switching cluster 'my_innodb_cluster' to Multi-Primary mode...
Instance 'db2:3306' was switched from SECONDARY to PRIMARY.
Instance 'db3:3306' was switched from SECONDARY to PRIMARY.
Instance 'db1:3306' remains PRIMARY.
The cluster successfully switched to Multi-Primary mode.Ověřte pomocí:
MySQL|db1:3306 ssl|JS> cluster.status(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"ssl": "REQUIRED",
"status": "OK",
"statusText": "Cluster is ONLINE and can tolerate up to ONE failure.",
"topology": {
"db1:3306": {
"address": "db1:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db2:3306": {
"address": "db2:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db3:3306": {
"address": "db3:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
}
},
"topologyMode": "Multi-Primary"
},
"groupInformationSourceMember": "db1:3306"
}V multiprimárním režimu jsou všechny uzly primární a schopné zpracovávat čtení a zápis. Při odesílání nového připojení přes MySQL Router na portu single-writer (6446) bude připojení odesláno pouze do jednoho uzlu, jako v tomto příkladu db1:
(app-server)$ for i in {1..3}; do mysql -usbtest -p -h192.168.10.40 -P6446 -e 'select @@hostname, @@read_only, @@super_read_only'; done
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db1 | 0 | 0 |
+------------+-------------+-------------------+
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db1 | 0 | 0 |
+------------+-------------+-------------------+
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db1 | 0 | 0 |
+------------+-------------+-------------------+Pokud se aplikace připojí k portu pro více zápisů (6447), bude připojení vyrovnáváno zatížení pomocí kruhového algoritmu pro všechny členy:
(app-server)$ for i in {1..3}; do mysql -usbtest -ppassword -h192.168.10.40 -P6447 -e 'select @@hostname, @@read_only, @@super_read_only'; done
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db2 | 0 | 0 |
+------------+-------------+-------------------+
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db3 | 0 | 0 |
+------------+-------------+-------------------+
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db1 | 0 | 0 |
+------------+-------------+-------------------+Jak můžete vidět z výše uvedeného výstupu, všechny uzly jsou schopny zpracovávat čtení a zápis s read_only =OFF. Bezpečné zápisy můžete distribuovat všem členům připojením k portu pro více zapisovačů (6447) a konfliktní nebo těžké zápisy posílat na port s jedním zapisovacím zařízením (6446).
Chcete-li přepnout zpět do režimu single-primary, použijte funkci switchToSinglePrimaryMode() a zadejte jeden člen jako primární uzel. V tomto příkladu jsme zvolili db1:
MySQL|db1:3306 ssl|JS> cluster.switchToSinglePrimaryMode("db1:3306");
Switching cluster 'my_innodb_cluster' to Single-Primary mode...
Instance 'db2:3306' was switched from PRIMARY to SECONDARY.
Instance 'db3:3306' was switched from PRIMARY to SECONDARY.
Instance 'db1:3306' remains PRIMARY.
WARNING: Existing connections that expected a R/W connection must be disconnected, i.e. instances that became SECONDARY.
The cluster successfully switched to Single-Primary mode.V tomto okamžiku je nyní db1 primárním uzlem konfigurovaným s deaktivovaným pouze pro čtení a zbytek bude nakonfigurován jako sekundární s povoleným pouze pro čtení.
Operace škálování clusteru MySQL InnoDB
Zvětšení (přidání nového uzlu DB)
Při přidávání nové instance musí být uzel nejprve zřízen, než mu bude povoleno účastnit se replikační skupiny. Proces zřizování bude zpracován automaticky pomocí MySQL. Také můžete nejprve zkontrolovat stav instance, zda je uzel platný pro připojení ke clusteru pomocí funkce checkInstanceState(), jak bylo vysvětleno dříve.
Chcete-li přidat nový uzel DB, použijte funkci addInstances() a zadejte hostitele:
MySQL|db1:3306 ssl|JS> cluster.addInstance("db3:3306")Při přidávání nové instance získáte následující:
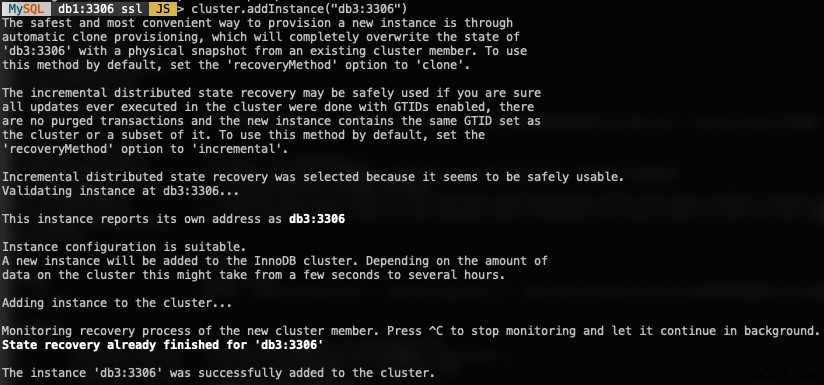
Ověřte novou velikost clusteru pomocí:
MySQL|db1:3306 ssl|JS> cluster.status() //or cluster.describe()MySQL Router automaticky zahrne přidaný uzel db3 do sady pro vyrovnávání zátěže.
Zmenšení (odstranění uzlu)
Chcete-li odebrat uzel, připojte se k libovolnému z uzlů DB kromě toho, který se chystáme odebrat, a použijte funkci removeInstance() s názvem instance databáze:
MySQL|db1:3306 ssl|JS> shell.connect("example@sqldat.com:3306");
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster()
MySQL|db1:3306 ssl|JS> cluster.removeInstance("db3:3306")Při odstranění instance získáte následující:
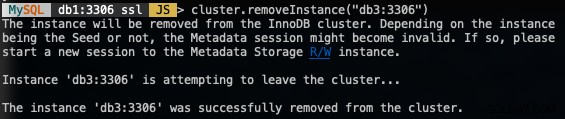
Ověřte novou velikost clusteru pomocí:
MySQL|db1:3306 ssl|JS> cluster.status() //or cluster.describe()Směrovač MySQL automaticky vyloučí odstraněný uzel db3 ze sady vyrovnávání zátěže.
Přidání nového slave replikačního zařízení
Můžeme škálovat InnoDB Cluster pomocí asynchronních replikačních slave replikací z kteréhokoli z uzlů clusteru. Slave je volně připojen ke clusteru a bude schopen zvládnout velkou zátěž bez ovlivnění výkonu clusteru. Slave může být také živá kopie databáze pro účely obnovy po havárii. V multiprimárním režimu můžete podřízenou jednotku použít jako vyhrazený procesor MySQL pouze pro čtení ke zmenšení zátěže čtení, provádění analytických operací nebo jako vyhrazený záložní server.
Na podřízeném serveru si stáhněte nejnovější konfigurační balíček APT, nainstalujte jej (v průvodci konfigurací vyberte MySQL 8.0), nainstalujte klíč APT, aktualizujte repolist a nainstalujte server MySQL.
$ wget https://repo.mysql.com/apt/ubuntu/pool/mysql-apt-config/m/mysql-apt-config/mysql-apt-config_0.8.14-1_all.deb
$ dpkg -i mysql-apt-config_0.8.14-1_all.deb
$ apt-key adv --recv-keys --keyserver ha.pool.sks-keyservers.net 5072E1F5
$ apt-get update
$ apt-get -y install mysql-server mysql-shellUpravte konfigurační soubor MySQL, abyste připravili server na replikaci slave. Otevřete konfigurační soubor pomocí textového editoru:
$ vim /etc/mysql/mysql.conf.d/mysqld.cnfA připojte následující řádky:
server-id = 1044 # must be unique across all nodes
gtid-mode = ON
enforce-gtid-consistency = ON
log-slave-updates = OFF
read-only = ON
super-read-only = ON
expire-logs-days = 7Restartujte server MySQL na podřízeném zařízení, aby se změny projevily:
$ systemctl restart mysqlNa jednom ze serverů InnoDB Cluster (vybrali jsme db3) vytvořte replikačního slave uživatele a následuje úplný výpis MySQL:
$ mysql -uroot -p
mysql> CREATE USER 'repl_user'@'192.168.0.44' IDENTIFIED BY 'password';
mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl_user'@'192.168.0.44';
mysql> exit
$ mysqldump -uroot -p --single-transaction --master-data=1 --all-databases --triggers --routines --events > dump.sqlPřeneste soubor výpisu z db3 do slave:
$ scp dump.sql example@sqldat.com:~A proveďte obnovu na podřízeném:
$ mysql -uroot -p < dump.sqlS master-data=1 náš soubor výpisu MySQL automaticky nakonfiguruje spouštěnou a vyčištěnou hodnotu GTID. Můžeme to ověřit pomocí následujícího příkazu na podřízeném serveru po obnovení:
$ mysql -uroot -p
mysql> show global variables like '%gtid_%';
+----------------------------------+----------------------------------------------+
| Variable_name | Value |
+----------------------------------+----------------------------------------------+
| binlog_gtid_simple_recovery | ON |
| enforce_gtid_consistency | ON |
| gtid_executed | d4790339-0694-11ea-8fd5-02f67042125d:1-45886 |
| gtid_executed_compression_period | 1000 |
| gtid_mode | ON |
| gtid_owned | |
| gtid_purged | d4790339-0694-11ea-8fd5-02f67042125d:1-45886 |
+----------------------------------+----------------------------------------------+Vypadá dobře. Poté můžeme nakonfigurovat replikační odkaz a spustit replikační vlákna na slave:
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.10.43', MASTER_USER = 'repl_user', MASTER_PASSWORD = 'password', MASTER_AUTO_POSITION = 1;
mysql> START SLAVE;Ověřte stav replikace a zajistěte, aby následující stav vrátil 'Ano':
mysql> show slave status\G
...
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
...V tuto chvíli naše architektura nyní vypadá takto:
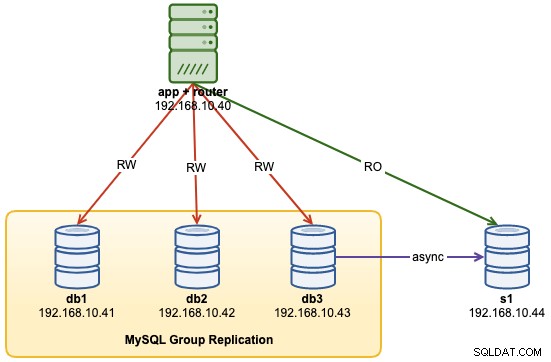
Běžné problémy s clustery MySQL InnoDB
Vyčerpání paměti
Při použití prostředí MySQL s MySQL 8.0 jsme neustále dostávali následující chybu, když byly instance nakonfigurovány s 1 GB paměti RAM:
Can't create a new thread (errno 11); if you are not out of available memory, you can consult the manual for a possible OS-dependent bug (MySQL Error 1135)Upgrade RAM každého hostitele na 2 GB RAM problém vyřešil. Komponenty MySQL 8.0 zjevně vyžadují více paměti RAM, aby fungovaly efektivně.
Ztracené připojení k serveru MySQL
In case the primary node goes down, you would probably see the "lost connection to MySQL server error" when trying to query something on the current session:
MySQL|db1:3306 ssl|JS> cluster.status()
Cluster.status: Lost connection to MySQL server during query (MySQL Error 2013)
MySQL|db1:3306 ssl|JS> cluster.status()
Cluster.status: MySQL server has gone away (MySQL Error 2006)The solution is to re-declare the object once more:
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster()
<Cluster:my_innodb_cluster>
MySQL|db1:3306 ssl|JS> cluster.status()At this point, it will connect to the newly promoted primary node to retrieve the cluster status.
Node Eviction and Expelled
In an event where communication between nodes is interrupted, the problematic node will be evicted from the cluster without any delay, which is not good if you are running on a non-stable network. This is what it looks like on db2 (the problematic node):
2019-11-14T07:07:59.344888Z 0 [ERROR] [MY-011505] [Repl] Plugin group_replication reported: 'Member was expelled from the group due to network failures, changing member status to ERROR.'
2019-11-14T07:07:59.371966Z 0 [ERROR] [MY-011712] [Repl] Plugin group_replication reported: 'The server was automatically set into read only mode after an error was detected.'Meanwhile from db1, it saw db2 was offline:
2019-11-14T07:07:44.086021Z 0 [Warning] [MY-011493] [Repl] Plugin group_replication reported: 'Member with address db2:3306 has become unreachable.'
2019-11-14T07:07:46.087216Z 0 [Warning] [MY-011499] [Repl] Plugin group_replication reported: 'Members removed from the group: db2:3306'
To tolerate a bit of delay on node eviction, we can set a higher timeout value before a node is being expelled from the group. The default value is 0, which means expel immediately. Use the setOption() function to set the expelTimeout value:
Thanks to Frédéric Descamps from Oracle who pointed this out:
Instead of relying on expelTimeout, it's recommended to set the autoRejoinTries option instead. The value represents the number of times an instance will attempt to rejoin the cluster after being expelled. A good number to start is 3, which means, the expelled member will try to rejoin the cluster for 3 times, which after an unsuccessful auto-rejoin attempt, the member waits 5 minutes before the next try.
To set this value cluster-wide, we can use the setOption() function:
MySQL|db1:3306 ssl|JS> cluster.setOption("autoRejoinTries", 3)
WARNING: Each cluster member will only proceed according to its exitStateAction if auto-rejoin fails (i.e. all retry attempts are exhausted).
Setting the value of 'autoRejoinTries' to '3' in all ReplicaSet members ...
Successfully set the value of 'autoRejoinTries' to '3' in the 'default' ReplicaSet.
Závěr
For MySQL InnoDB Cluster, most of the management and monitoring operations can be performed directly via MySQL Shell (only available from MySQL 5.7.21 and later).