V tomto příspěvku na blogu se podíváme na některé klíčové metriky a stav při monitorování serveru Percona pro MySQL, abychom mohli dlouhodobě doladit konfiguraci serveru MySQL. Jen pro upozornění, Percona Server má některé monitorovací metriky, které jsou k dispozici pouze v tomto sestavení. Při porovnání s verzí 8.0.20 je následujících 51 stavů dostupných pouze na serveru Percona pro MySQL, které nejsou dostupné na upstreamovém komunitním serveru Oracle MySQL:
- Binlog_snapshot_file
- Binlog_snapshot_position
- Binlog_snapshot_gtid_executed
- Com_create_compression_dictionary
- Com_drop_compression_dictionary
- Com_lock_tables_for_backup
- Com_show_client_statistics
- Com_show_index_statistics
- Com_show_table_statistics
- Com_show_thread_statistics
- Com_show_user_statistics
- Innodb_background_log_sync
- Innodb_buffer_pool_pages_LRU_flushed
- Innodb_buffer_pool_pages_made_not_young
- Innodb_buffer_pool_pages_made_young
- Innodb_buffer_pool_pages_old
- Innodb_checkpoint_age
- Innodb_ibuf_free_list
- Innodb_ibuf_segment_size
- Innodb_lsn_current
- Innodb_lsn_flushed
- Innodb_lsn_last_checkpoint
- Innodb_master_thread_active_loops
- Innodb_master_thread_idle_loops
- Innodb_max_trx_id
- Innodb_oldest_view_low_limit_trx_id
- Innodb_pages0_read
- Innodb_purge_trx_id
- Innodb_purge_undo_no
- Innodb_secondary_index_triggered_cluster_reads
- Innodb_secondary_index_triggered_cluster_reads_avoided
- Innodb_buffered_aio_submitted
- Innodb_scan_pages_contiguous
- Innodb_scan_pages_disjointed
- Innodb_scan_pages_total_seek_distance
- Innodb_scan_data_size
- Innodb_scan_deleted_recs_size
- Innodb_scrub_log
- Innodb_scrub_background_page_reorganizations
- Innodb_scrub_background_page_splits
- Innodb_scrub_background_page_split_failures_underflow
- Innodb_scrub_background_page_split_failures_out_of_filespace
- Innodb_scrub_background_page_split_failures_missing_index
- Innodb_scrub_background_page_split_failures_unknown
- Innodb_encryption_n_merge_blocks_encrypted
- Innodb_encryption_n_merge_blocks_decrypted
- Innodb_encryption_n_rowlog_blocks_encrypted
- Innodb_encryption_n_rowlog_blocks_decrypted
- Innodb_encryption_redo_key_version
- Threadpool_idle_threads
- Threadpool_threads
Podívejte se na stránku Extended InnoDB Status, kde najdete další informace o každé z výše uvedených metrik monitorování. Všimněte si, že některé další stavy, jako je fond vláken, jsou k dispozici pouze v Oracle MySQL Enterprise. Podívejte se na dokumentaci Percona Server for MySQL 8.0, kde najdete všechna vylepšení specificky pro toto sestavení oproti Oracle MySQL Community Server 8.0.
Chcete-li získat globální stav MySQL, jednoduše použijte jeden z následujících příkazů:
mysql> SHOW GLOBAL STATUS;
mysql> SHOW GLOBAL STATUS LIKE '%connect%'; -- list all status that contain string "connect"
mysql> SELECT * FROM performance_schema.global_status;
mysql> SELECT * FROM performance_schema.global_status WHERE VARIABLE_NAME LIKE '%connect%'; -- list all status that contain string "connect"Stav a přehled databáze
Začneme stavem provozuschopnosti, počtem sekund, po které byl server v provozu.
Všechny stavy com_* jsou proměnné čítače příkazů, které udávají, kolikrát byl každý příkaz proveden. Pro každý typ příkazu existuje jedna stavová proměnná. Například příkazy com_delete a com_update počítají příkazy DELETE a UPDATE. Příkazy com_delete_multi a com_update_multi jsou podobné, ale platí pro příkazy DELETE a UPDATE, které používají syntaxi více tabulek.
Chcete-li vypsat všechny běžící procesy MySQL, stačí spustit jeden z následujících příkazů:
mysql> SHOW PROCESSLIST;
mysql> SHOW FULL PROCESSLIST;
mysql> SELECT * FROM information_schema.processlist;
mysql> SELECT * FROM information_schema.processlist WHERE command <> 'sleep'; -- list all active processes except 'sleep' command.Spojení a vlákna
Aktuální připojení
Poměr aktuálně otevřených spojení (spojovací vlákno). Pokud je poměr vysoký, znamená to, že existuje mnoho souběžných připojení k serveru MySQL a mohlo by to vést k chybě „Příliš mnoho připojení“. Chcete-li získat procento připojení:
Current connections(%) = (threads_connected / max_connections) x 100Dobrá hodnota by měla být 80 % a méně. Zkuste zvýšit proměnnou max_connections nebo zkontrolujte připojení pomocí ZOBRAZIT ÚPLNÝ SEZNAM PROCESŮ. Pokud dojde k chybě „Příliš mnoho připojení“, databázový server MySQL se stane nedostupným pro uživatele, který není superuživatelem, dokud se některá připojení neuvolní. Všimněte si, že zvýšení proměnné max_connections by také mohlo potenciálně zvýšit paměťovou stopu MySQL.
Maximální počet zaznamenaných připojení
Poměr maximálního počtu připojení k serveru MySQL, který byl kdy zaznamenán. Jednoduchý výpočet by byl:
Max connections ever seen(%) = (max_used_connections / max_connections) x 100Dobrá hodnota by měla být nižší než 80 %. Pokud je poměr vysoký, znamená to, že MySQL jednou dosáhlo vysokého počtu připojení, což by vedlo k chybě „příliš mnoho připojení“. Zkontrolujte aktuální poměr připojení a zjistěte, zda je skutečně trvale nízký. V opačném případě zvyšte proměnnou max_connections. Zkontrolujte stav max_used_connections_time a uveďte, kdy stav max_used_connections dosáhl aktuální hodnoty.
Míra návštěvnosti mezipaměti vláken
Stav threads_created je počet vláken vytvořených pro zpracování připojení. Pokud je threads_created velký, možná budete chtít zvýšit hodnotu thread_cache_size. Četnost mezipaměti lze vypočítat takto:
Threads cache hit rate (%) = (threads_created / connections) x 100Je to zlomek, který udává míru návštěvnosti mezipaměti vláken. Čím blíže méně než 50 %, tím lépe. Pokud váš server vidí stovky připojení za sekundu, měli byste normálně nastavit thread_cache_size dostatečně vysoko, aby většina nových připojení používala vlákna uložená v mezipaměti.
Výkon dotazu
Prohledávání celé tabulky
Poměr úplného prohledávání tabulky, operace, která vyžaduje čtení celého obsahu tabulky, nikoli pouze vybrané části pomocí indexu. Tato hodnota je vysoká, pokud provádíte mnoho dotazů, které vyžadují řazení výsledků nebo skenování tabulek. Obecně to naznačuje, že tabulky nejsou správně indexovány nebo že vaše dotazy nejsou zapsány tak, aby využívaly indexy, které máte. Chcete-li vypočítat procento prohledání celé tabulky:
Full table scans (%) = (handler_read_rnd_next + handler_read_rnd) /
(handler_read_rnd_next + handler_read_rnd + handler_read_first + handler_read_next + handler_read_key + handler_read_prev)
x 100Dobrá hodnota by měla být nižší než 25 %. Prozkoumejte výstup protokolu pomalých dotazů MySQL a zjistěte suboptimální dotazy.
Vyberte možnost Úplné připojení
Stav select_full_join je počet spojení, která provádějí prohledávání tabulek, protože nepoužívají indexy. Pokud tato hodnota není 0, měli byste pečlivě zkontrolovat indexy vašich tabulek.
Vyberte kontrolu rozsahu
Stav select_range_check je počet spojení bez klíčů, které kontrolují použití klíče po každém řádku. Pokud to není 0, měli byste pečlivě zkontrolovat indexy vašich tabulek.
Řadit průkazy
Poměr slučovacích průchodů, které musel provést třídicí algoritmus. Pokud je tato hodnota vysoká, měli byste zvážit zvýšení hodnoty sort_buffer_size a read_rnd_buffer_size. Jednoduchý výpočet poměru je:
Sort passes = sort_merge_passes / (sort_scan + sort_range)Hodnota poměru nižší než 3 by měla být dobrá hodnota. Pokud chcete zvýšit sort_buffer_size nebo read_rnd_buffer_size, snažte se zvyšovat po malých krocích, dokud nedosáhnete přijatelného poměru.
Výkon InnoDB
Míra návštěvnosti fondu vyrovnávací paměti InnoDB
Poměr toho, jak často jsou vaše stránky načítány z paměti místo z disku. Pokud je hodnota během časného spouštění MySQL nízká, počkejte, prosím, nějakou dobu na zahřátí fondu vyrovnávacích pamětí. Chcete-li získat četnost přístupu k fondu vyrovnávacích pamětí, použijte příkaz SHOW ENGINE INNODB STATUS:
mysql> SHOW ENGINE INNODB STATUS\G
...
----------------------
BUFFER POOL AND MEMORY
----------------------
...
Buffer pool hit rate 1000 / 1000, young-making rate 0 / 1000 not 0 / 1000
...Nejlepší hodnota je 1 000 / 10 000 návštěvnosti. Pro nižší hodnotu například míra návštěvnosti 986/1000 znamená, že z 1000 přečtení stránky byl schopen přečíst stránky v paměti RAM 986krát. Zbývajících 14krát muselo MySQL číst stránky z disku. Jednoduše řečeno, 1000/1000 je nejlepší hodnota, které se zde snažíme dosáhnout, což znamená, že často používaná data se plně vejdou do paměti RAM.
Zvýšení proměnné innodb_buffer_pool_size hodně pomůže vytvořit více prostoru pro MySQL pro práci. Předtím se však ujistěte, že máte dostatek zdrojů paměti RAM. Pomoci by mohlo i odstranění nadbytečných indexů. Pokud máte více instancí fondu vyrovnávacích pamětí, ujistěte se, že četnost přístupu pro každou instanci dosahuje 1000/1000.
Nečisté stránky InnoDB
Poměr toho, jak často je třeba InnoDB spláchnout. Při velkém zatížení zápisem je normální, že se toto procento zvyšuje.
Jednoduchý výpočet by byl:
InnoDB dirty pages(%) = (innodb_buffer_pool_pages_dirty / innodb_buffer_pool_pages_total) x 100Dobrá hodnota by měla být 75 % a méně. Pokud procento nečistých stránek zůstává vysoké po dlouhou dobu, možná budete chtít zvýšit fond vyrovnávací paměti nebo získat rychlejší disky, abyste se vyhnuli problémům s výkonem.
InnoDB čeká na kontrolní bod
Poměr toho, jak často InnoDB potřebuje číst nebo vytvářet stránku, kde nejsou dostupné žádné čisté stránky. Normálně se zápisy do InnoDB Buffer Pool odehrávají na pozadí. Pokud je však nutné přečíst nebo vytvořit stránku a nejsou k dispozici žádné čisté stránky, je také nutné počkat, než se stránky nejprve vyprázdní. Čítač innodb_buffer_pool_wait_free počítá, kolikrát se to stalo. Pro výpočet poměru čekání InnoDB na checkpointing můžeme použít následující výpočet:
InnoDB waits for checkpoint = innodb_buffer_pool_wait_free / innodb_buffer_pool_write_requestsPokud je innodb_buffer_pool_wait_free větší než 0, je to silný indikátor toho, že fond vyrovnávacích pamětí InnoDB je příliš malý a operace musely čekat na kontrolní bod. Zvýšení innodb_buffer_pool_size obvykle sníží innodb_buffer_pool_wait_free, stejně jako tento poměr. Dobrá hodnota poměru by měla zůstat pod 1.
InnoDB čeká na Redolog
Poměr redo log sporu. Zkontrolujte innodb_log_waits a pokud se stále zvyšuje, zvyšte velikost innodb_log_buffer_size. Může to také znamenat, že disky jsou příliš pomalé a neudrží IO disku, možná kvůli špičkové zátěži při zápisu. K výpočtu poměru čekání redo log použijte následující výpočet:
InnoDB waits for redolog = innodb_log_waits / innodb_log_writesDobrá hodnota poměru by měla být nižší než 1. V opačném případě zvyšte innodb_log_buffer_size.
Tabulky
Využití mezipaměti tabulky
Poměr využití mezipaměti tabulky pro všechna vlákna. Jednoduchý výpočet by byl:
Table cache usage(%) = (opened_tables / table_open_cache) x 100Dobrá hodnota by měla být nižší než 80 %. Zvyšte proměnnou table_open_cache, dokud procento nedosáhne dobré hodnoty.
Poměr návštěvnosti mezipaměti tabulky
Poměr využití mezipaměti tabulky. Jednoduchý výpočet by byl:
Table cache hit ratio(%) = (open_tables / opened_tables) x 100Dobrá hodnota poměru požadavků na server by měla být 90 % a vyšší. V opačném případě zvyšujte proměnnou table_open_cache, dokud poměr požadavků na server nedosáhne dobré hodnoty.
Monitorování metrik pomocí ClusterControl
ClusterControl podporuje Percona Server pro MySQL a poskytuje agregovaný pohled na všechny uzly v clusteru na stránce ClusterControl -> Výkon -> Stav DB. To poskytuje centralizovaný přístup k vyhledání veškerého stavu na všech hostitelích s možností filtrovat stav, jak ukazuje následující snímek obrazovky:
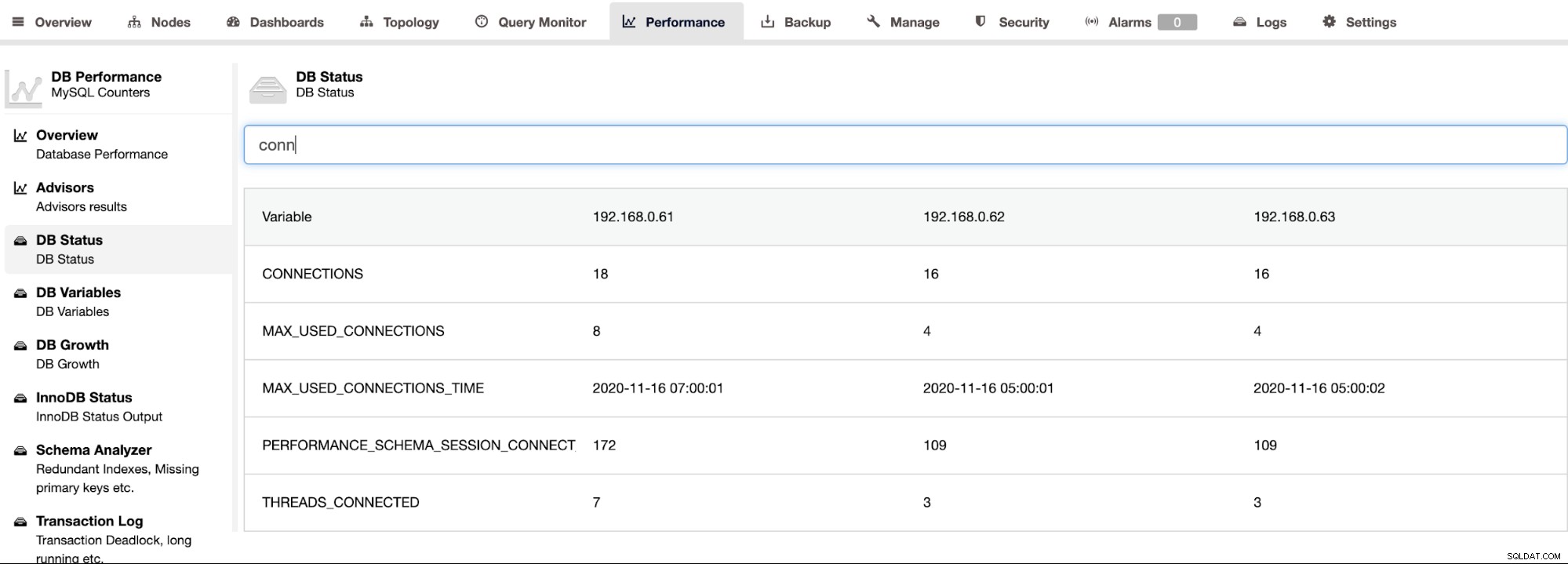
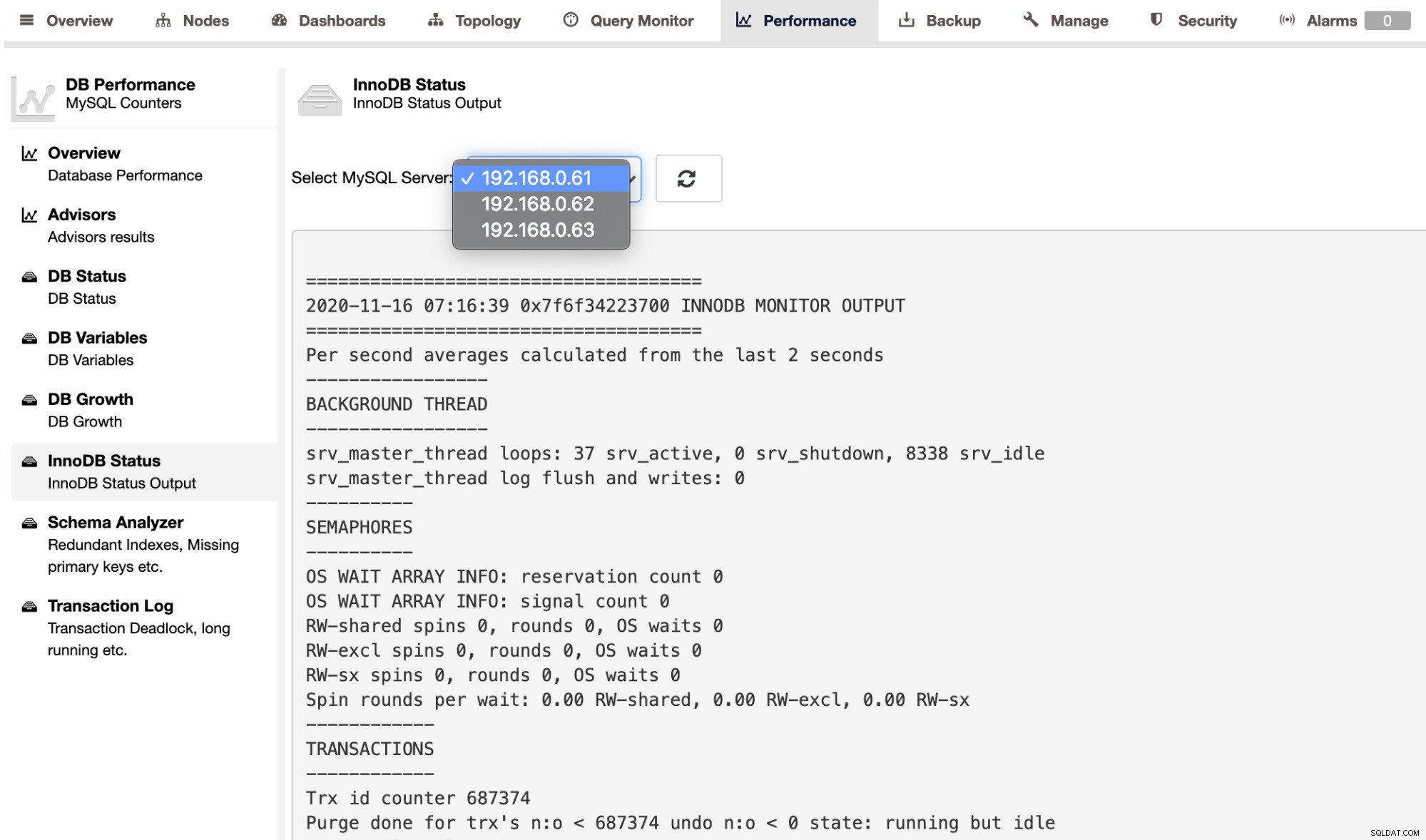
Chcete-li načíst výstup SHOW ENGINE INNODB STATUS pro jednotlivý server, můžete použijte stránku Výkon -> Stav InnoDB, jak je znázorněno níže:
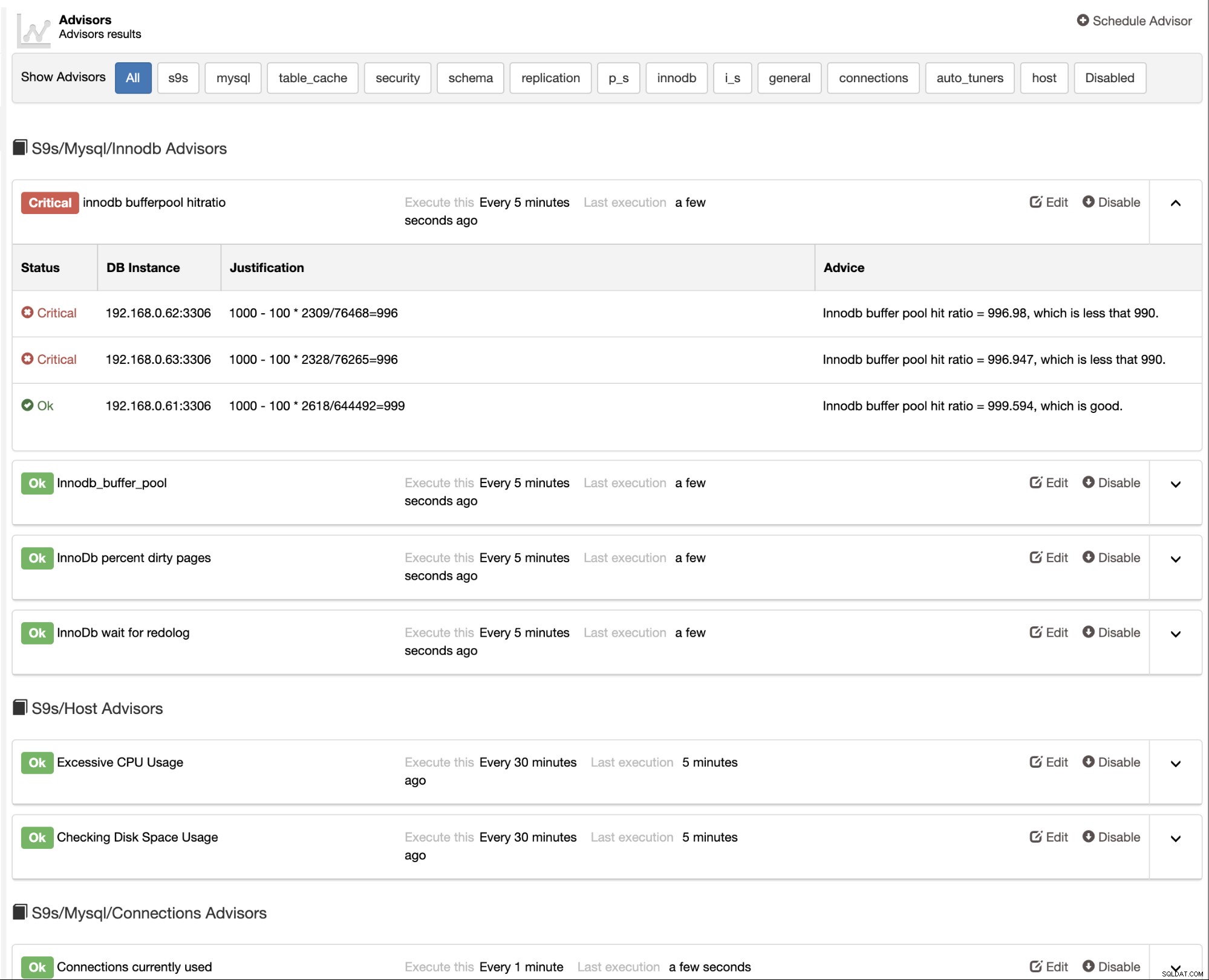
ClusterControl také poskytuje vestavěné poradce, které můžete použít ke sledování databáze výkon. Tato funkce je dostupná pod ClusterControl -> Výkon -> Poradci:
Poradci jsou v podstatě miniprogramy spouštěné ClusterControl v naplánovaném načasování jako cron pracovní místa. Poradce můžete naplánovat kliknutím na tlačítko „Naplánovat poradce“ a vybrat libovolného stávajícího poradce ze stromu objektů Developer Studio:
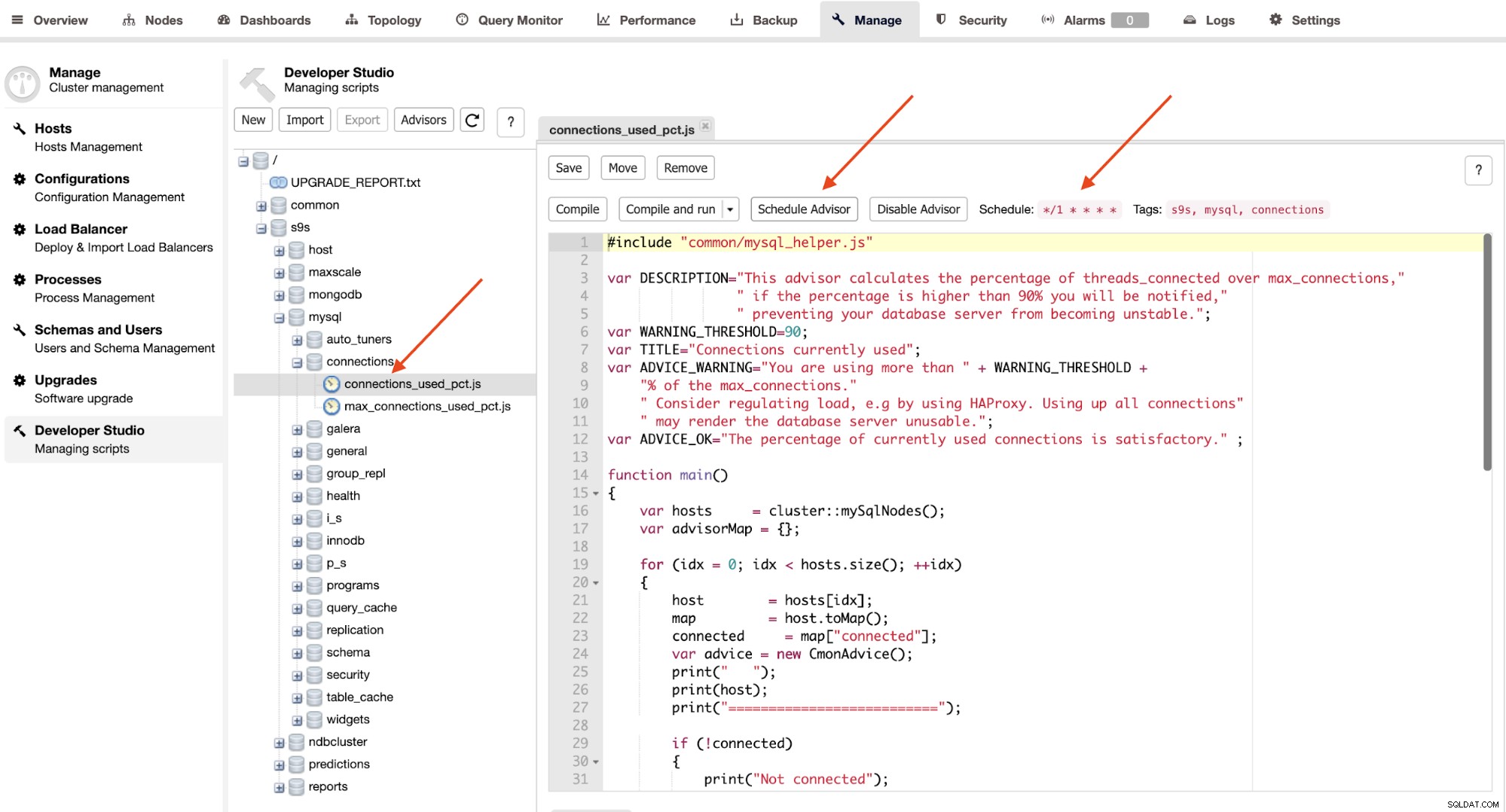
Kliknutím na tlačítko "Schedule Advisor" nastavíte plánování, argument na průkaz a také značky poradce. Poradce můžete také zkompilovat, abyste okamžitě viděli výstup kliknutím na tlačítko „Zkompilovat a spustit“, kde pod „Zprávami“ byste měli vidět následující výstup:

Můžete si vytvořit vlastního poradce podle této příručky pro vývojáře, napsané v Jazyk specifický pro doménu ClusterControl (velmi podobný Javascriptu) nebo přizpůsobte stávajícího poradce tak, aby vyhovoval vašim zásadám monitorování. Stručně řečeno, monitorovací povinnost ClusterControl lze rozšířit o neomezené možnosti prostřednictvím ClusterControl Advisors.