Příklad naleznete zde:https://github.com/afedulov/routing-data- zdroj .
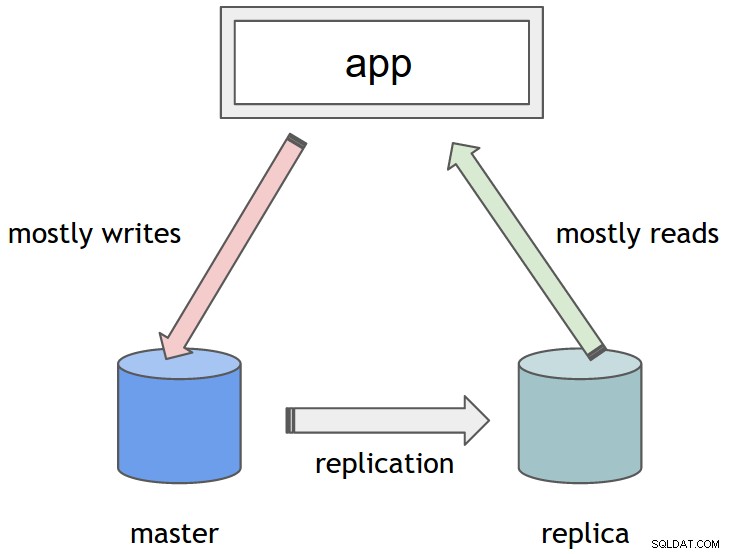
Spring poskytuje variantu DataSource nazvanou AbstractRoutingDatasource . Lze jej použít místo standardních implementací DataSource a umožňuje mechanismus určit, který konkrétní DataSource použít pro jednotlivé operace za běhu. Vše, co musíte udělat, je rozšířit jej a poskytnout implementaci abstraktního determineCurrentLookupKey metoda. Toto je místo, kde můžete implementovat svou vlastní logiku k určení konkrétního zdroje dat. Vrácený objekt slouží jako vyhledávací klíč. Obvykle je to řetězec nebo en Enum, který se používá jako kvalifikátor v konfiguraci Spring (podrobnosti budou následovat).
package website.fedulov.routing.RoutingDataSource
import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource;
public class RoutingDataSource extends AbstractRoutingDataSource {
@Override
protected Object determineCurrentLookupKey() {
return DbContextHolder.getDbType();
}
}
Možná vás zajímá, co je to objekt DbContextHolder a jak ví, který identifikátor DataSource má vrátit? Mějte na paměti, že determineCurrentLookupKey metoda bude volána vždy, když TransactionsManager požádá o připojení. Je důležité si uvědomit, že každá transakce je „přidružena“ k samostatnému vláknu. Přesněji, TransactionsManager váže připojení k aktuálnímu vláknu. Proto, abychom mohli odesílat různé transakce do různých cílových zdrojů dat, musíme se ujistit, že každé vlákno dokáže spolehlivě identifikovat, který zdroj dat je určen k použití. Díky tomu je přirozené používat proměnné ThreadLocal pro navázání konkrétního zdroje dat na vlákno a tedy na transakci. Dělá se to takto:
public enum DbType {
MASTER,
REPLICA1,
}
public class DbContextHolder {
private static final ThreadLocal<DbType> contextHolder = new ThreadLocal<DbType>();
public static void setDbType(DbType dbType) {
if(dbType == null){
throw new NullPointerException();
}
contextHolder.set(dbType);
}
public static DbType getDbType() {
return (DbType) contextHolder.get();
}
public static void clearDbType() {
contextHolder.remove();
}
}
Jak vidíte, můžete jako klíč použít i enum a Spring se postará o jeho správné vyřešení na základě názvu. Přidružená konfigurace a klíče DataSource mohou vypadat takto:
....
<bean id="dataSource" class="website.fedulov.routing.RoutingDataSource">
<property name="targetDataSources">
<map key-type="com.sabienzia.routing.DbType">
<entry key="MASTER" value-ref="dataSourceMaster"/>
<entry key="REPLICA1" value-ref="dataSourceReplica"/>
</map>
</property>
<property name="defaultTargetDataSource" ref="dataSourceMaster"/>
</bean>
<bean id="dataSourceMaster" class="org.apache.commons.dbcp.BasicDataSource">
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
<property name="url" value="${db.master.url}"/>
<property name="username" value="${db.username}"/>
<property name="password" value="${db.password}"/>
</bean>
<bean id="dataSourceReplica" class="org.apache.commons.dbcp.BasicDataSource">
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
<property name="url" value="${db.replica.url}"/>
<property name="username" value="${db.username}"/>
<property name="password" value="${db.password}"/>
</bean>
V tomto okamžiku můžete zjistit, že děláte něco takového:
@Service
public class BookService {
private final BookRepository bookRepository;
private final Mapper mapper;
@Inject
public BookService(BookRepository bookRepository, Mapper mapper) {
this.bookRepository = bookRepository;
this.mapper = mapper;
}
@Transactional(readOnly = true)
public Page<BookDTO> getBooks(Pageable p) {
DbContextHolder.setDbType(DbType.REPLICA1); // <----- set ThreadLocal DataSource lookup key
// all connection from here will go to REPLICA1
Page<Book> booksPage = callActionRepo.findAll(p);
List<BookDTO> pContent = CollectionMapper.map(mapper, callActionsPage.getContent(), BookDTO.class);
DbContextHolder.clearDbType(); // <----- clear ThreadLocal setting
return new PageImpl<BookDTO>(pContent, p, callActionsPage.getTotalElements());
}
...//other methods
Nyní můžeme ovládat, který DataSource bude použit, a přeposílat požadavky, jak chceme. Vypadá dobře!
...nebo ano? Za prvé, tato statická volání metod do magického DbContextHolder opravdu trčí. Vypadají, jako by nepatřily k obchodní logice. A oni ne. Nejen, že nesdělují účel, ale zdají se být křehké a náchylné k chybám (co takhle zapomenout vyčistit dbType). A co když je vyvolána výjimka mezi setDbType a cleanDbType? Nemůžeme to jen tak ignorovat. Musíme si být absolutně jisti, že jsme resetovali dbType, jinak by vlákno vrácené do ThreadPool mohlo být v „rozbitém“ stavu a při příštím volání se pokoušelo zapisovat do repliky. Takže potřebujeme toto:
@Transactional(readOnly = true)
public Page<BookDTO> getBooks(Pageable p) {
try{
DbContextHolder.setDbType(DbType.REPLICA1); // <----- set ThreadLocal DataSource lookup key
// all connection from here will go to REPLICA1
Page<Book> booksPage = callActionRepo.findAll(p);
List<BookDTO> pContent = CollectionMapper.map(mapper, callActionsPage.getContent(), BookDTO.class);
DbContextHolder.clearDbType(); // <----- clear ThreadLocal setting
} catch (Exception e){
throw new RuntimeException(e);
} finally {
DbContextHolder.clearDbType(); // <----- make sure ThreadLocal setting is cleared
}
return new PageImpl<BookDTO>(pContent, p, callActionsPage.getTotalElements());
}
Jejda >_< ! Tohle rozhodně nevypadá jako něco, co bych chtěl vložit do každé metody pouze pro čtení. Můžeme to udělat lépe? Samozřejmě! Tento vzorec „udělejte něco na začátku metody a pak udělejte něco na konci“ by měl odzvonit. Aspekty k záchraně!
Bohužel tento příspěvek je již příliš dlouhý na to, aby pokryl téma vlastních aspektů. Podrobnosti o používání aspektů můžete sledovat pomocí tohoto odkaz .