Má, alespoň někdy. Testoval jsem chování MySQL Connector/J verze 5.1.37 pomocí Wireshark. Pro stůl ...
CREATE TABLE lorem (
id INT AUTO_INCREMENT PRIMARY KEY,
tag VARCHAR(7),
text1 VARCHAR(255),
text2 VARCHAR(255)
)
... s testovacími daty ...
id tag text1 text2
--- ------- --------------- ---------------
0 row_000 Lorem ipsum ... Lorem ipsum ...
1 row_001 Lorem ipsum ... Lorem ipsum ...
2 row_002 Lorem ipsum ... Lorem ipsum ...
...
999 row_999 Lorem ipsum ... Lorem ipsum ...
(where both `text1` and `text2` actually contain 255 characters in each row)
... a kód ...
try (Statement s = conn.createStatement(java.sql.ResultSet.TYPE_FORWARD_ONLY, java.sql.ResultSet.CONCUR_READ_ONLY)) {
s.setFetchSize(Integer.MIN_VALUE);
String sql = "SELECT * FROM lorem ORDER BY id";
try (ResultSet rs = s.executeQuery(sql)) {
... bezprostředně za s.executeQuery(sql) – tj. před rs.next() se dokonce nazývá – MySQL Connector/J načetl prvních ~140 řádků z tabulky.
Ve skutečnosti při dotazu pouze na tag sloupec
String sql = "SELECT tag FROM lorem ORDER BY id";
MySQL Connector/J okamžitě načetl všech 1000 řádků, jak ukazuje seznam síťových rámců Wireshark:
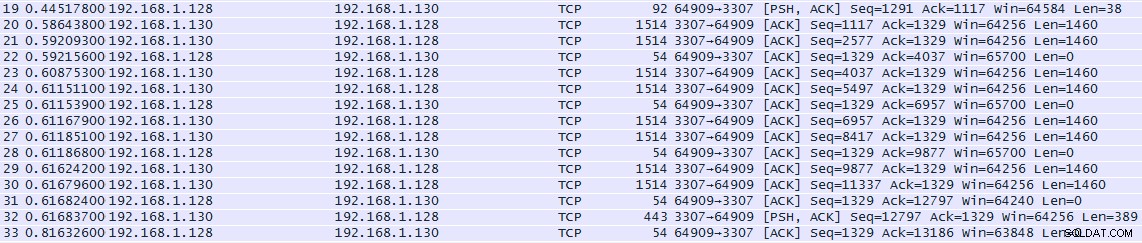
Snímek 19, který odeslal dotaz na server, vypadal takto:

Server MySQL odpověděl rámcem 20, který začínal ...
... a hned po něm následoval snímek 21, který začínal ...

... a tak dále, dokud server neodeslal snímek 32, který skončil s
Protože jediným rozdílem bylo množství informací vrácených pro každý řádek, můžeme dojít k závěru, že MySQL Connector/J rozhoduje o vhodné velikosti vyrovnávací paměti na základě maximální délky každého vráceného řádku a množství dostupné volné paměti.
MySQL Connector/J zpočátku načte první fetchSize skupina řádků, pak jako rs.next() projde přes ně, nakonec načte další skupinu řádků. To platí i pro setFetchSize(1) což je mimochodem cesta k skutečně získat pouze jeden řádek najednou.
(Všimněte si, že setFetchSize(n) pro n>0 vyžaduje useCursorFetch=true v adrese URL připojení. To zřejmě není vyžadováno pro setFetchSize(Integer.MIN_VALUE) .)