Úvod
Nyní mohou být vaše podmínky shody příliš široké. Ke kontrole slov však můžete použít levenshteinovskou vzdálenost. Splnit s ním všechny požadované cíle nemusí být příliš snadné, jako je zvuková podobnost. Proto navrhuji rozdělit váš problém na několik dalších problémů.
Můžete například vytvořit nějakou vlastní kontrolu, která bude používat předaný volatelný vstup, který vezme dva řetězce a poté zodpoví otázku, zda jsou stejné (pro levenshtein to bude vzdálenost menší než nějaká hodnota pro similar_text - nějaké procento podobnosti atd. - je na vás, jak definujete pravidla).
Podobnost na základě slov
Všechny vestavěné funkce selžou, pokud mluvíme o případu, kdy hledáte částečnou shodu - zejména pokud jde o neuspořádanou shodu. Budete tedy muset vytvořit složitější porovnávací nástroj. Máte:
- Datový řetězec (který bude například v DB). Vypadá to jako D =D0 D1 D2 ... Dn
- Vyhledávací řetězec (který bude zadáním uživatele). Vypadá to jako S =S0 S1 ... Sm
Symboly mezer zde znamenají jakoukoli mezeru (předpokládám, že symboly mezer neovlivní podobnost). Také n > m . S touto definicí se váš problém týká - najít sadu m slova v D který bude podobný S . Podle set Mám na mysli jakoukoli neuspořádanou sekvenci. Pokud tedy najdeme jakou takovou sekvenci v D a poté S je podobný D .
Je zřejmé, že pokud n < m pak vstup obsahuje více slov než datový řetězec. V tomto případě si můžete buď myslet, že si nejsou podobné, nebo se chovat jako výše, ale přepínat data a vstup (to však vypadá trochu divně, ale v určitém smyslu to lze použít)
Implementace
Chcete-li to udělat, musíte být schopni vytvořit sadu řetězců, které jsou částmi z m slova z D . Na základě mé této otázky
můžete to udělat pomocí:
protected function nextAssoc($assoc)
{
if(false !== ($pos = strrpos($assoc, '01')))
{
$assoc[$pos] = '1';
$assoc[$pos+1] = '0';
return substr($assoc, 0, $pos+2).
str_repeat('0', substr_count(substr($assoc, $pos+2), '0')).
str_repeat('1', substr_count(substr($assoc, $pos+2), '1'));
}
return false;
}
protected function getAssoc(array $data, $count=2)
{
if(count($data)<$count)
{
return null;
}
$assoc = str_repeat('0', count($data)-$count).str_repeat('1', $count);
$result = [];
do
{
$result[]=array_intersect_key($data, array_filter(str_split($assoc)));
}
while($assoc=$this->nextAssoc($assoc));
return $result;
}
-takže pro libovolné pole getAssoc() vrátí pole neuspořádaných výběrů skládajících se z m položky každý.
Dalším krokem je pořadí ve vyráběném výběru. Měli bychom prohledat oba Niels Andersen a Andersen Niels v našem D tětiva. Proto budete muset být schopni vytvářet permutace pro pole. Je to velmi častý problém, ale svou verzi dám také sem:
protected function getPermutations(array $input)
{
if(count($input)==1)
{
return [$input];
}
$result = [];
foreach($input as $key=>$element)
{
foreach($this->getPermutations(array_diff_key($input, [$key=>0])) as $subarray)
{
$result[] = array_merge([$element], $subarray);
}
}
return $result;
}
Poté budete moci vytvářet výběry m slova a poté permutací každého z nich získáte všechny varianty pro porovnání s vyhledávacím řetězcem S . Toto srovnání bude pokaždé provedeno pomocí nějakého zpětného volání, jako je levenshtein . Zde je ukázka:
public function checkMatch($search, callable $checker=null, array $args=[], $return=false)
{
$data = preg_split('/\s+/', strtolower($this->data), -1, PREG_SPLIT_NO_EMPTY);
$search = trim(preg_replace('/\s+/', ' ', strtolower($search)));
foreach($this->getAssoc($data, substr_count($search, ' ')+1) as $assoc)
{
foreach($this->getPermutations($assoc) as $ordered)
{
$ordered = join(' ', $ordered);
$result = call_user_func_array($checker, array_merge([$ordered, $search], $args));
if($result<=$this->distance)
{
return $return?$ordered:true;
}
}
}
return $return?null:false;
}
Tím se ověří podobnost na základě zpětného volání uživatele, které musí akceptovat alespoň dva parametry (tj. porovnávané řetězce). Můžete také chtít vrátit řetězec, který spustil kladné zpětné volání. Vezměte prosím na vědomí, že tento kód se nebude lišit velkými a malými písmeny - ale možná si takové chování nepřejete (pak stačí nahradit strtolower() ).
Ukázka úplného kódu je k dispozici v tomto seznamu (Sandbox jsem nepoužil, protože si nejsem jistý, jak dlouho tam bude výpis kódu k dispozici). S tímto příkladem použití:
$data = 'Niels Faurskov Andersen';
$search = [
'Niels Andersen',
'Niels Faurskov',
'Niels Faurskov Andersen',
'Nils Faurskov Andersen',
'Nils Andersen',
'niels faurskov',
'niels Faurskov',
'niffddels Faurskovffre'//I've added this crap
];
$checker = new Similarity($data, 2);
echo(sprintf('Testing "%s"'.PHP_EOL.PHP_EOL, $data));
foreach($search as $name)
{
echo(sprintf(
'Name "%s" has %s'.PHP_EOL,
$name,
($result=$checker->checkMatch($name, 'levenshtein', [], 1))
?sprintf('matched with "%s"', $result)
:'mismatched'
)
);
}
dostanete výsledek jako:
Testing "Niels Faurskov Andersen" Name "Niels Andersen" has matched with "niels andersen" Name "Niels Faurskov" has matched with "niels faurskov" Name "Niels Faurskov Andersen" has matched with "niels faurskov andersen" Name "Nils Faurskov Andersen" has matched with "niels faurskov andersen" Name "Nils Andersen" has matched with "niels andersen" Name "niels faurskov" has matched with "niels faurskov" Name "niels Faurskov" has matched with "niels faurskov" Name "niffddels Faurskovffre" has mismatched
-zde je ukázka tohoto kódu, pro každý případ.
Složitost
Vzhledem k tomu, že se nestaráte o ledajaké metody, ale také o - jak je dobrý, můžete si všimnout, že takový kód bude produkovat poměrně nadměrné operace. Myslím tím alespoň generaci smyčcových partů. Složitost se zde skládá ze dvou částí:
- Část generování částí řetězců. Pokud chcete vygenerovat všechny části řetězce - budete to muset udělat, jak jsem popsal výše. Možný bod ke zlepšení - generování neuspořádaných sad řetězců (které jsou před permutací). Ale stále pochybuji, že to lze provést, protože metoda v poskytnutém kódu je vygeneruje nikoli "hrubou silou", ale tak, jak jsou matematicky vypočteny (s mohutností
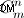 )
) - Část pro kontrolu podobnosti. Zde vaše složitost závisí na daném kontrole podobnosti. Například
similar_text()má O(N) složitost, takže s velkými srovnávacími množinami bude extrémně pomalý.
Stále však můžete vylepšit současné řešení kontrolou za chodu. Nyní tento kód nejprve vygeneruje všechny podsekvence řetězců a poté je začne jednu po druhé kontrolovat. V běžném případě to nemusíte dělat, takže to možná budete chtít nahradit chováním, kdy po vygenerování další sekvence bude okamžitě zkontrolováno. Potom zvýšíte výkon pro řetězce, které mají kladnou odpověď (ale ne pro ty, které nemají žádnou shodu).