Zajímá vás, co jsou schémata Postgresql a proč jsou důležitá a jak můžete schémata použít, aby byly vaše databázové implementace robustnější a udržitelnější? Tento článek představí základy schémat v Postgresql a na několika základních příkladech vám ukáže, jak je vytvořit. Budoucí články se ponoří do příkladů, jak zabezpečit a používat schémata pro skutečné aplikace.
Za prvé, abychom vyjasnili potenciální nejasnosti v terminologii, uvědomme si, že ve světě Postgresql je termín „schéma“ možná poněkud bohužel přetížený. V širším kontextu systémů pro správu relačních databází (RDBMS) lze pojem „schéma“ chápat tak, že odkazuje na celkový logický nebo fyzický návrh databáze, tj. na definici všech tabulek, sloupců, pohledů a dalších objektů. které tvoří definici databáze. V tomto širším kontextu může být schéma vyjádřeno v diagramu vztahu entit (ER) nebo ve skriptu příkazů jazyka definice dat (DDL) používaného k vytvoření instance aplikační databáze.
Ve světě Postgresql může být termín „schéma“ lépe chápán jako „jmenný prostor“. Ve skutečnosti jsou v tabulkách systému Postgresql schémata zaznamenána ve sloupcích tabulky nazývaných „jmenný prostor“, což je IMHO přesnější terminologie. Z praktického hlediska, kdykoli v kontextu Postgresql vidím „schéma“, v tichosti si to vykládám jako „prostor jmen“.
Ale můžete se zeptat:"Co je to jmenný prostor?" Obecně platí, že jmenný prostor je poměrně flexibilním prostředkem pro organizaci a identifikaci informací podle jména. Představte si například dvě sousední domácnosti, Smithové, Alice a Bob a Jones, Bob a Cathy (srov. obrázek 1). Pokud bychom použili pouze křestní jména, mohlo by být matoucí, kterou osobu jsme měli na mysli, když jsme mluvili o Bobovi. Ale přidáním příjmení, Smith nebo Jones, jednoznačně identifikujeme, kterou osobu máme na mysli.
Jmenné prostory jsou často organizovány ve vnořené hierarchii. To umožňuje efektivní klasifikaci obrovského množství informací do velmi jemně zrnité struktury, jako je například systém jmen internetových domén. Na nejvyšší úrovni „.com“, „.net“, „.org“, „.edu“ atd. definují široké jmenné prostory, ve kterých jsou registrované názvy pro konkrétní subjekty, například „severalnines.com“ a „postgresql.org“ jsou jednoznačně definovány. Ale pod každou z nich existuje řada společných subdomén, jako například „www“, „mail“ a „ftp“, které samy o sobě jsou duplicitní, ale v rámci příslušných jmenných prostorů jsou jedinečné.
Schémata Postgresql slouží stejnému účelu organizace a identifikace, avšak na rozdíl od druhého příkladu výše nemohou být schémata Postgresql vnořena do hierarchie. Zatímco databáze může obsahovat mnoho schémat, vždy existuje pouze jedna úroveň, a proto v rámci databáze musí být názvy schémat jedinečné. Každá databáze musí také obsahovat alespoň jedno schéma. Kdykoli je vytvořena instance nové databáze, vytvoří se výchozí schéma s názvem „public“. Obsah schématu zahrnuje všechny ostatní databázové objekty, jako jsou tabulky, pohledy, uložené procedury, spouštěče atd. Pro vizualizaci se podívejte na obrázek 2, který znázorňuje vnoření podobné matrjošce, které ukazuje, kam schémata zapadají do struktury Postgresql databáze.
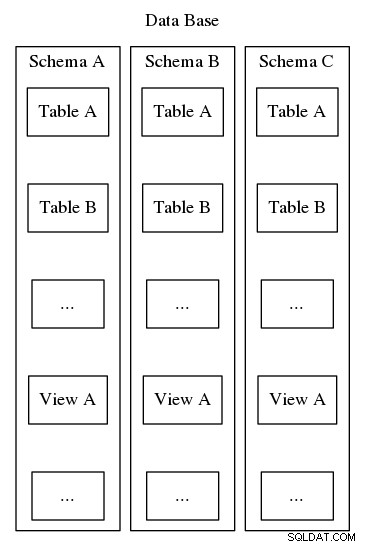
Kromě jednoduchého uspořádání databázových objektů do logických skupin, aby byly lépe ovladatelné, slouží schémata praktickému účelu vyhnout se kolizi názvů. Jedno operační paradigma zahrnuje definování schématu pro každého uživatele databáze tak, aby poskytoval určitý stupeň izolace, prostor, kde mohou uživatelé definovat své vlastní tabulky a pohledy, aniž by se navzájem rušili. Dalším přístupem je instalace nástrojů třetích stran nebo rozšíření databáze do jednotlivých schémat tak, aby všechny související komponenty byly logicky pohromadě. Další článek této série podrobně popíše nový přístup k robustnímu návrhu aplikací, využívající schémata jako prostředek nepřímého přístupu k omezení vystavení fyzickému návrhu databáze a místo toho představuje uživatelské rozhraní, které řeší syntetické klíče a usnadňuje dlouhodobou údržbu a správu konfigurace. jak se vyvíjejí systémové požadavky.
Pojďme udělat nějaký kód!
Stáhněte si Whitepaper Today Správa a automatizace PostgreSQL s ClusterControlZjistěte, co potřebujete vědět k nasazení, monitorování, správě a škálování PostgreSQLStáhněte si WhitepaperNejjednodušší příkaz k vytvoření schématu v databázi je
CREATE SCHEMA hollywood;Tento příkaz vyžaduje oprávnění k vytvoření v databázi a nově vytvořené schéma „hollywood“ bude vlastnit uživatel, který příkaz vyvolá. Složitější vyvolání může zahrnovat volitelné prvky určující jiného vlastníka a může dokonce zahrnovat příkazy DDL vytvářející instanci databázových objektů ve schématu v jednom příkazu!
Obecný formát je
CREATE SCHEMA schemaname [ AUTHORIZATION username ] [ schema_element [ ... ] ]kde „username“ je kdo bude vlastnit schéma a „schema_element“ může být jedním z určitých příkazů DDL (podrobnosti viz dokumentace Postgresql). K použití možnosti AUTORIZACE jsou vyžadována oprávnění superuživatele.
Chcete-li například vytvořit schéma s názvem „hollywood“ obsahující tabulku s názvem „filmy“ a pohled s názvem „winners“ v jednom příkazu, můžete to udělat
CREATE SCHEMA hollywood
CREATE TABLE films (title text, release date, awards text[])
CREATE VIEW winners AS
SELECT title, release FROM films WHERE awards IS NOT NULL;Další databázové objekty mohou být následně vytvořeny přímo, např. další tabulka by byla přidána do schématu pomocí
CREATE TABLE hollywood.actors (name text, dob date, gender text);Všimněte si ve výše uvedeném příkladu předpony názvu tabulky s názvem schématu. To je vyžadováno, protože ve výchozím nastavení, tedy bez explicitní specifikace schématu, jsou nové databázové objekty vytvářeny v rámci jakéhokoli aktuálního schématu, kterému se budeme věnovat dále.
Vzpomeňte si, jak jsme ve výše uvedeném příkladu s křestním prostorem měli dvě osoby jménem Bob a popsali jsme, jak je dekonflikt nebo odlišit přidáním příjmení. Ale v každé domácnosti Smith a Jones zvlášť každá rodina chápe „Bob“ jako odkaz na toho, který patří k této konkrétní domácnosti. Takže například v kontextu každé příslušné domácnosti nemusí Alice oslovovat svého manžela jako Bob Jones a Cathy nemusí svého manžela oslovovat jako Bob Smith:každý může jen říct „Bob“.
Aktuální schéma Postgresql je něco jako domácnost ve výše uvedeném příkladu. Na objekty v aktuálním schématu lze odkazovat nekvalifikovaně, ale odkazování na podobně pojmenované objekty v jiných schématech vyžaduje kvalifikaci názvu uvedením předpony názvu schématu, jak je uvedeno výše.
Aktuální schéma je odvozeno z konfiguračního parametru „search_path“. Tento parametr ukládá čárkami oddělený seznam názvů schémat a lze jej prozkoumat pomocí příkazu
SHOW search_path;nebo nastavte na novou hodnotu pomocí
SET search_path TO schema [, schema, ...];První název schématu v seznamu je „aktuální schéma“ a jsou zde vytvářeny nové objekty, pokud jsou zadány bez kvalifikace názvu schématu.
Čárkami oddělený seznam názvů schémat také slouží k určení pořadí vyhledávání, podle kterého systém vyhledá existující nekvalifikované pojmenované objekty. Například zpět do čtvrti Smith and Jones by zásilka adresovaná pouze „Bobovi“ vyžadovala návštěvu každé domácnosti, dokud nebude nalezen první obyvatel jménem „Bob“. Upozorňujeme, že toto nemusí být zamýšlený příjemce. Stejná logika platí pro Postgresql. Systém vyhledává tabulky, pohledy a další objekty ve schématech v pořadí cesta_hledání, a pak se použije první nalezený objekt odpovídající názvu. Pojmenované objekty kvalifikované pro schéma se používají přímo bez odkazu na cestu hledání.
Ve výchozí konfiguraci dotaz na konfigurační proměnnou search_path odhalí tuto hodnotu
SHOW search_path;
Search_path
--------------
"$user", publicSystém interpretuje první hodnotu uvedenou výše jako aktuálně přihlášené uživatelské jméno a přizpůsobí se výše uvedenému případu použití, kdy je každému uživateli přiděleno schéma pojmenované uživatelem pro pracovní prostor oddělený od ostatních uživatelů. Pokud žádné takové uživatelsky pojmenované schéma nebylo vytvořeno, bude tento záznam ignorován a „veřejné“ schéma se stane aktuálním schématem, kde jsou vytvářeny nové objekty.
Vraťme se tedy k našemu dřívějšímu příkladu vytvoření tabulky „hollywood.actors“, pokud bychom nekvalifikovali název tabulky názvem schématu, tabulka by byla vytvořena ve veřejném schématu. Pokud bychom očekávali vytvoření všech objektů v rámci konkrétního schématu, pak by mohlo být vhodné nastavit proměnnou search_path, například
SET search_path TO hollywood,public;usnadnění zkráceného psaní nekvalifikovaných jmen při vytváření nebo přístupu k databázovým objektům.
K dispozici je také funkce systémových informací, která vrací aktuální schéma s dotazem
select current_schema();V případě překlepů v pravopisu může vlastník schématu změnit název za předpokladu, že uživatel má také oprávnění k vytváření databáze, s
ALTER SCHEMA old_name RENAME TO new_name;A konečně, pro odstranění schématu z databáze existuje příkaz drop
DROP SCHEMA schema_name;Příkaz DROP selže, pokud schéma obsahuje nějaké objekty, takže je třeba je nejprve odstranit, nebo můžete volitelně rekurzivně odstranit celý obsah schématu pomocí možnosti CASCADE
DROP SCHEMA schema_name CASCADE;Tyto základy vám pomohou porozumět schématům!