PostgreSQL je jedna z nejpokročilejších open source databází na světě se spoustou skvělých funkcí. Jedním z nich je Streaming Replication (Physical Replication), který byl představen v PostgreSQL 9.0. Je založen na záznamech XLOG, které se přenesou na cílový server a tam se aplikují. Je však založen na clusteru a nemůžeme provádět replikaci jedné databáze nebo jednoho objektu (selektivní replikace). V průběhu let jsme byli závislí na externích nástrojích jako Slony, Bucardo, BDR atd. pro selektivní nebo částečnou replikaci, protože až do PostgreSQL 9.6 neexistovala žádná funkce na základní úrovni. PostgreSQL 10 však přišel s funkcí nazvanou Logical Replication, jejímž prostřednictvím můžeme provádět replikaci na úrovni databáze/objektu.
Logická replikace replikuje změny objektů na základě jejich replikační identity, což je obvykle primární klíč. Liší se od fyzické replikace, ve které je replikace založena na blocích a replikaci bajt po bajtu. Logická replikace nepotřebuje přesnou binární kopii na straně cílového serveru a na rozdíl od fyzické replikace máme možnost zapisovat na cílový server. Tato funkce pochází z pglogického modulu.
V tomto příspěvku na blogu budeme diskutovat:
- Jak to funguje – Architektura
- Funkce
- Případy použití – kdy je to užitečné
- Omezení
- Jak toho dosáhnout
Jak to funguje – architektura logické replikace
Logická replikace implementuje koncept publikování a odběru (Publication &Subscription). Níže je schéma architektury vyšší úrovně, jak to funguje.
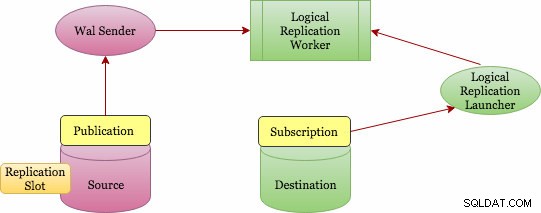
Základní architektura logické replikace
Publikaci lze definovat na hlavním serveru a uzel, na kterém je definována, se nazývá "vydavatel". Publikace je sada změn z jedné tabulky nebo skupiny tabulek. Je na úrovni databáze a každá publikace existuje v jedné databázi. Do jedné publikace lze přidat více tabulek a tabulka může být ve více publikacích. Objekty byste měli do publikace přidávat explicitně, kromě případů, kdy zvolíte možnost "ALL TABLES", která vyžaduje oprávnění superuživatele.
Můžete omezit změny objektů (INSERT, UPDATE a DELETE), které mají být replikovány. Ve výchozím nastavení jsou replikovány všechny typy operací. Musíte mít replikační identitu nakonfigurovanou pro objekt, který chcete přidat do publikace. Toto je za účelem replikace operací UPDATE a DELETE. Identita replikace může být primární klíč nebo jedinečný index. Pokud tabulka nemá primární klíč nebo jedinečný index, lze ji nastavit na repliku identity "full", ve které bere všechny sloupce jako klíč (klíčem se stává celý řádek).
Publikaci můžete vytvořit pomocí CREATE PUBLICATION. Některé praktické příkazy jsou popsány v části „Jak toho dosáhnout“.
Předplatné lze definovat na cílovém serveru a uzel, na kterém je definováno, se nazývá "předplatitel". Připojení ke zdrojové databázi je definováno v předplatném. Předplatitelský uzel je stejný jako jakákoli jiná samostatná postgres databáze a můžete jej také použít jako publikaci pro další předplatné.
Předplatné se přidá pomocí CREATE SUBSCRIPTION a lze jej kdykoli zastavit/obnovit pomocí příkazu ALTER SUBSCRIPTION a odebrat pomocí DROP SUBSCRIPTION.
Po vytvoření předplatného zkopíruje logická replikace snímek dat v databázi vydavatele. Jakmile to uděláte, čeká na rozdílové změny a odešle je do uzlu předplatného, jakmile k nim dojde.
Jak se však změny shromažďují? Kdo je pošle do cíle? A kdo je aplikuje na cíl? Logická replikace je také založena na stejné architektuře jako fyzická replikace. Je implementován procesy „walsender“ a „apply“. Protože je to založeno na dekódování WAL, kdo zahájí dekódování? Proces walsender je zodpovědný za spuštění logického dekódování WAL a načte standardní plugin pro logické dekódování (pgoutput). Plugin transformuje změny načtené z WAL do protokolu logické replikace a filtruje data podle specifikace publikace. Data jsou pak nepřetržitě přenášena pomocí streamingového replikačního protokolu k aplikačnímu pracovníkovi, který mapuje data do místních tabulek a aplikuje jednotlivé změny tak, jak jsou přijímány, ve správném transakčním pořadí.
Při nastavování zaznamenává všechny tyto kroky do souborů protokolu. Zprávy můžeme vidět v části „Jak toho dosáhnout“ později v příspěvku.
Funkce logické replikace
- Logická replikace replikuje datové objekty na základě jejich replikační identity (obecně
- primární klíč nebo jedinečný index).
- Pro zápisy lze použít cílový server. Můžete mít různé indexy a definice zabezpečení.
- Logická replikace podporuje různé verze. Na rozdíl od Streaming Replication lze logickou replikaci nastavit mezi různými verzemi PostgreSQL (> 9.4, i když)
- Logická replikace provádí filtrování založené na událostech
- Ve srovnání má logická replikace menší zesílení zápisu než streamovaná replikace
- Publikace mohou mít několik předplatných
- Logická replikace poskytuje flexibilitu úložiště prostřednictvím replikace menších sad (dokonce i rozdělených tabulek)
- Minimální zatížení serveru ve srovnání s řešeními založenými na spouštěči
- Umožňuje paralelní streamování mezi vydavateli
- Logickou replikaci lze použít pro migrace a upgrady
- Transformaci dat lze provést během nastavování.
Případy použití – Kdy je užitečná logická replikace?
Je velmi důležité vědět, kdy použít logickou replikaci. V opačném případě nezískáte mnoho výhod, pokud váš případ použití nebude odpovídat. Zde jsou některé případy použití, kdy použít logickou replikaci:
- Pokud chcete pro analytické účely sloučit více databází do jedné databáze.
- Pokud je vaším požadavkem replikace dat mezi různými hlavními verzemi PostgreSQL.
- Pokud chcete odeslat přírůstkové změny v jedné databázi nebo podmnožině databáze do jiných databází.
- Pokud poskytujete přístup k replikovaným datům různým skupinám uživatelů.
- Pokud sdílíte podmnožinu databáze mezi více databázemi.
Omezení logické replikace
Logická replikace má určitá omezení, na jejichž překonání komunita neustále pracuje:
- Tabulky musí mít mezi publikováním a předplatným stejný úplný kvalifikovaný název.
- Tabulky musí mít primární klíč nebo jedinečný klíč
- Vzájemná (obousměrná) replikace není podporována
- Nereplikuje schéma/DDL
- Nereplikuje sekvence
- Nereplikuje TRUNCATE
- Nereplikuje velké objekty
- Odběry mohou mít více sloupců nebo různé pořadí sloupců, ale typy a názvy sloupců se musí mezi Publikace a Předplatné shodovat.
- Oprávnění superuživatele přidat všechny tabulky
- Nemůžete streamovat na stejného hostitele (předplatné bude uzamčeno).
Jak dosáhnout logické replikace
Zde jsou kroky k dosažení základní logické replikace. O složitějších scénářích můžeme diskutovat později.
-
Inicializujte dvě různé instance pro publikaci a předplatné a začněte.
C1MQV0FZDTY3:bin bajishaik$ export PATH=$PWD:$PATH C1MQV0FZDTY3:bin bajishaik$ which psql /Users/bajishaik/pg_software/10.2/bin/psql C1MQV0FZDTY3:bin bajishaik$ ./initdb -D /tmp/publication_db C1MQV0FZDTY3:bin bajishaik$ ./initdb -D /tmp/subscription_db -
Parametry, které se mají změnit před spuštěním instancí (pro instance publikace i předplatného).
C1MQV0FZDTY3:bin bajishaik$ tail -3 /tmp/publication_db/postgresql.conf listen_addresses='*' port = 5555 wal_level= logical C1MQV0FZDTY3:bin bajishaik$ pg_ctl -D /tmp/publication_db/ start waiting for server to start....2018-03-21 16:03:30.394 IST [24344] LOG: listening on IPv4 address "0.0.0.0", port 5555 2018-03-21 16:03:30.395 IST [24344] LOG: listening on IPv6 address "::", port 5555 2018-03-21 16:03:30.544 IST [24344] LOG: listening on Unix socket "/tmp/.s.PGSQL.5555" 2018-03-21 16:03:30.662 IST [24345] LOG: database system was shut down at 2018-03-21 16:03:27 IST 2018-03-21 16:03:30.677 IST [24344] LOG: database system is ready to accept connections done server started C1MQV0FZDTY3:bin bajishaik$ tail -3 /tmp/subscription_db/postgresql.conf listen_addresses='*' port=5556 wal_level=logical C1MQV0FZDTY3:bin bajishaik$ pg_ctl -D /tmp/subscription_db/ start waiting for server to start....2018-03-21 16:05:28.408 IST [24387] LOG: listening on IPv4 address "0.0.0.0", port 5556 2018-03-21 16:05:28.408 IST [24387] LOG: listening on IPv6 address "::", port 5556 2018-03-21 16:05:28.410 IST [24387] LOG: listening on Unix socket "/tmp/.s.PGSQL.5556" 2018-03-21 16:05:28.460 IST [24388] LOG: database system was shut down at 2018-03-21 15:59:32 IST 2018-03-21 16:05:28.512 IST [24387] LOG: database system is ready to accept connections done server startedOstatní parametry mohou být výchozí pro základní nastavení.
-
Změňte soubor pg_hba.conf tak, aby umožňoval replikaci. Všimněte si, že tyto hodnoty jsou závislé na vašem prostředí, nicméně toto je pouze základní příklad (pro instance publikace i předplatného).
C1MQV0FZDTY3:bin bajishaik$ tail -1 /tmp/publication_db/pg_hba.conf host all repuser 0.0.0.0/0 md5 C1MQV0FZDTY3:bin bajishaik$ tail -1 /tmp/subscription_db/pg_hba.conf host all repuser 0.0.0.0/0 md5 C1MQV0FZDTY3:bin bajishaik$ psql -p 5555 -U bajishaik -c "select pg_reload_conf()" Timing is on. Pager usage is off. 2018-03-21 16:08:19.271 IST [24344] LOG: received SIGHUP, reloading configuration files pg_reload_conf ---------------- t (1 row) Time: 16.103 ms C1MQV0FZDTY3:bin bajishaik$ psql -p 5556 -U bajishaik -c "select pg_reload_conf()" Timing is on. Pager usage is off. 2018-03-21 16:08:29.929 IST [24387] LOG: received SIGHUP, reloading configuration files pg_reload_conf ---------------- t (1 row) Time: 53.542 ms C1MQV0FZDTY3:bin bajishaik$ -
Vytvořte několik testovacích tabulek pro replikaci a vložte některá data do instance publikace.
postgres=# create database source_rep; CREATE DATABASE Time: 662.342 ms postgres=# \c source_rep You are now connected to database "source_rep" as user "bajishaik". source_rep=# create table test_rep(id int primary key, name varchar); CREATE TABLE Time: 63.706 ms source_rep=# create table test_rep_other(id int primary key, name varchar); CREATE TABLE Time: 65.187 ms source_rep=# insert into test_rep values(generate_series(1,100),'data'||generate_series(1,100)); INSERT 0 100 Time: 2.679 ms source_rep=# insert into test_rep_other values(generate_series(1,100),'data'||generate_series(1,100)); INSERT 0 100 Time: 1.848 ms source_rep=# select count(1) from test_rep; count ------- 100 (1 row) Time: 0.513 ms source_rep=# select count(1) from test_rep_other ; count ------- 100 (1 row) Time: 0.488 ms source_rep=# -
Vytvořte strukturu tabulek na instanci Subscription, protože logická replikace nereplikuje strukturu.
postgres=# create database target_rep; CREATE DATABASE Time: 514.308 ms postgres=# \c target_rep You are now connected to database "target_rep" as user "bajishaik". target_rep=# create table test_rep_other(id int primary key, name varchar); CREATE TABLE Time: 9.684 ms target_rep=# create table test_rep(id int primary key, name varchar); CREATE TABLE Time: 5.374 ms target_rep=# -
Vytvořte publikaci v instanci publikace (port 5555).
source_rep=# CREATE PUBLICATION mypub FOR TABLE test_rep, test_rep_other; CREATE PUBLICATION Time: 3.840 ms source_rep=# -
Vytvořte předplatné na instanci Suscription (port 5556) pro publikaci vytvořenou v kroku 6.
target_rep=# CREATE SUBSCRIPTION mysub CONNECTION 'dbname=source_rep host=localhost user=bajishaik port=5555' PUBLICATION mypub; NOTICE: created replication slot "mysub" on publisher CREATE SUBSCRIPTION Time: 81.729 msZ protokolu:
2018-03-21 16:16:42.200 IST [24617] LOG: logical decoding found consistent point at 0/1616D80 2018-03-21 16:16:42.200 IST [24617] DETAIL: There are no running transactions. target_rep=# 2018-03-21 16:16:42.207 IST [24618] LOG: logical replication apply worker for subscription "mysub" has started 2018-03-21 16:16:42.217 IST [24619] LOG: starting logical decoding for slot "mysub" 2018-03-21 16:16:42.217 IST [24619] DETAIL: streaming transactions committing after 0/1616DB8, reading WAL from 0/1616D80 2018-03-21 16:16:42.217 IST [24619] LOG: logical decoding found consistent point at 0/1616D80 2018-03-21 16:16:42.217 IST [24619] DETAIL: There are no running transactions. 2018-03-21 16:16:42.219 IST [24620] LOG: logical replication table synchronization worker for subscription "mysub", table "test_rep" has started 2018-03-21 16:16:42.231 IST [24622] LOG: logical replication table synchronization worker for subscription "mysub", table "test_rep_other" has started 2018-03-21 16:16:42.260 IST [24621] LOG: logical decoding found consistent point at 0/1616DB8 2018-03-21 16:16:42.260 IST [24621] DETAIL: There are no running transactions. 2018-03-21 16:16:42.267 IST [24623] LOG: logical decoding found consistent point at 0/1616DF0 2018-03-21 16:16:42.267 IST [24623] DETAIL: There are no running transactions. 2018-03-21 16:16:42.304 IST [24621] LOG: starting logical decoding for slot "mysub_16403_sync_16393" 2018-03-21 16:16:42.304 IST [24621] DETAIL: streaming transactions committing after 0/1616DF0, reading WAL from 0/1616DB8 2018-03-21 16:16:42.304 IST [24621] LOG: logical decoding found consistent point at 0/1616DB8 2018-03-21 16:16:42.304 IST [24621] DETAIL: There are no running transactions. 2018-03-21 16:16:42.306 IST [24620] LOG: logical replication table synchronization worker for subscription "mysub", table "test_rep" has finished 2018-03-21 16:16:42.308 IST [24622] LOG: logical replication table synchronization worker for subscription "mysub", table "test_rep_other" has finishedJak můžete vidět ve zprávě NOTICE, vytvořila replikační slot, který zajišťuje, že vyčištění WAL by nemělo být provedeno, dokud nebudou do cílové databáze přeneseny počáteční snímky nebo rozdílové změny. Poté odesílatel WAL začal dekódovat změny a aplikace logické replikace fungovala, když byly spuštěny pub i sub. Poté se spustí synchronizace tabulky.
-
Ověřte data v instanci Subscription.
target_rep=# select count(1) from test_rep; count ------- 100 (1 row) Time: 0.927 ms target_rep=# select count(1) from test_rep_other ; count ------- 100 (1 row) Time: 0.767 ms target_rep=#Jak vidíte, data byla replikována prostřednictvím počátečního snímku.
-
Ověřte rozdílové změny.
C1MQV0FZDTY3:bin bajishaik$ psql -d postgres -p 5555 -d source_rep -c "insert into test_rep values(generate_series(101,200), 'data'||generate_series(101,200))" INSERT 0 100 Time: 3.869 ms C1MQV0FZDTY3:bin bajishaik$ psql -d postgres -p 5555 -d source_rep -c "insert into test_rep_other values(generate_series(101,200), 'data'||generate_series(101,200))" INSERT 0 100 Time: 3.211 ms C1MQV0FZDTY3:bin bajishaik$ psql -d postgres -p 5556 -d target_rep -c "select count(1) from test_rep" count ------- 200 (1 row) Time: 1.742 ms C1MQV0FZDTY3:bin bajishaik$ psql -d postgres -p 5556 -d target_rep -c "select count(1) from test_rep_other" count ------- 200 (1 row) Time: 1.480 ms C1MQV0FZDTY3:bin bajishaik$
Toto jsou kroky pro základní nastavení logické replikace.