V rámci svého podnikového monitorovacího systému spoléhají organizace na výstrahy a oznámení jako na svou první obrannou linii k dosažení vysoké dostupnosti a následně ke snížení nákladů na výpadky.
Upozornění a upozornění se někdy používají zaměnitelně, například můžeme říci „Obdržel jsem upozornění na vysoké zatížení systému“ a nahrazení „upozornění“ za „upozornění“ nezmění význam zprávy. Ve světě systémů pro správu je však důležité poznamenat rozdíl:výstrahy jsou události generované v důsledku systémové poruchy a oznámení se používají k doručení informací o stavu systému, včetně problémů. Například blog Somenines Introducing the ClusterControl Alerting Integrations pojednává o jedné z integračních funkcí ClusterControl, o oznamovacím systému, který je schopen doručovat výstrahy prostřednictvím e-mailu, chatovacích služeb a systémů správy incidentů. Viz také PostgreSQL Wiki — Alerts and Status Notifications.
Aby bylo možné přesně monitorovat aktivitu databáze PostgreSQL, spoléhá systém správy na metriky aktivity databáze, vlastní funkce nebo poradce monitorování a soubory protokolu monitorování.
V tomto článku přezkoumám nástroje uvedené na PostgreSQL Wiki, sekce Monitoring a PostgreSQL GUI, přičemž vynechám ty, které nejsou aktivně udržovány nebo neposkytují upozornění a upozornění buď v rámci produktu, nebo pomocí bezplatného zkušebního účtu. I když to není vyčerpávající přehled, každý nástroj byl nainstalován a nakonfigurován až do bodu, kdy jsem pochopil jeho možnosti upozornění a upozornění.
Nagios
Nagios je populární on-premise obecný monitorovací systém, který nabízí širokou škálu pluginů. Zatímco Nagios Core je open source, doporučeným řešením pro monitorování PostgreSQL je Nagios XI.
Nastavení oznámení platí pro každého uživatele a aby je mohl změnit, musí se administrátor „přihlásit jako“ uživatel — Nagios používá výraz maškaráda . Jakmile se uživatel dostane na stránku nastavení účtu, může povolit nebo zakázat způsoby upozornění:
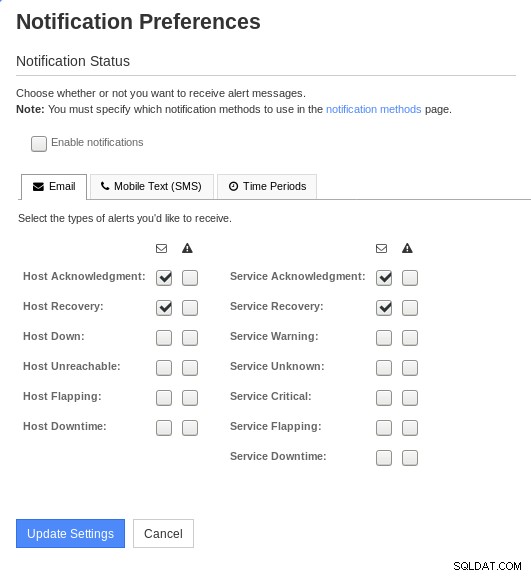 Předvolby oznámení Nagios XI
Předvolby oznámení Nagios XI Chcete-li nakonfigurovat typy oznámení, přejděte na stránku „Metody oznámení“:
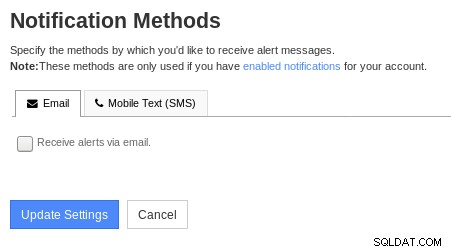 Metody oznámení Nagios XI
Metody oznámení Nagios XI Další podrobnosti naleznete v uživatelské příručce Nagios XI.
Chcete-li nakonfigurovat výstrahy, přihlaste se jako správce a vyberte průvodce konfigurací databáze:
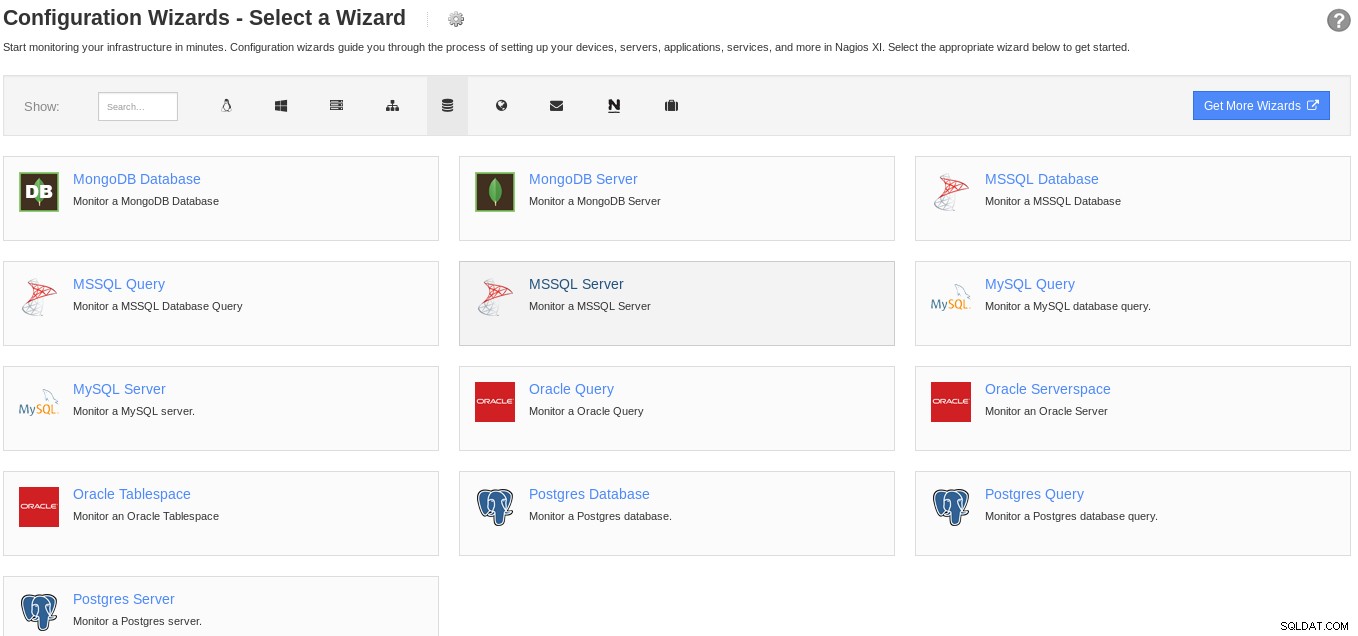 Průvodce konfigurací databáze Nagios XI
Průvodce konfigurací databáze Nagios XI Po nakonfigurování lze výstrahy zobrazit výběrem libovolného z výchozích zobrazení, panelů nebo můžeme nakonfigurovat vlastní. Nagios XI poskytuje následující monitory PostgreSQL:
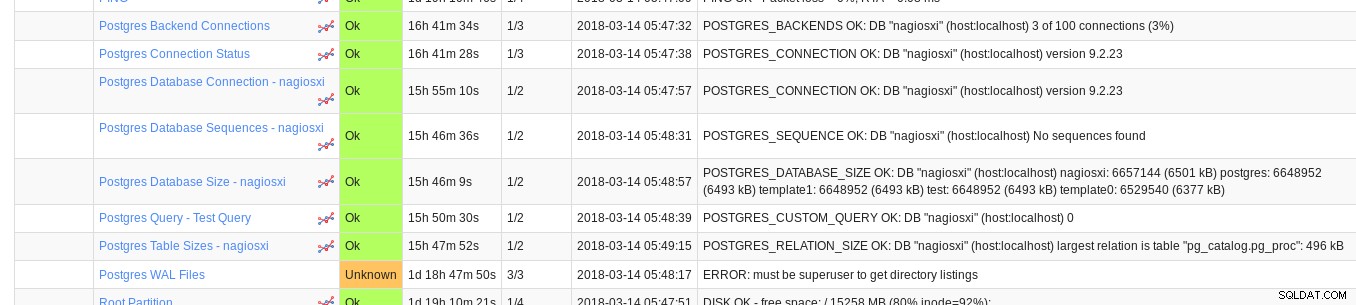 Nagios XI PostgreSQL monitory
Nagios XI PostgreSQL monitory Všimněte si, že Nagios XI po vybalení nenabízí žádné metriky založené na sběrači statistik PostgreSQL, místo toho musí být každá metrika definována pomocí konfiguračního průvodce „Postgres Query“:
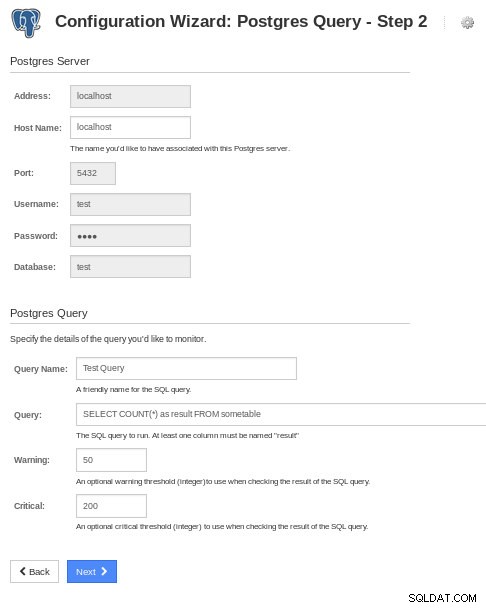 Nagios XI Postgres Query
Nagios XI Postgres Query Datový pes
Datadog je univerzální nástroj pro monitorování SaaS, který obsahuje velmi rozsáhlou sadu integrací s různými službami. Chcete-li zahájit monitorování, vyberte integraci PostgreSQL a poté vyberte integrace oznámení, jako je e-mail, chat (např. Slack) nebo systémy odezvy na incidenty, jako je PagerDuty:
 Integrace Datadog
Integrace Datadog Abychom mohli přijímat upozornění prostřednictvím dříve nakonfigurovaných integračních kanálů, musíme vytvořit alespoň jeden monitor Datadog, v případě sledování PostgreSQL typ monitoru „integrace“:
 Integrace Datadog PostgreSQL
Integrace Datadog PostgreSQL Prvním krokem při konfiguraci monitoru je výběr typu výstrahy:
 Metoda detekce Datadog
Metoda detekce Datadog Dále nakonfigurujte jednu nebo více metrik:
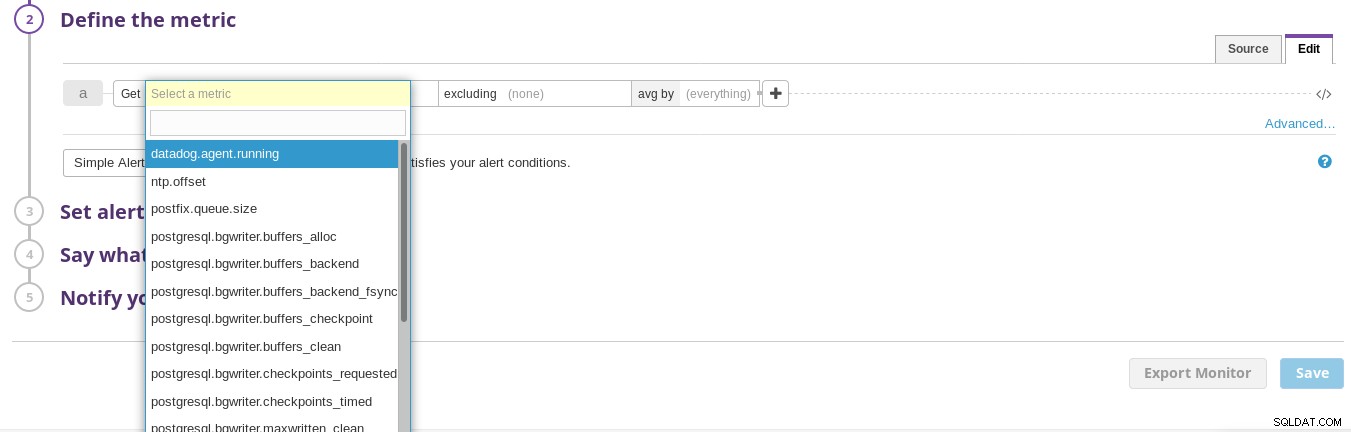 Konfigurace metrik datadoru
Konfigurace metrik datadoru Nakonfigurujte podmínky pro spuštění výstrahy:
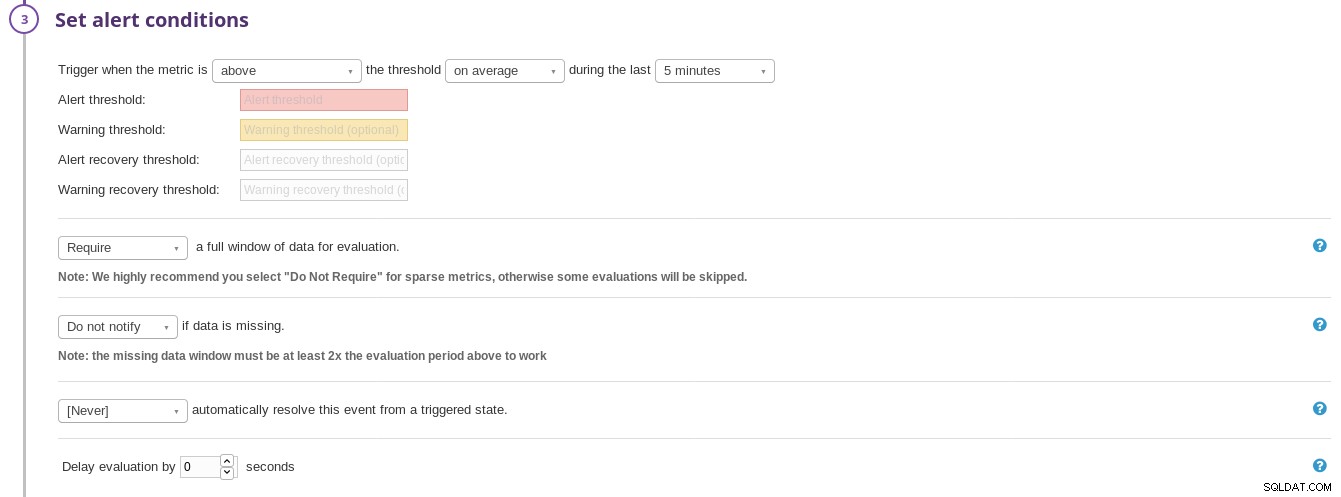 Spouštěč upozornění Datadog
Spouštěč upozornění Datadog Oznámení lze přizpůsobit pomocí proměnných šablony:
 Integrace Datadog Postgres
Integrace Datadog Postgres Nakonec uveďte seznam příjemců, kteří mají dostávat oznámení:
 Příjemci oznámení Datadog
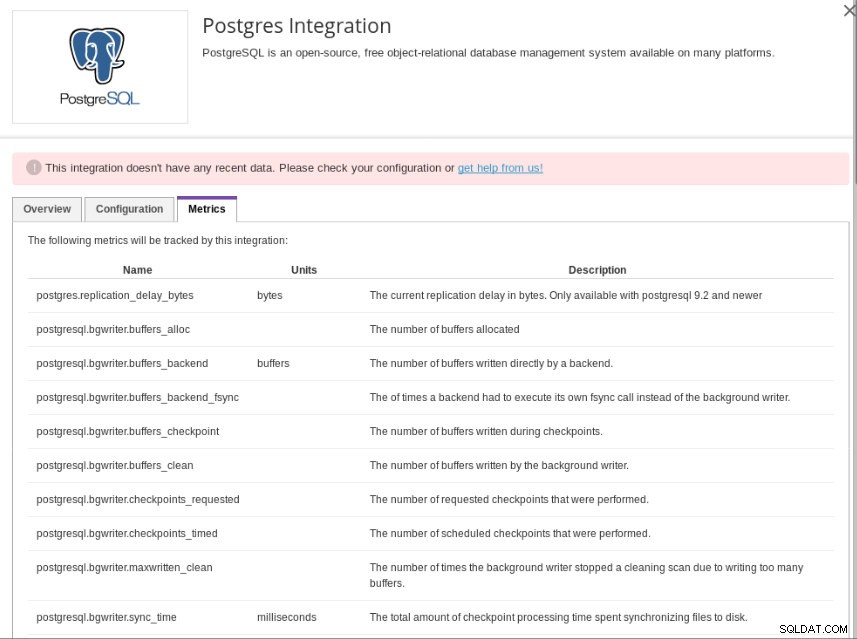
Příjemci oznámení Datadog Události, které může Datadog monitorovat, jsou uvedeny v části „Metriky“ integrace PostgreSQL a jsou založeny na předdefinovaných pohledech PostgreSQL Statistics Collector:
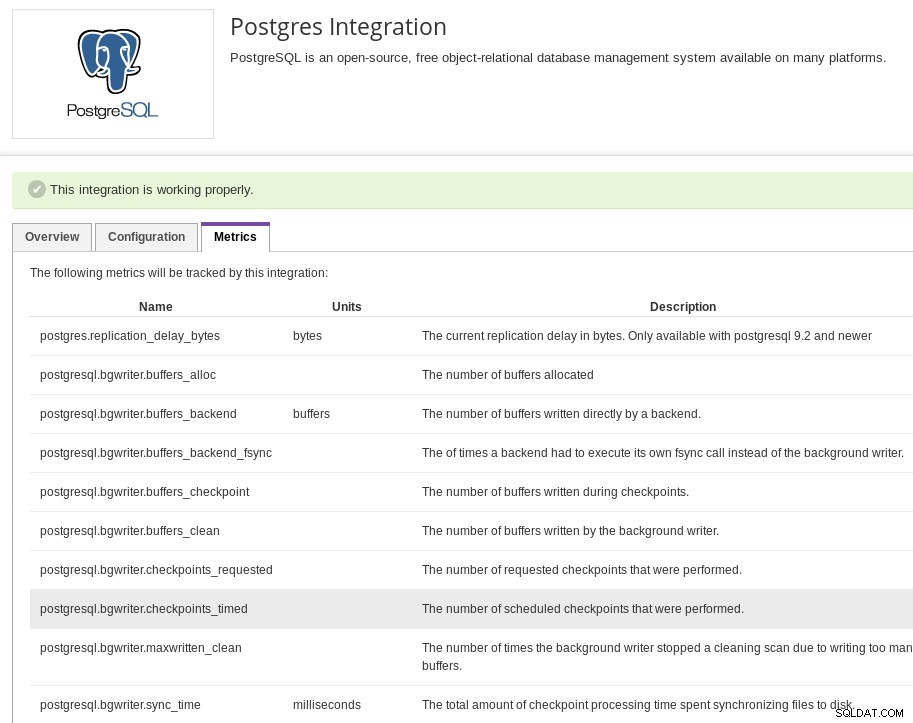 Metriky integrace Datadog Postgres
Metriky integrace Datadog Postgres Aby bylo možné sledovat události, které nejsou poskytovány s výchozí integrací, poskytuje Datadog zákazníkům možnost vytvářet vlastní metriky omezené na plán Datadog.
Okmetr
Okmeter je také součástí rodiny monitorování SaaS pro obecné účely a stejně jako ostatní nástroje SaaS vyžaduje agenta na monitorovaném hostiteli. Jakmile je agent nainstalován, je povolena sada výchozích spouštěčů událostí, včetně kontroly připojení PostgreSQL:
 Automatické spouštění okmetru
Automatické spouštění okmetru Získání dalších metrik PostgreSQL vyžaduje přidání PostgreSQL „serveru“:
 Okmeter – Přidání serveru
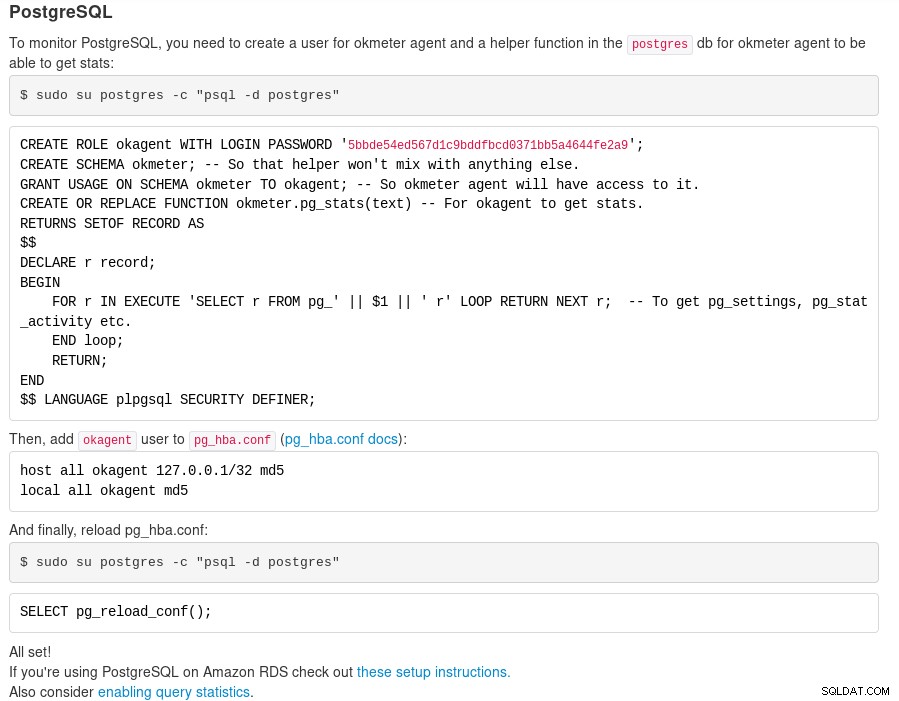
Okmeter – Přidání serveru Abychom mohli sledovat statistiky PostgreSQL, podobně jako u Nagios a Datadog, musíme nakonfigurovat vlastní metriky, jak je vysvětleno v Okmeter Documentation — Sending Custom metrics. Nebo upravte metriku „PostgreSQL server“ výše tak, aby byla zahrnuta pro zobrazení ve funkci „okmeter.pg_stats“.
Stránka dokumentace statistik dotazů Okmeter vysvětluje, jak povolit sledování statistik provádění pro příkazy SQL. Všimněte si, že při používání pohledů „pg_stat_statements“ existuje několik omezení, např. maximální počet odlišných příkazů, které může modul zaznamenat — podrobnosti najdete v dokumentaci PostgreSQL na pg_stat_statements.
Na stránce s kontakty oznámení se konfigurují oznámení pro každého uživatele:
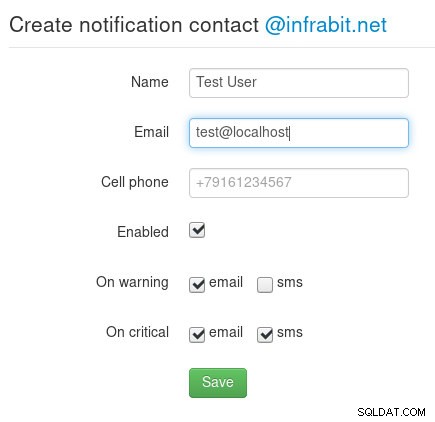 Oznámení kontaktu Okmeter
Oznámení kontaktu Okmeter Notifikační zprávy lze dále upravit pomocí šablon:
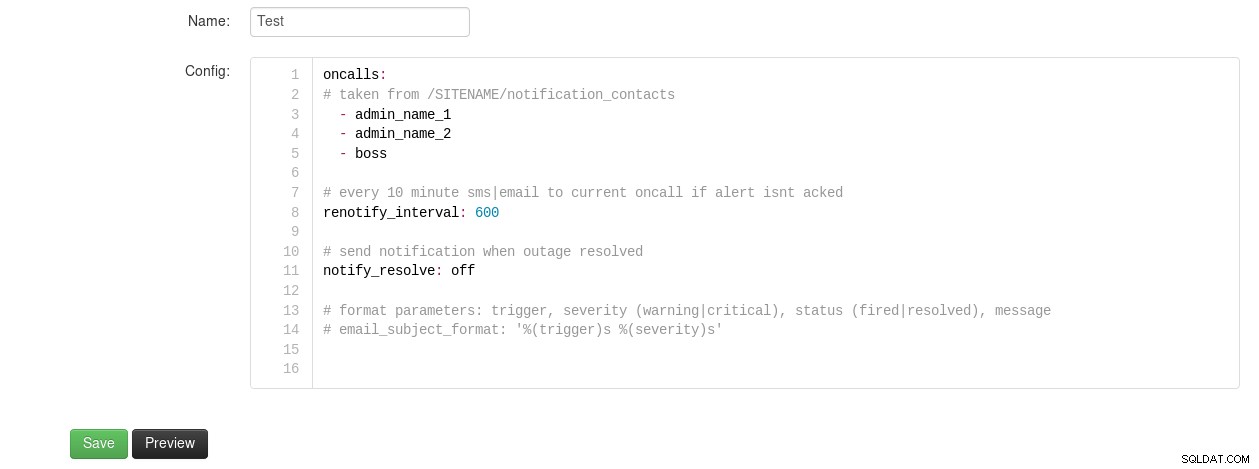 Šablona oznámení Okmeter
Šablona oznámení Okmeter Cirkonus
Circonus, další obecný monitorovací produkt SaaS, obsahuje „kontrolu“ PostgreSQL, kterou lze povolit jednotlivě nebo přidat jako součást instalace v jednom kroku:
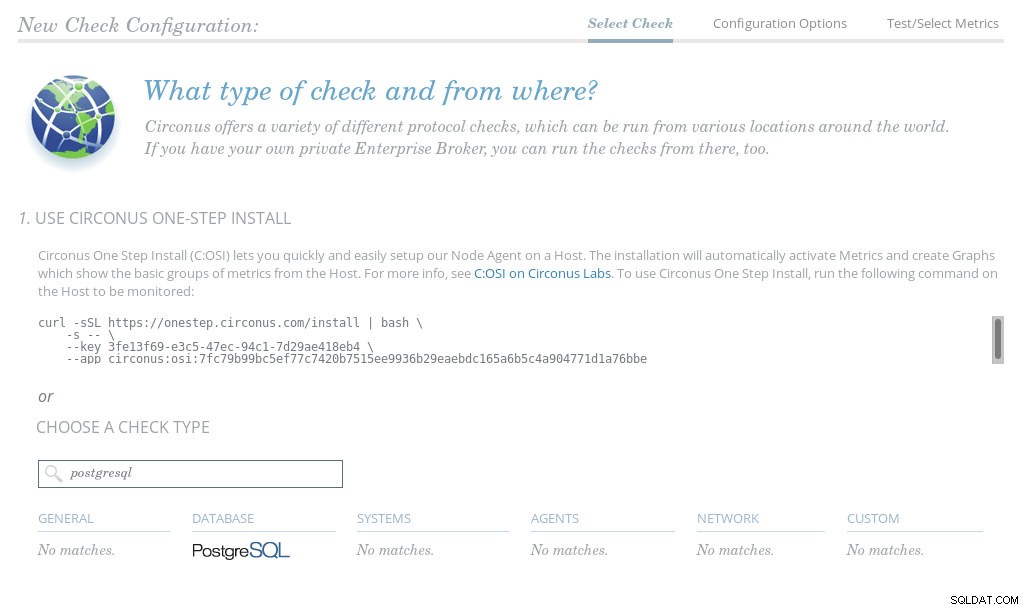 Nastavení Circonus Check
Nastavení Circonus Check Podle dokumentace Circonus PostgreSQL se kontrola provádí ze vzdáleného místa pomocí přímých příkazů SQL. Po konfiguraci hostitele PostgreSQL tak, aby přijímal připojení od brokera Circonus, průvodce nabídne seznam dostupných metrik:
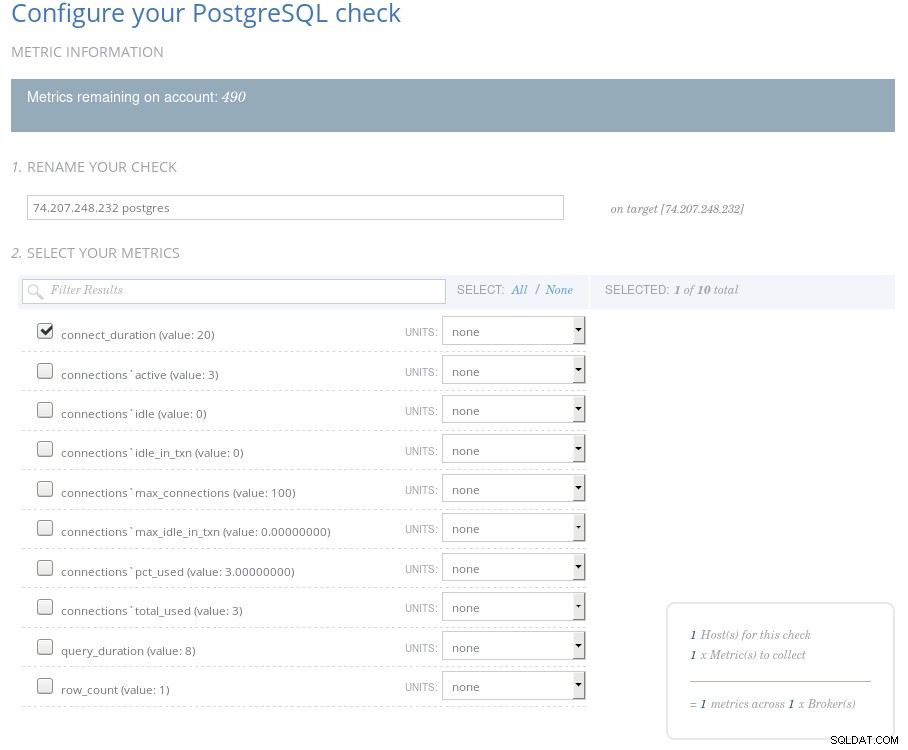 Kontrola Circonus PostgreSQL
Kontrola Circonus PostgreSQL Aby bylo možné konfigurovat upozornění, je každá metrika spojena se sadou pravidel a seznamem kontaktů, které mají být upozorněny.
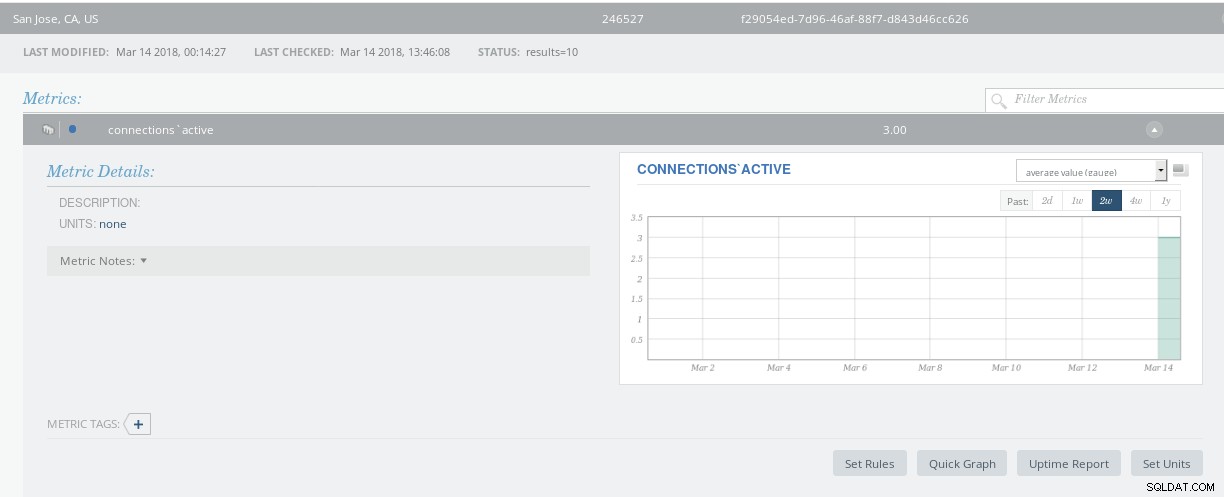 Podrobnosti metriky Circonus
Podrobnosti metriky Circonus Upozornění jsou kategorizována podle úrovní závažnosti:
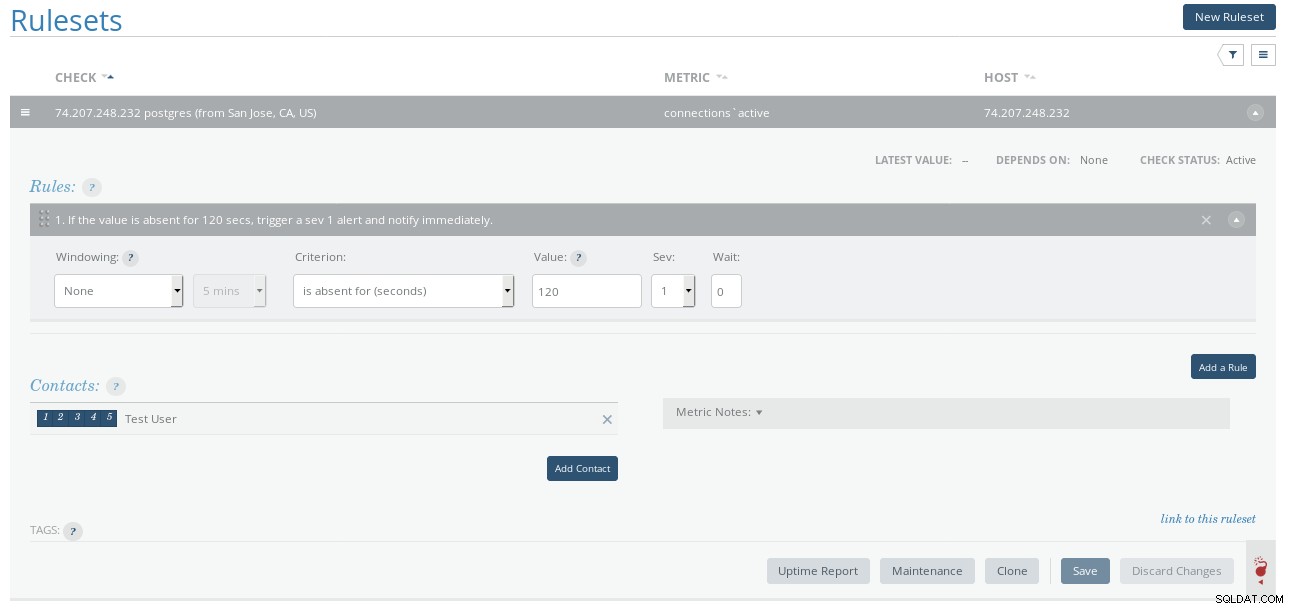 Úrovně závažnosti pravidel Circonus
Úrovně závažnosti pravidel Circonus Mezi kanály oznámení patří SMS, OpsGenie, Slack, VictorOps a PagerDuty (žádný e-mail). Níže uvedený snímek obrazovky ukazuje integraci Slack:
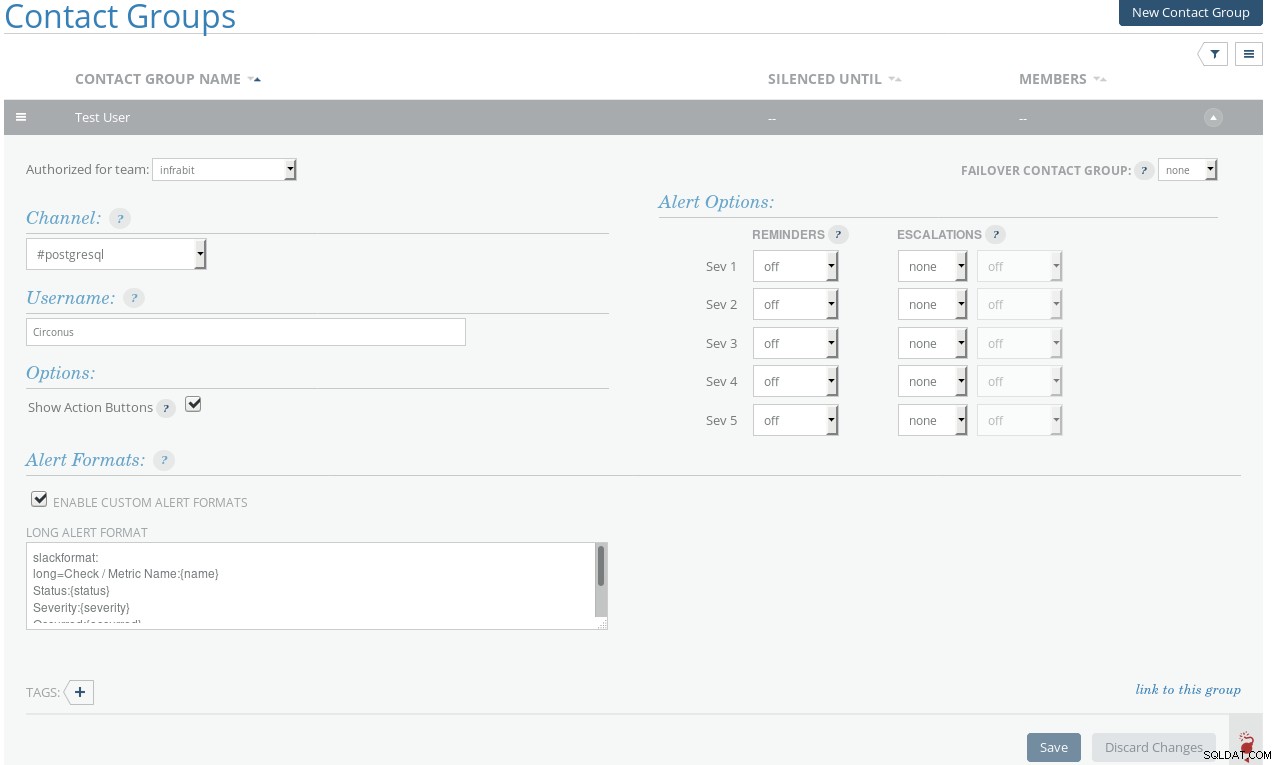 Skupiny kontaktů Circonus
Skupiny kontaktů Circonus Aby bylo možné konfigurovat oznámení, musí mít každá metrika v kontrole přiřazena pravidla a kontakty. Upozorňujeme, že kontakty je nutné vytvořit před úpravou metriky:
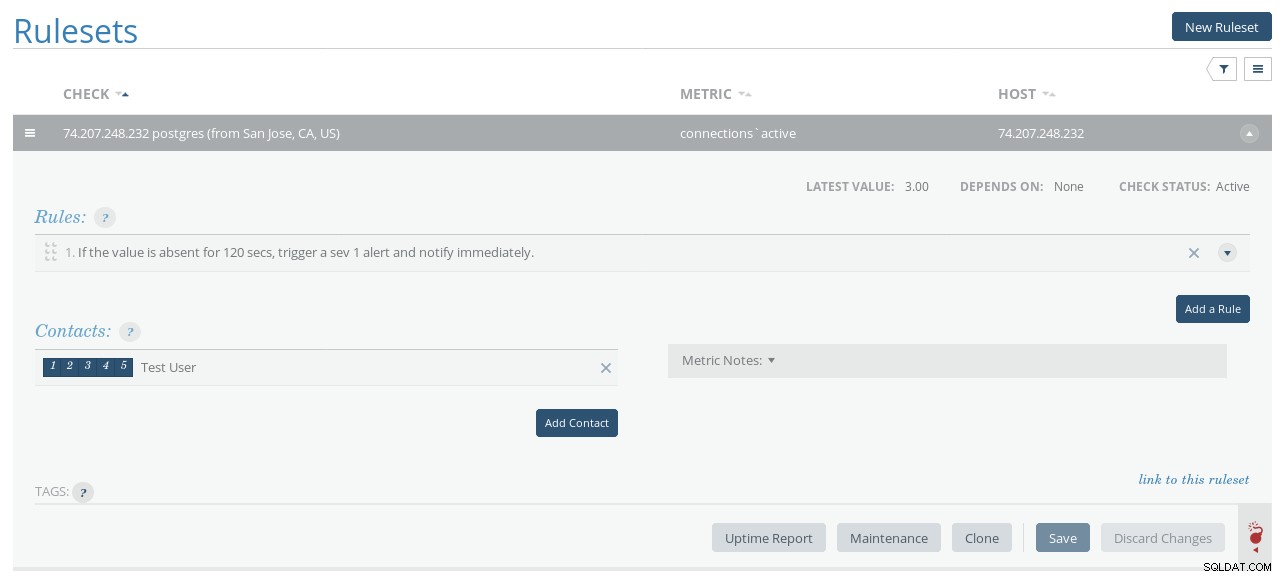 Sady pravidel Circonus
Sady pravidel Circonus Nová relikvie
New Relic je další obecný monitorovací systém SaaS. Pokud jde o PostgreSQL, existují (v době psaní tohoto článku) tři dostupné pluginy. Nejnovější je plugin Blue Medora:
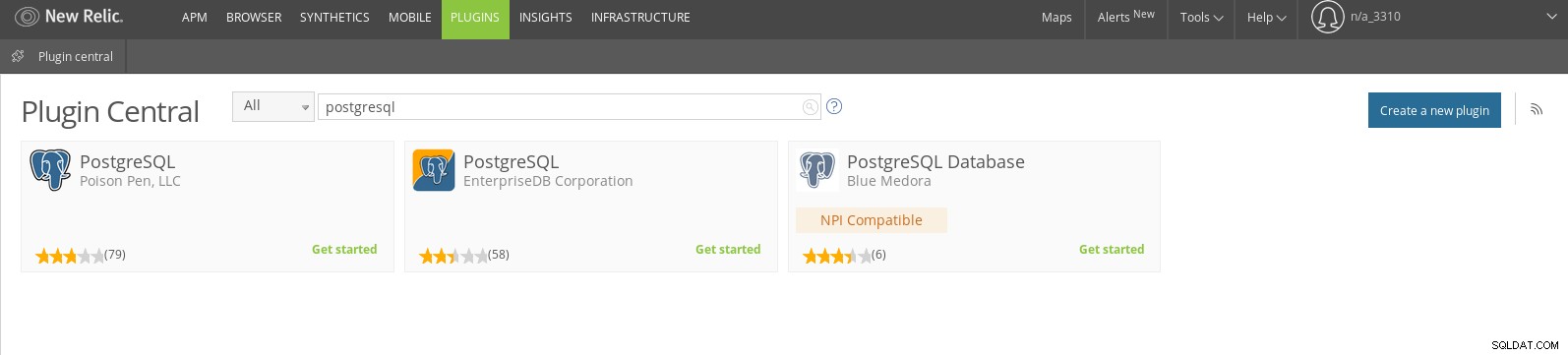 Nový plugin Relic PostgreSQL od Blue Medora
Nový plugin Relic PostgreSQL od Blue Medora Jakmile plugin funguje, bude viditelný na stránce pluginů a jsme připraveni nakonfigurovat upozornění:
 Nové nastavení upozornění na památky
Nové nastavení upozornění na památky New Relic využívá koncept zásad výstrah k seskupování výstrah do incidentů. Před konfigurací zásady musíme nastavit kanály oznámení. Po vybalení se New Relic integruje se všemi oblíbenými systémy reakce na incidenty a také s e-mailem:
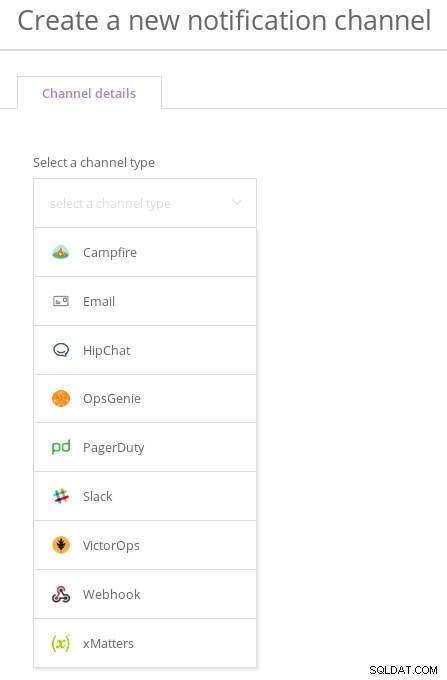 Nové typy kanálů Relic
Nové typy kanálů Relic Všimněte si, že integrace musí být nejprve povolena v oznamovací aplikaci. Například výběrem Slack ze seznamu typů kanálů:
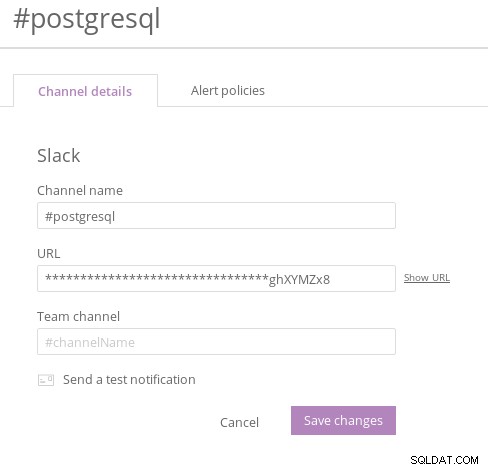 Nová integrace Relic Slack
Nová integrace Relic Slack Dále vytvořte „zásadu výstrah“:
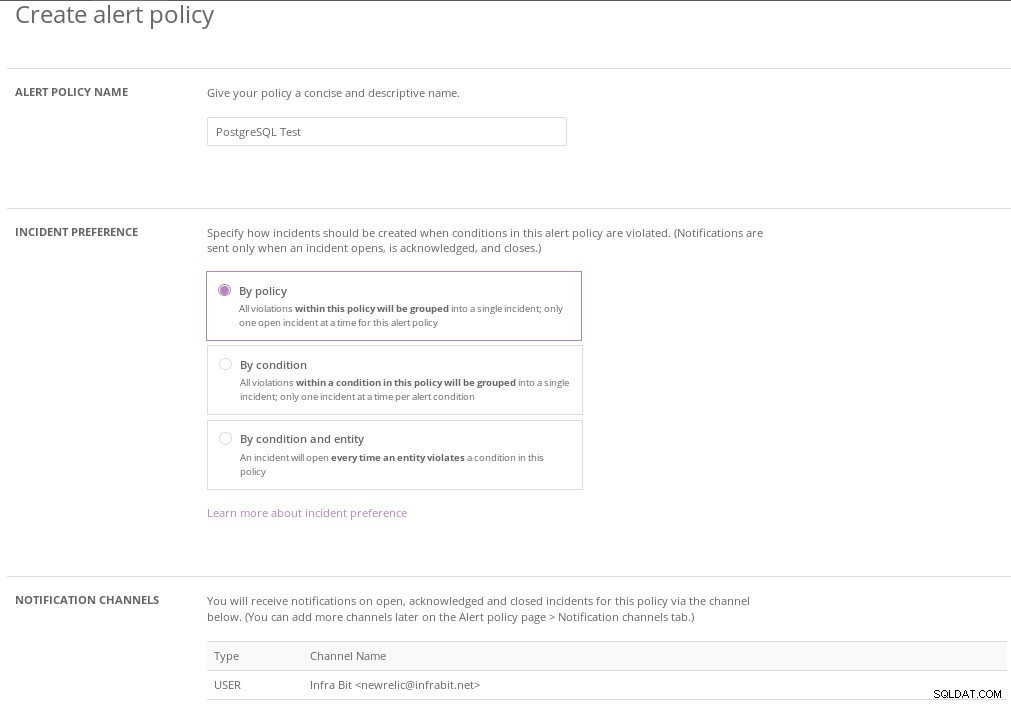 Nové zásady upozornění na památky
Nové zásady upozornění na památky Zásada výstrahy vyžaduje „podmínku výstrahy“. Další sada snímků obrazovky ukazuje kroky, jak toho dosáhnout:
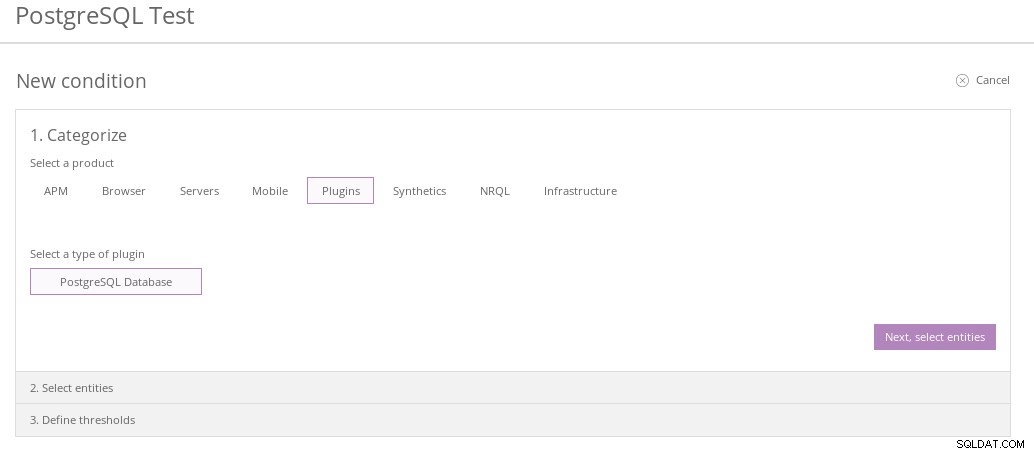 Nová kategorie podmínek PostgreSQL
Nová kategorie podmínek PostgreSQL 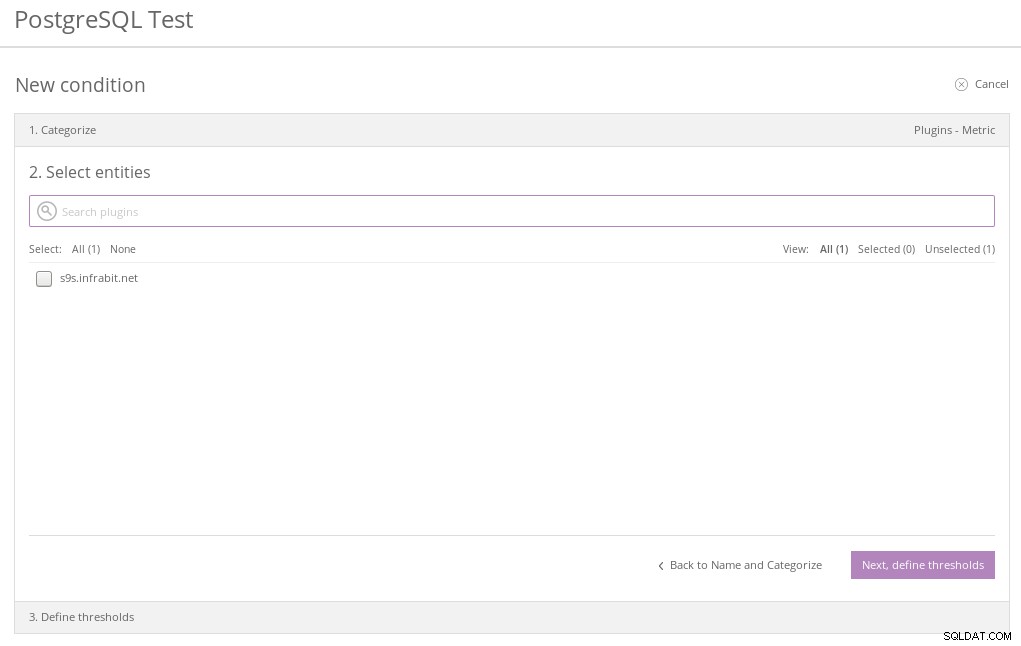 Nová entita Relic PostgreSQL Condition
Nová entita Relic PostgreSQL Condition 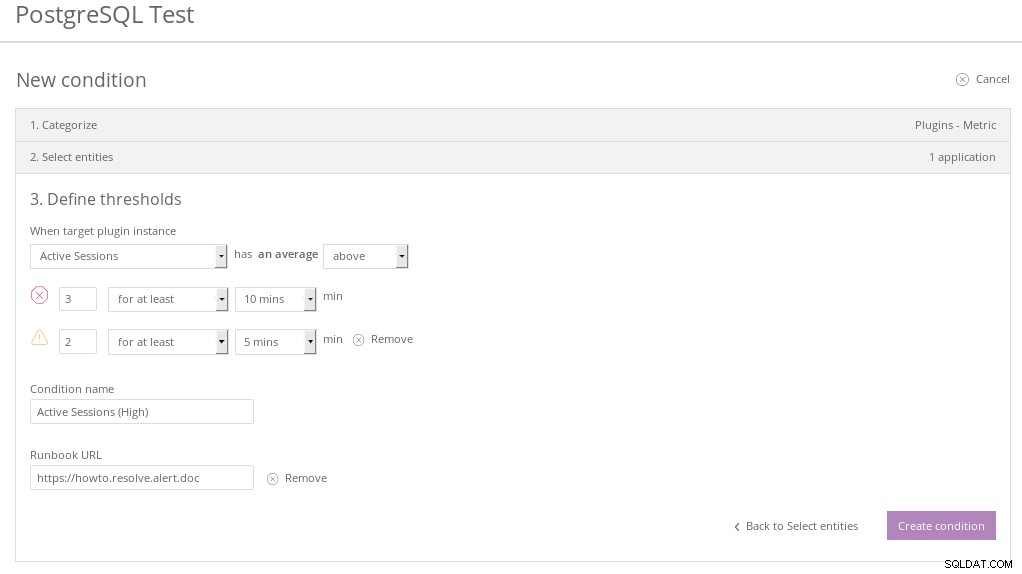 New Relic PostgreSQL Condition Threshold
New Relic PostgreSQL Condition Threshold Nakonec vyberte kartu oznamovacích kanálů, abyste mohli upravit výchozí:
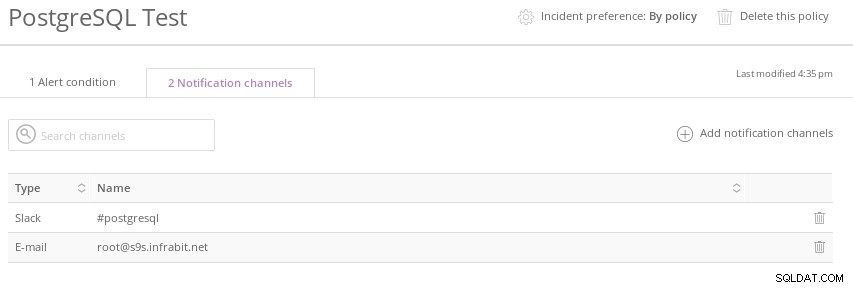 Nové oznamovací kanály Relic PostgreSQL
Nové oznamovací kanály Relic PostgreSQL Volitelně přidejte podmínku výstrahy do New Relic Insights (vyžaduje další předplatné):
 New Relic Insights
New Relic Insights Postgres Enterprise Manager
PEM nebo Postgres Enterprise Manager je nástroj pro správu, ladění a monitorování PostgreSQL.
Dodává se s velmi bohatou sadou předdefinovaných metrik:
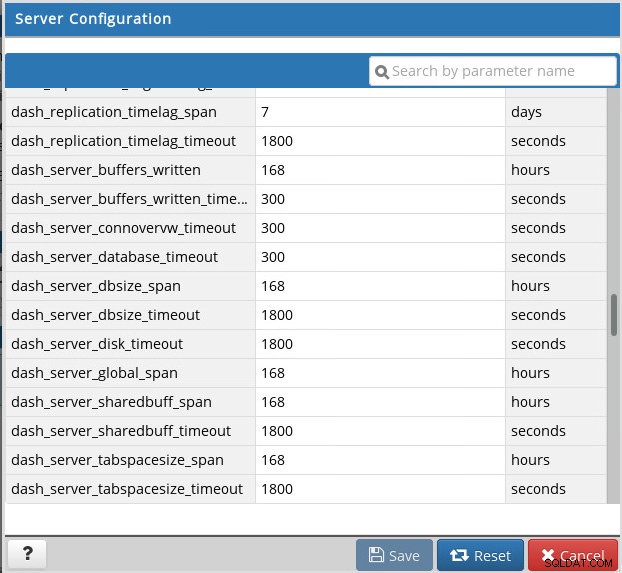 Předdefinované metriky Postgres Enterprise Manager
Předdefinované metriky Postgres Enterprise Manager Chcete-li upravit výchozí výstrahy nebo vytvořit vlastní výstrahy, použijte šablony výstrah:
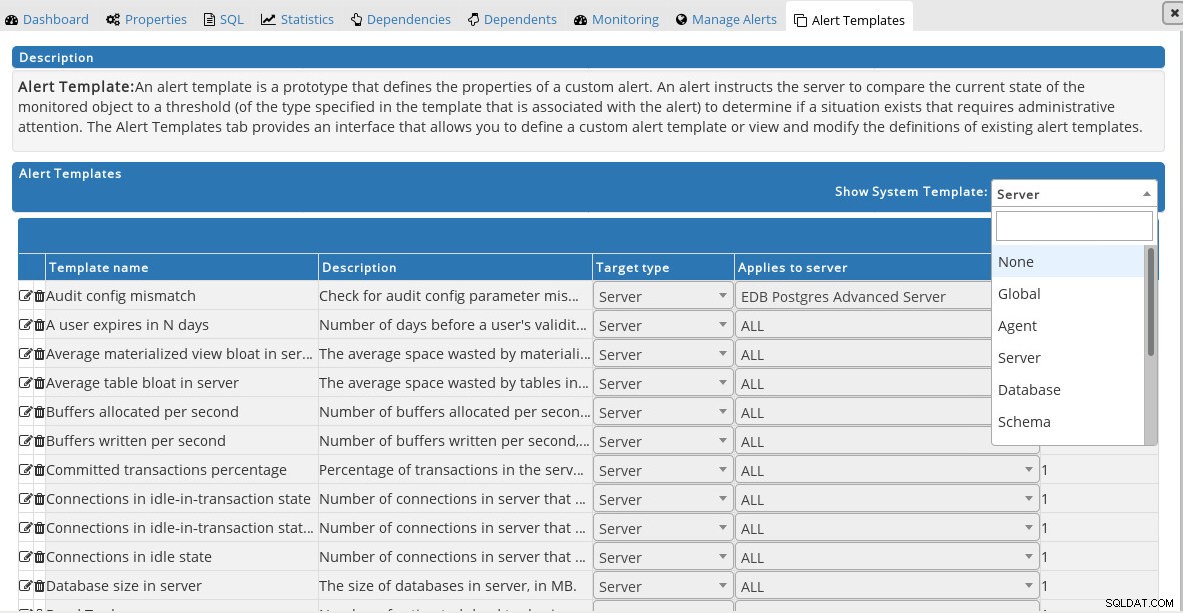 Šablona vlastní výstrahy Postgres Enterprise Manager
Šablona vlastní výstrahy Postgres Enterprise Manager PEM se při upozorňování spoléhá na e-mail a SNMP, takže jej lze snadno integrovat s monitorovacími systémy, jako je Nagios, ale neexistují žádné integrace s oblíbenými systémy správy incidentů (PagerDuty, VictorOps, OpsGenie) nebo chatovacími službami (Slack), které lze nalézt v ostatní produkty.
 E-mailová a SNMP upozornění Postgres Enterprise Manager
E-mailová a SNMP upozornění Postgres Enterprise Manager pgwatch2
pgwatch2 je další monitorovací nástroj zaměřený na PostgreSQL, řešení s vlastním hostitelem.
Abychom mohli definovat upozornění, musíme nejprve vytvořit vlastní řídicí panel a definovat metriku:
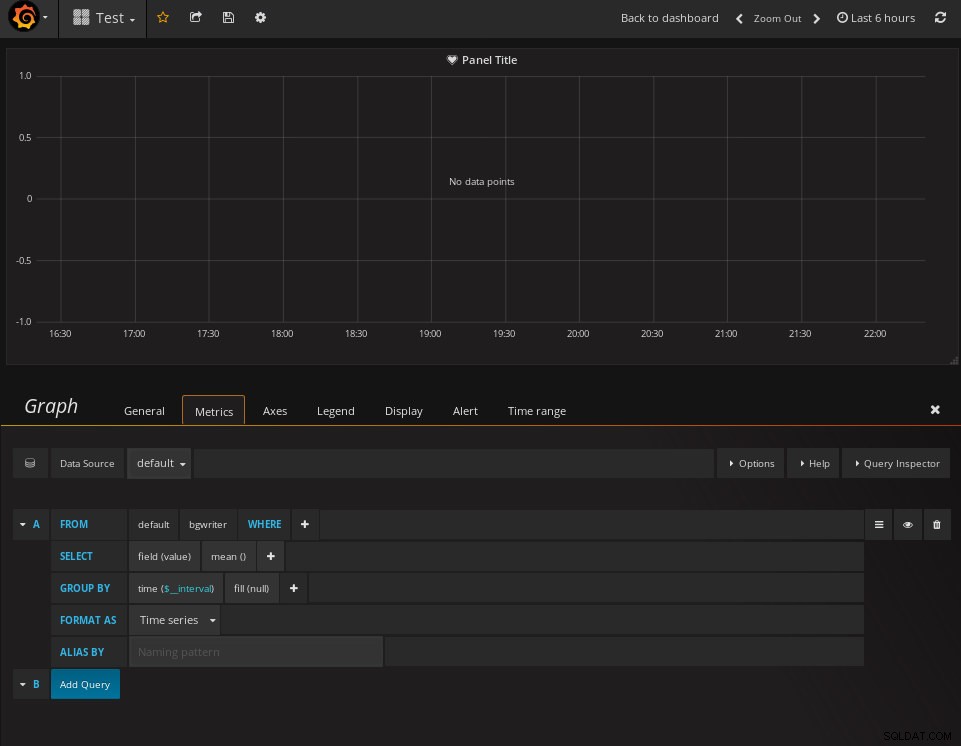 pgwatch2 Dashboard Metrics
pgwatch2 Dashboard Metrics Dále nakonfigurujte upozornění:
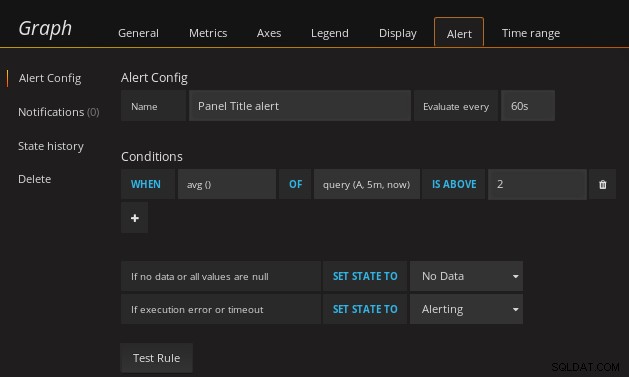 pgwatch2 Konfigurace upozornění řídicího panelu
pgwatch2 Konfigurace upozornění řídicího panelu Po nakonfigurování se výstrahy zobrazí na stránce Seznam výstrah:
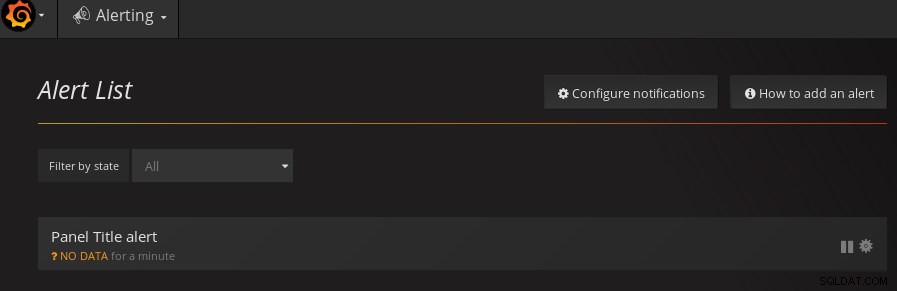 pgwatch2 Dashboard Seznam upozornění
pgwatch2 Dashboard Seznam upozornění pgwatch2 se integruje se všemi oblíbenými oznamovacími systémy. Zde je příklad přidání kanálu Slack:
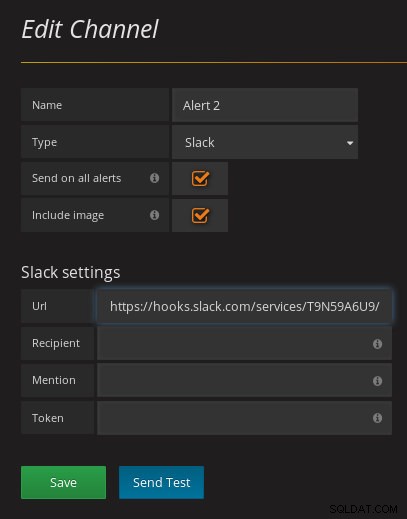 pgwatch2 Slack Integration
pgwatch2 Slack Integration Chcete-li zobrazit kanály oznámení nakonfigurované v systému, otevřete stránku „Kanály oznámení“:
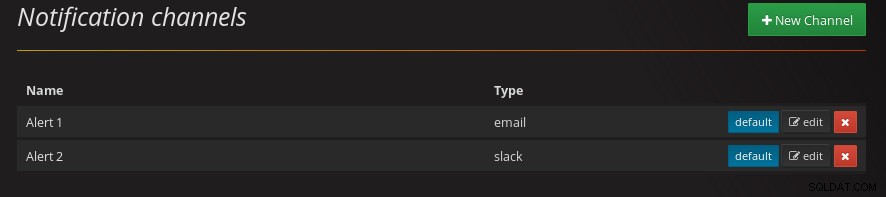 kanály oznámení pgwatch2
kanály oznámení pgwatch2 Další metriky lze přidat, jak je zdokumentováno v části Funkce pgwatch2.
ClusterControl
ClusterControl je místní databázově orientovaný systém správy s podporou PostgreSQL, MySQL, MariaDB a MongoDB.
Prvním krokem je přidání integrace oznámení. Další informace o dostupných integracích jsou k dispozici na stránce Představení integrací výstrah ClusterControl:
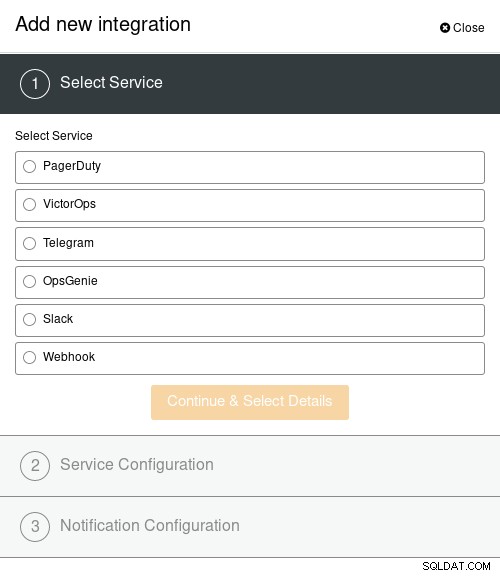 Integrace ClusterControl
Integrace ClusterControl Pro účely této ukázky jsem nakonfiguroval Slack:
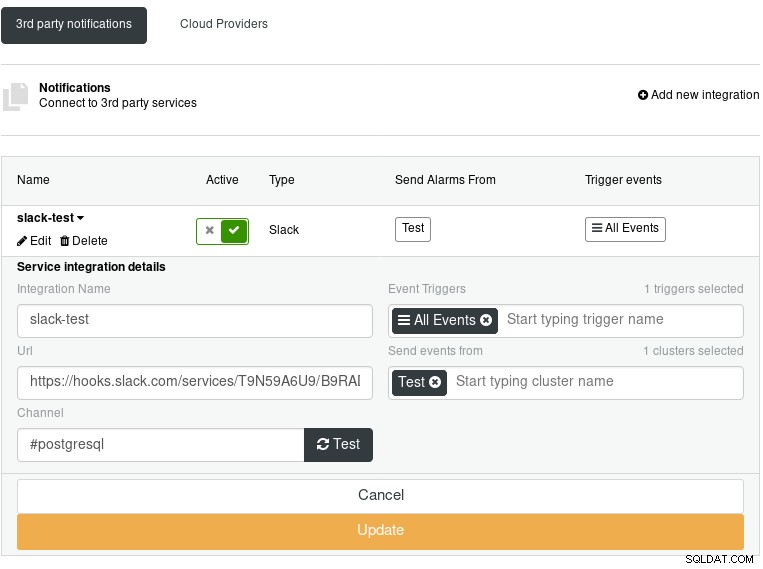 ClusterControl Slack Integration
ClusterControl Slack Integration ClusterControl také nabízí možnost upozornění e-mailem:
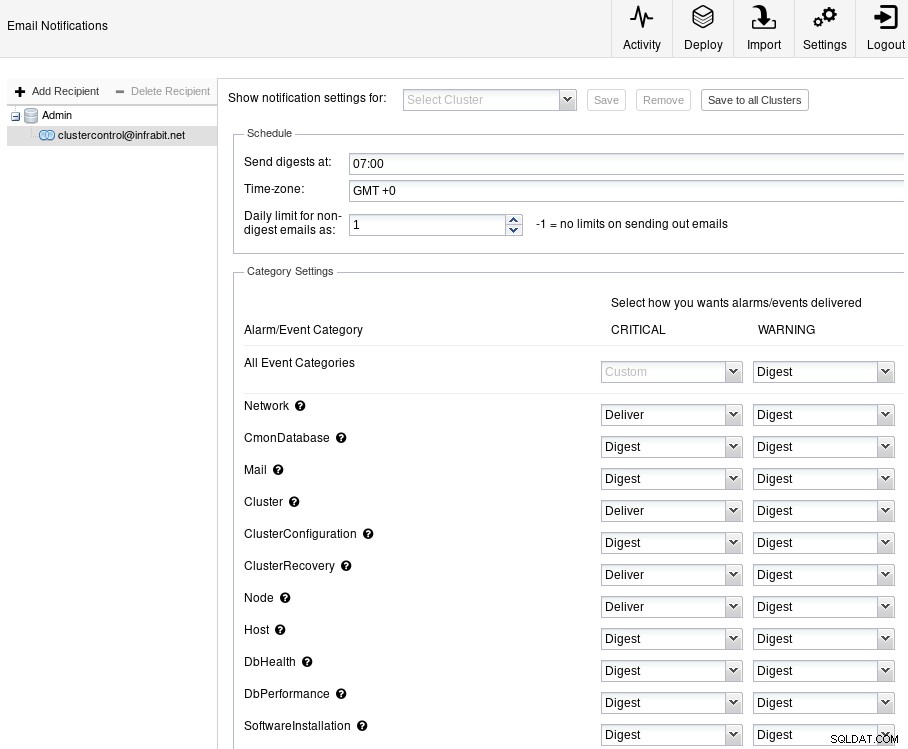 Oznámení ClusterControl prostřednictvím e-mailu
Oznámení ClusterControl prostřednictvím e-mailu Jakmile budou oznámení zavedena, vytvořte si vlastní poradce, aby bylo možné spouštět výstrahy na základě konkrétních kritérií:
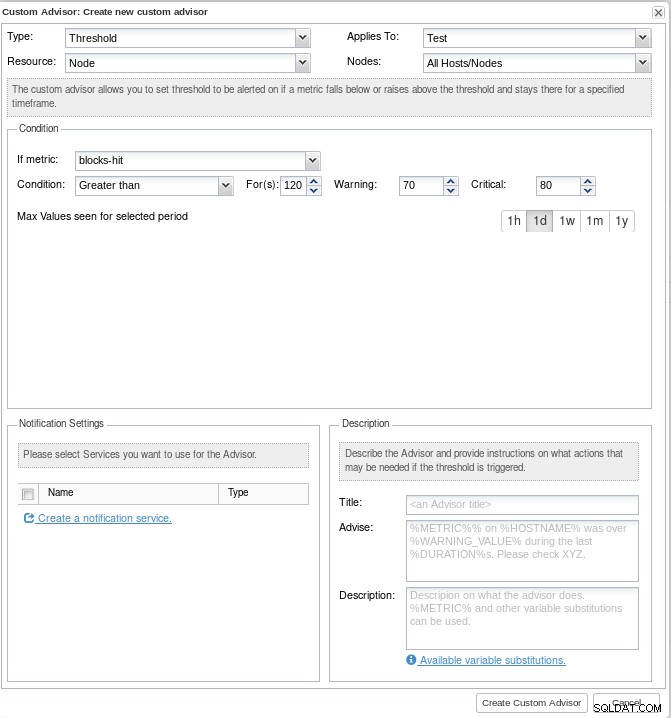 ClusterControl Custom AdvisorsStáhněte si dokument ještě dnes PostgreSQL Management &Automation with ClusterControlZjistěte, co potřebujete vědět k nasazení, monitorování spravovat a škálovat PostgreSQLStáhněte si dokument Whitepaper
ClusterControl Custom AdvisorsStáhněte si dokument ještě dnes PostgreSQL Management &Automation with ClusterControlZjistěte, co potřebujete vědět k nasazení, monitorování spravovat a škálovat PostgreSQLStáhněte si dokument Whitepaper Závěr
Tento článek nebyl zamýšlen jako hluboký ponor do funkčnosti jednotlivých nástrojů, spíše jsem se pokusil nastínit to, co jsem považoval za důležité funkce související s upozorňováním a upozorněním pro PostgreSQL, konkrétně.
Jedním z poučení je, že proces výběru by měl vzít v úvahu několik faktorů:
- on premise nebo SaaS
- agentní nebo vzdálená kontrola
- integrace se systémy správy incidentů a chatovacími službami
- dostupnost monitorovaných metrik a pluginů
- možnost přidávat vlastní metriky
- Funkce správy výstrah (např. seskupování)
- složitost versus granularita uživatelského rozhraní
- další funkce (správa, ladění, rozhraní API atd.)
Také pokud jedno řešení nesplňuje všechny obchodní a/nebo technické požadavky, je vždy možné použít kombinaci služeb.