Při práci v IT průmyslu jsme slovo „failover“ pravděpodobně slyšeli mnohokrát, ale může také vyvolat otázky jako:Co je to skutečně selhání? K čemu ji můžeme použít? Je důležité ho mít? Jak to můžeme udělat?
I když se mohou zdát docela základní otázky, je důležité je vzít v úvahu v jakémkoli databázovém prostředí. A mnohem častěji nebereme v potaz základy...
Pro začátek se podívejme na některé základní pojmy.
Co je převzetí služeb při selhání?
Failover je schopnost systému pokračovat v činnosti, i když dojde k nějakému selhání. To naznačuje, že funkce systému přebírají sekundární komponenty, pokud primární komponenty selžou.
V případě PostgreSQL existují různé nástroje, které vám umožňují implementovat databázový cluster odolný vůči selhání. Jeden mechanismus redundance dostupný nativně v PostgreSQL je replikace. A novinkou v PostgreSQL 10 je implementace logické replikace.
Co je replikace?
Je to proces kopírování a udržování aktualizovaných dat v jednom nebo více databázových uzlech. Používá koncept hlavního uzlu, který přijímá úpravy, a podřízených uzlů, kde jsou replikovány.
Máme několik způsobů kategorizace replikace:
- Synchronní replikace:Nedochází ke ztrátě dat, i když je ztracen náš hlavní uzel, ale potvrzení v hlavním uzlu musí čekat na potvrzení od podřízeného, což může ovlivnit výkon.
- Asynchronní replikace:Existuje možnost ztráty dat v případě ztráty hlavního uzlu. Pokud replika z nějakého důvodu není v době incidentu aktualizována, informace, které nebyly zkopírovány, mohou být ztraceny.
- Fyzická replikace:Bloky disku se zkopírují.
- Logická replikace:Streamování změn dat.
- Podřízené jednotky v teplém pohotovostním režimu:Nepodporují připojení.
- Hot Standby Slave:Podpora připojení pouze pro čtení, užitečné pro sestavy nebo dotazy.
K čemu se používá převzetí služeb při selhání?
Existuje několik možných použití převzetí služeb při selhání. Podívejme se na několik příkladů.
Migrace
Pokud chceme migrovat z jednoho datového centra do druhého minimalizací prostojů, můžeme použít převzetí služeb při selhání.
Předpokládejme, že náš master je v datovém centru A a chceme migrovat naše systémy do datového centra B.
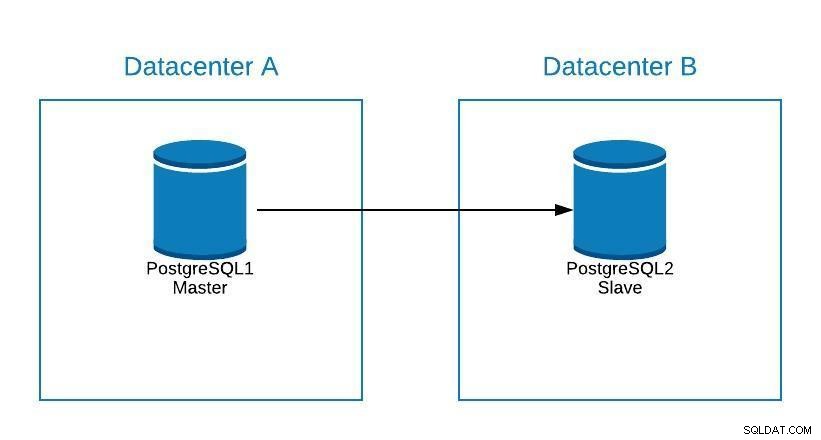 Diagram migrace 1
Diagram migrace 1 Můžeme vytvořit repliku v datovém centru B. Jakmile je synchronizována, musíme zastavit náš systém, povýšit naši repliku na nový master a failover, než náš systém nasměrujeme na nový master v datovém centru B.
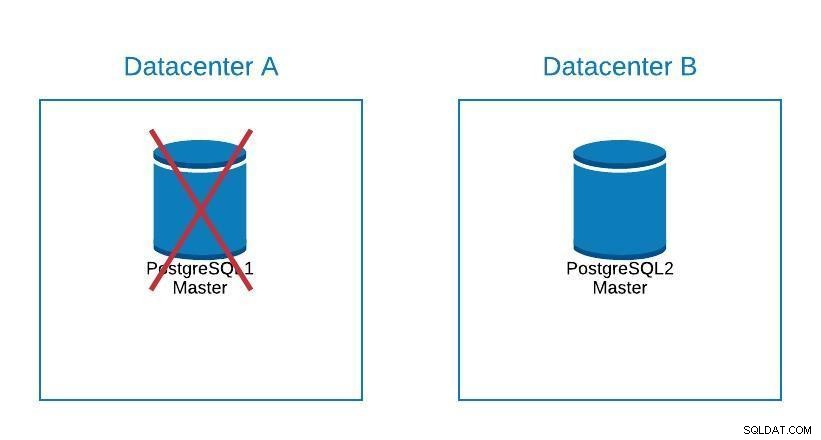 Diagram migrace 2
Diagram migrace 2 Failover se netýká pouze databáze, ale také aplikace (aplikací). Jak poznají, ke které databázi se mají připojit? Určitě nechceme upravovat naši aplikaci, protože to jen prodlouží naše výpadky. Můžeme tedy nakonfigurovat load balancer tak, že když stáhneme náš master, automaticky ukáže na další server, který je povýšen.
Další možností je použití DNS. Povýšením hlavní repliky v novém datovém centru přímo upravíme IP adresu názvu hostitele, který ukazuje na hlavní server. Tímto způsobem se vyhneme nutnosti upravovat naši aplikaci, a přestože to nelze provést automaticky, je to alternativa, pokud nechceme implementovat nástroj pro vyrovnávání zatížení.
Mít jedinou instanci nástroje pro vyrovnávání zatížení není skvělé, protože se může stát jediným bodem selhání. Proto můžete také implementovat převzetí služeb při selhání pro nástroj pro vyrovnávání zatížení pomocí služby, jako je keepalived. Tímto způsobem, pokud máme problém s naším primárním load balancerem, keepalived je zodpovědný za migraci IP do našeho sekundárního load balanceru a vše funguje transparentně.
Údržba
Pokud musíme provést jakoukoli údržbu na našem postgreSQL master databázovém serveru, můžeme povýšit našeho otroka, provést úkol a zrekonstruovat slave na našem starém masteru.
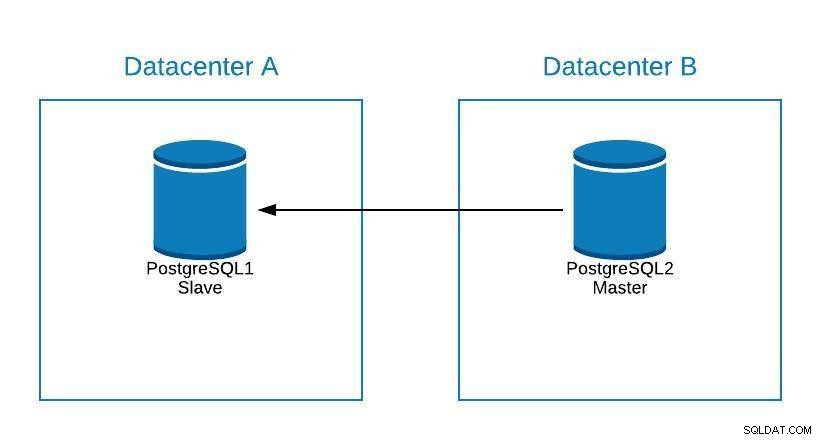 Diagram údržby 1
Diagram údržby 1 Poté můžeme znovu povýšit starého pána a zopakovat proces rekonstrukce otroka a vrátit se do původního stavu.
Diagram údržby 2 Tímto způsobem jsme mohli pracovat na našem serveru, aniž bychom riskovali, že budeme offline nebo ztratíme informace při provádění údržby.
Upgrade
Ačkoli PostgreSQL 11 ještě není k dispozici, bylo by technicky možné upgradovat z PostgreSQL verze 10 pomocí logické replikace, jak to lze provést s jinými motory.
Kroky by byly stejné jako při migraci do nového datového centra (viz část Migrace), pouze by náš slave byl v PostgreSQL 11.
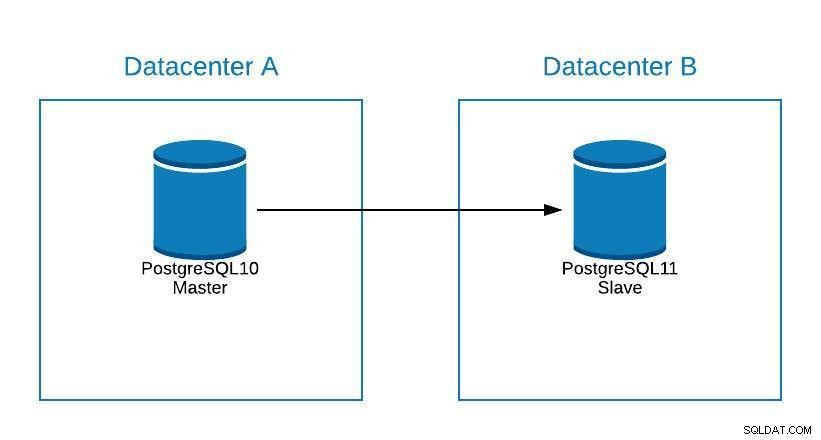 Diagram upgradu 1
Diagram upgradu 1 Problémy
Nejdůležitější funkcí převzetí služeb při selhání je minimalizovat naše prostoje nebo se vyhnout ztrátě informací, když máme problém s naší hlavní databází.
Pokud z nějakého důvodu ztratíme naši hlavní databázi, můžeme provést převzetí služeb při selhání povýšením našeho slave na master a udržet naše systémy v chodu.
K tomu nám PostgreSQL neposkytuje žádné automatizované řešení. Můžeme to udělat ručně nebo automatizovat pomocí skriptu nebo externího nástroje.
Povýšení našeho otroka na pána:
-
Spusťte pg_ctl promotion
bash-4.2$ pg_ctl promote -D /var/lib/pgsql/10/data/ waiting for server to promote.... done server promoted - Vytvořte soubor trigger_file, který musíme přidat do recovery.conf našeho datového adresáře.
bash-4.2$ cat /var/lib/pgsql/10/data/recovery.conf standby_mode = 'on' primary_conninfo = 'application_name=pgsql_node_0 host=postgres1 port=5432 user=replication password=****' recovery_target_timeline = 'latest' trigger_file = '/tmp/failover.trigger' bash-4.2$ touch /tmp/failover.trigger
Abychom mohli implementovat strategii převzetí služeb při selhání, musíme ji naplánovat a důkladně otestovat pomocí různých scénářů selhání. Protože k selhání může dojít různými způsoby a řešení by v ideálním případě mělo fungovat pro většinu běžných scénářů. Pokud hledáme způsob, jak to automatizovat, můžeme se podívat na to, co ClusterControl nabízí.
ClusterControl for PostgreSQL Failover
ClusterControl má řadu funkcí souvisejících s replikací PostgreSQL a automatickým převzetím služeb při selhání.
Přidat Slave
Pokud chceme přidat slave v jiném datovém centru, ať už jako případnou událost, nebo pro migraci vašich systémů, můžeme přejít na Cluster Actions a vybrat Add Replication Slave.
 ClusterControl Přidat Slave 1
ClusterControl Přidat Slave 1 Budeme muset zadat některá základní data, jako je IP nebo název hostitele, datový adresář (volitelné), synchronní nebo asynchronní slave. Měli bychom mít našeho otroka v provozu po několika sekundách.
V případě použití jiného datového centra doporučujeme vytvořit asynchronní slave, protože jinak může latence značně ovlivnit výkon.
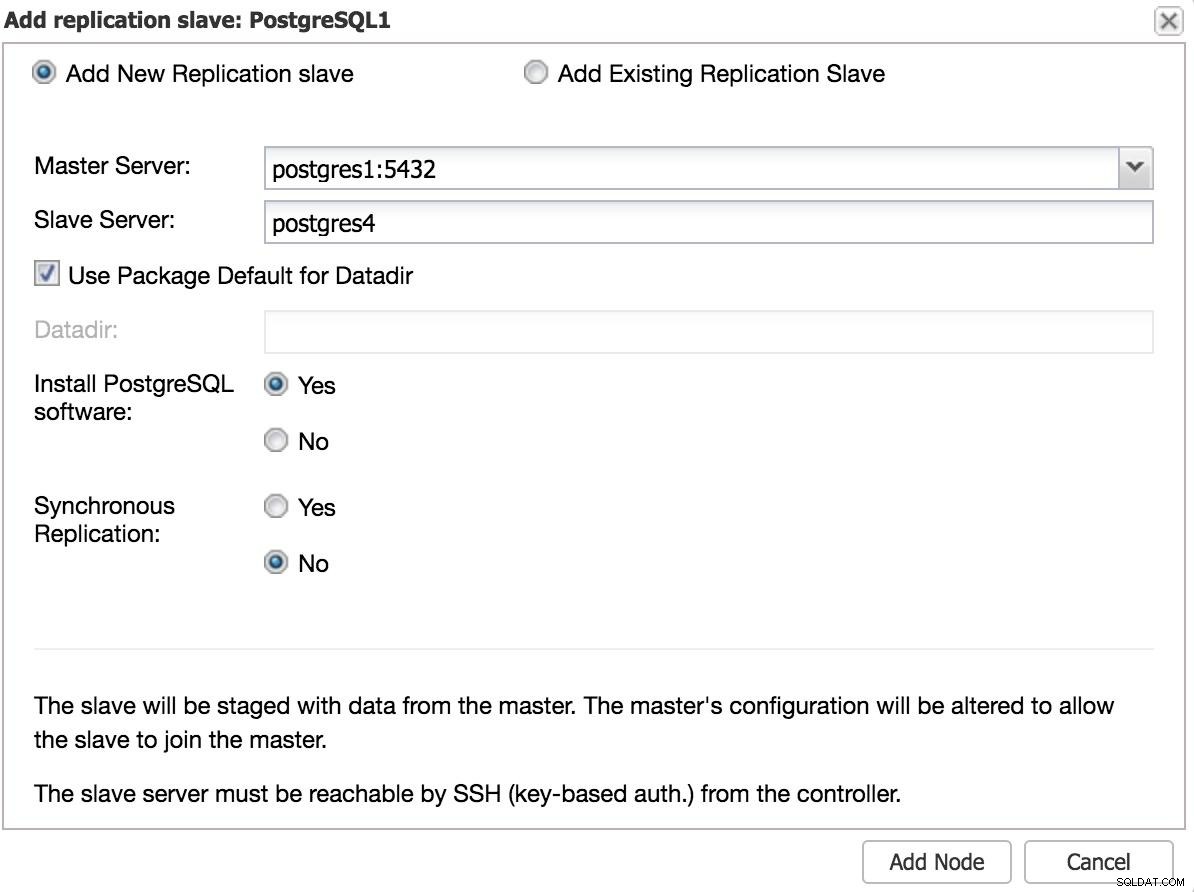 ClusterControl Přidat Slave 2
ClusterControl Přidat Slave 2 Ruční převzetí služeb při selhání
Pomocí ClusterControl lze převzetí služeb při selhání provést ručně nebo automaticky.
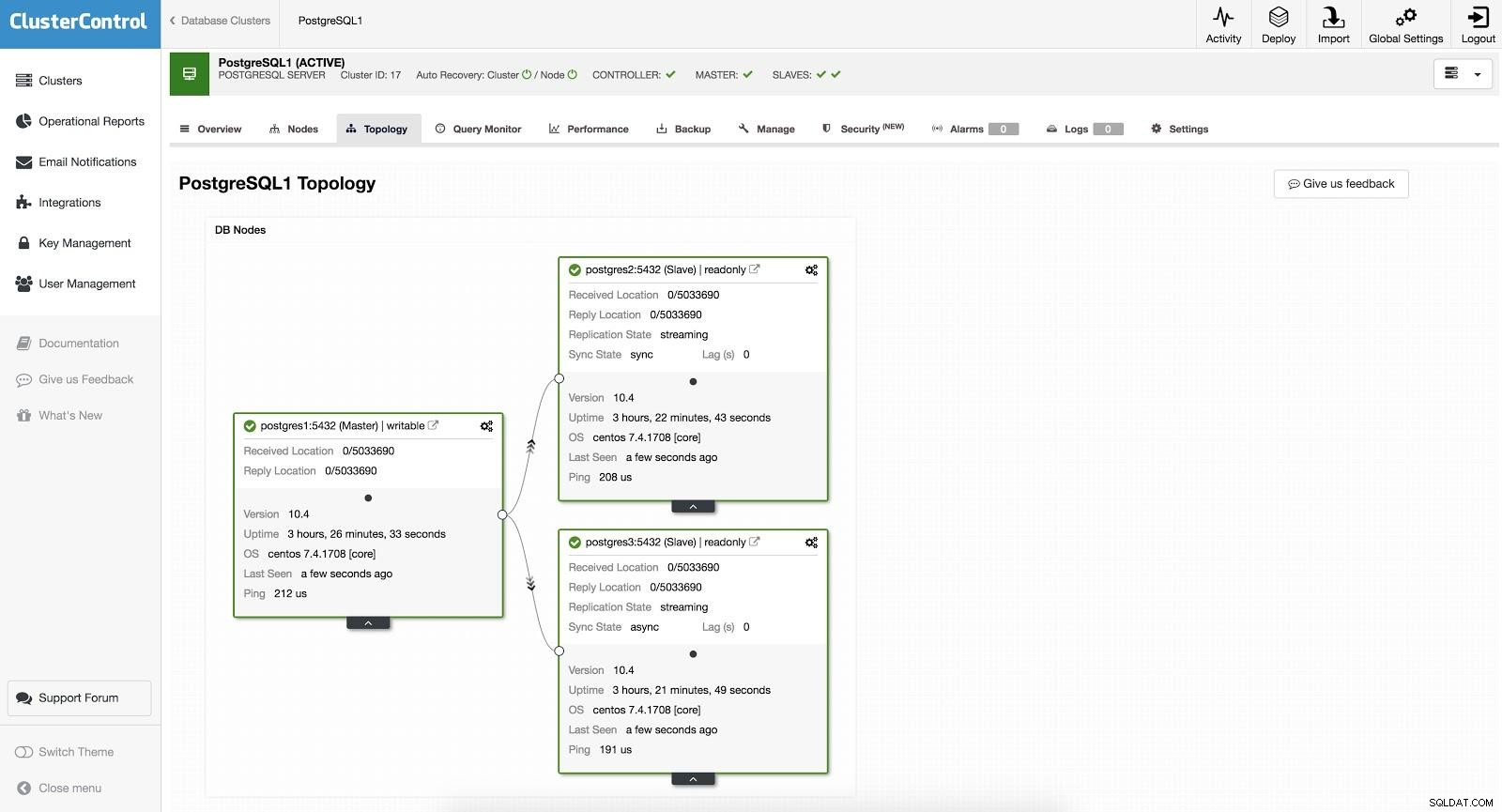 ClusterControl Failover 1
ClusterControl Failover 1 Chcete-li provést ruční převzetí služeb při selhání, přejděte do ClusterControl -> Select Cluster -> Nodes a v Action Node jednoho z našich slave vyberte "Promote Slave". Tímto způsobem se náš otrok po několika sekundách stane pánem a to, co bylo naším pánem dříve, se změní na otroka.
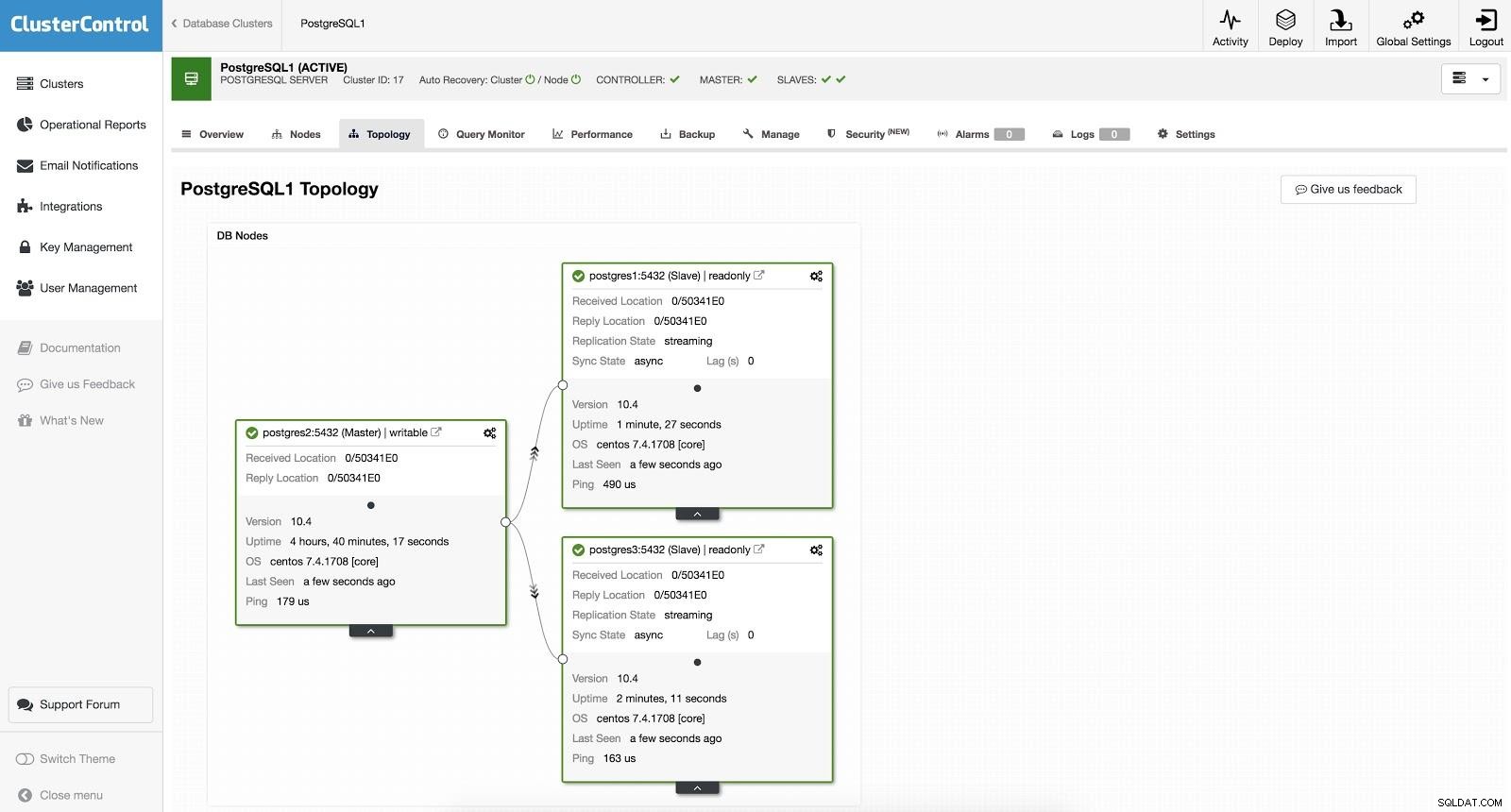 ClusterControl Failover 2
ClusterControl Failover 2 Výše uvedené je užitečné pro úkoly migrace, údržby a upgradů, které jsme viděli dříve.
Automatické převzetí služeb při selhání
V případě automatického převzetí služeb při selhání detekuje ClusterControl selhání v masteru a povýší slave s nejaktuálnějšími daty jako nový master. Funguje také na ostatních podřízených, aby je nechali replikovat z nového mastera.
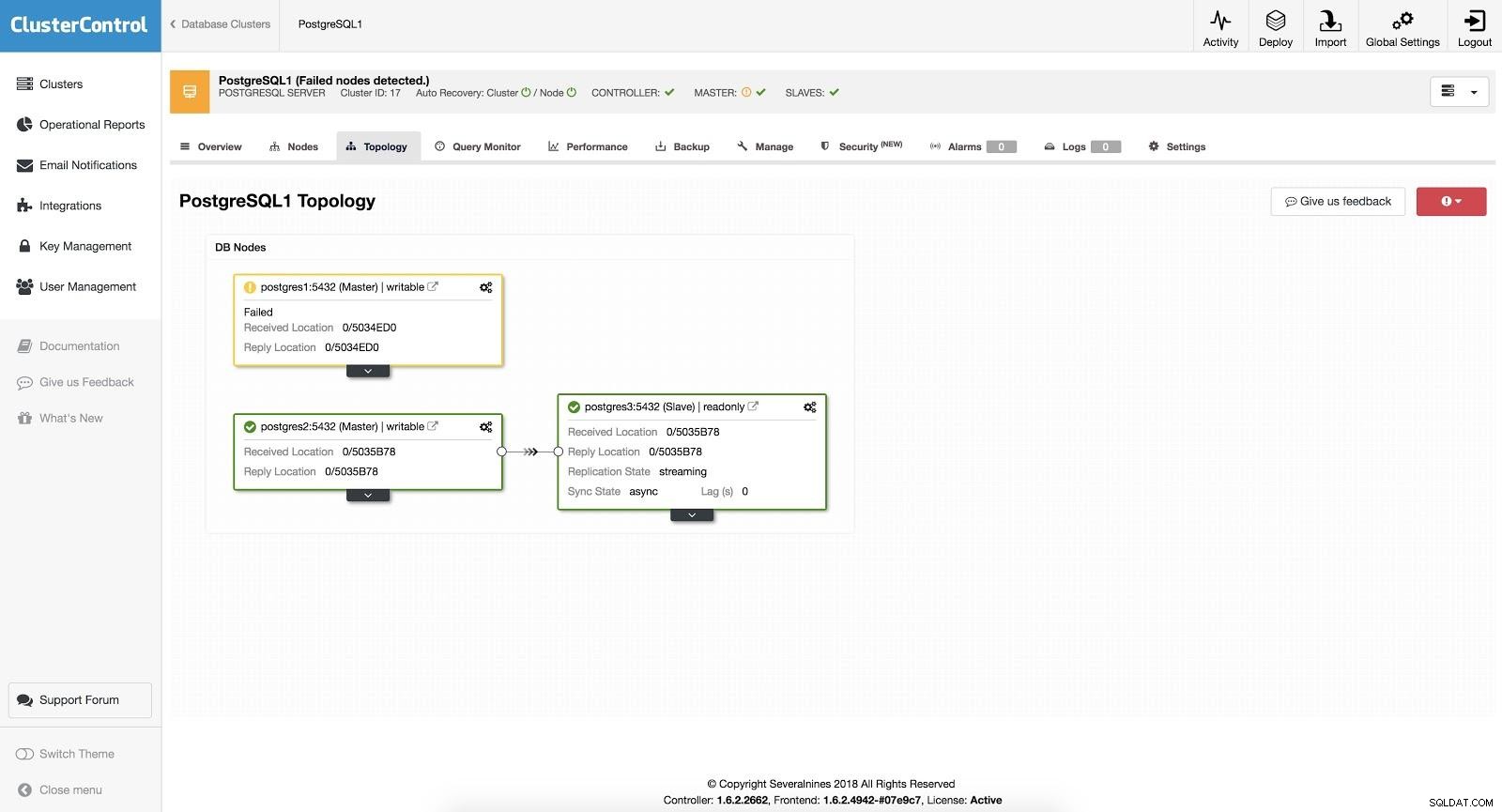 ClusterControl Failover 3
ClusterControl Failover 3 Když je zapnutá možnost „Autorecovery“, náš ClusterControl provede automatické převzetí služeb při selhání a upozorní nás na problém. Tímto způsobem se naše systémy mohou obnovit během několika sekund a bez našeho zásahu.
Cluster Control nám nabízí možnost nakonfigurovat whitelist/blacklist, aby bylo možné definovat, jak chceme, aby byly naše servery brány v úvahu (nebo aby nebyly brány v úvahu) při rozhodování o hlavním kandidátovi.
Z těch, které jsou k dispozici podle výše uvedené konfigurace, vybere ClusterControl nejpokročilejšího slave, přičemž k tomuto účelu použije pg_current_xlog_location (PostgreSQL 9+) nebo pg_current_wal_lsn (PostgreSQL 10+) v závislosti na verzi naší databáze.
ClusterControl také provádí několik kontrol procesu převzetí služeb při selhání, aby se zabránilo některým běžným chybám. Jedním z příkladů je, že pokud se nám podaří obnovit náš starý neúspěšný master, NEBUDE automaticky znovu zaveden do clusteru, ani jako master, ani jako slave. Musíme to udělat ručně. Vyhneme se tak možnosti ztráty dat nebo nekonzistence v případě, že náš slave (kterého jsme povýšili) byl v době selhání zpožděn. Možná bychom chtěli problém podrobně analyzovat, ale při jeho přidání do našeho clusteru bychom možná přišli o diagnostické informace.
Také pokud selže převzetí služeb při selhání, nejsou prováděny žádné další pokusy, je nutný ruční zásah k analýze problému a provedení odpovídajících akcí. Je to proto, aby se zabránilo situaci, kdy se ClusterControl jako správce vysoké dostupnosti pokusí povýšit dalšího slave a dalšího. Může nastat problém a my nechceme situaci zhoršovat pokusy o vícenásobné převzetí služeb při selhání.
Vyvažovače zátěže
Jak jsme již zmínili dříve, nástroj pro vyrovnávání zatížení je důležitým nástrojem, který je třeba vzít v úvahu pro naše převzetí služeb při selhání, zejména pokud chceme v topologii databáze použít automatické převzetí služeb při selhání.
Aby bylo převzetí služeb při selhání transparentní pro uživatele i aplikaci, potřebujeme komponentu mezi tím, protože nestačí povýšit master na slave. K tomu můžeme použít HAProxy + Keepalived.
Co je HAProxy?
HAProxy je nástroj pro vyrovnávání zatížení, který distribuuje provoz z jednoho zdroje do jednoho nebo více cílů a může pro tento úkol definovat specifická pravidla a/nebo protokoly. Pokud některý z cílů přestane reagovat, je označen jako offline a provoz je odeslán do zbývajících dostupných cílů. To zabraňuje odesílání provozu do nepřístupného cíle a zabraňuje ztrátě tohoto provozu jeho nasměrováním do platného cíle.
Co je Keepalived?
Keepalived umožňuje konfigurovat virtuální IP v rámci aktivní/pasivní skupiny serverů. Tato virtuální IP je přiřazena k aktivnímu „Primárnímu“ serveru. Pokud tento server selže, IP je automaticky migrována na „sekundární“ server, který byl shledán pasivním, což mu umožňuje pokračovat v práci se stejnou IP transparentním způsobem pro naše systémy.
Abychom toto řešení implementovali pomocí ClusterControl, začali jsme, jako bychom chtěli přidat slave. Přejděte do Cluster Actions a vyberte Add Load Balancer (viz obrázek ClusterControl Add Slave 1).
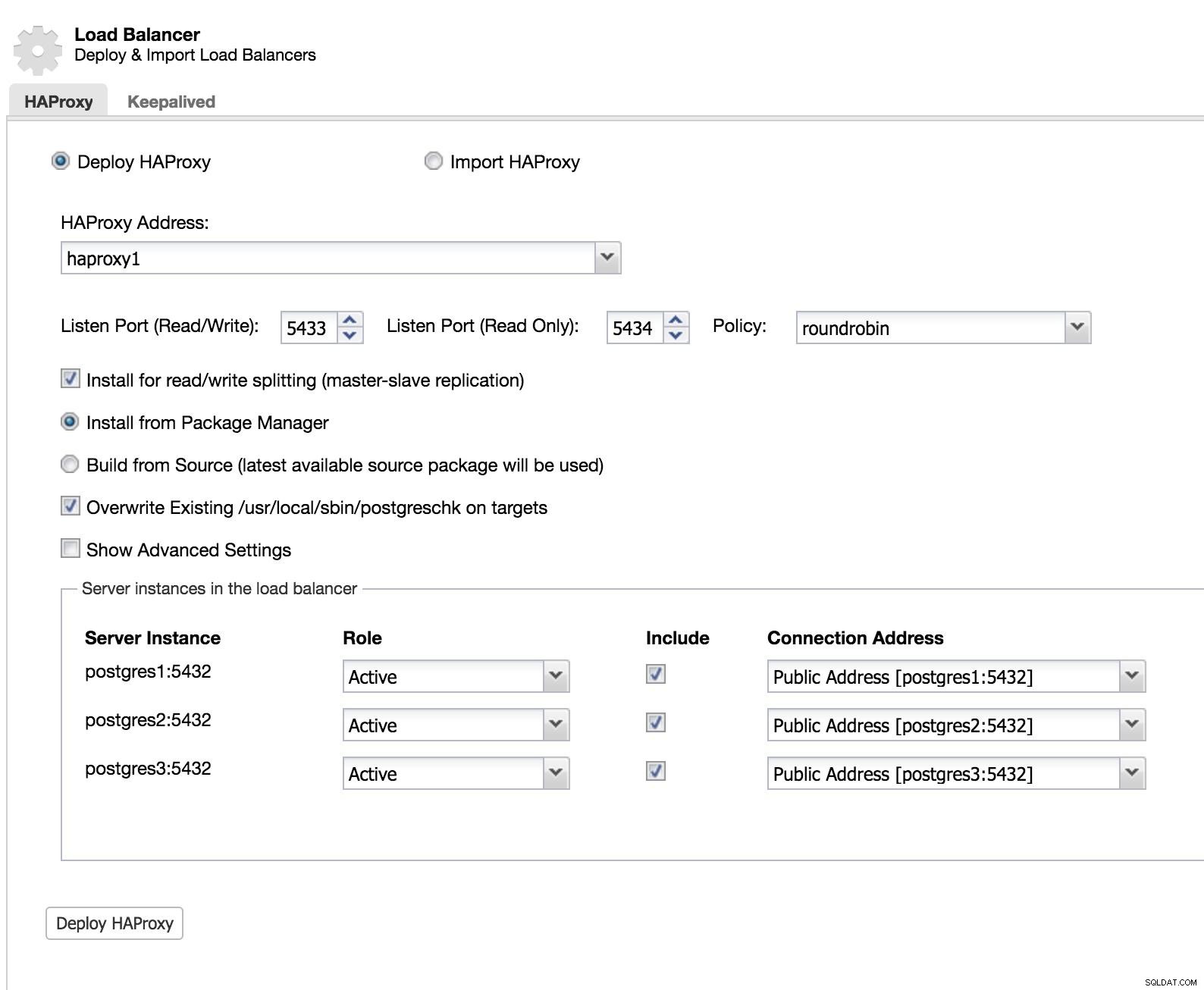 ClusterControl Load Balancer 1
ClusterControl Load Balancer 1 Přidáváme informace o našem novém nástroji pro vyrovnávání zatížení a o tom, jak chceme, aby se choval (Zásady).
V případě, že chceme implementovat převzetí služeb při selhání pro náš nástroj pro vyrovnávání zatížení, musíme nakonfigurovat alespoň dvě instance.
Poté můžeme nakonfigurovat Keepalived (Vyberte Cluster -> Spravovat -> Load Balancer -> Keepalived).
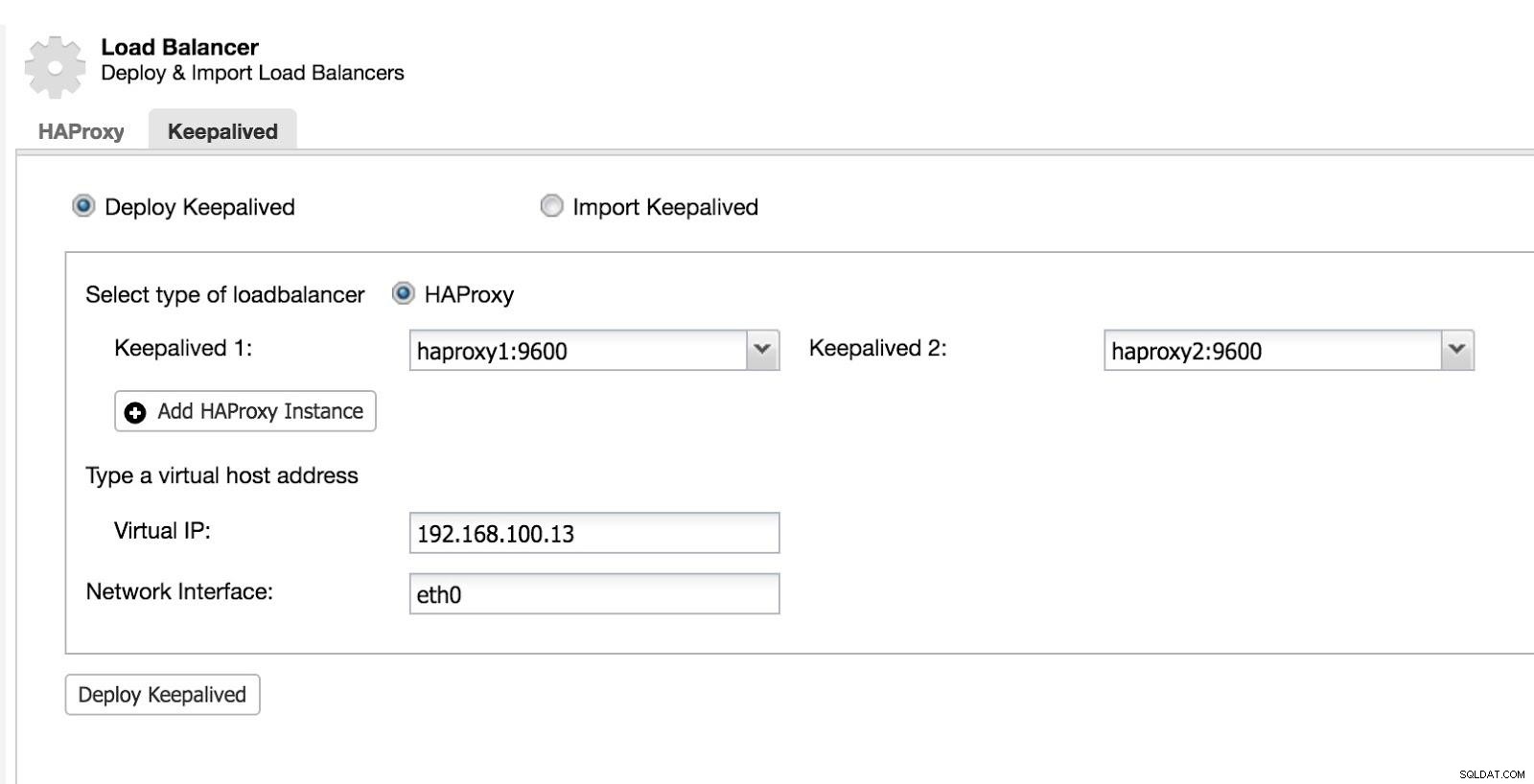 ClusterControl Load Balancer 2
ClusterControl Load Balancer 2 Poté máme následující topologii:
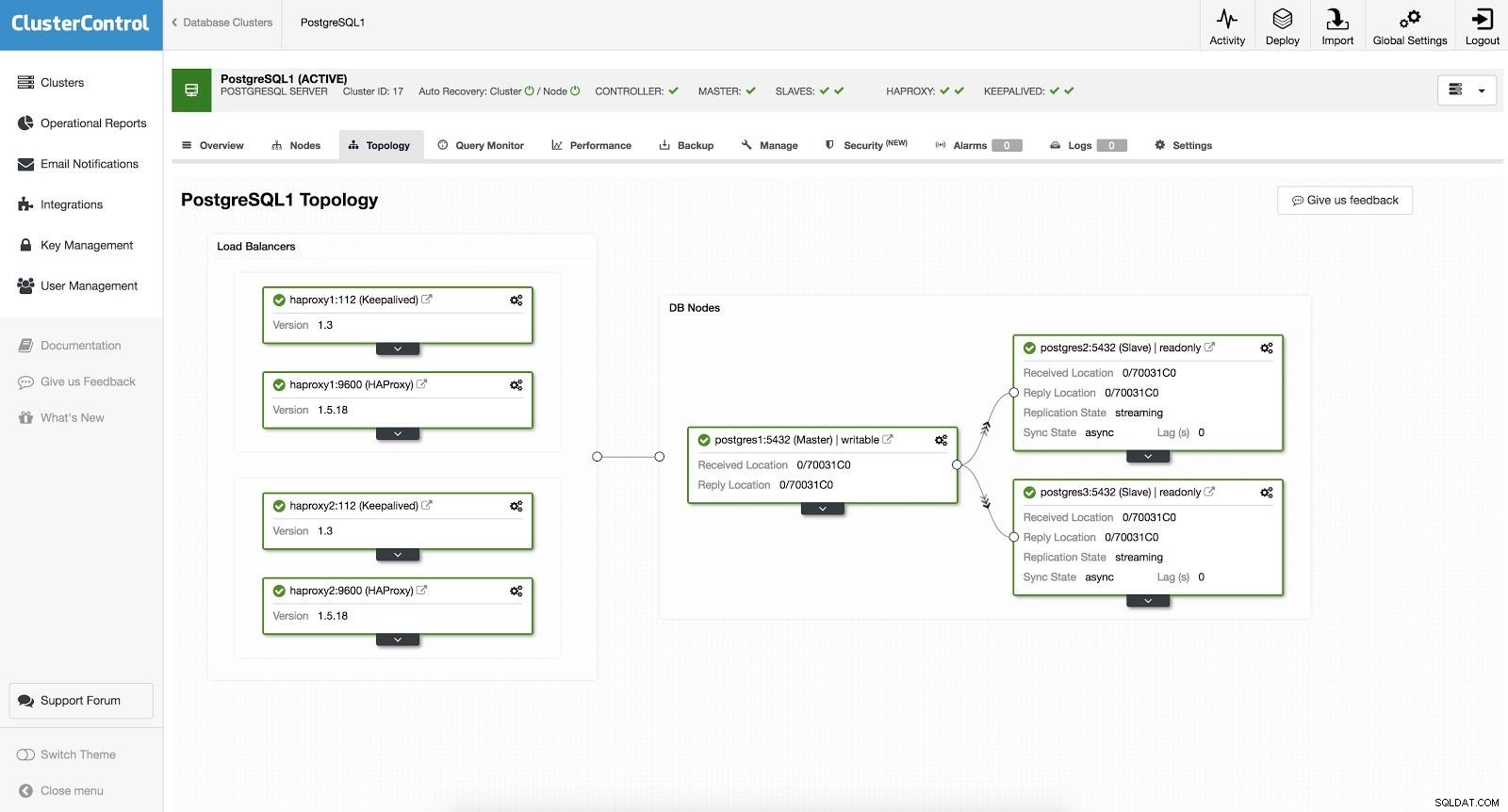 ClusterControl Load Balancer 3
ClusterControl Load Balancer 3 HAProxy je nakonfigurován se dvěma různými porty, jedním pro čtení-zápis a jedním pouze pro čtení.
V našem portu pro čtení a zápis máme náš hlavní server jako online a zbytek našich uzlů jako offline. V portu pouze pro čtení máme master i slave online. Tímto způsobem můžeme vyvážit čtecí provoz mezi našimi uzly. Při zápisu se použije port pro čtení a zápis, který bude ukazovat na master.
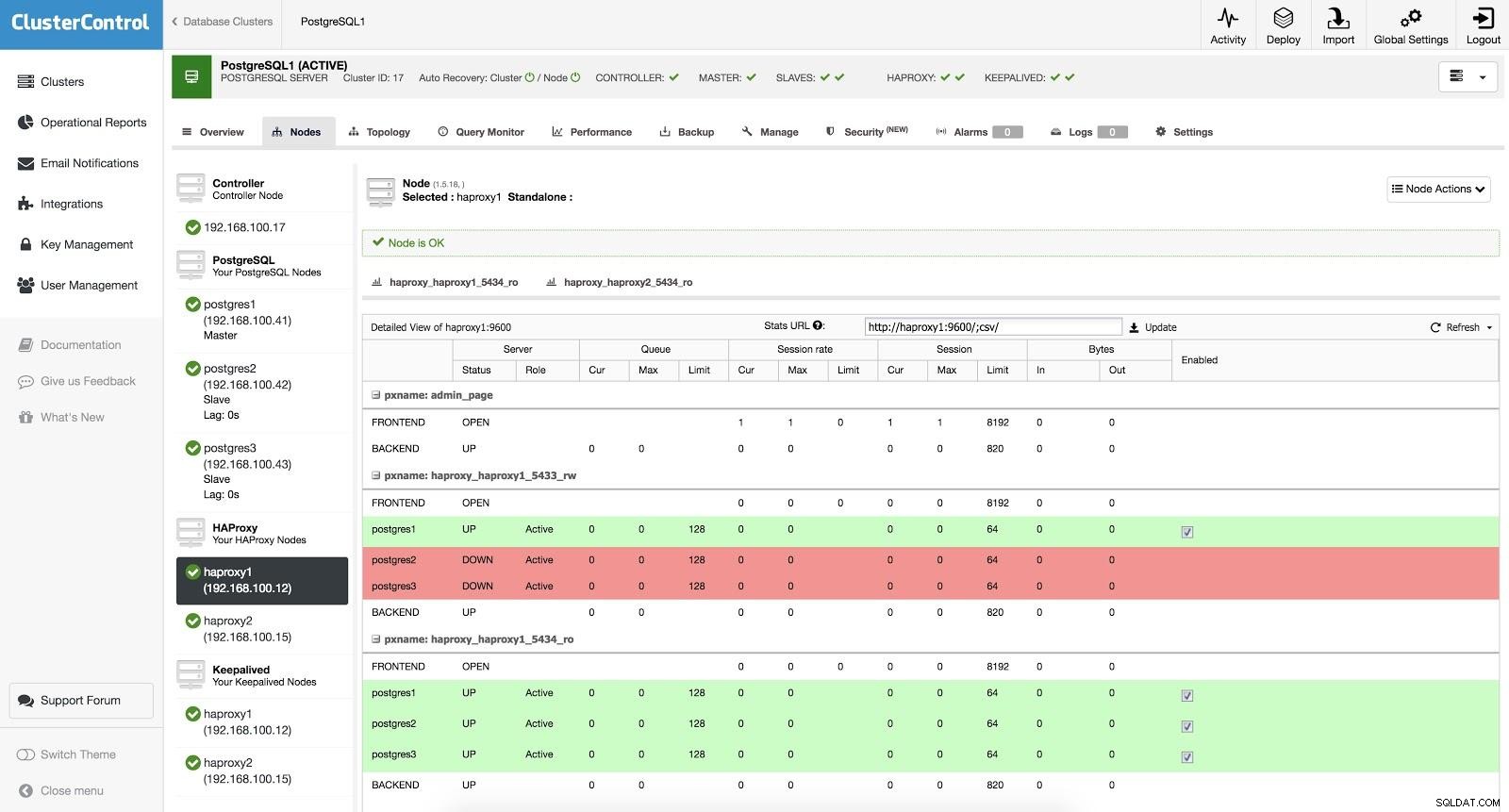 ClusterControl Load Balancer 3
ClusterControl Load Balancer 3 Když HAProxy zjistí, že jeden z našich uzlů, ať už master nebo slave, není přístupný, automaticky ho označí jako offline. HAProxy na něj nebude posílat žádný provoz. Tato kontrola se provádí pomocí skriptů kontroly stavu, které jsou konfigurovány ClusterControl v době nasazení. Tyto kontrolují, zda jsou instance aktivní, zda procházejí obnovením nebo jsou pouze pro čtení.
Když ClusterControl povýší slave na master, naše HAProxy označí starý master jako offline (pro oba porty) a uvede povýšený uzel online (do portu pro čtení a zápis). Tímto způsobem naše systémy nadále normálně fungují.
Pokud naše aktivní HAProxy (která má přiřazenou virtuální IP adresu, ke které se naše systémy připojují) selže, Keepalived tuto IP migruje na naši pasivní HAProxy automaticky. To znamená, že naše systémy jsou pak schopny nadále normálně fungovat.
Závěr
Jak jsme mohli vidět, převzetí služeb při selhání je základní součástí každé produkční databáze. To může být užitečné při provádění běžných úloh údržby nebo migrace. Doufáme, že tento blog byl užitečný jako úvod do tématu, takže můžete pokračovat ve výzkumu a vytvářet své vlastní strategie převzetí služeb při selhání.