S obnovou po havárii se snažíme nastavit systémy tak, aby zvládly vše, co by se mohlo pokazit v naší databázi. Co se stane, když databáze spadne? Co když vývojář omylem zkrátí tabulku? Co když zjistíme, že některá data byla smazána minulý týden, ale my jsme si toho nevšimli až dnes? Tyto věci se stávají a díky pevnému plánu a systému bude DBA vypadat jako hrdina, když se srdce všech ostatních již zastavilo, když katastrofa vztyčí svou ošklivou hlavu.
Každá databáze, která má jakoukoli hodnotu, by měla mít způsob, jak implementovat jednu nebo více možností zotavení po havárii. PostgreSQL má zabudovaný velmi solidní replikační systém a je dostatečně flexibilní, aby mohl být nastaven v mnoha konfiguracích, aby pomohl s obnovou po havárii, pokud by se něco pokazilo. Zaměříme se na scénáře, jako jsou výše uvedené otázky, jak nastavit naše možnosti zotavení po havárii a výhody každého řešení.
Vysoká dostupnost
Díky replikaci streamování v PostgreSQL se vysoká dostupnost snadno nastavuje a udržuje. Cílem je poskytnout web s podporou převzetí služeb při selhání, který lze povýšit na hlavní, pokud dojde z jakéhokoli důvodu k výpadku hlavní databáze, například k selhání hardwaru, selhání softwaru nebo dokonce k výpadku sítě. Hostování repliky na jiném hostiteli je skvělé, ale hostování v jiném datovém centru je ještě lepší.
Pro specifika nastavení streamovací replikace má Somenines k dispozici podrobný hloubkový ponor zde. Oficiální PostgreSQL Streaming Replication Documentation obsahuje podrobné informace o streamingovém replikačním protokolu a o tom, jak to celé funguje.
Standardní nastavení bude vypadat takto, hlavní databáze akceptující připojení pro čtení/zápis, s replikovanou databází přijímající veškerou aktivitu WAL téměř v reálném čase, přičemž veškerou aktivitu změny dat přehrává lokálně.
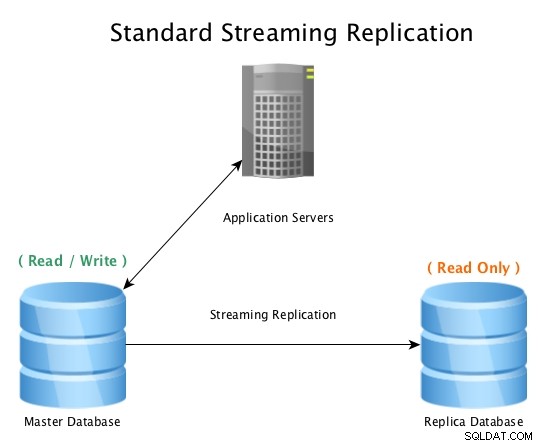 Standardní replikace streamování s PostgreSQL
Standardní replikace streamování s PostgreSQL Když se hlavní databáze stane nepoužitelnou, zahájí se procedura převzetí služeb při selhání, která ji přepne do režimu offline a povýší replikovanou databázi na hlavní a poté všechna připojení nasměruje na nově povýšeného hostitele. Toho lze dosáhnout buď překonfigurováním nástroje pro vyrovnávání zatížení, konfigurace aplikací, aliasů IP nebo jinými chytrými způsoby přesměrování provozu.
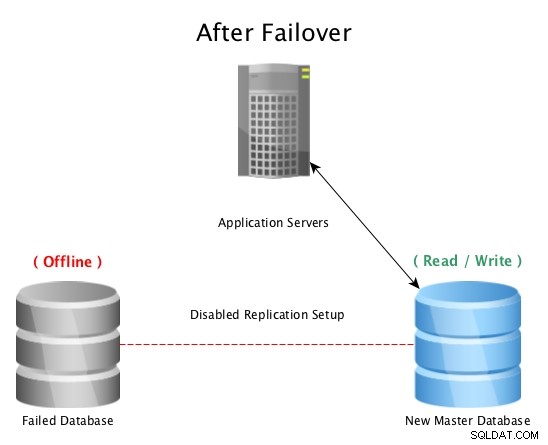 Po převzetí služeb při selhání pomocí PostgreSQL Streaming Replication
Po převzetí služeb při selhání pomocí PostgreSQL Streaming Replication Když hlavní databázi zasáhne katastrofa (jako je porucha pevného disku, výpadek napájení nebo cokoli, co brání hlavní databázi pracovat tak, jak bylo zamýšleno), přepnutí do pohotovostního režimu je nejrychlejší způsob, jak zůstat online obsluhovat dotazy aplikací nebo zákazníkům bez vážných problémů. prostoje. Poté probíhá závod buď o opravu selhaného databázového hostitele, nebo o uvedení nové repliky online, aby byla zachována záchranná síť připravené k použití v pohotovostním režimu. Vícenásobné pohotovostní režimy zajistí, že okno po katastrofální poruše bude také připraveno na sekundární poruchu, jakkoli se to může zdát nepravděpodobné.
Poznámka:Při selhání streamované repliky bude pokračovat tam, kde předchozí hlavní server skončil, takže to pomáhá udržovat databázi online, ale neobnovuje náhodně ztracená data.
Obnovení bodu v čase
Další možností zotavení po havárii je Point in TIME Recovery (PITR). S PITR lze kopii databáze přivést zpět kdykoli chceme, pokud máme základní zálohu z doby před tímto časem a všechny segmenty WAL potřebné do té doby.
Možnost Point In Time Recovery není tak rychle uvedena online jako Hot Standby, ale hlavní výhodou je možnost obnovit snímek databáze před velkou událostí, jako je smazaná tabulka, vkládání špatných dat nebo dokonce nevysvětlitelné poškození dat. . Cokoli, co by zničilo data takovým způsobem, že bychom chtěli získat kopii před tímto zničením, PITR zachraňuje situaci.
Point in Time Recovery funguje tak, že vytváří pravidelné snímky databáze, obvykle pomocí programu pg_basebackup, a uchovává archivované kopie všech souborů WAL vygenerovaných master
Nastavení bodové obnovy
Nastavení vyžaduje několik konfiguračních možností nastavených na hlavním serveru, z nichž některé je dobré použít s výchozími hodnotami v aktuální nejnovější verzi PostgreSQL 11. V tomto příkladu zkopírujeme 16MB soubor přímo do našeho vzdáleného hostitele PITR pomocí rsync , a jejich komprimaci na druhé straně pomocí úlohy cron.
Archivace WAL
Hlavní postgresql.conf
wal_level = replica
archive_mode = on
archive_command = 'rsync -av -z %p example@sqldat.com:/mnt/db/wal_archive/%f'POZNÁMKA: Nastavení archive_command může být mnoho věcí, celkovým cílem je poslat všechny archivované soubory WAL pryč na jiného hostitele z bezpečnostních důvodů. Pokud ztratíme nějaké soubory WAL, PITR za ztraceným souborem WAL se stane nemožným. Nechte svou programátorskou kreativitu zbláznit, ale ujistěte se, že je to spolehlivé.
[Volitelné] Komprimujte archivované soubory WAL:
Každé nastavení se bude poněkud lišit, ale pokud není daná databáze velmi lehká v aktualizacích dat, nahromadění 16 MB souborů zaplní místo na disku poměrně rychle. Snadný komprimační skript, nastavený pomocí cronu, by mohl vypadat takto.
compress_WAL_archive.sh:
#!/bin/bash
# Compress any WAL files found that are not yet compressed
gzip /mnt/db/wal_archive/*[0-F]POZNÁMKA: Během jakékoli metody obnovy bude nutné později všechny komprimované soubory dekomprimovat. Někteří správci se rozhodnou komprimovat soubory pouze poté, co jsou X dní staré, čímž udržují celkový nedostatek místa, ale také udržují novější soubory WAL připravené k obnovení bez další práce. Vyberte nejlepší možnost pro dané databáze, abyste maximalizovali rychlost obnovy.
Základní zálohy
Jednou z klíčových součástí zálohy PITR je základní záloha a frekvence základních záloh. Ty mohou být hodinové, denní, týdenní, měsíční, ale vybraly si nejlepší možnost na základě potřeb obnovy a také provozu databázových datových proudů. Pokud máme týdenní zálohy každou neděli a potřebujeme se obnovit až do sobotního odpoledne, převedeme základní zálohu z předchozí neděle online se všemi soubory WAL mezi touto zálohou a sobotním odpolednem. Pokud proces obnovy trvá 10 hodin, je to pravděpodobně nežádoucí příliš dlouho. Denní základní zálohy zkrátí dobu obnovy, protože základní záloha by byla z toho rána, ale také zvýší množství práce na hostiteli pro základní zálohu. sám.
Pokud týdenní obnova souborů WAL zabere jen několik minut, protože databáze zaznamenává nízký úbytek, pak jsou týdenní zálohy v pořádku. Stejná data budou nakonec existovat, ale klíčem je, jak rychle k nim budete mít přístup.
V našem příkladu nastavíme týdenní základní zálohu, a protože používáme Streaming Replication pro vysokou dostupnost a zároveň snižujeme zatížení hlavního serveru, vytvoříme základní zálohu z databáze replik.
base_backup.sh:
#!/bin/bash
backup_dir="$(date +'%Y-%m-%d')_backup"
cd /mnt/db/backups
mkdir $backup_dir
pg_basebackup -h <replica host> -p <replica port> -U replication -D $backup_dir -Ft -zPOZNÁMKA: Příkaz pg_basebackup předpokládá, že tento hostitel je nastaven pro přístup bez hesla pro „replikaci“ uživatele na hlavním serveru, což lze provést buď „důvěrou“ v pg_hba pro tohoto hostitele zálohy PITR, heslem v souboru .pgpass nebo jinými bezpečnějšími způsoby. . Při nastavování záloh mějte na paměti zabezpečení.
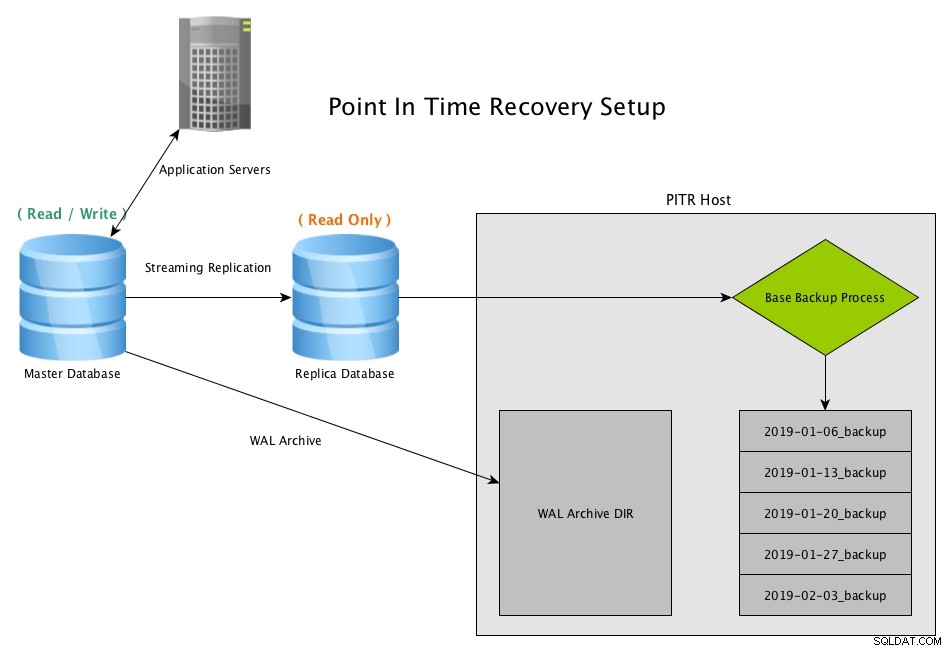 Point In Time Recovery (PITR) ze streamovací repliky s PostgreSQLStáhněte si dokument ještě dnes Správa a automatizace PostgreSQL pomocí Cluster co potřebujete vědět k nasazení, monitorování, správě a škálování PostgreSQLStáhněte si Whitepaper
Point In Time Recovery (PITR) ze streamovací repliky s PostgreSQLStáhněte si dokument ještě dnes Správa a automatizace PostgreSQL pomocí Cluster co potřebujete vědět k nasazení, monitorování, správě a škálování PostgreSQLStáhněte si Whitepaper Scénář obnovy PITR
Nastavení Point In Time Recovery je pouze část práce, nutnost obnovit data je druhá část. S trochou štěstí se to možná nikdy nemusí stát, ale důrazně se doporučuje pravidelně obnovovat zálohu PITR, abyste ověřili, že systém funguje, a abyste se ujistili, že proces je znám / správně napsán.
V našem testovacím scénáři vybereme bod v čase k obnovení a zahájíme proces obnovy. Například:V pátek ráno vývojář vloží do výroby novou změnu kódu, aniž by prošel kontrolou kódu, a zničí to spoustu důležitých zákaznických dat. Vzhledem k tomu, že náš Hot Standby je vždy synchronizován s masterem, jeho selháním by se nic nevyřešilo, protože by to byla stejná data. Zálohy PITR nás zachrání.
Zaslání kódu proběhlo v 11:00, takže potřebujeme obnovit databázi těsně před tímto časem, 10:59, jak se rozhodneme, a naštěstí děláme denní zálohy, abychom měli zálohu od dnešní půlnoci. Protože nevíme, co všechno bylo zničeno, rozhodli jsme se také provést úplnou obnovu této databáze na našem hostiteli PITR a uvést ji online jako hlavní, protože má stejné hardwarové specifikace jako hlavní, pro případ, že scénář se stal.
Vypnout Master
Vzhledem k tomu, že jsme se rozhodli provést úplnou obnovu ze zálohy a povýšit ji na hlavní, není nutné tuto zálohu uchovávat online. Vypneme ho, ale necháme si ho pro případ, že bychom z něj později pro jistotu něco potřebovali.
Nastavení základní zálohy pro obnovení
Dále na našem hostiteli PITR stáhneme naši nejnovější zálohu základny z doby před událostí, což je záloha ‚2018-12-21_backup‘.
mkdir /var/lib/pgsql/11/data
chmod 700 /var/lib/pgsql/11/data
cd /var/lib/pgsql/11/data
tar -xzvf /mnt/db/backups/2018-12-21_backup/base.tar.gz
cd pg_wal
tar -xzvf /mnt/db/backups/2018-12-21_backup/pg_wal.tar.gz
mkdir /mnt/db/wal_archive/pitr_restore/Díky tomu jsou základní záloha, stejně jako soubory WAL poskytované pg_basebackup, připraveny k použití. Pokud ji nyní zpřístupníme online, obnoví se do bodu, ve kterém záloha proběhla, ale my chceme obnovit všechny transakce WAL mezi půlnoci a 11:59, takže jsme nastavili soubor recovery.conf.
Vytvořit recovery.conf
Vzhledem k tomu, že tato záloha ve skutečnosti pocházela ze streamované repliky, pravděpodobně již existuje soubor recovery.conf s nastavením repliky. Přepíšeme jej novým nastavením. Podrobný seznam informací pro všechny různé možnosti je k dispozici v dokumentaci PostgreSQL zde.
Buďte opatrní se soubory WAL, příkaz restore zkopíruje komprimované soubory, které potřebuje, do adresáře pro obnovu, dekomprimuje je a poté se přesune tam, kde je PostgreSQL potřebuje pro obnovu. Původní soubory WAL zůstanou tam, kde jsou pro případ potřeby z jiných důvodů.
Nové recovery.conf:
recovery_target_time = '2018-12-21 11:59:00-07'
restore_command = 'cp /mnt/db/wal_archive/%f.gz /var/lib/pgsql/test_recovery/pitr_restore/%f.gz && gunzip /var/lib/pgsql/test_recovery/pitr_restore/%f.gz && mv /var/lib/pgsql/test_recovery/pitr_restore/%f "%p"'Spusťte proces obnovy
Nyní, když je vše nastaveno, zahájíme proces obnovy. Když k tomu dojde, je dobré sledovat protokol databáze, abyste se ujistili, že se obnovuje podle plánu.
Spusťte DB:
pg_ctl -D /var/lib/pgsql/11/data startTail the logs:
V protokolu bude mnoho záznamů, které ukazují, že se databáze obnovuje z archivních souborů, a v určitém okamžiku se zobrazí řádek s nápisem „zastavení obnovy před potvrzením transakce…“
2018-12-22 04:21:30 UTC [20565]: [705-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000074" from archive
2018-12-22 04:21:30 UTC [20565]: [706-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000075" from archive
2018-12-22 04:21:31 UTC [20565]: [707-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000076" from archive
2018-12-22 04:21:31 UTC [20565]: [708-1] user=,db=,app=,client= LOG: restored log file "000000010000000400000077" from archive
2018-12-22 04:21:31 UTC [20565]: [709-1] user=,db=,app=,client= LOG: recovery stopping before commit of transaction 611765, time 2018-12-21 11:59:01.45545+07V tomto okamžiku proces obnovy zpracoval všechny soubory WAL, ale také potřebuje kontrolu, než bude online jako hlavní server. V tomto příkladu protokol poznamenává, že další transakce po cílovém čase obnovení 11:59:00 byla 11:59:01 a nebyla obnovena. Chcete-li ověřit, přihlaste se do databáze a podívejte se, že spuštěná databáze by měla být snímek přesně v 11:59.
Když vše vypadá dobře, je čas podpořit obnovu jako mistr.
postgres=# SELECT pg_wal_replay_resume();
pg_wal_replay_resume
----------------------
(1 row)Nyní je databáze online, obnovena do bodu, pro který jsme se rozhodli, a přijímá připojení pro čtení/zápis jako hlavní uzel. Ujistěte se, že všechny konfigurační parametry jsou správné a připravené k výrobě.
Databáze je online, ale proces obnovy ještě není dokončen! Nyní, když je tato záloha PITR online jako hlavní, by měl být nastaven nový pohotovostní režim a nastavení PITR, do té doby může být tento nový hlavní server online a obsluhovat aplikace, ale není v bezpečí před další katastrofou, dokud to nebude znovu nastaveno.
Další scénáře obnovy v čase
Obnovení zálohy PITR pro celou databázi je extrémní případ, ale existují i jiné scénáře, kdy chybí, je poškozená nebo špatná pouze podmnožina dat. V těchto případech můžeme být kreativní s našimi možnostmi obnovy. Bez přepnutí hlavního serveru do režimu offline a jeho nahrazení zálohou můžeme zálohu PITR přenést do režimu online přesně v požadovaný čas na jiném hostiteli (nebo na jiném portu, pokud není problém s místem), a exportovat obnovená data ze zálohy přímo. do hlavní databáze. To lze použít k obnovení několika řádků, několika tabulek nebo jakékoli potřebné konfigurace dat.
Díky streamingové replikaci a Point In Time Recovery nám PostgreSQL poskytuje velkou flexibilitu, pokud jde o zajištění toho, že můžeme obnovit jakákoli data, která potřebujeme, pokud máme pohotovostní hostitele připravené k použití jako hlavní nebo zálohy připravené k obnově. Dobrá možnost zotavení po havárii může být dále rozšířena o další možnosti zálohování, více uzlů replik, více míst zálohování napříč různými datovými centry a kontinenty, pravidelné pg_dumps na jiné replice atd.
Tyto možnosti se mohou sčítat, ale skutečnou otázkou je, „jak cenná jsou data a kolik jste ochotni utratit, abyste je získali zpět?“. V mnoha případech je ztráta dat konec podnikání, takže by měly být k dispozici dobré možnosti zotavení po havárii, aby se předešlo nejhoršímu.