Historicky nejtěžším úkolem při práci s PostgreSQL bylo řešení upgradů. Nejintuitivnějším způsobem upgradu, který si můžete představit, je vygenerovat repliku v nové verzi a provést do ní převzetí aplikace při selhání. S PostgreSQL to prostě nebylo možné nativním způsobem. Chcete-li provést upgrady, museli jste přemýšlet o jiných způsobech upgradu, jako je použití pg_upgrade, dumping a obnovení nebo použití některých nástrojů třetích stran, jako je Slony nebo Bucardo, všechny mají své vlastní výhrady.
proč to bylo? Kvůli způsobu, jakým PostgreSQL implementuje replikaci.
Vestavěná streamingová replikace PostgreSQL se nazývá fyzická:bude replikovat změny na úrovni bajtu po bajtu, čímž vytvoří identickou kopii databáze na jiném serveru. Tato metoda má mnoho omezení, když uvažujete o upgradu, protože jednoduše nemůžete vytvořit repliku v jiné verzi serveru nebo dokonce v jiné architektuře.
Zde se tedy PostgreSQL 10 stává změnou hry. S těmito novými verzemi 10 a 11 PostgreSQL implementuje vestavěnou logickou replikaci, kterou na rozdíl od fyzické replikace můžete replikovat mezi různými hlavními verzemi PostgreSQL. To samozřejmě otevírá nové dveře pro upgradování strategií.
V tomto blogu se podíváme, jak můžeme upgradovat náš PostgreSQL 10 na PostgreSQL 11 s nulovými prostoji pomocí logické replikace. Nejprve si projdeme úvod do logické replikace.
Co je logická replikace?
Logická replikace je metoda replikace datových objektů a jejich změn na základě jejich replikační identity (obvykle primární klíč). Je založen na režimu publikování a odběru, kde jeden nebo více odběratelů odebírá jednu nebo více publikací v uzlu vydavatele.
Publikace je sada změn generovaných z tabulky nebo skupiny tabulek (také označované jako replikační sada). Uzel, kde je definována publikace, se nazývá vydavatel. Předplatné je následnou stranou logické replikace. Uzel, kde je definováno předplatné, se označuje jako předplatitel a definuje připojení k jiné databázi a sadě publikací (jedné nebo více), ke kterým se chce přihlásit. Předplatitelé získávají data z publikací, které odebírají.
Logická replikace je postavena na architektuře podobné replikaci fyzického streamování. Je implementován procesy „walsender“ a „apply“. Proces walsender spustí logické dekódování WAL a načte standardní plugin pro logické dekódování. Plugin transformuje změny načtené z WAL do protokolu logické replikace a filtruje data podle specifikace publikace. Data jsou pak nepřetržitě přenášena pomocí streamingového replikačního protokolu k aplikačnímu pracovníkovi, který mapuje data do lokálních tabulek a aplikuje jednotlivé změny tak, jak jsou přijímány, ve správném transakčním pořadí.
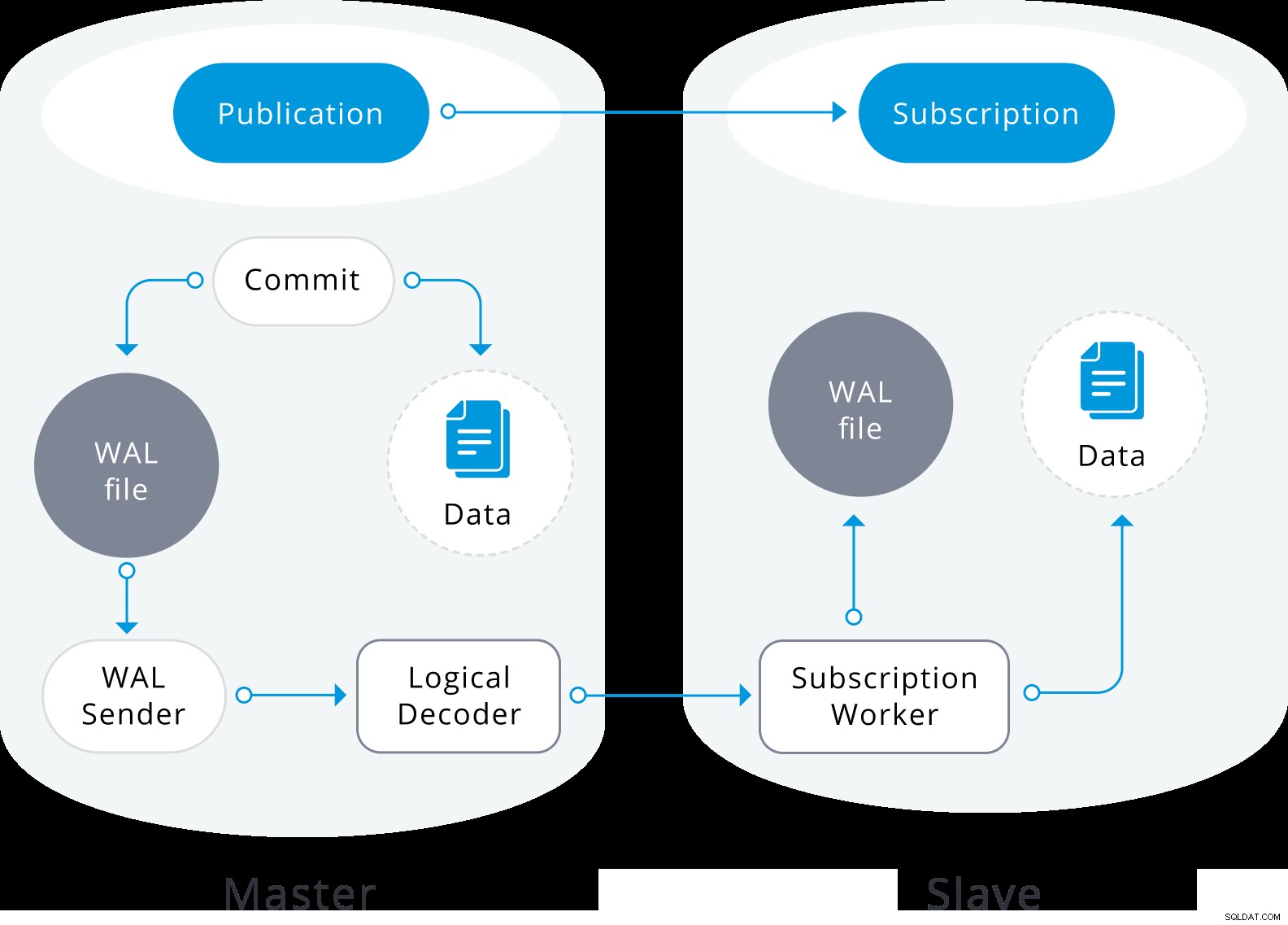 Diagram logické replikace
Diagram logické replikace Logická replikace začíná pořízením snímku dat v databázi vydavatele a zkopírováním těchto dat odběrateli. Počáteční data v existujících odebíraných tabulkách jsou zachycována a zkopírována v paralelní instanci speciálního druhu aplikačního procesu. Tento proces vytvoří svůj vlastní dočasný replikační slot a zkopíruje existující data. Jakmile jsou existující data zkopírována, pracovník přejde do režimu synchronizace, který zajistí, že tabulka bude uvedena do synchronizovaného stavu s hlavním procesem aplikace streamováním jakýchkoli změn, ke kterým došlo během počátečního kopírování dat, pomocí standardní logické replikace. Po dokončení synchronizace je řízení replikace tabulky předáno zpět hlavnímu procesu aplikace, kde replikace pokračuje jako obvykle. Změny ve vydavateli jsou odesílány odběrateli tak, jak k nim dochází v reálném čase.
Více o logické replikaci naleznete v následujících blozích:
- Přehled logické replikace v PostgreSQL
- PostgreSQL Streaming Replication versus Logical Replication
Jak upgradovat PostgreSQL 10 na PostgreSQL 11 pomocí logické replikace
Takže, když už víme, o čem tato nová funkce je, můžeme přemýšlet o tom, jak ji využít k vyřešení problému s upgradem.
Chystáme se nakonfigurovat logickou replikaci mezi dvěma různými hlavními verzemi PostgreSQL (10 a 11) a samozřejmě poté, co toto zprovozníte, je pouze otázkou provedení převzetí služeb při selhání do databáze s novější verzí.
Pro zprovoznění logické replikace provedeme následující kroky:
- Nakonfigurujte uzel vydavatele
- Nakonfigurujte uzel odběratele
- Vytvořte uživatele odběratele
- Vytvořte publikaci
- Vytvořte strukturu tabulky v odběrateli
- Vytvořte odběr
- Zkontrolujte stav replikace
Takže začneme.
Na straně vydavatele se chystáme nakonfigurovat následující parametry v souboru postgresql.conf:
- listen_addresses:Jakou IP adresu(y) poslouchat. Pro všechny budeme používat '*'.
- wal_level:Určuje, kolik informací se zapisuje do WAL. Nastavíme to na logické.
- max_replication_slots:Určuje maximální počet replikačních slotů, které může server podporovat. Musí být nastaveno alespoň na počet předplatných, které se mají připojit, plus určitou rezervu pro synchronizaci tabulek.
- max_wal_senders:Určuje maximální počet souběžných připojení ze serverů v pohotovostním režimu nebo ze základních zálohovacích klientů streamování. Mělo by být nastaveno alespoň na stejnou hodnotu jako max_replication_slots plus počet fyzických replik, které jsou připojeny ve stejnou dobu.
Mějte na paměti, že některé z těchto parametrů vyžadovaly restart služby PostgreSQL.
Soubor pg_hba.conf je také potřeba upravit, aby umožňoval replikaci. Musíme umožnit uživateli replikace připojit se k databázi.
Na základě toho tedy nakonfigurujeme našeho vydavatele (v tomto případě náš server PostgreSQL 10) takto:
- postgresql.conf:
listen_addresses = '*' wal_level = logical max_wal_senders = 8 max_replication_slots = 4 - pg_hba.conf:
# TYPE DATABASE USER ADDRESS METHOD host all rep 192.168.100.144/32 md5
Musíme změnit uživatele (v našem příkladu zástupce), který bude použit pro replikaci, a IP adresu 192.168.100.144/32 pro IP, která odpovídá našemu PostgreSQL 11.
Na straně předplatitele také vyžaduje nastavení max_replication_slots. V tomto případě by měl být nastaven alespoň na počet předplatných, které budou přidány k předplatiteli.
Další parametry, které je zde také potřeba nastavit, jsou:
- max_logical_replication_workers:Určuje maximální počet pracovníků logické replikace. To zahrnuje jak pracovníky aplikací, tak pracovníky synchronizace tabulek. Pracovníci logické replikace jsou přebíráni z fondu definovaného pomocí max_worker_processes. Musí být nastaven alespoň na počet odběrů, opět plus nějaká rezerva na synchronizaci tabulky.
- max_worker_processes:Nastavuje maximální počet procesů na pozadí, které může systém podporovat. Možná bude nutné jej upravit, aby vyhovoval pracovníkům replikace, alespoň max_logical_replication_workers + 1. Tento parametr vyžaduje restart PostgreSQL.
Musíme tedy nakonfigurovat našeho předplatitele (v tomto případě náš server PostgreSQL 11) následovně:
- postgresql.conf:
listen_addresses = '*' max_replication_slots = 4 max_logical_replication_workers = 4 max_worker_processes = 8
Protože tento PostgreSQL 11 bude brzy naším novým masterem, měli bychom v tomto kroku zvážit přidání parametrů wal_level a archive_mode, abychom se později vyhnuli novému restartu služby.
wal_level = logical
archive_mode = onTyto parametry budou užitečné, pokud chceme přidat nového replikačního slave zařízení nebo pro použití záloh PITR.
Ve vydavateli musíme vytvořit uživatele, se kterým se náš odběratel spojí:
world=# CREATE ROLE rep WITH LOGIN PASSWORD '*****' REPLICATION;
CREATE ROLERole použitá pro připojení replikace musí mít atribut REPLICATION. Přístup pro roli musí být nakonfigurován v pg_hba.conf a musí mít atribut LOGIN.
Aby bylo možné zkopírovat počáteční data, musí mít role použitá pro připojení replikace oprávnění SELECT pro publikovanou tabulku.
world=# GRANT SELECT ON ALL TABLES IN SCHEMA public to rep;
GRANTV uzlu vydavatele vytvoříme publikaci pub1 pro všechny tabulky:
world=# CREATE PUBLICATION pub1 FOR ALL TABLES;
CREATE PUBLICATIONUživatel, který vytvoří publikaci, musí mít v databázi oprávnění CREATE, ale pro vytvoření publikace, která publikuje všechny tabulky automaticky, musí být uživatel superuživatel.
Pro potvrzení vytvořené publikace použijeme katalog pg_publication. Tento katalog obsahuje informace o všech publikacích vytvořených v databázi.
world=# SELECT * FROM pg_publication;
-[ RECORD 1 ]+------
pubname | pub1
pubowner | 16384
puballtables | t
pubinsert | t
pubupdate | t
pubdelete | tPopisy sloupců:
- pubname:Název publikace.
- pubowner:Vlastník publikace.
- puballtables:Pokud je true, tato publikace automaticky zahrnuje všechny tabulky v databázi, včetně všech, které budou vytvořeny v budoucnu.
- pubinsert:Pokud je true, operace INSERT se replikují pro tabulky v publikaci.
- pubupdate:Pokud je true, operace UPDATE jsou replikovány pro tabulky v publikaci.
- pubdelete:Pokud je true, operace DELETE se replikují pro tabulky v publikaci.
Protože schéma není replikováno, musíme provést zálohu v PostgreSQL 10 a obnovit ji v našem PostgreSQL 11. Záloha bude provedena pouze pro schéma, protože informace budou replikovány při prvním přenosu.
V PostgreSQL 10:
$ pg_dumpall -s > schema.sqlV PostgreSQL 11:
$ psql -d postgres -f schema.sqlJakmile máme naše schéma v PostgreSQL 11, vytvoříme předplatné a nahradíme hodnoty hostitele, dbname, uživatele a hesla těmi, které odpovídají našemu prostředí.
PostgreSQL 11:
world=# CREATE SUBSCRIPTION sub1 CONNECTION 'host=192.168.100.143 dbname=world user=rep password=*****' PUBLICATION pub1;
NOTICE: created replication slot "sub1" on publisher
CREATE SUBSCRIPTIONVýše uvedené spustí proces replikace, který synchronizuje počáteční obsah tabulek tabulek v publikaci a poté začne replikovat přírůstkové změny těchto tabulek.
Uživatel vytvářející předplatné musí být superuživatel. Proces použití předplatného bude spuštěn v místní databázi s oprávněními superuživatele.
Pro ověření vytvořeného předplatného pak můžeme použít katalog pg_stat_subscription. Toto zobrazení bude obsahovat jeden řádek na předplatné pro hlavního pracovníka (s nulovým PID, pokud pracovník není spuštěn) a další řádky pro pracovníky zpracovávající počáteční kopii dat přihlášených tabulek.
world=# SELECT * FROM pg_stat_subscription;
-[ RECORD 1 ]---------+------------------------------
subid | 16428
subname | sub1
pid | 1111
relid |
received_lsn | 0/172AF90
last_msg_send_time | 2018-12-05 22:11:45.195963+00
last_msg_receipt_time | 2018-12-05 22:11:45.196065+00
latest_end_lsn | 0/172AF90
latest_end_time | 2018-12-05 22:11:45.195963+00Popisy sloupců:
- subid:OID předplatného.
- subname:Název předplatného.
- pid:ID procesu pracovního procesu předplatného.
- relid:OID vztahu, který pracovník synchronizuje; null pro hlavního aplikačního pracovníka.
- received_lsn:Bylo přijato místo posledního zápisu do protokolu, počáteční hodnota tohoto pole je 0.
- last_msg_send_time:Čas odeslání poslední zprávy přijaté od původního odesílatele WAL.
- last_msg_receipt_time:Čas přijetí poslední zprávy přijaté od původního odesílatele WAL.
- latest_end_lsn:Poslední umístění protokolu napřed nahlášené původnímu odesílateli WAL.
- latest_end_time:Čas posledního umístění protokolu napřed nahlášené původnímu odesílateli WAL.
Pro ověření stavu replikace v masteru můžeme použít pg_stat_replication:
world=# SELECT * FROM pg_stat_replication;
-[ RECORD 1 ]----+------------------------------
pid | 1178
usesysid | 16427
usename | rep
application_name | sub1
client_addr | 192.168.100.144
client_hostname |
client_port | 58270
backend_start | 2018-12-05 22:11:45.097539+00
backend_xmin |
state | streaming
sent_lsn | 0/172AF90
write_lsn | 0/172AF90
flush_lsn | 0/172AF90
replay_lsn | 0/172AF90
write_lag |
flush_lag |
replay_lag |
sync_priority | 0
sync_state | asyncPopisy sloupců:
- pid:ID procesu procesu odesílatele WAL.
- usesysid:OID uživatele přihlášeného k tomuto procesu odesílatele WAL.
- usename:Jméno uživatele přihlášeného k tomuto procesu odesílatele WAL.
- název_aplikace:Název aplikace, která je připojena k tomuto odesílateli WAL.
- client_addr:IP adresa klienta připojeného k tomuto odesílateli WAL. Pokud je toto pole prázdné, znamená to, že klient je připojen prostřednictvím Unixového soketu na serveru.
- název_hostitele_klienta:Název hostitele připojeného klienta, jak je hlášeno zpětným vyhledáváním DNS adresy client_addr. Toto pole nebude mít hodnotu null pouze pro připojení IP a pouze v případě, že je povoleno log_hostname.
- client_port:Číslo portu TCP, který klient používá pro komunikaci s tímto odesílatelem WAL, nebo -1, pokud je použit soket Unix.
- backend_start:Čas, kdy byl tento proces zahájen.
- backend_xmin:Horizont xmin tohoto pohotovostního režimu hlášený službou hot_standby_feedback.
- stav:Aktuální stav odesílatele WAL. Možné hodnoty jsou:startup, catchup, streaming, backup and stopping.
- sent_lsn:Poslední umístění protokolu pro zápis napřed odeslané při tomto připojení.
- write_lsn:Poslední umístění protokolu napřed zapsané na disk tímto pohotovostním serverem.
- flush_lsn:Poslední umístění protokolu napřed vyprázdněno na disk tímto pohotovostním serverem.
- replay_lsn:Umístění protokolu posledního zápisu napřed přehráno do databáze na tomto pohotovostním serveru.
- write_lag:Doba, která uplynula mezi místním vyprázdněním poslední WAL a přijetím upozornění, že ji tento pohotovostní server zapsal (ale ještě ji nevyprázdnil ani neaplikoval).
- flush_lag:Čas, který uplynul mezi místním vyprázdněním poslední WAL a přijetím upozornění, že tento pohotovostní server ji zapsal a vyprázdnil (ale ještě ji nepoužil).
- replay_lag:Čas, který uplynul mezi místním vyprázdněním poslední WAL a přijetím upozornění, že tento pohotovostní server ji zapsal, vyprázdnil a použil.
- sync_priority:Priorita tohoto pohotovostního serveru pro výběr jako synchronního pohotovostního režimu v synchronní replikaci založené na prioritách.
- sync_state:Synchronní stav tohoto pohotovostního serveru. Možné hodnoty jsou async, potential, sync, quorum.
Abychom si ověřili, kdy je počáteční přenos dokončen, můžeme vidět protokol PostgreSQL na předplatiteli:
2018-12-05 22:11:45.096 UTC [1111] LOG: logical replication apply worker for subscription "sub1" has started
2018-12-05 22:11:45.103 UTC [1112] LOG: logical replication table synchronization worker for subscription "sub1", table "city" has started
2018-12-05 22:11:45.114 UTC [1113] LOG: logical replication table synchronization worker for subscription "sub1", table "country" has started
2018-12-05 22:11:45.156 UTC [1112] LOG: logical replication table synchronization worker for subscription "sub1", table "city" has finished
2018-12-05 22:11:45.162 UTC [1114] LOG: logical replication table synchronization worker for subscription "sub1", table "countrylanguage" has started
2018-12-05 22:11:45.168 UTC [1113] LOG: logical replication table synchronization worker for subscription "sub1", table "country" has finished
2018-12-05 22:11:45.206 UTC [1114] LOG: logical replication table synchronization worker for subscription "sub1", table "countrylanguage" has finishedNebo kontrola proměnné srsubstate v katalogu pg_subscription_rel. Tento katalog obsahuje stav pro každý replikovaný vztah v každém předplatném.
world=# SELECT * FROM pg_subscription_rel;
-[ RECORD 1 ]---------
srsubid | 16428
srrelid | 16387
srsubstate | r
srsublsn | 0/172AF20
-[ RECORD 2 ]---------
srsubid | 16428
srrelid | 16393
srsubstate | r
srsublsn | 0/172AF58
-[ RECORD 3 ]---------
srsubid | 16428
srrelid | 16400
srsubstate | r
srsublsn | 0/172AF90Popisy sloupců:
- srsubid:Odkaz na předplatné.
- srrelid:Odkaz na vztah.
- srsubstate:Stavový kód:i =inicializovat, d =data se kopírují, s =synchronizována, r =připraveno (normální replikace).
- srsublsn:Ukončení LSN pro stavy sar.
Můžeme vložit nějaké testovací záznamy do našeho PostgreSQL 10 a ověřit, že je máme v našem PostgreSQL 11:
PostgreSQL 10:
world=# INSERT INTO city (id,name,countrycode,district,population) VALUES (5001,'city1','USA','District1',10000);
INSERT 0 1
world=# INSERT INTO city (id,name,countrycode,district,population) VALUES (5002,'city2','ITA','District2',20000);
INSERT 0 1
world=# INSERT INTO city (id,name,countrycode,district,population) VALUES (5003,'city3','CHN','District3',30000);
INSERT 0 1PostgreSQL 11:
world=# SELECT * FROM city WHERE id>5000;
id | name | countrycode | district | population
------+-------+-------------+-----------+------------
5001 | city1 | USA | District1 | 10000
5002 | city2 | ITA | District2 | 20000
5003 | city3 | CHN | District3 | 30000
(3 rows)V tuto chvíli máme vše připraveno, abychom naši aplikaci nasměrovali na náš PostgreSQL 11.
Za tímto účelem musíme nejprve potvrdit, že nemáme zpoždění replikace.
Na hlavní:
world=# SELECT application_name, pg_wal_lsn_diff(pg_current_wal_lsn(), replay_lsn) lag FROM pg_stat_replication;
-[ RECORD 1 ]----+-----
application_name | sub1
lag | 0A nyní potřebujeme pouze změnit náš koncový bod z naší aplikace nebo nástroje pro vyrovnávání zatížení (pokud jej máme) na nový server PostgreSQL 11.
Pokud máme load balancer, jako je HAProxy, můžeme jej nakonfigurovat pomocí PostgreSQL 10 jako aktivního a PostgreSQL 11 jako záložního, a to tímto způsobem:
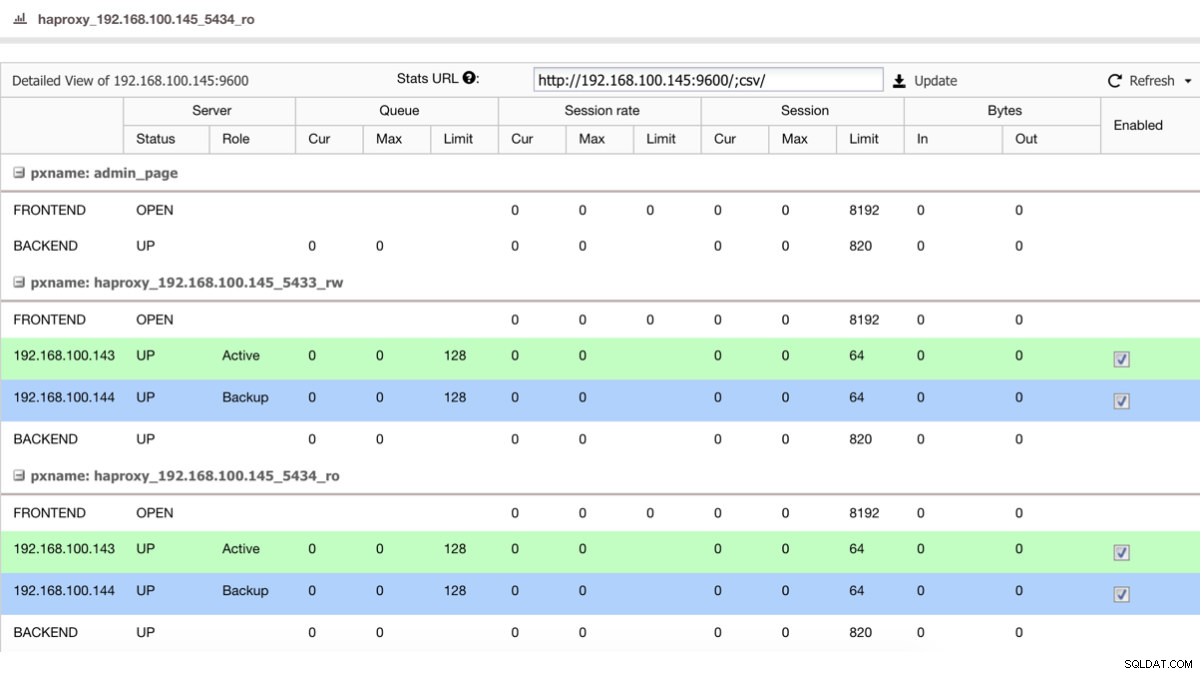 Zobrazení stavu HAProxy
Zobrazení stavu HAProxy Pokud tedy právě vypnete hlavní server v PostgreSQL 10, záložní server, v tomto případě v PostgreSQL 11, začne přijímat provoz transparentním způsobem pro uživatele/aplikaci.
Na konci migrace můžeme smazat předplatné v našem novém masteru v PostgreSQL 11:
world=# DROP SUBSCRIPTION sub1;
NOTICE: dropped replication slot "sub1" on publisher
DROP SUBSCRIPTIONA ověřte, zda je správně odstraněn:
world=# SELECT * FROM pg_subscription_rel;
(0 rows)
world=# SELECT * FROM pg_stat_subscription;
(0 rows)Omezení
Před použitím logické replikace mějte na paměti následující omezení:
- Schéma databáze a příkazy DDL nejsou replikovány. Počáteční schéma lze zkopírovat pomocí pg_dump --schema-only.
- Sekvenční data nejsou replikována. Data v sériových nebo identifikačních sloupcích podporovaná sekvencemi budou replikována jako součást tabulky, ale samotná sekvence bude stále zobrazovat počáteční hodnotu na odběrateli.
- Replikace příkazů TRUNCATE je podporována, ale při ořezávání skupin tabulek spojených cizími klíči je třeba věnovat určitou pozornost. Při replikaci akce zkrácení předplatitel zkrátí stejnou skupinu tabulek, která byla zkrácena na vydavateli, buď explicitně zadaná, nebo implicitně shromážděná prostřednictvím CASCADE, mínus tabulky, které nejsou součástí předplatného. To bude fungovat správně, pokud jsou všechny ovlivněné tabulky součástí stejného předplatného. Pokud však některé tabulky, které mají být zkráceny na odběrateli, mají odkazy s cizím klíčem na tabulky, které nejsou součástí stejného (nebo jakéhokoli) předplatného, pak aplikace akce zkrácení na odběratele selže.
- Velké objekty se nereplikují. Neexistuje žádné jiné řešení, než ukládání dat do normálních tabulek.
- Replikace je možná pouze ze základních tabulek na základní tabulky. To znamená, že tabulky na publikaci a na straně předplatného musí být normální tabulky, nikoli pohledy, materializované pohledy, kořenové tabulky oddílů nebo cizí tabulky. V případě diskových oddílů můžete replikovat hierarchii oddílů jedna ku jedné, ale aktuálně ji nelze replikovat do jinak rozděleného nastavení.
Závěr
Udržování vašeho PostgreSQL serveru v aktuálním stavu prováděním pravidelných upgradů bylo nezbytným, ale obtížným úkolem až do verze PostgreSQL 10.
V tomto blogu jsme krátce představili logickou replikaci, funkci PostgreSQL zavedenou nativně ve verzi 10, a ukázali jsme vám, jak vám může pomoci splnit tuto výzvu se strategií nulových prostojů.