V dnešní době je běžné vidět velké množství dat v databázi společnosti, ale v závislosti na velikosti může být obtížné ji spravovat a výkon může být ovlivněn při vysokém provozu, pokud ji nenakonfigurujeme nebo neimplementujeme správným způsobem. . Obecně platí, že pokud máme obrovskou databázi a chceme mít nízkou dobu odezvy, budeme ji chtít škálovat. PostgreSQL není v tomto bodě výjimkou. Existuje mnoho dostupných přístupů ke škálování PostgreSQL, ale nejprve se podívejme, co je to škálování.
Škálovatelnost je vlastnost systému/databáze zvládat rostoucí množství požadavků přidáním zdrojů.
Důvody tohoto množství požadavků mohou být dočasné, například pokud spouštíme slevu na výprodej, nebo trvalé, pro nárůst zákazníků nebo zaměstnanců. V každém případě bychom měli být schopni přidávat nebo odebírat zdroje pro řízení těchto změn podle požadavků nebo nárůstu provozu.
V tomto blogu se podíváme na to, jak můžeme škálovat naši databázi PostgreSQL a kdy to potřebujeme udělat.
Horizontální měřítko vs. Vertikální měřítko
Existují dva hlavní způsoby, jak škálovat naši databázi...
- Horizontální škálování (scale-out):Provádí se přidáním více databázových uzlů vytvářejících nebo zvětšujících databázový cluster.
- Vertikální škálování (scale-up):Provádí se přidáním dalších hardwarových prostředků (CPU, paměť, disk) do existujícího databázového uzlu.
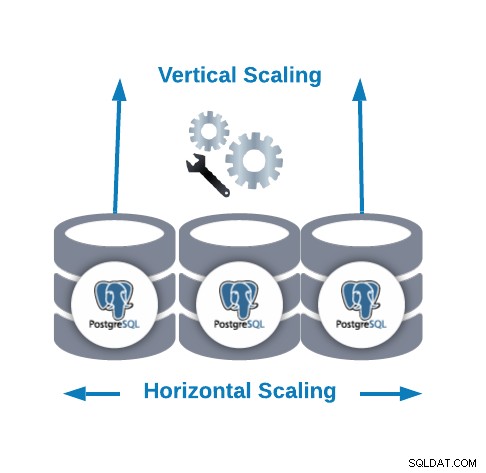
Pro horizontální škálování můžeme přidat další databázové uzly jako podřízené uzly. Může nám to pomoci zlepšit výkon čtení vyvažující provoz mezi uzly. V tomto případě budeme muset přidat nástroj pro vyrovnávání zatížení, který distribuuje provoz do správného uzlu v závislosti na zásadách a stavu uzlu.
Abychom se vyhnuli jedinému bodu selhání přidáním pouze jednoho nástroje pro vyrovnávání zatížení, měli bychom zvážit přidání dvou nebo více uzlů nástroje pro vyrovnávání zatížení a použití nějakého nástroje, jako je „Keepalived“, abychom zajistili dostupnost.
Protože PostgreSQL nemá nativní podporu pro více masterů, pokud jej chceme implementovat pro zlepšení výkonu zápisu, budeme pro tento úkol muset použít externí nástroj.
Pro vertikální škálování může být potřeba změnit některý konfigurační parametr, aby PostgreSQL umožnil používat nový nebo lepší hardwarový prostředek. Podívejme se na některé z těchto parametrů z dokumentace PostgreSQL.
- work_mem:Určuje množství paměti, které bude využito interními operacemi řazení a hashovacími tabulkami před zápisem do dočasných souborů na disku. Několik běžících relací může provádět takové operace současně, takže celková použitá paměť může být mnohonásobkem hodnoty work_mem.
- maintenance_work_mem:Určuje maximální množství paměti, které bude využito operacemi údržby, jako je VACUUM, CREATE INDEX a ALTER TABLE ADD FOREIGN KEY. Větší nastavení může zlepšit výkon vysávání a obnovy výpisů databáze.
- autovacuum_work_mem:Určuje maximální množství paměti, které může použít každý pracovní proces autovacuum.
- autovacuum_max_workers:Určuje maximální počet procesů autovakuování, které mohou být spuštěny najednou.
- max_worker_processes:Nastavuje maximální počet procesů na pozadí, které může systém podporovat. Zadejte limit procesu, jako je vysávání, kontrolní body a další úlohy údržby.
- max_parallel_workers:Nastavuje maximální počet pracovníků, které může systém podporovat pro paralelní operace. Paralelní pracovníci jsou přebíráni ze skupiny pracovních procesů vytvořených předchozím parametrem.
- max_parallel_maintenance_workers:Nastavuje maximální počet paralelních pracovníků, které lze spustit jediným příkazem nástroje. V současnosti je jediným příkazem paralelního nástroje, který podporuje použití paralelních pracovníků, CREATE INDEX, a to pouze při vytváření indexu B-stromu.
- effective_cache_size:Nastavuje předpoklad plánovače o efektivní velikosti mezipaměti disku, která je k dispozici pro jeden dotaz. To je zohledněno v odhadech nákladů na použití indexu; vyšší hodnota zvyšuje pravděpodobnost použití indexových skenů, nižší hodnota zvyšuje pravděpodobnost použití sekvenčního skenování.
- shared_buffers:Nastavuje množství paměti, kterou databázový server používá pro vyrovnávací paměti sdílené paměti. Pro dobrý výkon je obvykle potřeba nastavení výrazně vyšší než minimum.
- temp_buffers:Nastavuje maximální počet dočasných vyrovnávacích pamětí používaných každou relací databáze. Jedná se o místní vyrovnávací paměti používané pouze pro přístup k dočasným tabulkám.
- effective_io_concurrency:Nastavuje počet souběžných diskových I/O operací, které PostgreSQL očekává, že mohou být provedeny současně. Zvýšením této hodnoty se zvýší počet I/O operací, které se jakákoli jednotlivá relace PostgreSQL pokusí spustit paralelně. V současnosti toto nastavení ovlivňuje pouze skenování haldy bitmap.
- max_connections:Určuje maximální počet souběžných připojení k databázovému serveru. Zvýšení tohoto parametru umožňuje PostgreSQL spouštět více backendových procesů současně.
V tomto okamžiku je zde otázka, kterou si musíme položit. Jak můžeme vědět, zda potřebujeme škálovat naši databázi a jak můžeme vědět, jak to nejlépe udělat?
Monitorování
Škálování naší PostgreSQL databáze je složitý proces, takže bychom měli zkontrolovat některé metriky, abychom mohli určit nejlepší strategii pro její škálování.
Můžeme monitorovat využití CPU, paměti a disku, abychom zjistili, zda došlo k nějakému problému s konfigurací, nebo zda skutečně potřebujeme naši databázi škálovat. Pokud například zaznamenáváme vysoké zatížení serveru, ale aktivita databáze je nízká, pravděpodobně není nutné ji škálovat, musíme pouze zkontrolovat konfigurační parametry, aby odpovídaly našim hardwarovým zdrojům.
Kontrola diskového prostoru používaného uzlem PostgreSQL na databázi nám může pomoci potvrdit, zda potřebujeme více disku nebo dokonce rozdělení tabulky. Ke kontrole místa na disku používaném databází/tabulkou můžeme použít nějakou funkci PostgreSQL jako pg_database_size nebo pg_table_size.
Ze strany databáze bychom měli zkontrolovat
- Počet připojení
- Spouštění dotazů
- Využití indexu
- Nadýmání
- Prodleva replikace
Mohou to být jasné metriky pro potvrzení, zda je potřeba škálování naší databáze.
ClusterControl jako škálovací a monitorovací systém
ClusterControl nám může pomoci vyrovnat se s oběma způsoby škálování, které jsme viděli dříve, a sledovat všechny potřebné metriky k potvrzení požadavku škálování. Podívejme se, jak...
Pokud ClusterControl ještě nepoužíváte, můžete jej nainstalovat a nasadit nebo importovat svou aktuální databázi PostgreSQL výběrem možnosti „Importovat“ a postupujte podle pokynů, abyste mohli využít všechny funkce ClusterControl, jako jsou zálohy, automatické přepnutí při selhání, výstrahy, monitorování, a další.
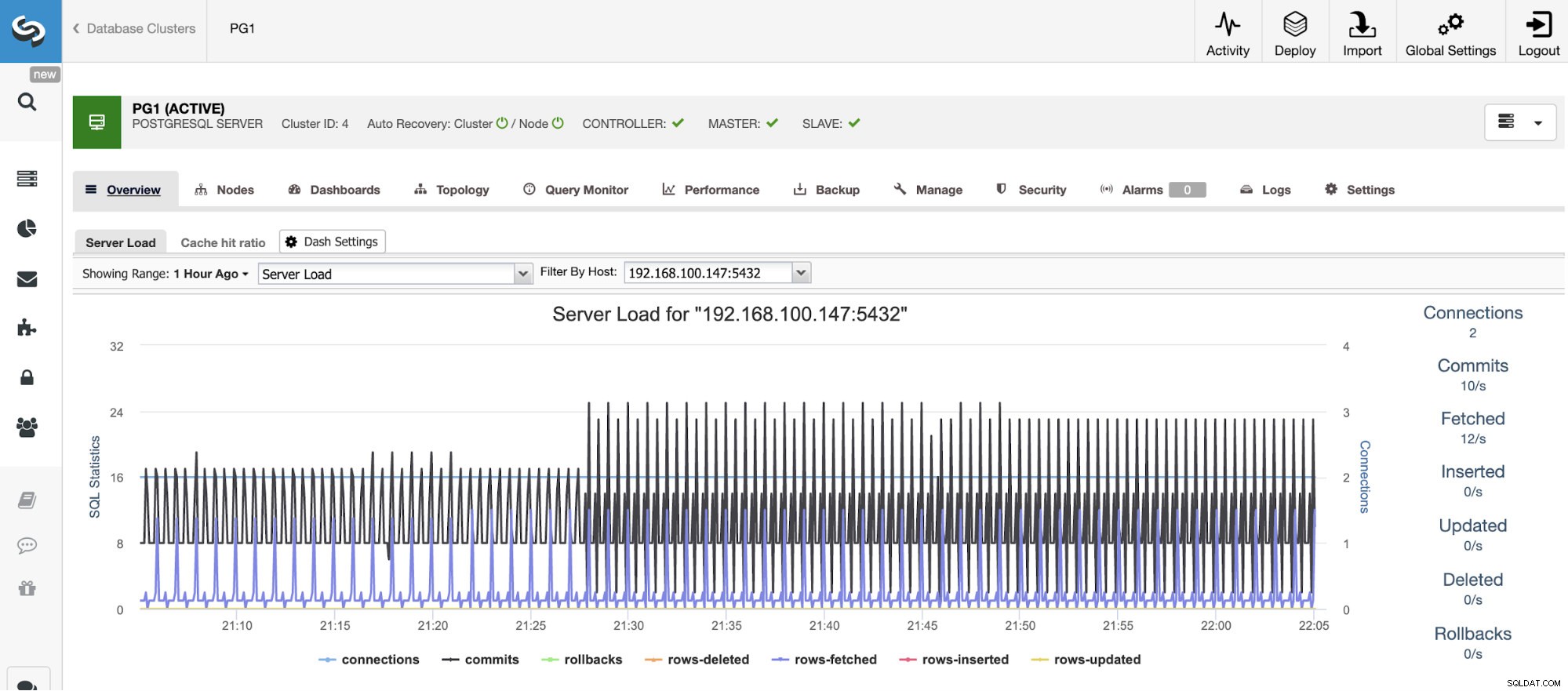
Horizontální měřítko
Pro horizontální škálování, pokud přejdeme na akce clusteru a vybereme „Add Replication Slave“, můžeme buď vytvořit novou repliku od začátku, nebo přidat existující databázi PostgreSQL jako repliku.
Podívejme se, jak může být přidání nového replikačního slave skutečně snadným úkolem.
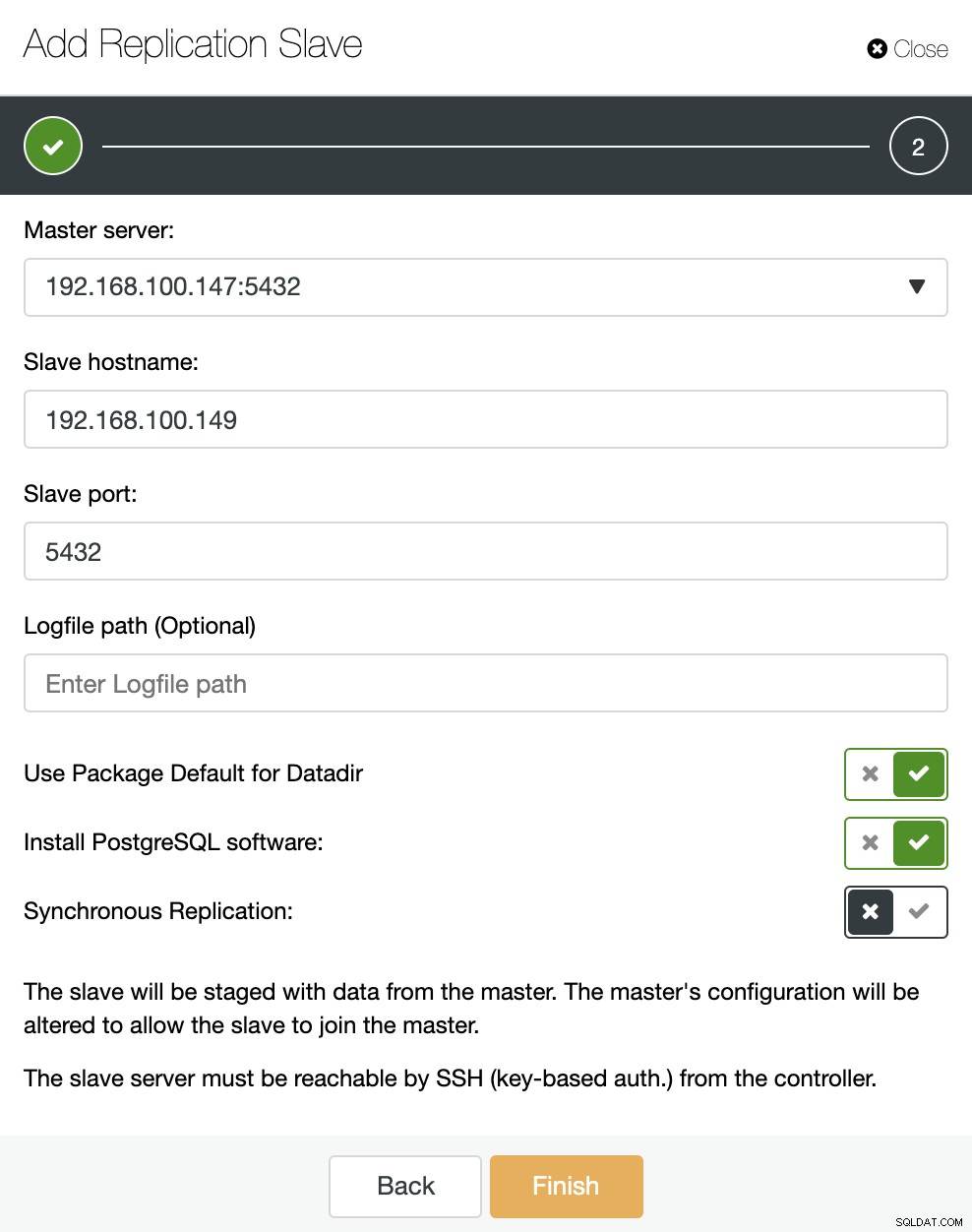
Jak můžete vidět na obrázku, stačí si vybrat náš hlavní server, zadat IP adresu našeho nového podřízeného serveru a port databáze. Poté si můžeme vybrat, zda chceme, aby ClusterControl nainstaloval software za nás a zda má být replikační slave synchronní nebo asynchronní.
Tímto způsobem můžeme přidat tolik replik, kolik chceme, a rozložit mezi ně provoz čtení pomocí nástroje pro vyrovnávání zatížení, který můžeme implementovat také pomocí ClusterControl.
Pokud nyní přejdeme na akce clusteru a vybereme „Přidat nástroj pro vyrovnávání zatížení“, můžeme nasadit nový nástroj pro vyrovnávání zatížení HAProxy nebo přidat existující.
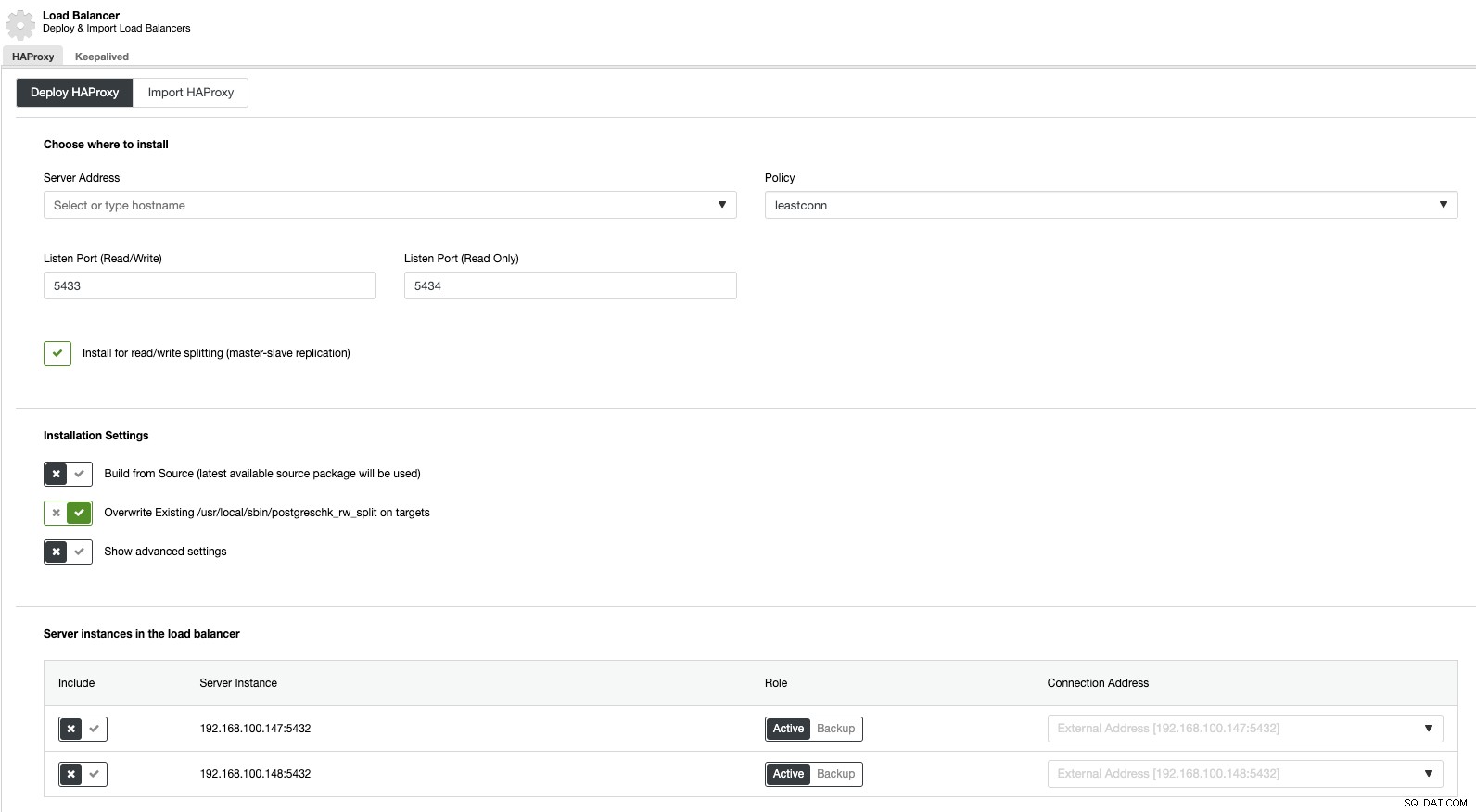
A pak ve stejné sekci nástroje pro vyrovnávání zatížení můžeme přidat službu Keepalived běžící na uzlech nástroje pro vyrovnávání zatížení pro zlepšení našeho prostředí s vysokou dostupností.
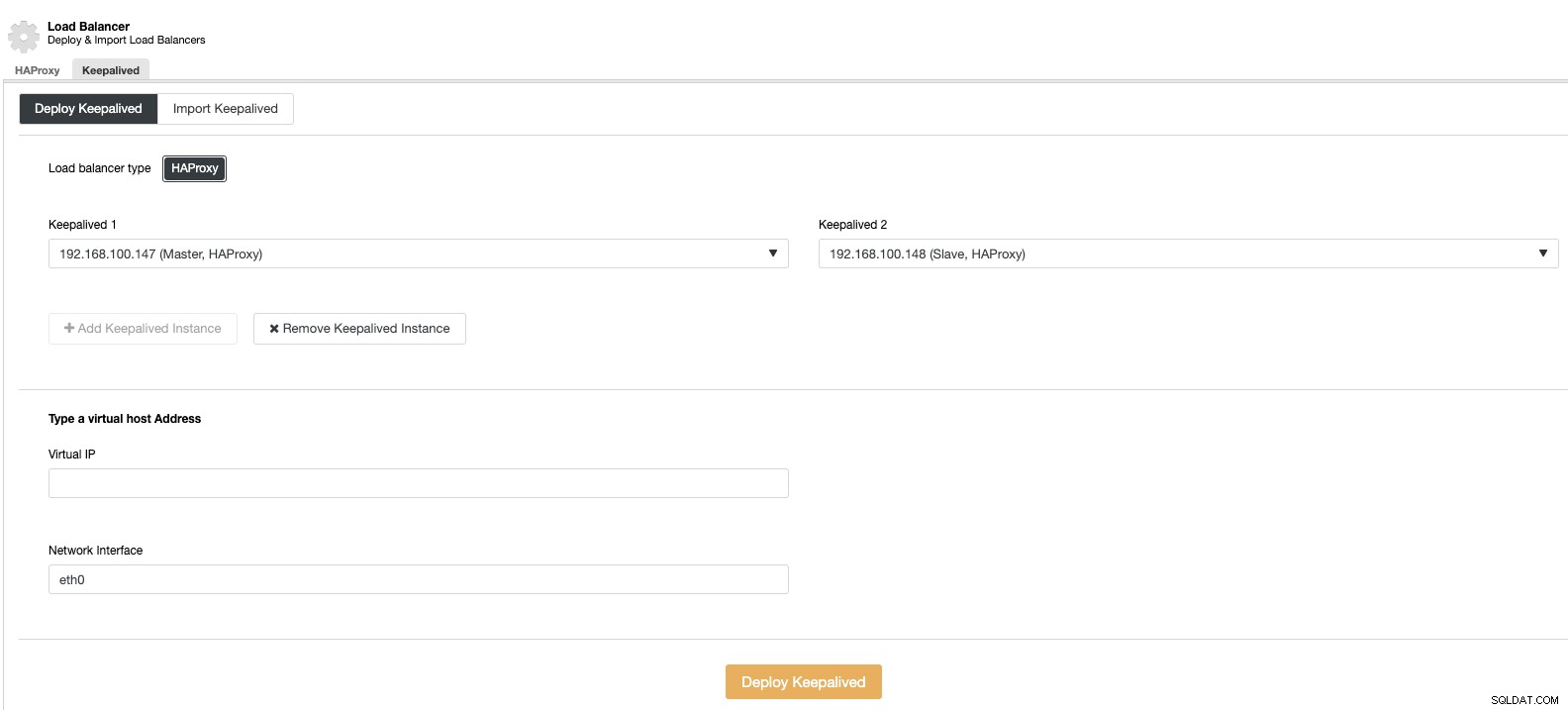
Vertikální měřítko
Pro vertikální škálování můžeme pomocí ClusterControl monitorovat naše databázové uzly jak ze strany operačního systému, tak ze strany databáze. Můžeme zkontrolovat některé metriky, jako je využití procesoru, paměť, připojení, nejčastější dotazy, spuštěné dotazy a ještě více. Můžeme také povolit sekci Dashboard, která nám umožňuje vidět metriky podrobněji a přátelštějším způsobem.
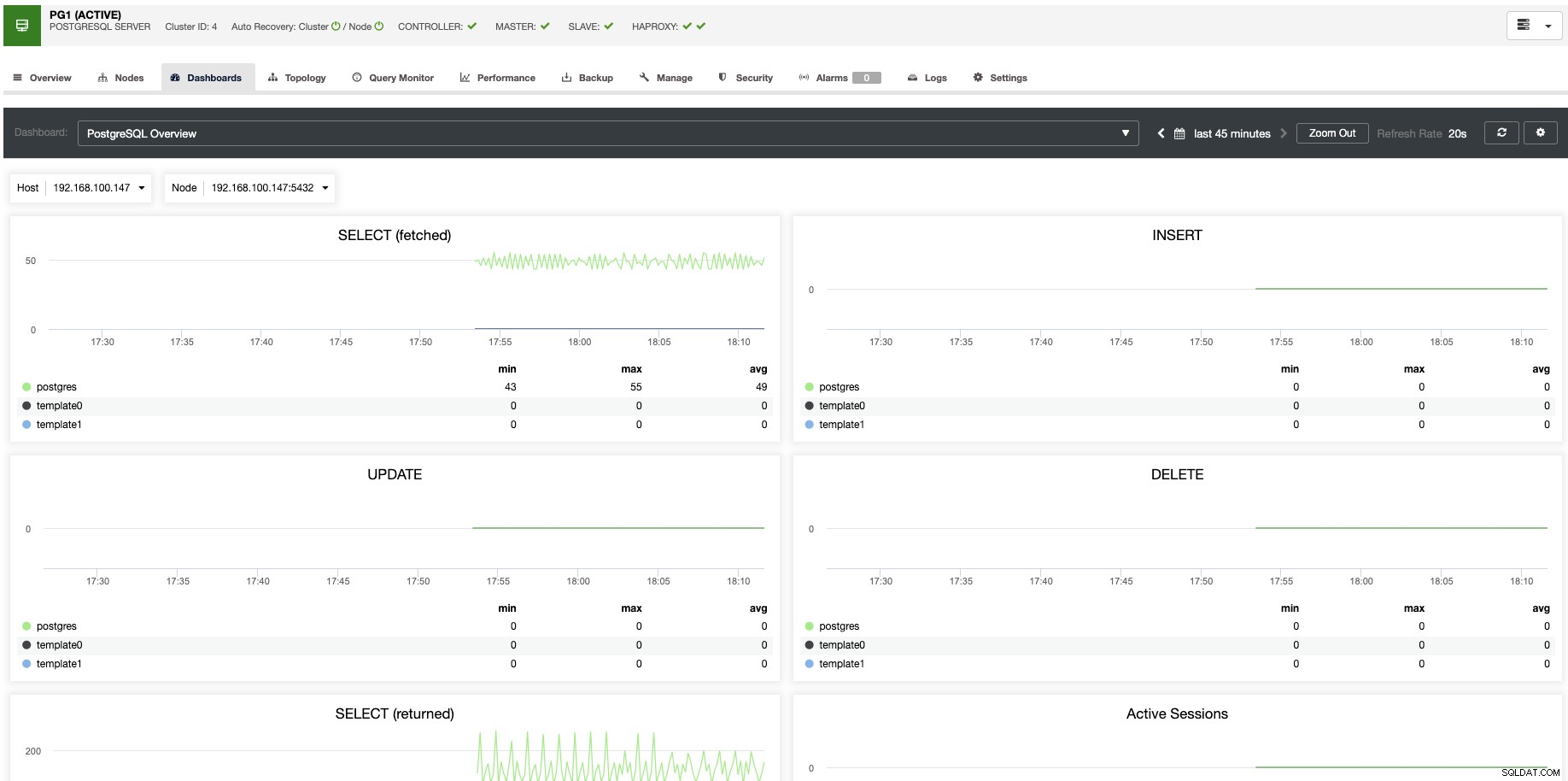
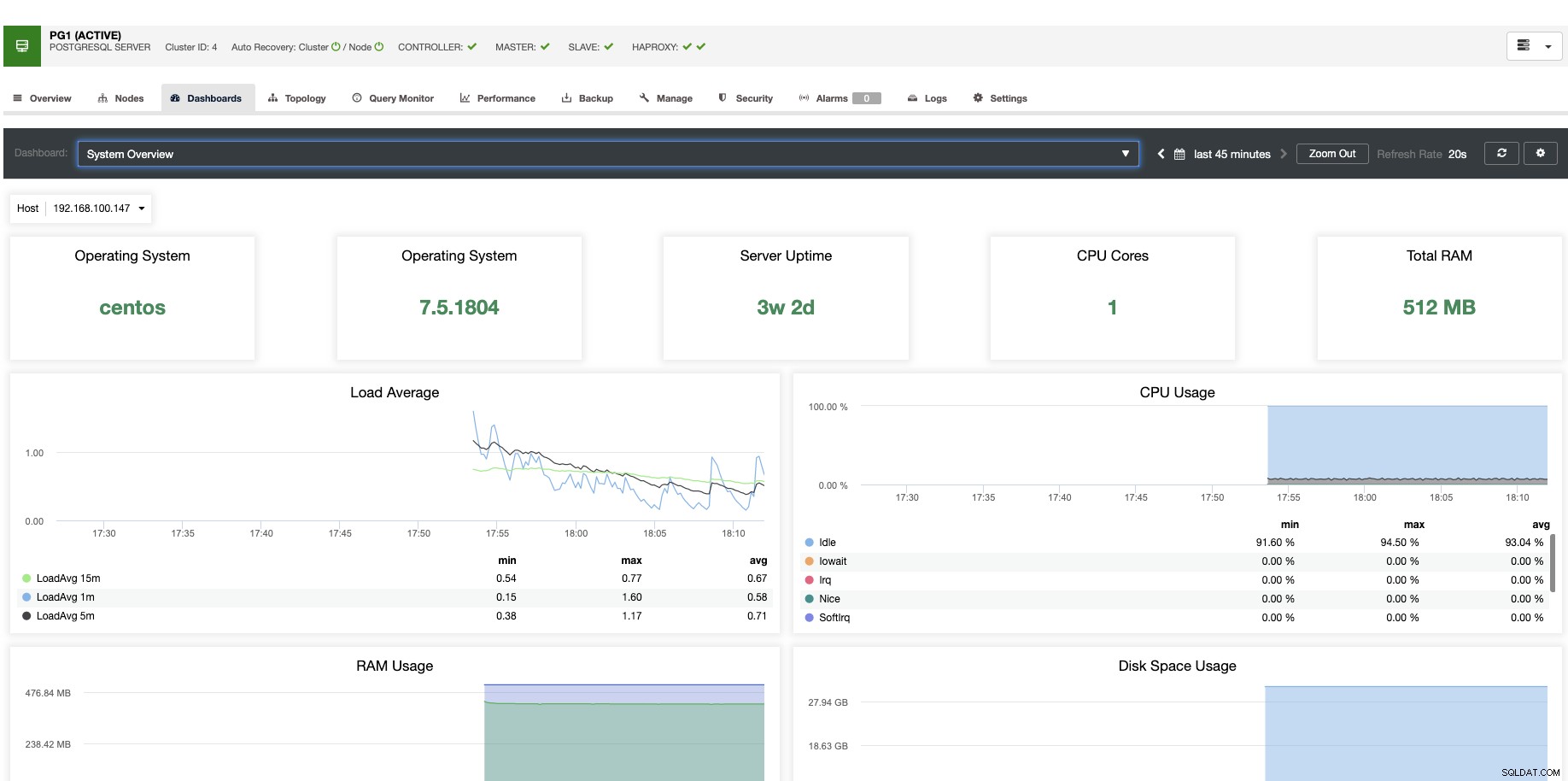
Z ClusterControl můžete také jediným kliknutím provádět různé úlohy správy, jako je Reboot Host, Rebuild Replication Slave nebo Promote Slave.
Závěr
Škálování PostgreSQL databází může být časově náročný úkol. Musíme vědět, co potřebujeme škálovat a jaký je nejlepší způsob, jak to udělat. Manuální správa a škálování clusterů se po určitém okamžiku stává docela zatěžující, takže se většina obrací na nástroje, jako je ten náš.
Pokud zvolíte ruční trasu, podívejte se, kdy zvážit přidání dalšího uzlu do clusteru. Chcete se vyhnout potížím? Vyhodnoťte ClusterControl zdarma po dobu 30 dnů a zjistěte, jak jeho funkce zjednodušují a zefektivňují práci s rozsáhlými open-source.
Ať už chcete spravovat a škálovat své databáze, sledujte nás na Twitteru nebo LinkedIn nebo se přihlaste k odběru našeho newsletteru a získejte nejnovější zprávy a osvědčené postupy při správě open source databázové infrastruktury, a brzy se uvidíme!