Vysoká dostupnost je požadavkem téměř každé společnosti na celém světě používající PostgreSQL Je dobře známo, že PostgreSQL používá jako metodu replikace streamovací replikaci. PostgreSQL Streaming Replication je ve výchozím nastavení asynchronní, takže je možné, aby byly některé transakce potvrzeny v primárním uzlu, které ještě nebyly replikovány na záložní server. To znamená, že existuje možnost určité potenciální ztráty dat.
Toto zpoždění v procesu odevzdání má být velmi malé... pokud je záložní server dostatečně výkonný, aby držel krok se zátěží. Pokud toto malé riziko ztráty dat není ve společnosti přijatelné, můžete také použít synchronní replikaci místo výchozího nastavení.
Při synchronní replikaci bude každé potvrzení transakce zápisu čekat na potvrzení, že potvrzení bylo zapsáno do protokolu pro zápis na disk primárního i záložního serveru.
Tato metoda minimalizuje možnost ztráty dat. Aby došlo ke ztrátě dat, museli byste současně selhat primární i pohotovostní režim.
Nevýhoda této metody je u všech synchronních metod stejná, protože u této metody se zvyšuje doba odezvy pro každou transakci zápisu. To je způsobeno nutností počkat na všechna potvrzení, že transakce byla potvrzena. Naštěstí to neovlivní transakce pouze pro čtení, ale; pouze transakce zápisu.
V tomto blogu vám ukážeme, jak nainstalovat PostgreSQL Cluster od začátku, jak převést asynchronní replikaci (výchozí) na synchronní. Také vám ukážu, jak se vrátit zpět, pokud doba odezvy není přijatelná, protože se můžete snadno vrátit do předchozího stavu. Uvidíte, jak snadno nasadit, konfigurovat a monitorovat synchronní replikaci PostgreSQL pomocí ClusterControl za použití jediného nástroje pro celý proces.
Instalace klastru PostgreSQL
Začněme s instalací a konfigurací asynchronní replikace PostgreSQL, což je obvyklý režim replikace používaný v clusteru PostgreSQL. Budeme používat PostgreSQL 11 na CentOS 7.
Instalace PostgreSQL
Podle oficiální instalační příručky PostgreSQL je tento úkol docela jednoduchý.
Nejprve nainstalujte úložiště:
$ yum install https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-latest.noarch.rpmNainstalujte klientské a serverové balíčky PostgreSQL:
$ yum install postgresql11 postgresql11-serverInicializovat databázi:
$ /usr/pgsql-11/bin/postgresql-11-setup initdb
$ systemctl enable postgresql-11
$ systemctl start postgresql-11V pohotovostním uzlu se můžete vyhnout poslednímu příkazu (spustit službu databáze), protože obnovíte binární zálohu za účelem vytvoření streamované replikace.
Nyní se podíváme na konfiguraci, kterou vyžaduje asynchronní replikace PostgreSQL.
Konfigurace asynchronní replikace PostgreSQL
Nastavení primárního uzlu
V primárním uzlu PostgreSQL musíte k vytvoření asynchronní replikace použít následující základní konfiguraci. Soubory, které budou upraveny, jsou postgresql.conf a pg_hba.conf. Obecně jsou v datovém adresáři (/var/lib/pgsql/11/data/), ale můžete to potvrdit na straně databáze:
postgres=# SELECT setting FROM pg_settings WHERE name = 'data_directory';
setting
------------------------
/var/lib/pgsql/11/data
(1 row)Postgresql.conf
Změňte nebo přidejte následující parametry v konfiguračním souboru postgresql.conf.
Zde musíte přidat IP adresu (adresy), na které chcete poslouchat. Výchozí hodnota je 'localhost' a v tomto příkladu použijeme '*' pro všechny IP adresy na serveru.
listen_addresses = '*' Nastavte port serveru, na kterém se má naslouchat. Ve výchozím nastavení 5432.
port = 5432 Určete, kolik informací se zapisuje do WAL. Možné hodnoty jsou minimální, replika nebo logické. Hodnota hot_standby je mapována na repliku a používá se k zachování kompatibility s předchozími verzemi.
wal_level = hot_standby Nastavte maximální počet procesů walsender, které spravují připojení k záložnímu serveru.
max_wal_senders = 16Nastavte minimální množství souborů WAL, které se mají uchovávat v adresáři pg_wal.
wal_keep_segments = 32Změna těchto parametrů vyžaduje restartování databázové služby.
$ systemctl restart postgresql-11Pg_hba.conf
Změňte nebo přidejte následující parametry v konfiguračním souboru pg_hba.conf.
# TYPE DATABASE USER ADDRESS METHOD
host replication replication_user IP_STANDBY_NODE/32 md5
host replication replication_user IP_PRIMARY_NODE/32 md5Jak vidíte, zde je potřeba přidat přístupové oprávnění uživatele. V prvním sloupci je typ připojení, který může být hostitelský nebo místní. Poté musíte zadat databázi (replikaci), uživatele, zdrojovou IP adresu a metodu ověřování. Změna tohoto souboru vyžaduje opětovné načtení databázové služby.
$ systemctl reload postgresql-11Tuto konfiguraci byste měli přidat do primárního i pohotovostního uzlu, protože ji budete potřebovat, pokud bude pohotovostní uzel povýšen na hlavní v případě selhání.
Nyní musíte vytvořit uživatele replikace.
Replikační role
Role (uživatel) musí mít oprávnění REPLICATION, aby ji mohla používat ve streamovací replikaci.
postgres=# CREATE ROLE replication_user WITH LOGIN PASSWORD 'PASSWORD' REPLICATION;
CREATE ROLEPo konfiguraci příslušných souborů a vytvoření uživatele je třeba vytvořit konzistentní zálohu z primárního uzlu a obnovit ji v pohotovostním uzlu.
Nastavení pohotovostního uzlu
V pohotovostním uzlu přejděte do adresáře /var/lib/pgsql/11/ a přesuňte nebo odeberte aktuální datový adresář:
$ cd /var/lib/pgsql/11/
$ mv data data.bkPotom spusťte příkaz pg_basebackup, abyste získali aktuální primární datový adresář a přiřadili správného vlastníka (postgres):
$ pg_basebackup -h 192.168.100.145 -D /var/lib/pgsql/11/data/ -P -U replication_user --wal-method=stream
$ chown -R postgres.postgres dataNyní musíte k vytvoření asynchronní replikace použít následující základní konfiguraci. Soubor, který bude upraven, je postgresql.conf a musíte vytvořit nový soubor recovery.conf. Oba budou umístěny v /var/lib/pgsql/11/.
Recovery.conf
Určete, že tento server bude záložním serverem. Pokud je zapnutá, server bude pokračovat v obnově načítáním nových segmentů WAL, když bude dosaženo konce archivované WAL.
standby_mode = 'on'Zadejte připojovací řetězec, který se má použít pro pohotovostní server pro připojení k primárnímu uzlu.
primary_conninfo = 'host=IP_PRIMARY_NODE port=5432 user=replication_user password=PASSWORD'Určete obnovení do konkrétní časové osy. Výchozí nastavení je obnovit podle stejné časové osy, která byla aktuální, když byla pořízena základní záloha. Nastavením na „nejnovější“ se obnoví nejnovější časová osa nalezená v archivu.
recovery_target_timeline = 'latest'Určete spouštěcí soubor, jehož přítomnost ukončí obnovu v pohotovostním režimu.
trigger_file = '/tmp/failover_5432.trigger'Postgresql.conf
Změňte nebo přidejte následující parametry v konfiguračním souboru postgresql.conf.
Určete, kolik informací se zapisuje do WAL. Možné hodnoty jsou minimální, replika nebo logické. Hodnota hot_standby je mapována na repliku a používá se k zachování kompatibility s předchozími verzemi. Změna této hodnoty vyžaduje restart služby.
wal_level = hot_standbyPovolit dotazy během obnovy. Změna této hodnoty vyžaduje restart služby.
hot_standby = onSpuštění pohotovostního uzlu
Nyní máte na svém místě veškerou požadovanou konfiguraci, stačí spustit databázovou službu v pohotovostním uzlu.
$ systemctl start postgresql-11A zkontrolujte databázové protokoly ve /var/lib/pgsql/11/data/log/. Měli byste mít něco takového:
2019-11-18 20:23:57.440 UTC [1131] LOG: entering standby mode
2019-11-18 20:23:57.447 UTC [1131] LOG: redo starts at 0/3000028
2019-11-18 20:23:57.449 UTC [1131] LOG: consistent recovery state reached at 0/30000F8
2019-11-18 20:23:57.449 UTC [1129] LOG: database system is ready to accept read only connections
2019-11-18 20:23:57.457 UTC [1135] LOG: started streaming WAL from primary at 0/4000000 on timeline 1Stav replikace v primárním uzlu můžete také zkontrolovat spuštěním následujícího dotazu:
postgres=# SELECT pid,usename,application_name,state,sync_state FROM pg_stat_replication;
pid | usename | application_name | state | sync_state
------+------------------+------------------+-----------+------------
1467 | replication_user | walreceiver | streaming | async
(1 row)Jak můžete vidět, používáme asynchronní replikaci.
Převod asynchronní replikace PostgreSQL na synchronní replikaci
Nyní je čas převést tuto asynchronní replikaci na synchronizační, a proto budete muset nakonfigurovat primární i pohotovostní uzel.
Primární uzel
V primárním uzlu PostgreSQL musíte použít tuto základní konfiguraci navíc k předchozí asynchronní konfiguraci.
Postgresql.conf
Uveďte seznam rezervních serverů, které mohou podporovat synchronní replikaci. Tento název pohotovostního serveru je nastavením názvu aplikace v souboru recovery.conf pohotovostního režimu.
synchronous_standby_names = 'pgsql_0_node_0'synchronous_standby_names = 'pgsql_0_node_0'Uvádí, zda potvrzení transakce bude čekat na zápis záznamů WAL na disk, než příkaz vrátí klientovi indikaci „úspěchu“. Platné hodnoty jsou on, remote_apply, remote_write, local a off. Výchozí hodnota je zapnutá.
synchronous_commit = onNastavení pohotovostního uzlu
V pohotovostním uzlu PostgreSQL musíte změnit soubor recovery.conf přidáním hodnoty 'application_name do parametru primary_conninfo.
Recovery.conf
standby_mode = 'on'
primary_conninfo = 'application_name=pgsql_0_node_0 host=IP_PRIMARY_NODE port=5432 user=replication_user password=PASSWORD'
recovery_target_timeline = 'latest'
trigger_file = '/tmp/failover_5432.trigger'Restartujte databázovou službu v primárním i v pohotovostním uzlu:
$ service postgresql-11 restartNyní byste měli mít svou synchronizační streamovací replikaci spuštěnou:
postgres=# SELECT pid,usename,application_name,state,sync_state FROM pg_stat_replication;
pid | usename | application_name | state | sync_state
------+------------------+------------------+-----------+------------
1561 | replication_user | pgsql_0_node_0 | streaming | sync
(1 row)Návrat ze synchronní na asynchronní replikaci PostgreSQL
Pokud se potřebujete vrátit k asynchronní replikaci PostgreSQL, stačí vrátit zpět změny provedené v souboru postgresql.conf na primárním uzlu:
Postgresql.conf
#synchronous_standby_names = 'pgsql_0_node_0'
#synchronous_commit = onA restartujte databázovou službu.
$ service postgresql-11 restartTeď byste měli mít znovu asynchronní replikaci.
postgres=# SELECT pid,usename,application_name,state,sync_state FROM pg_stat_replication;
pid | usename | application_name | state | sync_state
------+------------------+------------------+-----------+------------
1625 | replication_user | pgsql_0_node_0 | streaming | async
(1 row)Jak nasadit synchronní replikaci PostgreSQL pomocí ClusterControl
S ClusterControl můžete provádět úlohy nasazení, konfigurace a monitorování vše v jednom ze stejné úlohy a budete ji moci spravovat ze stejného uživatelského rozhraní.
Předpokládáme, že máte nainstalovaný ClusterControl a ten může přistupovat k databázovým uzlům přes SSH. Další informace o konfiguraci přístupu ClusterControl naleznete v naší oficiální dokumentaci.
Přejděte do ClusterControl a pomocí možnosti „Deploy“ vytvořte nový cluster PostgreSQL.
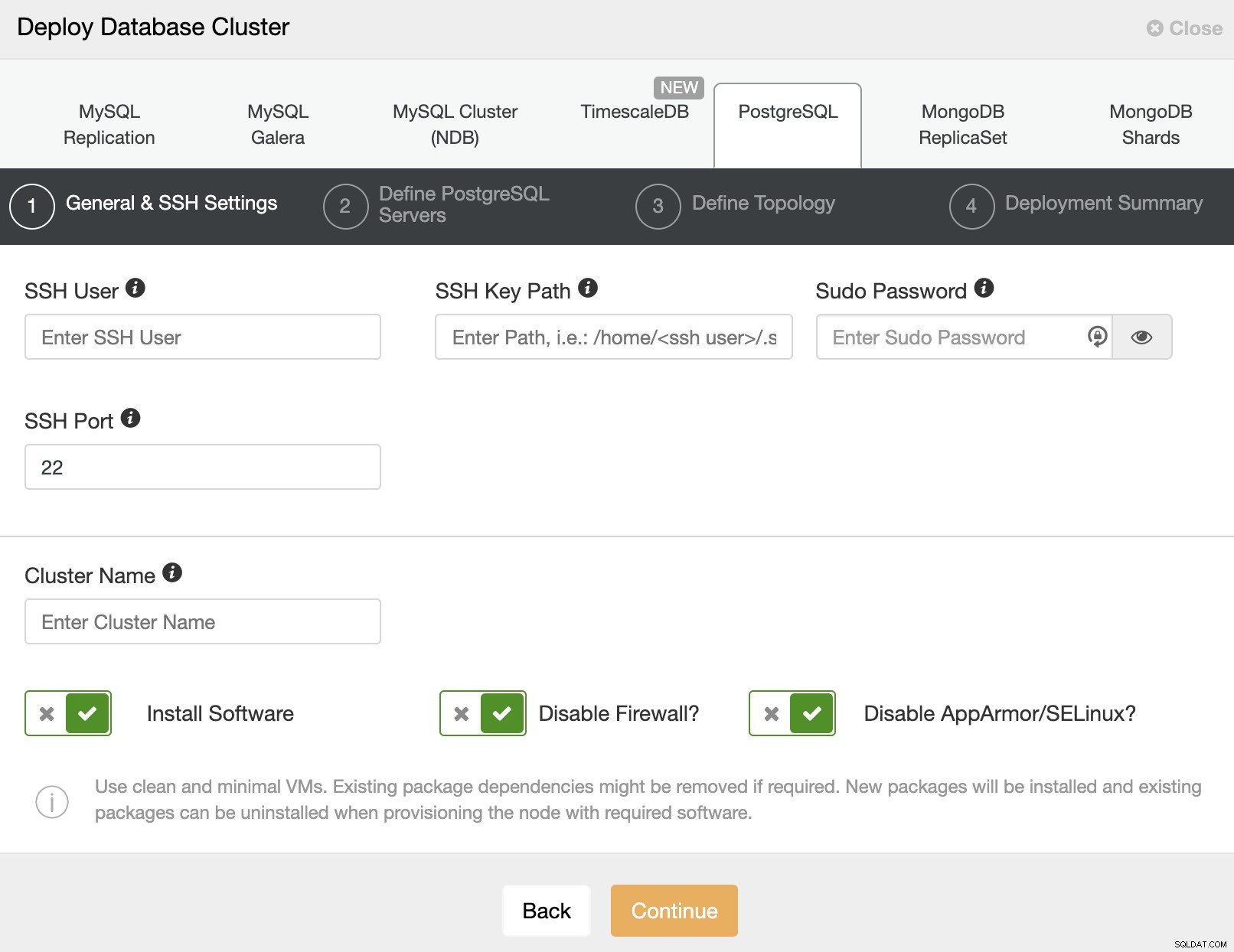
Při výběru PostgreSQL musíte zadat uživatele, klíč nebo heslo a port pro připojení pomocí SSH k našim serverům. Potřebujete také název pro svůj nový cluster a pokud chcete, aby ClusterControl nainstaloval odpovídající software a konfigurace za vás.
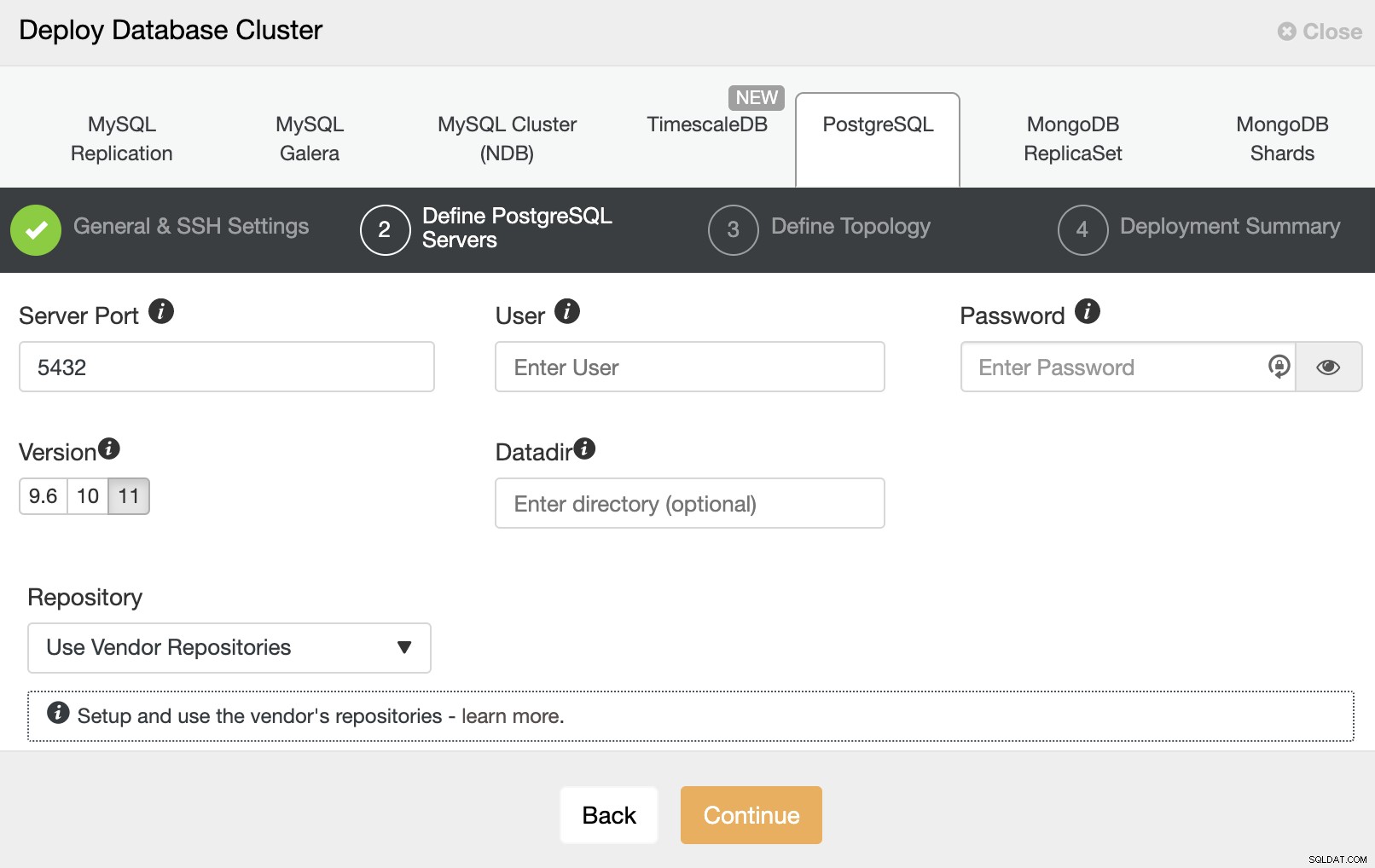
Po nastavení přístupových informací SSH musíte zadat data pro přístup vaší databázi. Můžete také určit, které úložiště použít.
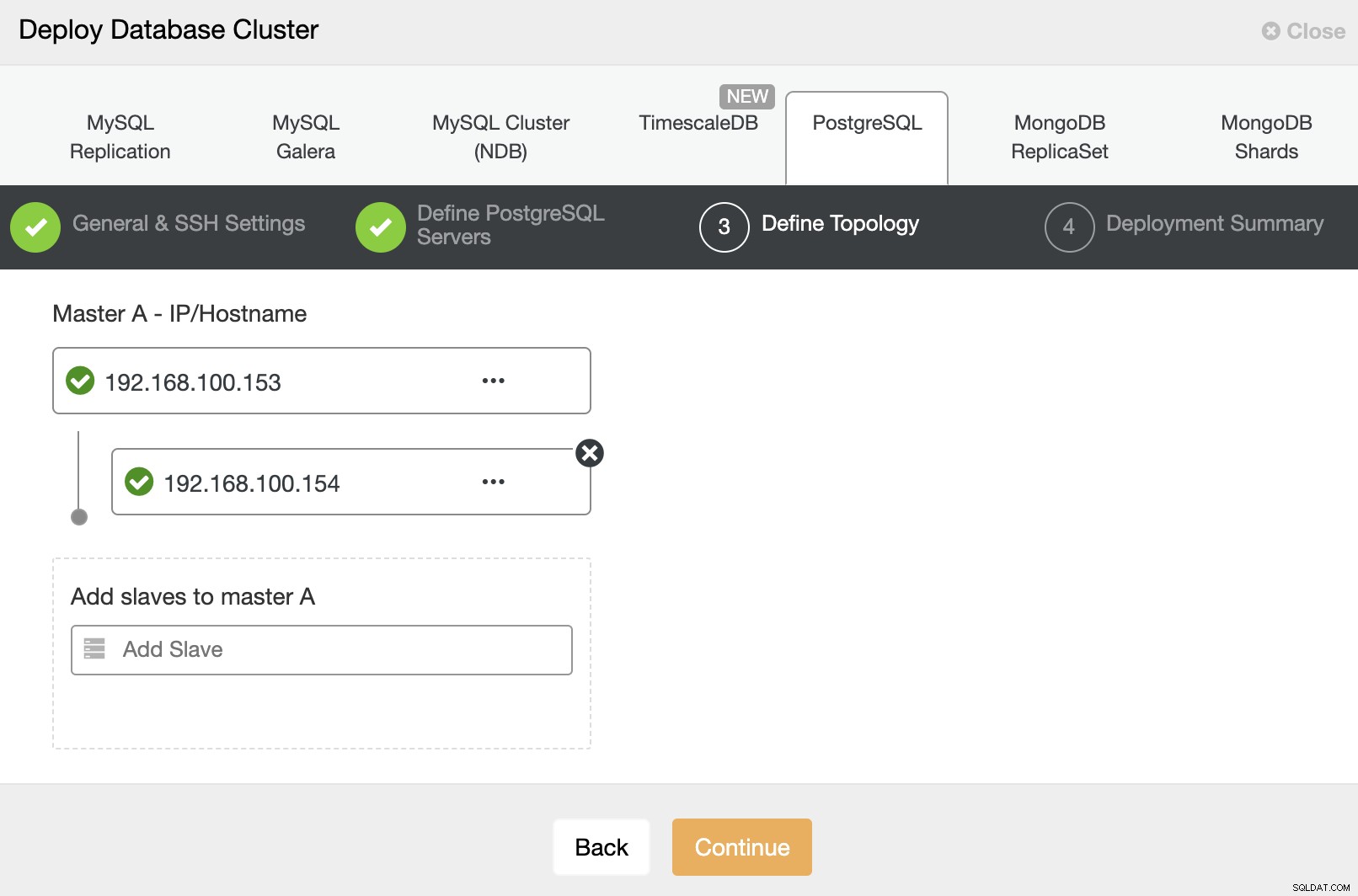
V dalším kroku musíte do clusteru přidat servery, které budete tvořit. Při přidávání serverů můžete zadat IP nebo název hostitele.
A nakonec si v posledním kroku můžete vybrat metodu replikace, která může být asynchronní nebo synchronní replikací.
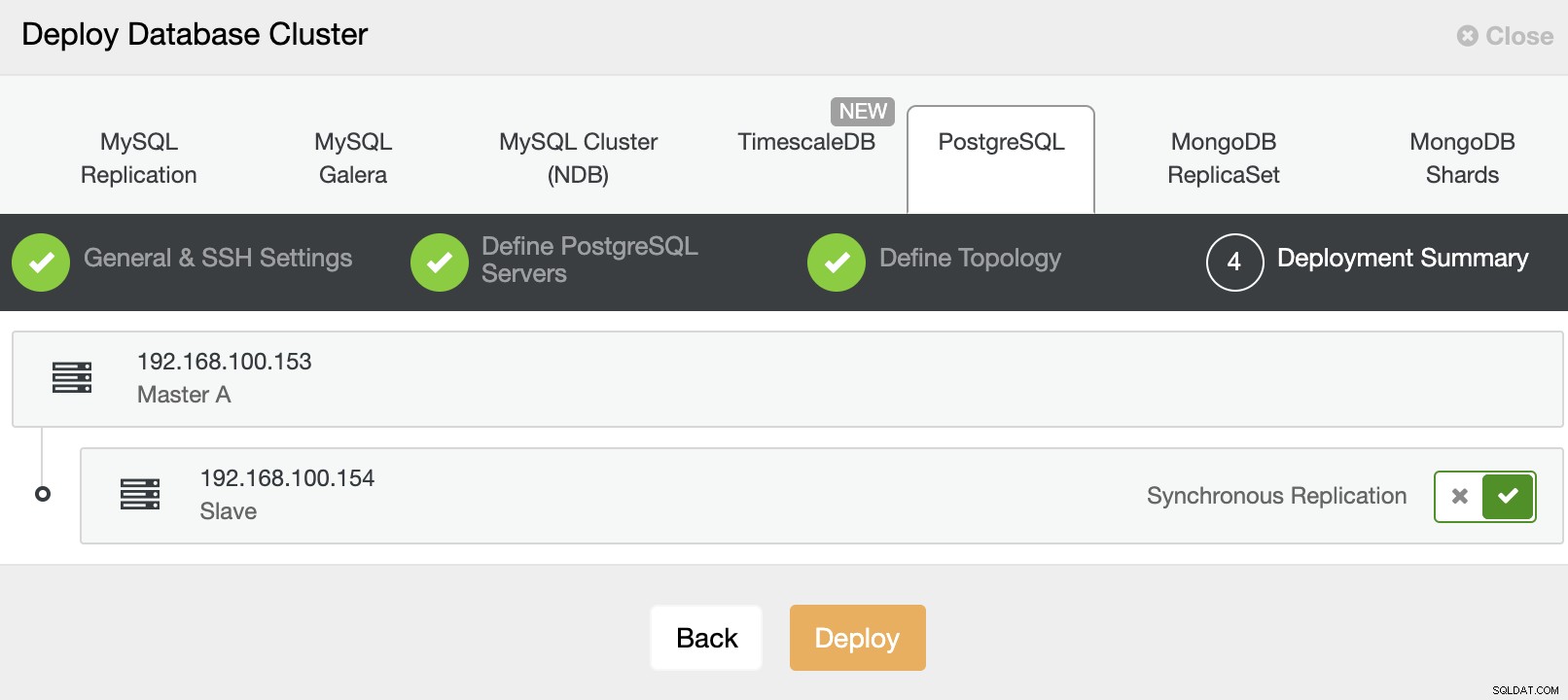
To je vše. Stav úlohy můžete sledovat v části Aktivita ClusterControl.
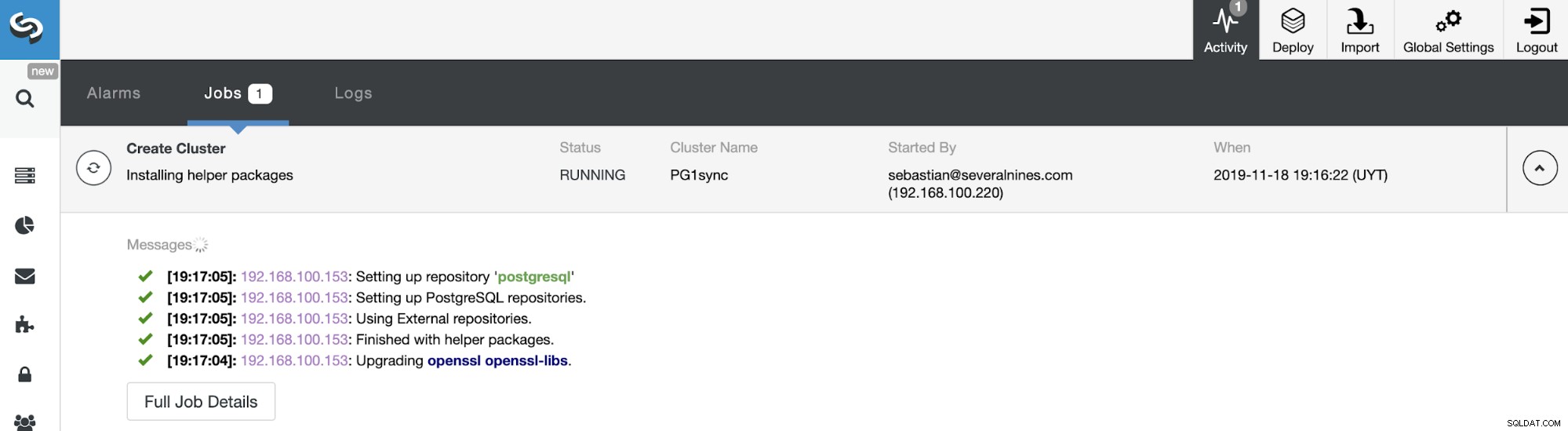
A až tato úloha skončí, budete mít nainstalován váš synchronní cluster PostgreSQL, konfigurováno a monitorováno pomocí ClusterControl.
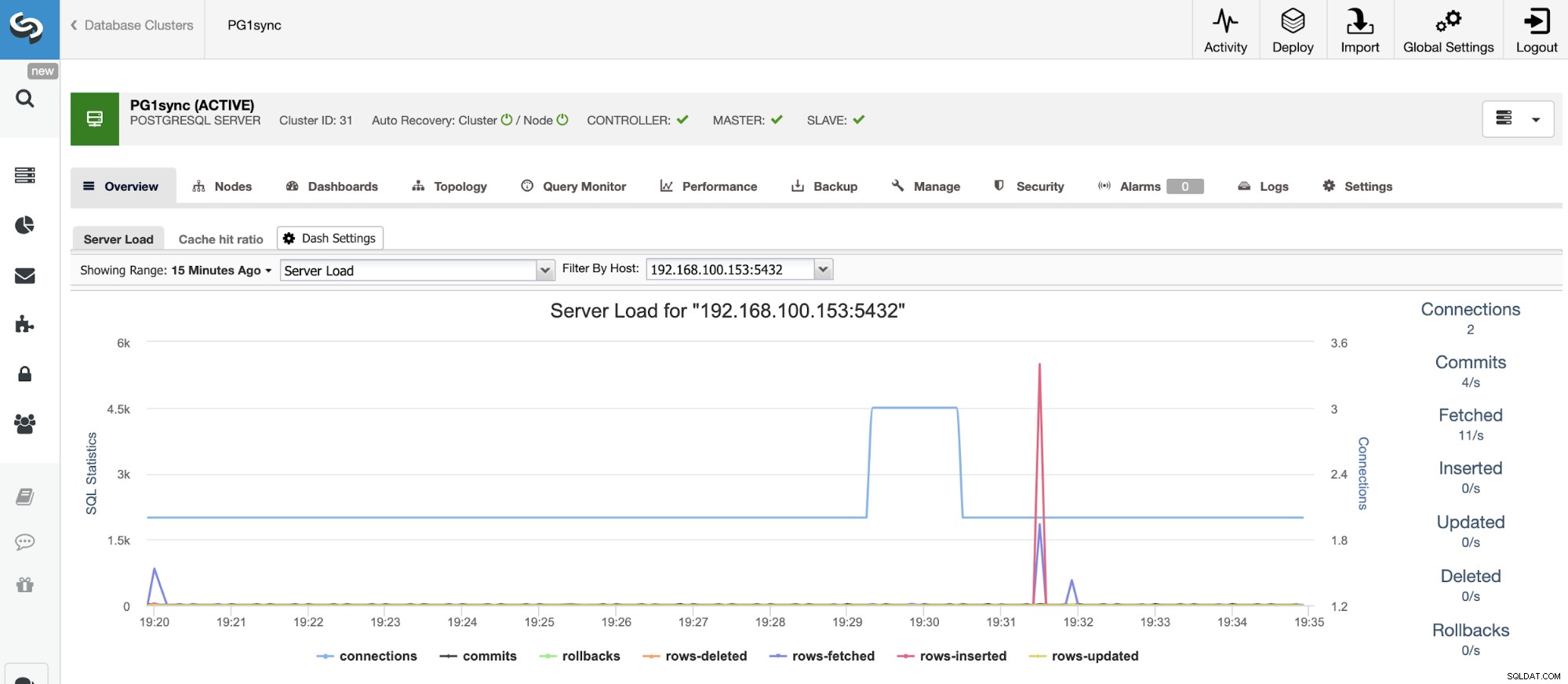
Závěr
Jak jsme zmínili na začátku tohoto blogu, vysoká dostupnost je požadavkem pro všechny společnosti, takže byste měli znát dostupné možnosti, jak ji dosáhnout pro každou používanou technologii. Pro PostgreSQL můžete jako nejbezpečnější způsob implementace použít synchronní streamovací replikaci, ale tato metoda nefunguje pro všechna prostředí a pracovní zátěže.
Namísto řešení s vysokou dostupností buďte opatrní s latencí generovanou čekáním na potvrzení každé transakce, která by mohla být problémem.