Toto je druhý díl dvoudílné série o repmgr 2ndQuadrant, open source nástroji s vysokou dostupností pro PostgreSQL.
V první části jsme nastavili tříuzlový cluster PostgreSQL 12 spolu s uzlem „svědek“. Cluster se skládal z primárního uzlu a dvou pohotovostních uzlů. Cluster a uzel svědka byly hostovány ve virtuálním privátním cloudu (VPC) Amazon Web Service. Servery EC2 hostující instance Postgres byly umístěny v podsítích v různých zónách dostupnosti (AZ), jak je uvedeno níže:
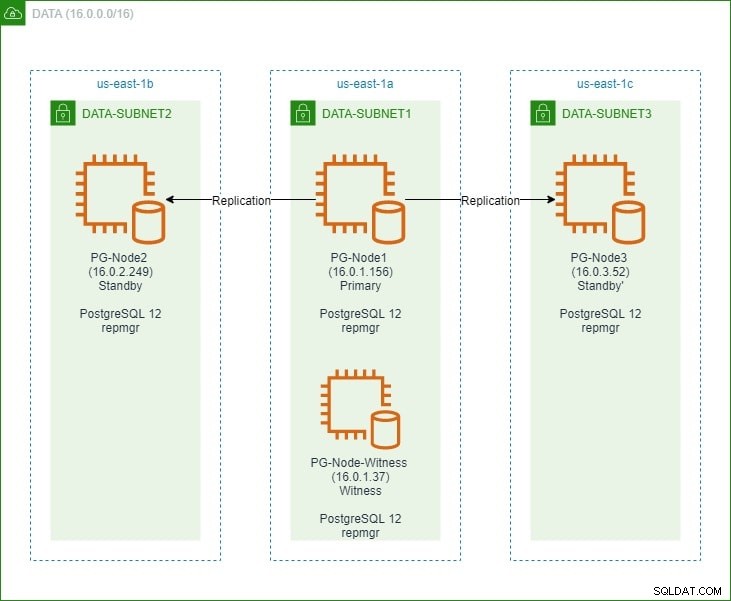
Uděláme rozsáhlé odkazy na názvy uzlů a jejich IP adresy, takže zde je opět tabulka s podrobnostmi o uzlech:
| Název uzlu | IP adresa | Role | Spuštěné aplikace |
| PG-Node1 | 16.0.1.156 | Primární | PostgreSQL 12 a repmgr |
| PG-Node2 | 16.0.2.249 | Pohotovostní režim 1 | PostgreSQL 12 a repmgr |
| PG-Node3 | 16.0.3.52 | Pohotovostní režim 2 | PostgreSQL 12 a repmgr |
| PG-Node-Witness | 16.0.1.37 | Svědek | PostgreSQL 12 a repmgr |
Nainstalovali jsme repmgr do primárních a pohotovostních uzlů a poté jsme primární uzel zaregistrovali pomocí repmgr. Poté jsme naklonovali oba pohotovostní uzly z primární a spustili je. Oba pohotovostní uzly byly také registrovány u repmgr. Příkaz „repmgr cluster show“ nám ukázal, že vše běží podle očekávání:

Aktuální problém
Nastavení streamingové replikace pomocí repmgr je velmi jednoduché. Dále musíme zajistit, aby klastr fungoval, i když se primární stane nedostupným. Tomu se budeme věnovat v tomto článku.
V replikaci PostgreSQL může být primární z několika důvodů nedostupný. Například:
- Operační systém primárního uzlu může selhat nebo přestat reagovat
- Primární uzel může ztratit své síťové připojení
- Služba PostgreSQL v primárním uzlu může selhat, zastavit se nebo se neočekávaně stát nedostupnou
- Službu PostgreSQL v primárním uzlu lze zastavit úmyslně nebo náhodně
Kdykoli se primární stane nedostupným, pohotovostní režim není automaticky povýší do primární role. Pohotovostní režim nadále obsluhuje dotazy pouze pro čtení – i když data budou aktuální až do posledního LSN přijatého od primárního. Jakýkoli pokus o operaci zápisu selže.
Existují dva způsoby, jak to zmírnit:
- Pohotovostní režim je ručně povýšen na primární roli. To je obvykle případ plánovaného převzetí služeb při selhání nebo „přepnutí“
- Pohotovostní režim je automaticky povýšen do primární role. To je případ nenativních nástrojů, které nepřetržitě monitorují replikaci a provádějí obnovu, když primární není k dispozici. repmgr je jedním z takových nástrojů.
Zde se budeme zabývat druhým scénářem. Tato situace má však několik dalších problémů:
- Pokud existuje více než jeden pohotovostní režim, jak nástroj (nebo pohotovostní režimy) rozhodne, který z nich bude povýšen jako primární? Jak funguje kvorum a proces povýšení?
- Pokud je u více pohotovostních režimů jeden nastaven jako primární, jak ho ostatní uzly začnou „sledovat“ jako nový primární?
- Co se stane, když primární server funguje, ale z nějakého důvodu je dočasně odpojen od sítě? Pokud je jeden z pohotovostních režimů povýšen na primární a poté se původní primární zařízení vrátí online, jak se lze vyhnout situaci „rozděleného mozku“?
odpověď remgr:Witness Node a démon repmgr
K zodpovězení těchto otázek používá repmgr něco, co se nazývá uzel svědka . Když je primární uzel nedostupný – je úkolem uzlu svědka pomoci pohotovostním režimům dosáhnout kvora, pokud by jeden z nich měl být povýšen do primární role. Pohotovostní režimy dosáhnou tohoto kvora určením, zda je primární uzel skutečně offline nebo je nedostupný pouze dočasně. Uzel svědka by měl být umístěn ve stejném datovém centru/segmentu/podsíti jako primární uzel, ale NIKDY nesmí běžet na stejném fyzickém hostiteli jako primární uzel.
Pamatujte, že v první části této série jsme zavedli uzel svědka ve stejné zóně dostupnosti a podsíti jako primární uzel. Pojmenovali jsme to PG-Node-Witness a nainstalovali tam instanci PostgreSQL 12. V tomto příspěvku tam nainstalujeme také repmgr, ale o tom později.
Druhou součástí řešení je démon repmgr (repmgrd) běžící ve všech uzlech clusteru a uzlu svědka. Opět jsme tohoto démona nespustili v prvním díle této série, ale zde tak učiníme. Démon je součástí balíčku repmgr – když je povolen, běží jako běžná služba a nepřetržitě monitoruje stav clusteru. Zahájí převzetí služeb při selhání, když je dosaženo kvora o tom, že primární je offline. Nejenže může automaticky propagovat pohotovostní režim, ale může také znovu iniciovat další pohotovostní režimy ve víceuzlovém clusteru, aby následovaly nové primární funkce .
Proces kvora
Když si pohotovostní režim uvědomí, že nevidí primární, konzultuje to s ostatními pohotovostními režimy. Všechny pohotovostní režimy spuštěné v klastru dosáhnou kvora, aby zvolily nové primární pomocí série kontrol:
- Každý pohotovostní režim zjišťuje ostatní pohotovostní režimy o době, kdy naposledy „viděl“ primární. Pokud je poslední replikované LSN pohotovostního režimu nebo čas poslední komunikace s primárním uzlem novější než poslední replikované LSN aktuálního uzlu nebo čas poslední komunikace, uzel nic nedělá a čeká na obnovení komunikace s primárním uzlem
- Pokud žádný z pohotovostních režimů nevidí primárního, zkontrolují, zda je dostupný uzel svědka. Pokud nelze dosáhnout ani uzel svědka, pohotovostní režimy předpokládají, že došlo k výpadku sítě na primární straně, a nepokračují ve výběru nového primárního.
- Pokud lze svědka zastihnout, pohotovostní režimy předpokládají, že primární je vypnutý, a přistoupí k výběru primárního
- Uzel, který byl nakonfigurován jako „preferovaný“ primární, bude poté povýšen. U každého pohotovostního režimu bude replikace znovu inicializována, aby následovala nové primární.
Konfigurace clusteru pro automatické převzetí služeb při selhání
Nyní nakonfigurujeme cluster a pamětní uzel pro automatické převzetí služeb při selhání.
Krok 1:Nainstalujte a nakonfigurujte repmgr ve Witness
Jak nainstalovat balíček repmgr jsme již viděli v našem minulém článku. Toto provedeme také v uzlu svědka:
# wget https://download.postgresql.org/pub/repos/yum/reporpms/EL-8-x86_64/pgdg-redhat-repo-latest.noarch.rpm
A pak:
# yum nainstalovat repmgr12 -y
Dále přidáme následující řádky do souboru postgresql.conf uzlu svědka:
listen_addresses ='*'shared_preload_libraries ='repmgr'
Dále přidáváme následující řádky do souboru pg_hba.conf v uzlu svědka. Všimněte si, jak místo zadávání jednotlivých IP adres používáme rozsah CIDR clusteru.
Místní replikace repmgr Trusthost Replikace Repmgr 127.0.0.1/32 Trusthost Replication Repmgr 16.0.0.0/16 Trustlocal Repmgr rephmgr repmgr 127.0.0.1/32 Trusthmgr repmgr 16.0.0.0/16Poznámka
[Zde popsané kroky slouží pouze pro demonstrační účely. Náš příklad zde používá externě dostupné adresy IP pro uzly. Použití listen_address =‚*‘ spolu s bezpečnostním mechanismem „důvěry“ pg_hba proto představuje bezpečnostní riziko a NEMĚLO by se používat v produkčních scénářích. V produkčním systému budou všechny uzly uvnitř jedné nebo více privátních podsítí, dosažitelných prostřednictvím soukromých IP adres z jumphostů.]
Po provedení změn postgresql.conf a pg_hba.conf vytvoříme uživatele repmgr a databázi repmgr ve svědectví a změníme výchozí vyhledávací cestu uživatele repmgr:
[example@sqldat.comitness ~]$ createuser --superuser repmgr[example@sqldat.com ~]$ createdb --owner=repmgr repmgr[example@sqldat.com ~]$ psql -c "ALTER USER repmgr SET search_path TO repmgr, public;"Nakonec přidáme následující řádky do souboru repmgr.conf, který se nachází v /etc/repmgr/12/
node_id =4název_uzlu ='PG-Node-Witness'conninfo ='host=16.0.1.37 user=repmgr dbname=repmgr connect_timeout=2'data_directory ='/var/lib/pgsql/12/data'Jakmile jsou konfigurační parametry nastaveny, restartujeme službu PostgreSQL v uzlu svědka:
# systemctl restart postgresql-12.serviceChcete-li otestovat konektivitu k svědeckému uzlu repmgr, můžeme spustit tento příkaz z primárního uzlu:
[example@sqldat.com ~]$ psql 'host=16.0.1.37 user=repmgr dbname=repmgr connect_timeout=2'Dále zaregistrujeme uzel svědka pomocí repmgr spuštěním příkazu „repmgr svedkov registr“ jako uživatel postgres. Všimněte si, jak používáme adresu primárního uzel a NE uzel svědka v příkazu níže:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf registr svědků -h 16.0.1.156Důvodem je, že příkaz „repmgr saw register“ přidá metadata uzlu svědka do databáze repmgr primárního uzlu a v případě potřeby inicializuje uzel svědka instalací rozšíření repmgr a zkopírováním metadat repmgr do uzlu svědka.
Výstup bude vypadat takto:
INFO:připojení k uzlu svědka "PG-Node-Witness" (ID:4)INFO:připojení k primárnímu uzluNOTICE:pokus o instalaci rozšíření "repmgr"UPOZORNĚNÍ:rozšíření "repmgr" úspěšně nainstalovánoINFO:registrace svědka dokončeno UPOZORNĚNÍ:uzel svědka "PG-Node-Witness" (ID:4) úspěšně registrovanýNakonec zkontrolujeme stav celkového nastavení z libovolného uzlu:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster show --compactVýstup vypadá takto:
Krok 2:Úprava souboru sudoers
Se spuštěným clusterem a svědkem přidáme následující řádky do souboru sudoers do každého uzlu klastru a uzlu svědka:
Výchozí:postgres !requirettypostgres ALL =NOPASSWD:/usr/bin/systemctl zastavit postgresql-12.service, /usr/bin/systemctl spustit postgresql-12.service, /usr/bin/systemctl restartovat postgresql-12.service , /usr/bin/systemctl reload postgresql-12.service, /usr/bin/systemctl start repmgr12.service, /usr/bin/systemctl stop repmgr12.serviceKrok 3:Konfigurace parametrů repmgrd
V každém uzlu jsme již přidali čtyři parametry do souboru repmgr.conf. Přidané parametry jsou základní parametry potřebné pro provoz repmgr. Chcete-li povolit démona repmgr a automatické převzetí služeb při selhání, je třeba povolit/přidat řadu dalších parametrů. V následujících podsekcích popíšeme každý parametr a hodnotu, na kterou budou nastaveny v každém uzlu.
přepnutí při selhání
Parametr převzetí služeb při selhání je jedním z povinných parametrů démona repmgr. Tento parametr říká démonovi, zda má spustit automatické převzetí služeb při selhání, když je zjištěna situace převzetí služeb při selhání. Může mít jednu ze dvou hodnot:„manuální“ nebo „automatická“. V každém uzlu to nastavíme na automatické:
failover ='automatic'promote_command
Toto je další povinný parametr pro démona repmgr. Tento parametr říká démonu repmgr, jaký příkaz by měl spustit, aby se aktivoval pohotovostní režim. Hodnota tohoto parametru bude obvykle příkaz „repmgr standby promotion“ nebo cesta ke skriptu shellu, který příkaz volá. Pro náš případ použití jsme to v každém uzlu nastavili na následující:
promote_command ='/usr/pgsql-12/bin/repmgr pohotovostní podpora -f /etc/repmgr/12/repmgr.conf --log-to-file'follow_command
Toto je třetí povinný parametr pro démona repmgr. Tento parametr říká pohotovostnímu uzlu, aby následoval nový primární uzel. Démon repmgr nahradí zástupný symbol %n ID uzlu nového primárního uzlu za běhu:
follow_command ='/usr/pgsql-12/bin/repmgr standby follow -f /etc/repmgr/12/repmgr.conf --log-to-file --upstream-node-id=%n'priorita
Parametr priority přidává váhu způsobilosti uzlu stát se primárním. Nastavením tohoto parametru na vyšší hodnotu získá uzel větší způsobilost stát se primárním uzlem. Nastavení této hodnoty na nulu pro uzel také zajistí, že uzel nebude nikdy povýšen jako primární.
V našem případě použití máme dva pohotovostní režimy:PG-Node2 a PG-Node3. Chceme propagovat PG-Node2 jako novou primární, když PG-Node1 přejde do režimu offline, a PG-Node3 následovat PG-Node2 jako svou novou primární. Ve dvou pohotovostních uzlech nastavíme parametr na následující hodnoty:

| Název uzlu | Nastavení parametrů |
| PG-Node2 | priorita =60 |
| PG-Node3 | priorita =40 |
interval_monitoru_secs
Tento parametr říká démonu repmgr, jak často (v sekundách) by měl kontrolovat dostupnost upstream uzlu. V našem případě existuje pouze jeden upstream uzel:primární uzel. Výchozí hodnota je 2 sekundy, ale v každém uzlu ji explicitně nastavíme:
monitor_interval_secs =2
connection_check_type
Parametr connection_check_type určuje, jaký protokol repmgr démon použije k oslovení upstreamového uzlu. Tento parametr může nabývat tří hodnot:
- ping :repmgr používá metodu PQPing()
- připojení :repmgr se pokusí vytvořit nové připojení k upstream uzlu
- dotaz :repmgr se pokusí spustit dotaz SQL na upstream uzlu pomocí existujícího připojení
Opět nastavíme tento parametr na výchozí hodnotu ping v každém uzlu:
connection_check_type ='ping'
reconnect_interval a reconnect_interval
Když primární nebude k dispozici, démon repmgr v pohotovostních uzlech se pokusí znovu připojit k primárnímu po dobu reconnect_attempts. Výchozí hodnota tohoto parametru je 6. Mezi každým pokusem o opětovné připojení bude čekat po dobu reconnect_interval sekund, což má výchozí hodnotu 10. Pro demonstrační účely použijeme krátký interval a méně pokusů o opětovné připojení. Tento parametr nastavujeme v každém uzlu:
pokusy o opětovné připojení =4interval_obnovení =8
primary_visibility_consensus
Když primární přestane být k dispozici ve víceuzlovém clusteru, mohou se pohotovostní režimy vzájemně konzultovat, aby vytvořili kvorum o převzetí služeb při selhání. To se provádí tak, že se každého pohotovostního režimu zeptáte na čas, kdy naposledy viděl primární. Pokud byla poslední komunikace uzlu velmi nedávná a později než v době, kdy místní uzel viděl primární uzel, předpokládá místní uzel, že primární je stále dostupný, a nepokračuje v rozhodnutí o převzetí služeb při selhání.
Chcete-li povolit tento model konsensu, musí být parametr primary_visibility_consensus nastaven na hodnotu „true“ v každém uzlu – včetně svědka:
primary_visibility_consensus =pravda
standby_disconnect_on_failover
Když je parametr standby_disconnect_on_failover v pohotovostním uzlu nastaven na hodnotu „true“, démon repmgr zajistí, že jeho přijímač WAL je odpojen od primárního a nepřijímá žádné segmenty WAL. Před provedením rozhodnutí o převzetí služeb při selhání také počká, až se zastaví přijímače WAL ostatních pohotovostních uzlů. Tento parametr by měl být nastaven na stejnou hodnotu v každém uzlu. Nastavujeme to na „true“.
standby_disconnect_on_failover =pravda
Nastavení tohoto parametru na hodnotu true znamená, že každý pohotovostní uzel přestal přijímat data z primárního zařízení, protože došlo k převzetí služeb při selhání. Proces bude mít zpoždění 5 sekund plus čas, který potřebuje přijímač WAL k zastavení před rozhodnutím o převzetí služeb při selhání. Ve výchozím nastavení bude démon repmgr čekat 30 sekund, aby potvrdil, že všechny sourozenecké uzly přestaly přijímat segmenty WAL, než dojde k převzetí služeb při selhání.
repmgrd_service_start_command a repmgrd_service_stop_command
Tyto dva parametry určují, jak spustit a zastavit démona repmgr pomocí příkazů „repmgr daemon start“ a „repmgr daemon stop“.
V zásadě jsou tyto dva příkazy obaly kolem příkazů operačního systému pro spuštění/zastavení služby. Dvě hodnoty parametrů mapují tyto příkazy na jejich verze specifické pro operační systém. Tyto parametry nastavíme v každém uzlu na následující hodnoty:
repmgrd_service_start_command ='sudo /usr/bin/systemctl start repmgr12.service'repmgrd_service_stop_command ='sudo /usr/bin/systemctl stop repmgr12.service'
Příkazy Start/Stop/Restart služby PostgreSQL
V rámci své činnosti bude démon repmgr často muset zastavit, spustit nebo restartovat službu PostgreSQL. Pro zajištění hladkého průběhu je nejlepší zadat odpovídající příkazy operačního systému jako hodnoty parametrů v souboru repmgr.conf. Pro tento účel nastavíme v každém uzlu čtyři parametry:
service_start_command ='sudo /usr/bin/systemctl start postgresql-12.service'service_stop_command ='sudo /usr/bin/systemctl stop postgresql-12.service'service_restart_command ='sudo /usr/bin/systemctl restart postgresql-12.service'service_reload_command ='sudo /usr/bin/systemctl reload postgresql-12.service'
historie_monitoringu
Nastavením parametru monitoring_history na „yes“ zajistíte, že repmgr ukládá svá data monitorování clusteru. V každém uzlu jsme to nastavili na „yes“:
historie_monitoringu =ano
log_status_interval
V každém uzlu jsme nastavili parametr, který určuje, jak často bude démon repmgr protokolovat stavovou zprávu. V tomto případě to nastavujeme na každých 60 sekund:
log_status_interval =60
Krok 4:Spuštění démona repmgr
S parametry nyní nastavenými v clusteru a uzlu svědka provedeme suché spuštění příkazu ke spuštění démona repmgr. Nejprve to otestujeme v primárním uzlu a poté ve dvou pohotovostních uzlech a následně v uzlu svědka. Příkaz musí být proveden jako uživatel postgres:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf spuštění démona --dry-run
Výstup by měl vypadat takto:
INFO:předpoklady pro spuštění repmgrd splněny DETAIL:Bude proveden následující příkaz: sudo /usr/bin/systemctl start repmgr12.service
Dále spustíme démona ve všech čtyřech uzlech:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf spuštění démona
Výstup v každém uzlu by měl ukazovat, že se démon spustil:
UPOZORNĚNÍ:provádění:"sudo /usr/bin/systemctl start repmgr12.service"UPOZORNĚNÍ:repmgrd byl úspěšně spuštěn
Můžeme také zkontrolovat událost spuštění služby z primárních nebo pohotovostních uzlů:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf událost clusteru --event=repmgrd_start
Výstup by měl ukazovat, že démon monitoruje připojení:
ID uzlu | Jméno | Akce | OK | Časové razítko | Podrobnosti--------+-----------------+----------------+----+- --------------------+----------------------------- -------------------------------------4 | PG-Node-Witness | repmgrd_start | t | 2020-02-05 11:37:31 | Svědecké monitorování připojení k primárnímu uzlu "PG-Node1" (ID:1) 3 | PG-Node3 | repmgrd_start | t | 2020-02-05 11:37:24 | monitorování připojení k upstreamovému uzlu "PG-Node1" (ID:1) 2 | PG-Node2 | repmgrd_start | t | 2020-02-05 11:37:19 | monitorování připojení k upstreamovému uzlu "PG-Node1" (ID:1) 1 | PG-Uzel1 | repmgrd_start | t | 2020-02-05 11:37:14 | monitorování primárního clusteru "PG-Node1" (ID:1)
Nakonec můžeme zkontrolovat výstup démona ze syslogu v libovolném pohotovostním režimu:
# cat /var/log/messages | grep repmgr | méně
Zde je výstup z PG-Node3:
Únor 5 11:37:24 PG-Node3 repmgrd[2014]:[2020-02-05 11:37:24] [UPOZORNĚNÍ] pomocí poskytnutého konfiguračního souboru "/etc/repmgr/12/repmgr.conf"Feb 5 11:37:24 PG-Node3 repmgrd[2014]:[2020-02-05 11:37:24] [POZNÁMKA] spouštění repmgrd (repmgrd 5.0.0) Feb 5 11:37:24 PG-Node3 repmgrd[2014]:[2020-02-05 11:37:24] [INFO] připojování k databázi "host=16.0.3.52 user=repmgr dbname=repmgr connect_timeout=2"Feb 5 11:37:24 PG-Node3 systemd[1]:repmgr12.service:Nelze otevřít soubor PID /run/repmgr/repmgrd-12.pid (zatím?) po spuštění:Žádný takový soubor nebo adresářFeb 5 11:37 :24 PG-Node3 repmgrd[2014]:INFO: set_repmgrd_pid():za předpokladu, že soubor pid je /run/repmgr/repmgrd-12.pid Feb 5 11:37:24 PG-Node3 repmgrd[2014]:[2020-02-05 11:37:24] [UPOZORNĚNÍ] spouští monitorování uzlu "PG-Node3" (ID:3) Feb 5 11:37:24 PG-Node3 repmgrd[2014]:[2020-02-05 11:37:24] [INFO] "connection_check_type" nastaveno na "ping" Feb 5 11:37:24 PG-Node3 repmgrd[2014]:[2020-02-05 11:37:24] [INFO] monitorování připojení k upstream uzlu "PG-Node1" (ID:1) Feb 5 11:38:25 PG-Node3 repmgrd[2014]:[2020-02-05 11:38:25] [INFO] uzel "PG-Node3" (ID:3) monitoring upstream uzel "PG- Node1" (ID:1) v normálním stavu Feb 5 11:38:25 PG-Node3 repmgrd[2014]:[2020-02-05 11:38:25] [DETAIL] poslední aktualizace statistik sledování byla provedena před 2 sekundami Feb 5 11:39:26 PG-Node3 repmgrd[2014]:[2020-02-05 11:39:26] [INFO] uzel "PG-Node3" (ID:3) monitorování upstream uzel "PG- Node1" (ID:1) v normálním stavu … …
Kontrola syslog v primárním uzlu ukazuje jiný typ výstupu:
Únor 5 11:37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [UPOZORNĚNÍ] pomocí poskytnutého konfiguračního souboru "/etc/repmgr/12/repmgr.conf"Feb 5 11:37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [UPOZORNĚNÍ] spouštění repmgrd (repmgrd 5.0.0) Feb 5 11:37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [INFO] připojování k databázi "host=16.0.1.156 user=repmgr dbname=repmgr connect_timeout=2"Feb 5 11:37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [UPOZORNĚNÍ] spouští monitorování uzlu "PG-Node1" (ID:1) Feb 5 11:37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [INFO] "connection_check_type" nastaveno na "ping" Feb 5 11:37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [UPOZORNĚNÍ] primární monitorovací cluster "PG-Node1" (ID:1) Únor 5 11:37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [INFO] podřízený uzel "PG-Node-Witness" (ID:4) ještě není připojen 5. února 11 :37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [INFO] podřízený uzel "PG-Node3" (ID:3) je připojen Feb 5 11:37:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:14] [INFO] podřízený uzel „PG-Node2“ (ID:2) je připojen Feb 5 11:37:32 PG-Node1 repmgrd[2017]:[2020-02-05 11:37:32] [NOTICE] nový svědek „PG-Node-Witness“ (ID:4) se připojil Feb 5 11:38:14 PG-Node1 repmgrd[2017]:[2020-02-05 11:38:14] [INFO] monitorování primárního uzlu "PG-Node1" (ID:1) v normálním stavu Feb 5 11:39:15 PG-Node1 repmgrd[2017]:[2020-02-05 11:39:15] [INFO] monitorování primárního uzlu "PG-Node1" (ID:1) v normálním stavu … …
Krok 5:Simulace neúspěšné primární volby
Nyní budeme simulovat selhání primárního uzlu zastavením primárního uzlu (PG-Node1). Z příkazového řádku uzlu spustíme následující příkaz:
# systemctl stop postgresql-12.service
Proces převzetí služeb při selhání
Jakmile se proces zastaví, počkáme asi minutu nebo dvě a poté zkontrolujeme soubor syslog PG-Node2. Zobrazí se následující zprávy. Pro přehlednost a jednoduchost jsme barevně odlišili skupiny zpráv a přidali mezery mezi řádky:
… 5. února 11:53:36 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:36] [VAROVÁNÍ] nelze odeslat příkaz ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr" 5. února 11:53:36 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:3] DETAIL] PQping() vrátilo "PQPING_NO_RESPONSE" Feb 5 11:53:36 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:36] [INFO] spí 8 sekund do dalšího pokusu o opětovné připojení Feb 5 11:53:44 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:44] [INFO] kontrola stavu uzlu 1, 2 ze 4 pokusů Feb 5 11:53:44 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:44] [VAROVÁNÍ] nelze odeslat příkaz ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr" 5. února 11:53:44 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:4] DETAIL] PQping() vrátilo "PQPING_NO_RESPONSE" Feb 5 11:53:44 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:44] [INFO] spí 8 sekund do dalšího pokusu o opětovné připojení Feb 5 11:53:52 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:52] [INFO] kontrola stavu uzlu 1, 3 ze 4 pokusů Únor 5 11:53:52 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:52] [VAROVÁNÍ] nelze odeslat příkaz ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr" 5. února 11:53:52 PG-Node2 repmgrd[2165]:[2020-02-05 12:53:5 DETAIL] PQping() vrátilo "PQPING_NO_RESPONSE" Feb 5 11:53:52 PG-Node2 repmgrd[2165]:[2020-02-05 11:53:52] [INFO] spí 8 sekund do dalšího pokusu o opětovné připojení Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] kontrola stavu uzlu 1, 4 ze 4 pokusů Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [VAROVÁNÍ] nelze odeslat příkaz ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr" 5. února 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:0 DETAIL] PQping() vrátilo "PQPING_NO_RESPONSE" Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [VAROVÁNÍ] nelze se znovu připojit k uzlu 1 po 4 pokusech Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [NOTICE] nastavení "wal_retrieve_retry_interval" na 86405000 milisekund Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [VAROVÁNÍ] wal přijímač neběží Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [UPOZORNĚNÍ] Přijímač WAL odpojen na všech sourozeneckých uzlech Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] Přijímač WAL odpojen na všech 2 sourozeneckých uzlech Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] poslední příjem místního uzlu lsn:0/2214A000 Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] kontroluje stav sourozeneckého uzlu "PG-Node3" (ID:3) Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] uzel "PG-Node3" (ID:3) hlásí, že jeho upstream je uzel 1 , naposledy online před 26 sekundami Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] uzel 3 naposledy viděl primární uzel před 26 sekundami Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] poslední příjem LSN pro sourozenecký uzel „PG-Node3“ (ID:3) je :0/2214A000 Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] uzel "PG-Node3" (ID:3) má stejné LSN jako aktuální kandidát "PG-Node2" (ID:2) Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] uzel "PG-Node3" (ID:3) má nižší prioritu (40) než aktuální kandidát "PG-Node2" (ID:2) (60) Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] kontroluje stav sourozeneckého uzlu "PG-Node-Witness" (ID:4) Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] uzel „PG-Node-Witness“ (ID:4) hlásí, že jeho upstream je uzel 1, naposledy viděn před 26 sekundami Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] uzel 4 naposledy viděl primární uzel před 26 sekundami Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [INFO] viditelné uzly:3; celkový počet uzlů:3; žádné uzly neviděly primární během posledních 4 sekund ……únor 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [NOTICE] kandidát na povýšení je "PG-Node2" (ID:2) Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [NOTICE] nastavení "wal_retrieve_retry_interval" na 5000 ms Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [UPOZORNĚNÍ] tento uzel je vítěz, nyní se bude propagovat a informovat ostatní uzly …… Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [UPOZORNĚNÍ] podpora pohotovostního režimu na primární Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [DETAIL] propagující server "PG-Node2" (ID:2) pomocí pg_promote() Feb 5 11:54:00 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:00] [NOTICE] čekání až 60 sekund (parametr "promote_check_timeout") na dokončení povýšení Feb 5 11:54:01 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:01] [NOTICE] STANDBY PROMOTE úspěšná Feb 5 11:54:01 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:01] [DETAIL] server "PG-Node2" (ID:2) byl úspěšně povýšen na primární Feb 5 11:54:01 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:01] [INFO] 2 sledující pro oznámení Feb 5 11:54:01 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:01] [NOTICE] oznamující uzel "PG-Node3" (ID:3), aby následoval uzel 2 Feb 5 11:54:01 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:01] [NOTICE] oznamující uzel „PG-Node-Witness“ (ID:4), aby následoval uzel 2 Feb 5 11:54:01 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:01] [INFO] přepnutí do režimu primárního monitorování Feb 5 11:54:01 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:01] [UPOZORNĚNÍ] primární monitorovací cluster "PG-Node2" (ID:2) Feb 5 11:54:07 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:07] [NOTICE] nový svědek „PG-Node-Witness“ (ID:4) se připojil Feb 5 11:54:07 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:07] [UPOZORNĚNÍ] nový pohotovostní režim "PG-Node3" (ID:3) se připojil Feb 5 11:54:07 PG-Node2 repmgrd[2165]:[2020-02-05 11:54:07] [UPOZORNĚNÍ] nový pohotovostní režim „PG-Node3“ (ID:3) se připojilFeb 5 11:55:02 PG-Node2 repmgrd[2165]:[2020-02-05 11:55:02] [INFO] monitorování primárního uzlu "PG-Node2" (ID:2) v normálním stavu Feb 5 11:56:02 PG-Node2 repmgrd[2165]:[2020-02-05 11:56:02] [INFO] monitorování primárního uzlu "PG-Node2" (ID:2) v normálním stavu … …
There is a lot of information here, but let’s break down how the events have unfolded. For simplicity, we have grouped messages and placed whitespaces between the groups.
The first set of messages shows the repmgr daemon is trying to connect to the primary node (node ID 1) four times using PQPing(). This is because we specified the connection_check_type parameter to “ping” in the repmgr.conf file. After 4 attempts, the daemon reports it cannot connect to the primary node.
The next set of messages tells us the standbys have disconnected their WAL receivers. This is because we had set the parameter standby_disconnect_on_failover to “true” in the repmgr.conf file.
In the next set of messages, the standby nodes and the witness inquire about the last received LSN from the primary and the last time each saw the primary. The last received LSNs match for both the standby nodes. The nodes agree they cannot see the primary within the last 4 seconds. Note how repmgr daemon also finds PG-Node3 has a lower priority for promotion. As none of the nodes have seen the primary recently, they can reach a quorum that the primary is down.
After this, we have messages that show repmgr is choosing PG-Node2 as the promotion candidate. It declares the node winner and says the node will promote itself and inform other nodes.
The group of messages after this shows PG-Node2 successfully promoting to the primary role. Once that’s done, the nodes PG-Node3 (node ID 3) and PG-Node-Witness (node ID 4) are signaled to follow the newly promoted primary.
The final set of messages shows the two nodes have connected to the new primary and the repmgr daemon has started monitoring the local node.
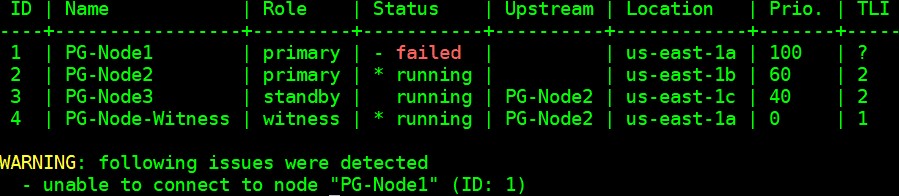
Our cluster is now back in action. We can confirm this by running the “repmgr cluster show” command:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster show --compact
The output shown in the image below is self-explanatory:
We can also look for the events by running the “repmgr cluster event” command:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster event
The output displays how it happened:
Node ID | Name | Event | OK | Timestamp | Details --------+-----------------+----------------------------+----+---------------------+------------------------------------------------------------------------------------3 | PG-Node3 | repmgrd_failover_follow | t | 2020-02-05 11:54:08 | node 3 now following new upstream node 2 3 | PG-Node3 | standby_follow | t | 2020-02-05 11:54:08 | standby attached to upstream node "PG-Node2" (ID:2) 2 | PG-Node2 | child_node_new_connect | t | 2020-02-05 11:54:07 | new standby "PG-Node3" (ID:3) has connected 2 | PG-Node2 | child_node_new_connect | t | 2020-02-05 11:54:07 | new witness "PG-Node-Witness" (ID:4) has connected 4 | PG-Node-Witness | repmgrd_upstream_reconnect | t | 2020-02-05 11:54:02 | witness monitoring connection to primary node "PG-Node2" (ID:2) 4 | PG-Node-Witness | repmgrd_failover_follow | t | 2020-02-05 11:54:02 | witness node 4 now following new primary node 2 2 | PG-Node2 | repmgrd_reload | t | 2020-02-05 11:54:01 | monitoring cluster primary "PG-Node2" (ID:2) 2 | PG-Node2 | repmgrd_failover_promote | t | 2020-02-05 11:54:01 | node 2 promoted to primary; old primary 1 marked as failed 2 | PG-Node2 | standby_promote | t | 2020-02-05 11:54:01 | server "PG-Node2" (ID:2) was successfully promoted to primary 1 | PG-Node1 | child_node_new_connect | t | 2020-02-05 11:37:32 | new witness "PG-Node-Witness" (ID:4) has connected
Závěr
This completes our two-part series on repmgr and its daemon repmgrd. As we saw in the first part, setting up a multi-node PostgreSQL replication is very simple with repmgr. The daemon makes it even easier to automate a failover. It also automatically redirects existing standbys to follow the new primary. In native PostgreSQL replication, all existing standbys have to be manually configured to replicate from the new primary – automating this process saves valuable time and effort for the DBA.
One thing we have not covered here is “fencing off” the failed primary. In a failover situation, a failed primary needs to be removed from the cluster, and remain inaccessible to client connections. This is to prevent any split-brain situation in the event the old primary accidentally comes back online. The repmgr daemon can work with a connection-pooling tool like pgbouncer to implement the fence-off process. For more information, you can refer to this 2ndQuadrant Github documentation.
Also, after a failover, applications connecting to the cluster need to have their connection strings changed to repoint to the new master. This is a big topic in itself and we will not go into the details here, but one of the methods to address this can be the use of a virtual IP address (and associated DNS resolution) to hide the underlying master node of the cluster.
How to Automate PostgreSQL 12 Replication and Failover with repmgr – Part 1