Tento článek poskytuje krok za krokem průvodce využíváním možností strojového učení s 2UDA. V článku použijeme příklad zvířat k předpovědi, zda se jedná o savce, ptáky, ryby nebo hmyz.
Verze softwaru
K implementaci modelu strojového učení použijeme 2UDA verze 11.6-1. 2UDA verze 11.6-1 kombinuje:
- PostgreSQL 11.6
- Oranžová 3.23.0
Nejnovější verzi 2UDA naleznete zde.
Krok 1:Načtěte tréninkovou datovou sadu do PostgreSQL
Ukázková datová sada, která se používá k trénování našeho modelu, je k dispozici v oficiálním úložišti Orange GitHub zde.
Chcete-li načíst trénovací data do tabulek PostgreSQL, postupujte takto:
- Připojte se k PostgreSQL přes psql, OmniDB nebo jakýkoli jiný nástroj, který znáte.
- Vytvořte tabulku pro uložení našich tréninkových dat . Zde je pojmenován jako training_data.
CREATE TABLE training_data( name VARCHAR (100), hair integer, feathers integer, eggs integer, milk integer, airborne integer, aquatic integer, predator integer, toothed integer, backbone integer, breathes integer, venomous integer, fins integer, legs integer, tail integer, domestic integer, catsize integer, type VARCHAR (100) );
- Vložte trénovací data do tabulky pomocí dotazu COPY. Před provedením dotazu COPY se ujistěte, že PostgreSQL vyžaduje oprávnění ke čtení datového souboru, jinak operace COPY selže.
POZNÁMKA: Ujistěte se, že zadáváte tabulátor mezera mezi jednoduchými uvozovkami za oddělovačem klíčové slovo.
COPY training_data FROM 'Path_to_training_data_file’ with delimiter ' ' csv header;
Snímek obrazovky tréninkové datové sady naleznete níže
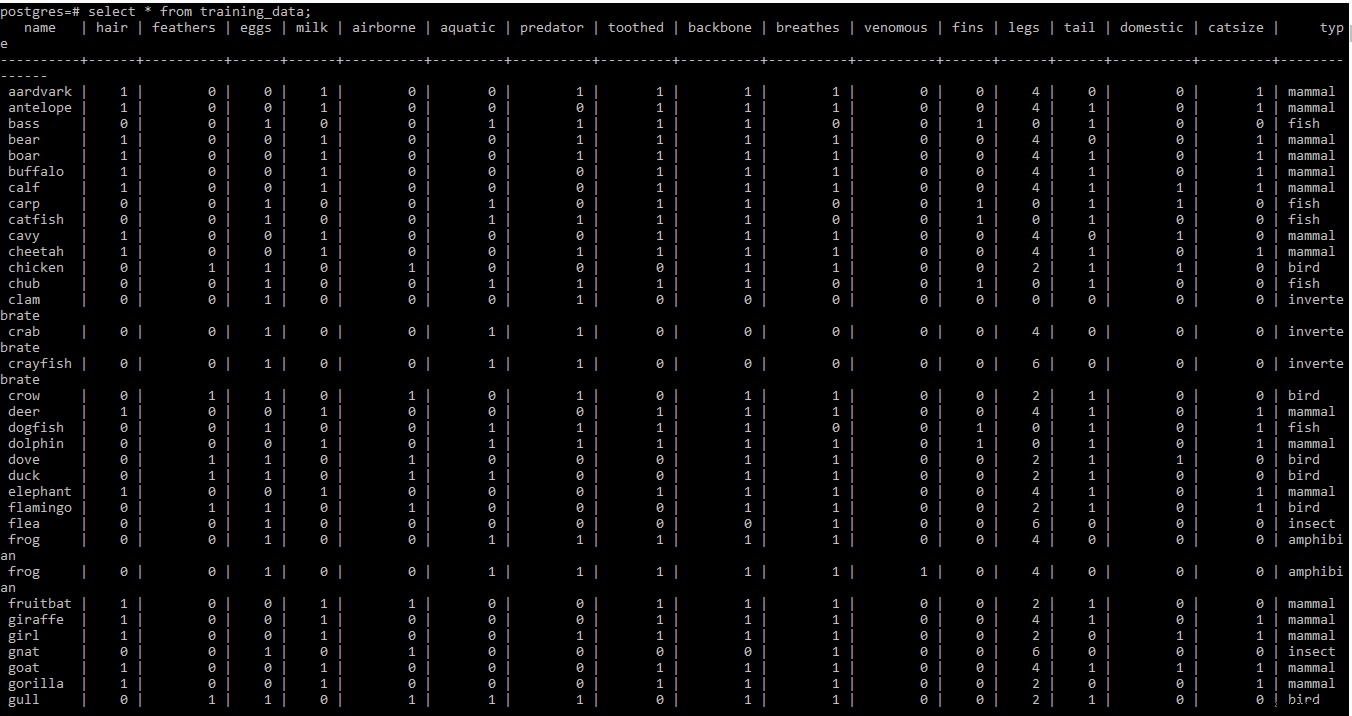
POZNÁMKA: Řádky dva a tři trénovací datové sady na kartě .tab soubor obsahuje nějaké meta informace. Protože v tuto chvíli není potřeba, byl ze souboru odstraněn.
Krok 2:Vytvořte pracovní postup s Orange
- Přejděte na plochu a dvakrát klikněte na oranžovou ikonu.
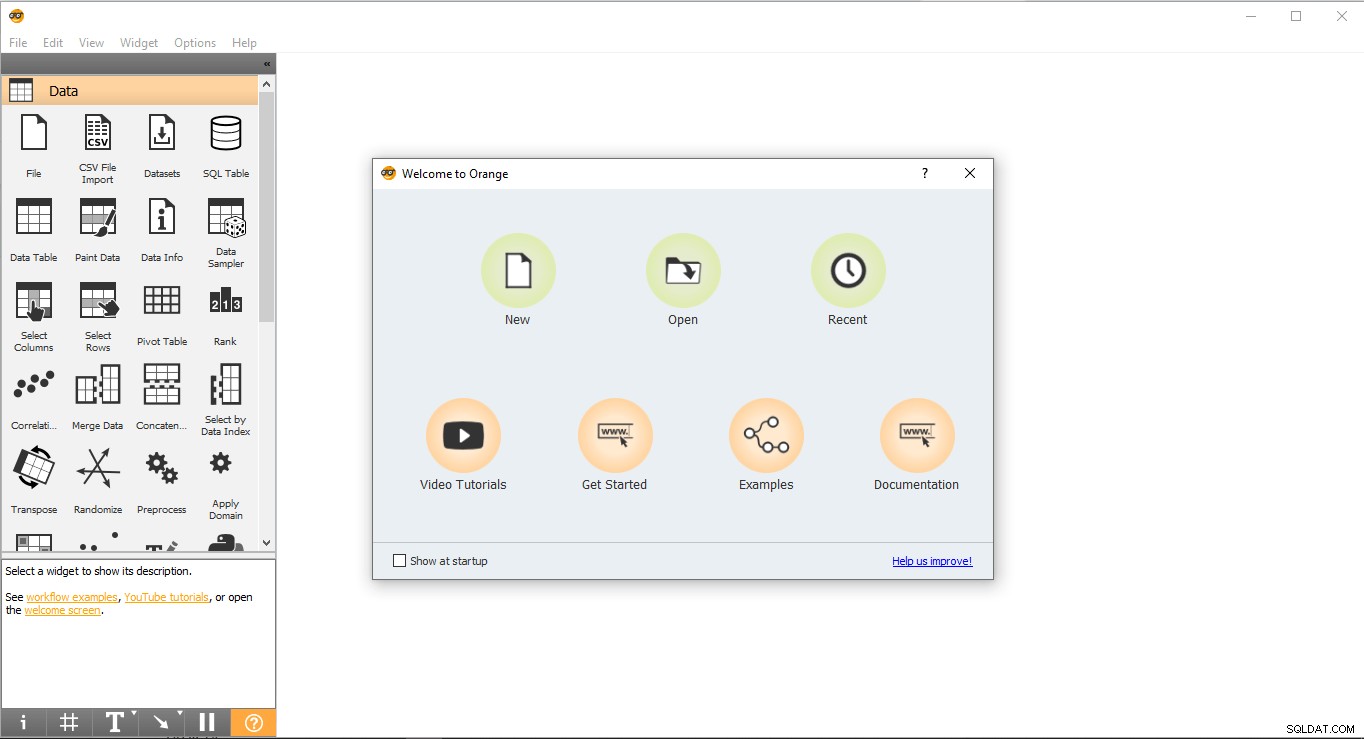
- Takto vypadá úvodní stránka. Vyberte Nový a vytvoří prázdný projekt.

Nyní jste připraveni použít model strojového učení na datovou sadu.
Krok 3:Chcete-li trénovat data, vyberte model strojového učení
U tohoto článku k-nearest sousedé K trénování dat se používá model strojového učení (KNN). Po dokončení procesu trénování dat jsou v dalším kroku testovací data předána do Předpovědi widget pro kontrolu přesnosti předpovědí.
Krok 4:Import tréninkových dat z PostgreSQL do Orange
Tato trénovací datová sada bude použita k trénování modelu strojového učení.
- Přetáhněte Tabulku SQL widget z Data Jídelní lístek.
- Přejmenovat widget (volitelné)
- Klikněte pravým tlačítkem na Tabulku SQL widget.
- Vyberte Přejmenovat .
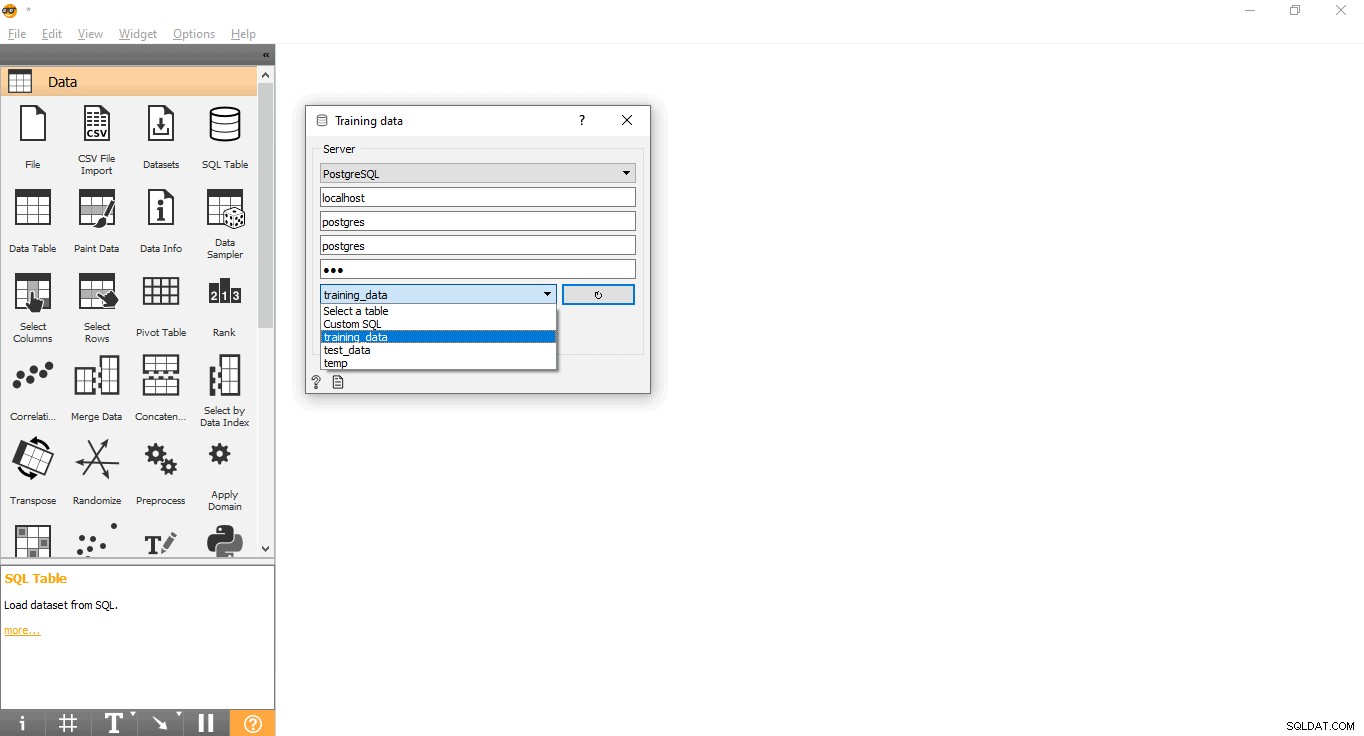
- Připojte se k PostgreSQL a načtěte trénovací datovou sadu:
- Dvakrát klikněte na Údaje o školení widget.
- Zadejte přihlašovací údaje pro připojení k databázi PostgreSQL.
- Stiskněte tlačítko znovu načíst pro načtení všech dostupných tabulek z dané databáze.
- Z rozbalovací nabídky vyberte tabulku training_data a zavřete vyskakovací okno.
Krok 5:Přidejte cílový sloupec
Tento krok je důležitý, protože model strojového učení se pokusí předpovědět data pro tuto cílovou proměnnou/sloupec:
- Přetáhněte Vyberte sloupce widget z dat menu.
- Dvakrát klikněte na Vybrat sloupce widget.
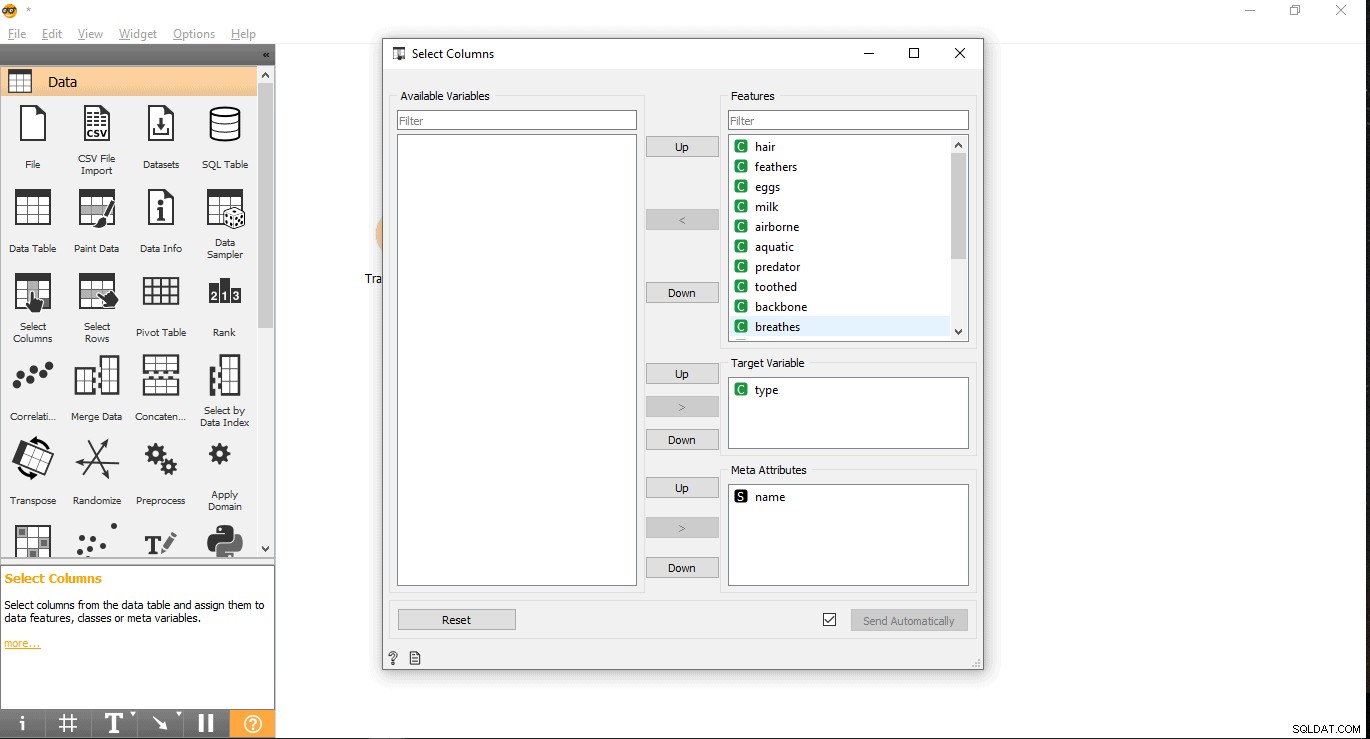
- Vyhledejte cílový sloupec pod štítkem Funkce. Zde se používá typ jako cílovou proměnnou, protože potřebujeme vidět, jaký typ dané zvíře je.
- Přetáhněte ji do části Cílová proměnná a zavřete vyskakovací okno.
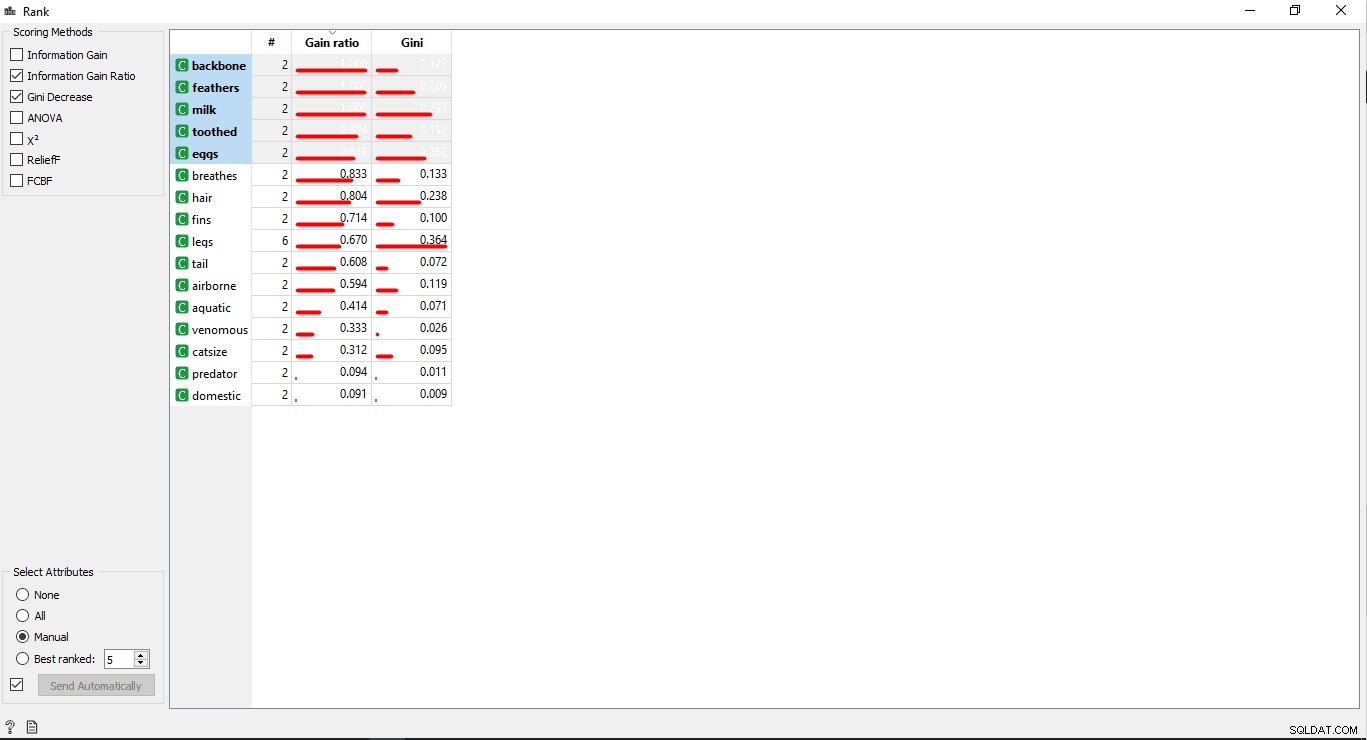
Krok 6:Hodnocení sloupců
Tréninkovou proměnnou/sloupce můžete seřadit nebo ohodnotit podle jejich korelace s cílovým sloupcem.
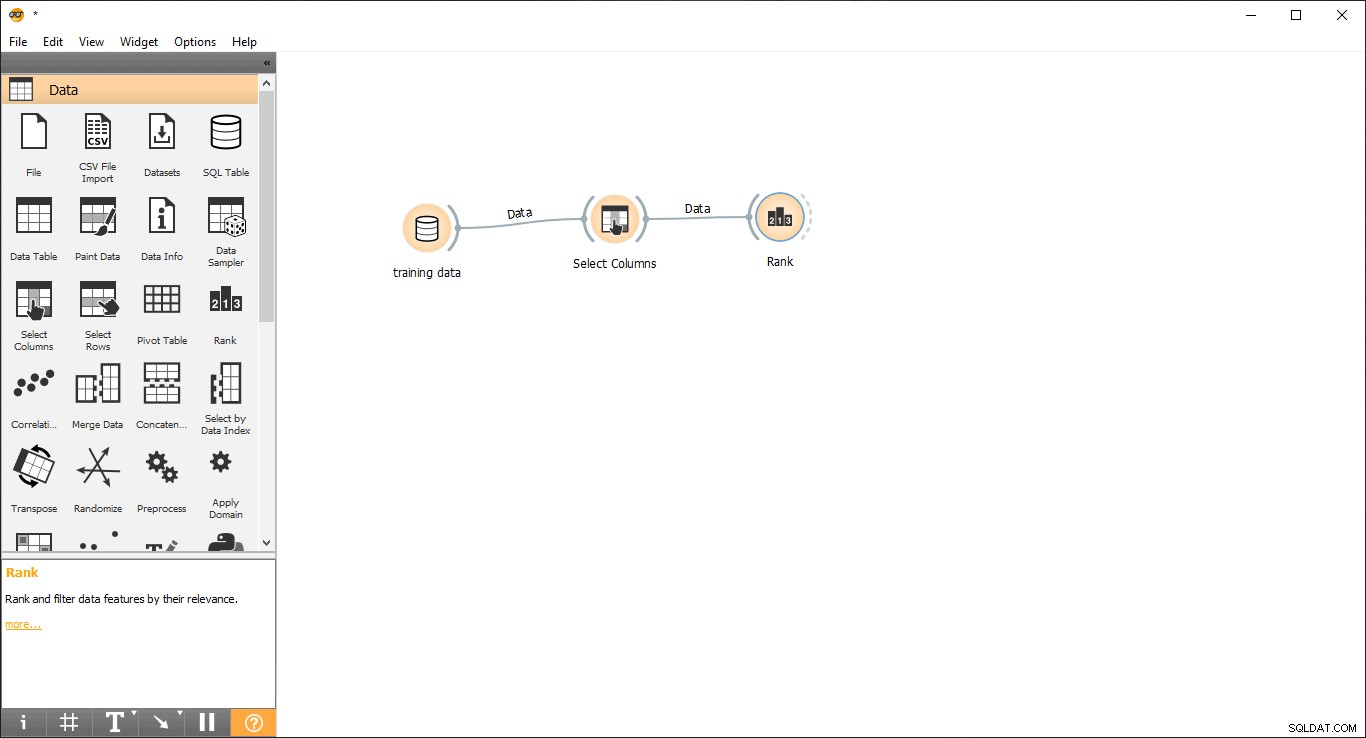
- Přetáhněte Hodnocení widget z dat menu.
- Nakreslete čáru odkazu v části Vybrat sloupce widgetu k hodnocení widget .
- Dvakrát klikněte na Hodnocení widget pro zobrazení nejvíce souvisejících sloupců v tabulce tréninkových dat. Ve výchozím nastavení vybere prvních 5 sloupců.
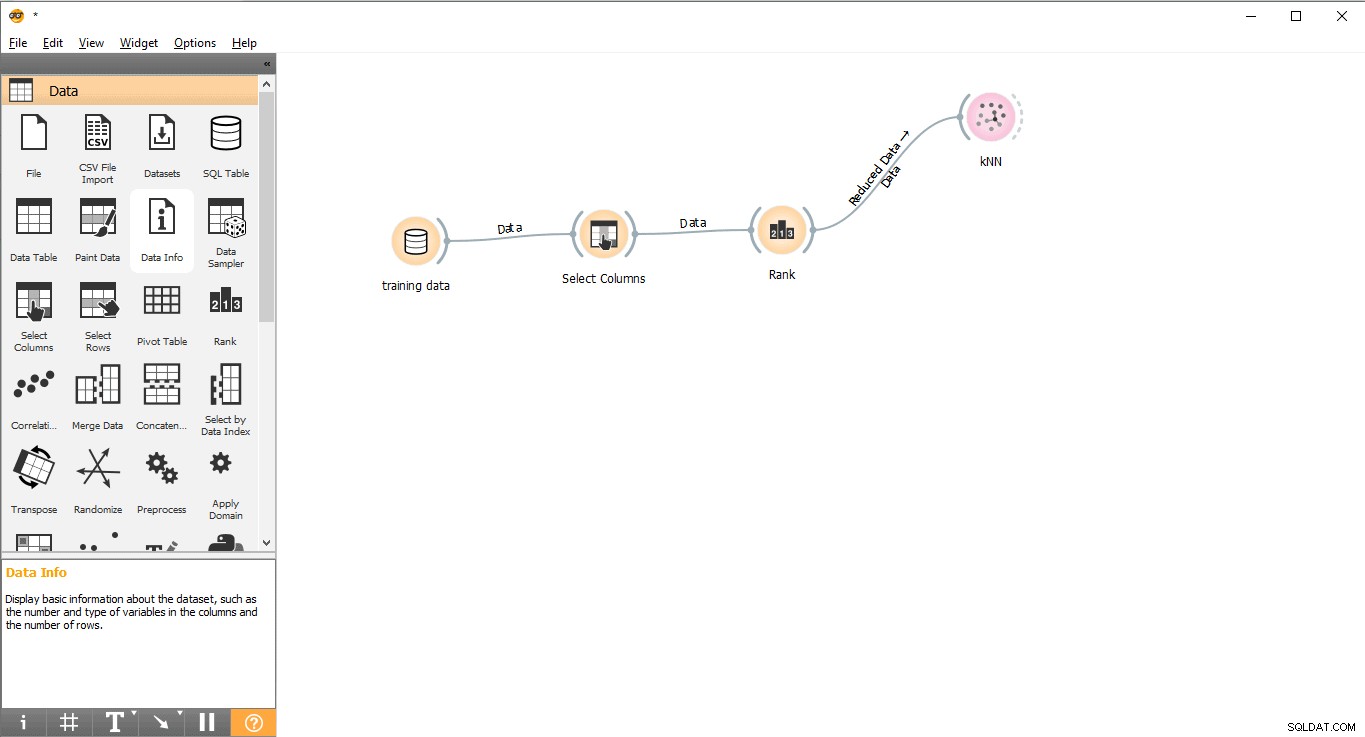
Krok 7:Školení dat
V tomto kroku bude model strojového učení (KNN) trénován pomocí trénovací datové sady. Postupujte prosím podle následujících kroků:
- Přetáhněte KNN widget z Modelu menu.
- Nakreslete linku odkazu z Hodnocení widget na KNN widget.
Krok 8:Načtěte testovací datovou sadu do PostgreSQL
Pro provádění předpovědí je vytvořena samostatná testovací datová sada. Postupujte podle kroků pro načtení testovací datové sady do tabulky PostgreSQL.
- Vytvořte tabulku pro uložení našich testovacích dat . Zde je pojmenována jako test_data.
CREATE TABLE test_data( name VARCHAR (100), hair integer, feathers integer, eggs integer, milk integer, airborne integer, aquatic integer, predator integer, toothed integer, backbone integer, breathes integer, venomous integer, fins integer, legs integer, tail integer, domestic integer, catsize integer, type VARCHAR (100) );
- Vložte testovací data do testovací tabulky pomocí COPY dotaz. Před spuštěním COPY dotaz prosím ujistěte se, že PostgreSQL vyžaduje oprávnění ke čtení datového souboru, jinak operace COPY selže.
POZNÁMKA: Ujistěte se, že zadáváte tabulátor mezera mezi jednoduchými uvozovkami za oddělovačem klíčové slovo. Do typu je záměrně umístěn otazník sloupec testovací datové sady, protože potřebujeme zjistit typ daného zvířete pomocí našeho modelu strojového učení.
COPY test_data FROM 'Path_to_test_data_file’ with delimiter ' ' csv header;
Snímek obrazovky testovací datové sady naleznete níže

Krok 9:Importujte testovací data z PostgreSQL do Orange
Chcete-li použít předpovědi, postupujte podle následujících kroků.
- Přetáhněte Tabulku SQL widget z dat Jídelní lístek.
- Přejmenovat widget (volitelné)
- Klikněte pravým tlačítkem na Tabulku SQL widget.
- Vyberte Přejmenovat .
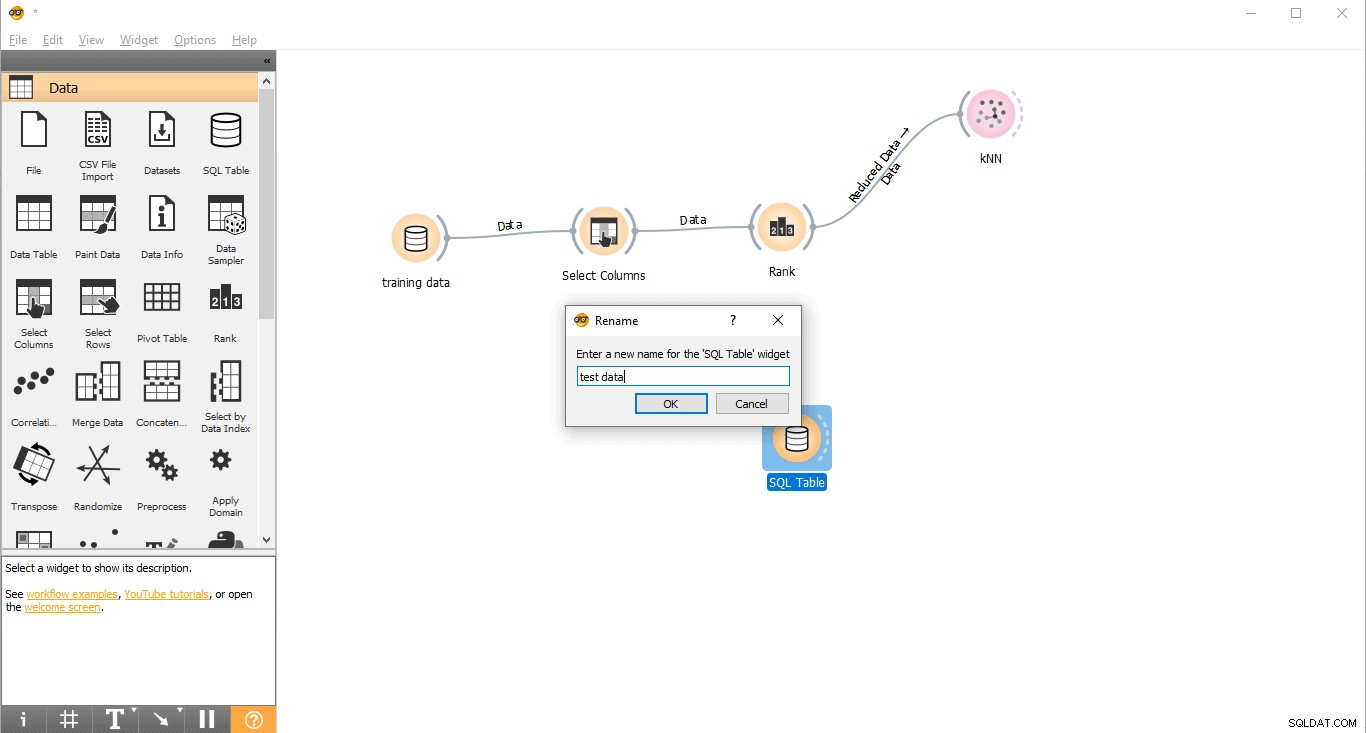
- Připojte se k PostgreSQL a načtěte testovací data.
- Dvakrát klikněte na Testovat data widget.
- Propojte jej s Testovacími daty tabulky z PostgreSQL.
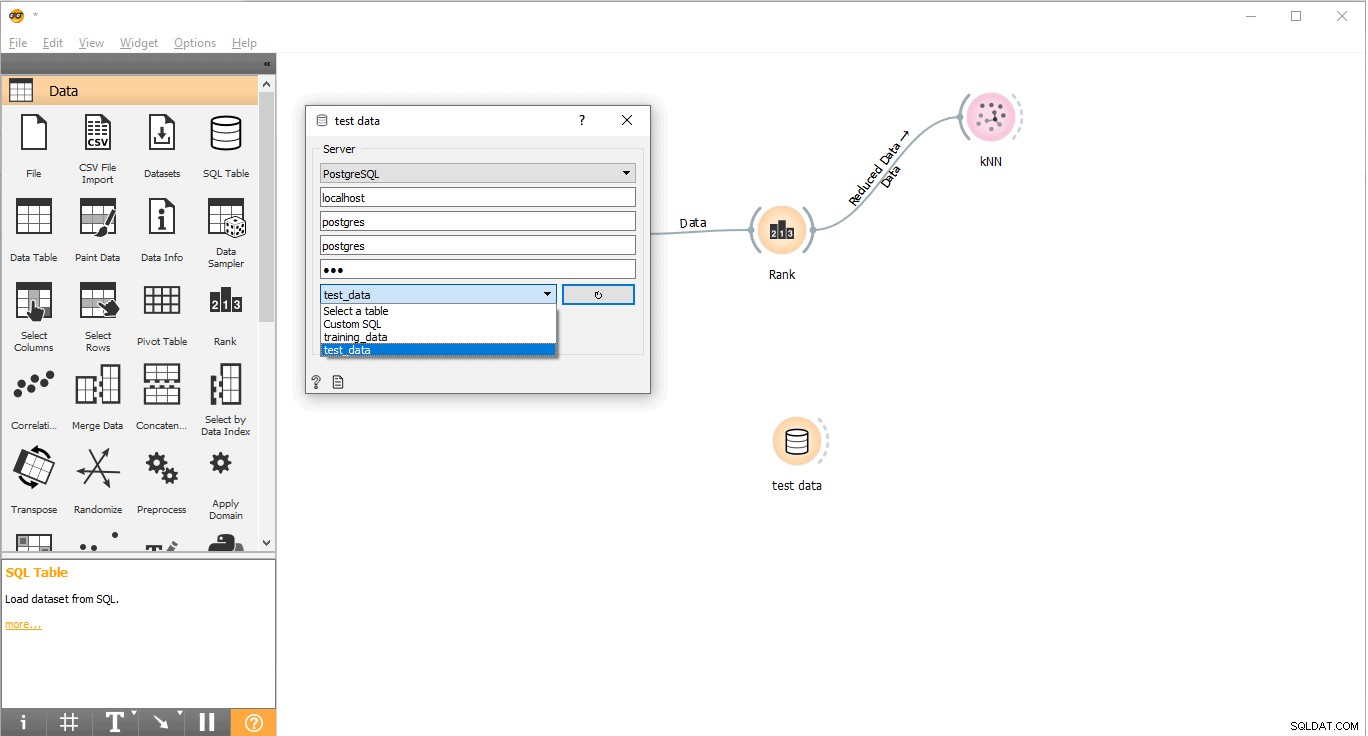
Nyní jsme připraveni provádět předpovědi.
Krok 10:Předpovědi
Předpověď widget se pokusí předpovědět testovací data na základě tréninkových dat z KNN .
- Přetáhněte Předpověď widget z Vyhodnotit menu.
- Nakreslete linku odkazu ve formuláři Testovací data widgetu do Předpovědi widget.
- Nakreslete linku odkazu z KNN widgetu do Předpovědi widget.
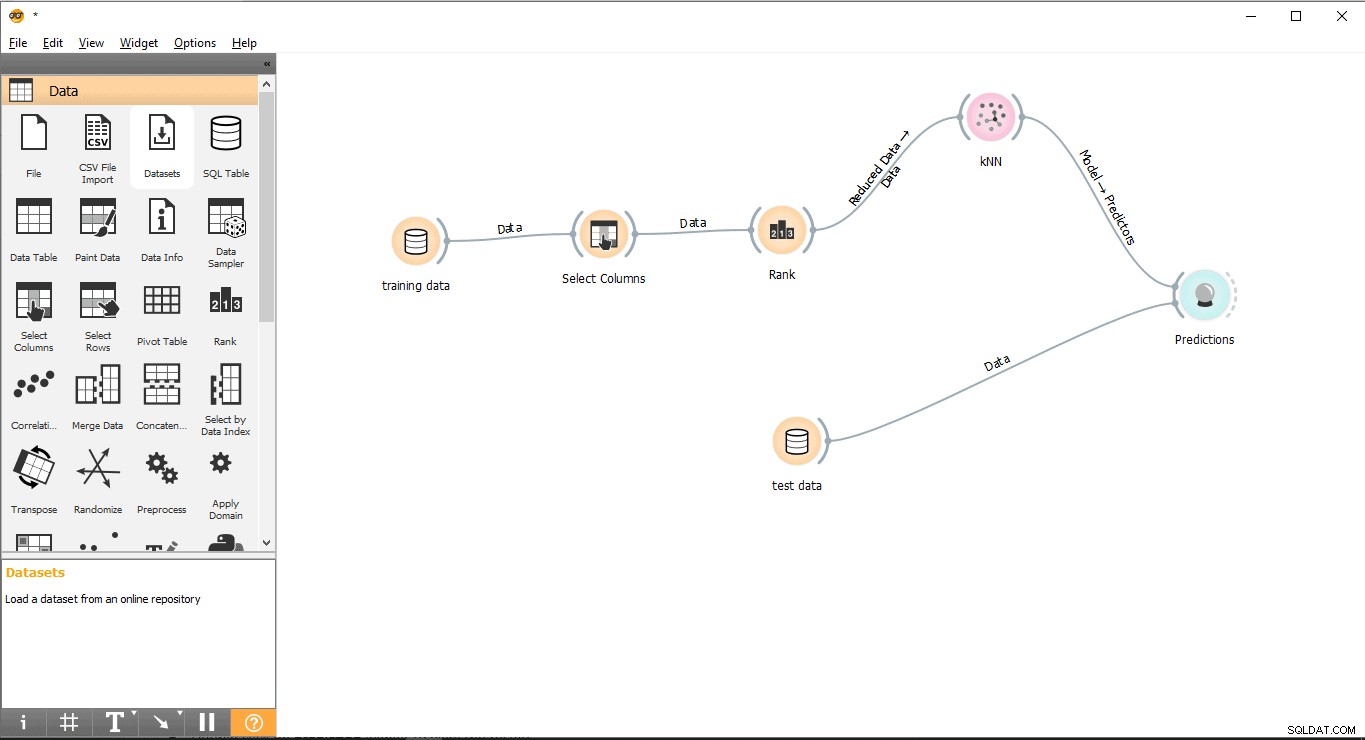
Krok 11:Výsledky
Dvakrát klikněte na Předpověď widget pro zobrazení výsledků.
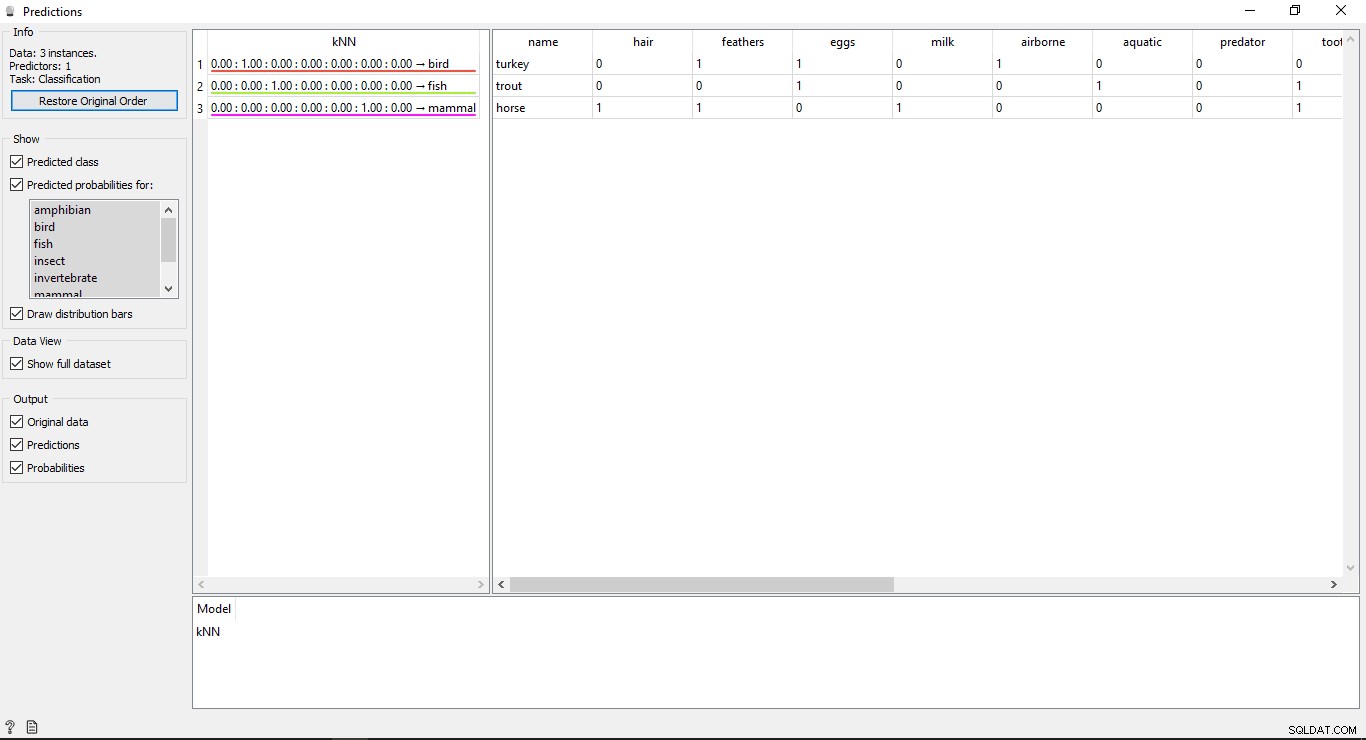
Porozumění výsledkům
V okně predikce uvidíte 2 hlavní tabulky. Tabulka na levé straně ukazuje předpokládané výsledky, zatímco tabulka napravo ukazuje původní testovací data, která byla poskytnuta pro předpovědi.
Od KNN model byl použit k trénování dat, takže uvidíte jeden sloupec s názvem KNN kde jsou uvedeny výsledky.
Jak víme:
- Kůň je Savec
- Pstruh je Ryba
- Turecko je pták
KNN je tedy schopen správně určit všechny typy.
Přesnost předpovědí
Pokud vidíte tabulku na levé straně ve výstupu widgetu predikce, obsahuje některá čísla před predikovaným typem, tj. 1,00. 0,00 Tato čísla ukazují přesnost předpokládaného typu.
V trénovací datové sadě jsme použili 7 typů zvířat, takže ukazuje celkový počet 7 sloupců s hodnotami přesnosti, každý sloupec bude představovat 1 typ zvířete. Chcete-li zkontrolovat, který sloupec představuje jaký typ zvířete, podívejte se na seznam dostupný na levé straně obrazovky v části Předpokládané pravděpodobnosti pro označení. Pokud se podíváte na první řádek, který říká Turecko je pták . Vidíme, že jeho přesnost je 1,00 (100 % z 2. sloupce). Totéž platí pro další příklady Pstruh je Ryba a jeho přesnost je 1,00 (100 % ze 3. sloupce).
V tomto článku jsme použili algoritmus k-nearest sousedů (KNN) k implementaci modelu strojového učení. V příštím blogu budeme používat Support Vector Machine (SVM) model.
V případě jakýchkoli dotazů nebo připomínek nás prosím kontaktujte pomocí kontaktního formuláře zde.