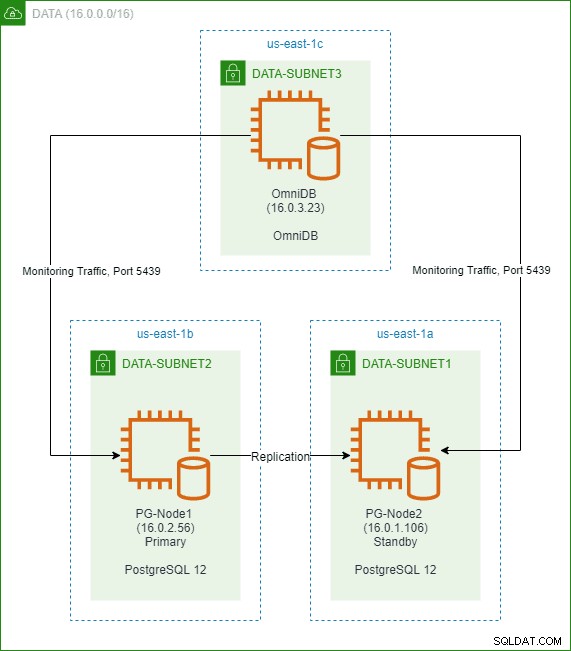
V předchozím článku této série jsme vytvořili dvouuzlový cluster PostgreSQL 12 v cloudu AWS. Také jsme nainstalovali a nakonfigurovali 2ndQuadrant OmniDB ve třetím uzlu. Obrázek níže ukazuje architekturu:
Mohli jsme se připojit k primárnímu i pohotovostnímu uzlu z webového uživatelského rozhraní OmniDB. Poté jsme obnovili ukázkovou databázi nazvanou „dvdrental“ v primárním uzlu, který se začal replikovat do pohotovostního režimu.
V této části seriálu se naučíme, jak vytvořit a používat monitorovací dashboard v OmniDB. DBA a operační týmy často dávají přednost grafickým nástrojům před komplexními dotazy k vizuální kontrole stavu databáze. OmniDB přichází s řadou důležitých widgetů, které lze snadno použít v monitorovacím panelu. Jak uvidíme později, umožňuje také uživatelům psát své vlastní monitorovací widgety.
Vytvoření řídicího panelu sledování výkonu
Začněme výchozím řídicím panelem, který OmniDB obsahuje.
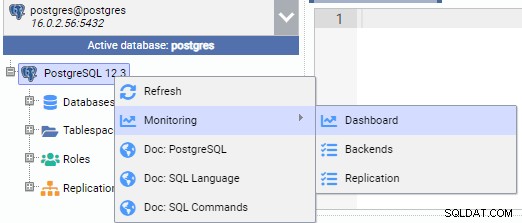
Na obrázku níže jsme připojeni k primárnímu uzlu (PG-Node1). Klikneme pravým tlačítkem myši na název instance a poté z vyskakovací nabídky vybereme „Monitor“ a poté „Dashboard“.
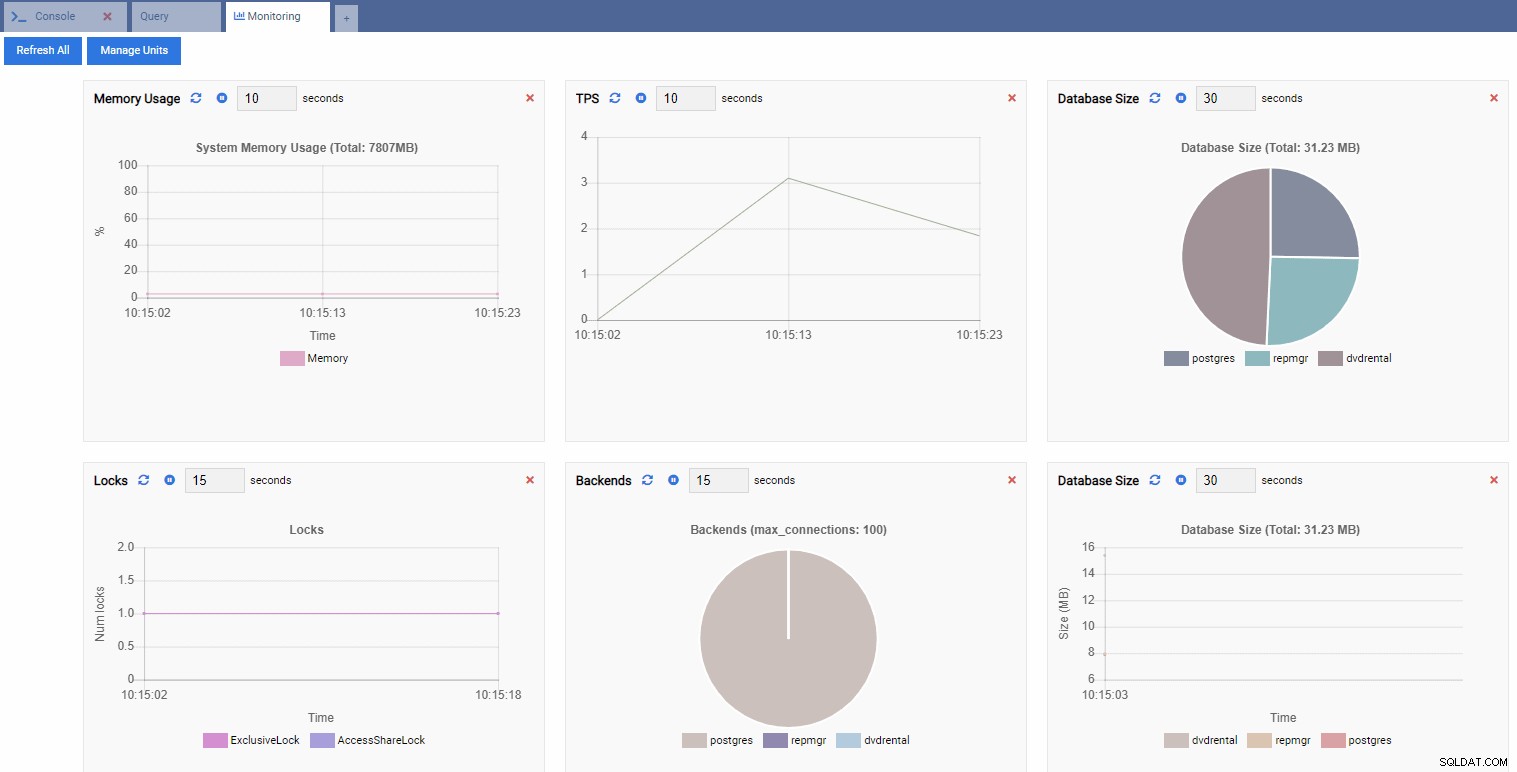
Tím se otevře řídicí panel s některými widgety.
V podmínkách OmniDB se obdélníkové widgety na řídicím panelu nazývají Monitorovací jednotky . Každá z těchto jednotek zobrazuje specifickou metriku z instance PostgreSQL, ke které je připojena, a dynamicky aktualizuje svá data.
Porozumění monitorovacím jednotkám
OmniDB se dodává se čtyřmi typy monitorovacích jednotek:
- Mřížka je tabulková struktura, která zobrazuje výsledek dotazu. Může to být například výstup SELECT * FROM pg_stat_replication. Mřížka vypadá takto:
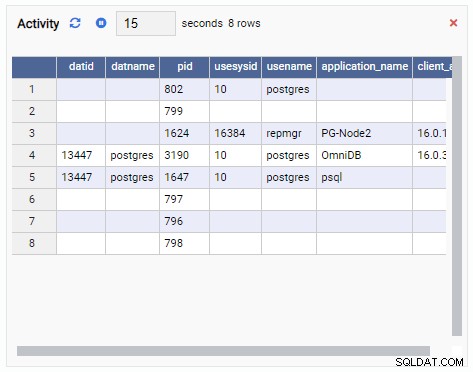
- Graf zobrazuje data v grafickém formátu, jako jsou čárové nebo koláčové grafy. Když se obnoví, celý graf se na obrazovce překreslí s novou hodnotou a stará hodnota je pryč. Pomocí těchto monitorovacích jednotek můžeme vidět pouze aktuální hodnotu metriky. Zde je příklad grafu:
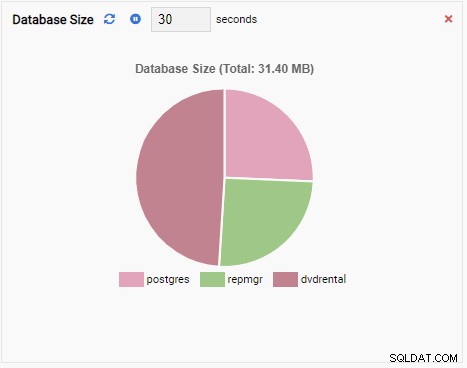
- Příloha ke grafu je také monitorovací jednotkou typu grafu, kromě toho, když se aktualizuje, připojí novou hodnotu ke stávající řadě. Pomocí Chart-Append můžeme snadno vidět trendy v čase. Zde je příklad:
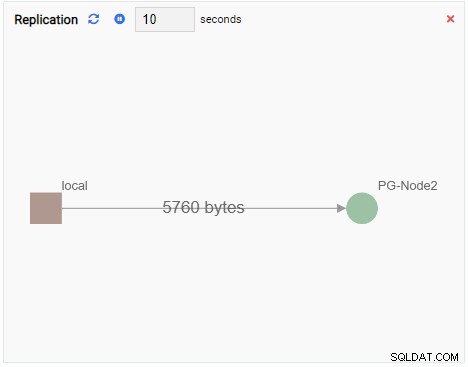
- Graf ukazuje vztahy mezi instancemi clusteru PostgreSQL a související metrikou. Stejně jako jednotka pro sledování grafů i jednotka pro sledování grafů obnovuje svou starou hodnotu novou. Obrázek níže ukazuje, že aktuální uzel (PG-Node1) se replikuje do PG-Node2:
Každá monitorovací jednotka má řadu společných prvků:
- Název monitorovací jednotky
- Tlačítko „Obnovit“ pro ruční obnovení jednotky
- Tlačítko „pozastavit“ pro dočasné zastavení obnovování monitorovací jednotky
- Textové pole zobrazující aktuální interval obnovení. Toto lze změnit
- Tlačítko „zavřít“ (červený křížek) pro odstranění monitorovací jednotky z řídicího panelu
- Aktuální oblast kreslení monitoru
Předpřipravené monitorovací jednotky
OmniDB přichází s řadou monitorovacích jednotek pro PostgreSQL, které můžeme přidat na náš dashboard. Pro přístup k těmto jednotkám klikneme na tlačítko „Spravovat jednotky“ v horní části řídicího panelu:
Otevře se seznam „Správa jednotek“:
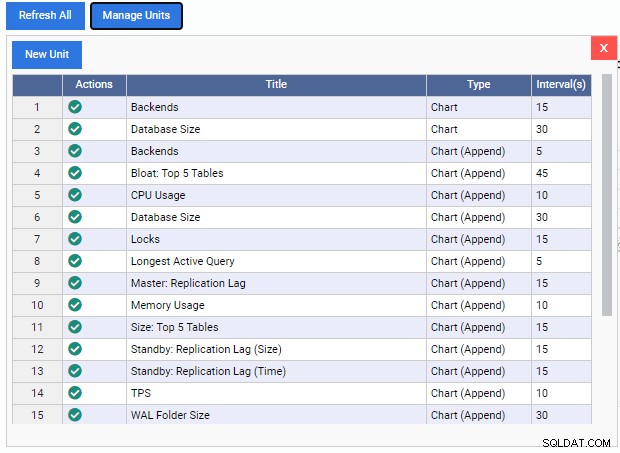
Jak vidíme, je zde několik předpřipravených monitorovacích jednotek. Kódy pro tyto monitorovací jednotky jsou volně ke stažení z repozitáře GitHub společnosti 2ndQuadrant. Každá jednotka zde uvedená zobrazuje svůj název, typ (Chart, Chart Append, Graph nebo Grid) a výchozí obnovovací frekvenci.
Chcete-li přidat monitorovací jednotku na řídicí panel, stačí kliknout na zelenou značku zaškrtnutí ve sloupci „Akce“ pro tuto jednotku. Můžeme kombinovat různé monitorovací jednotky a vytvořit tak řídicí panel, jaký chceme.
Na obrázku níže jsme přidali následující jednotky pro náš řídicí panel sledování výkonu a odstranili vše ostatní:
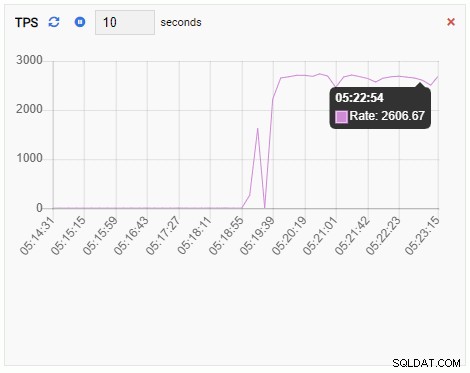
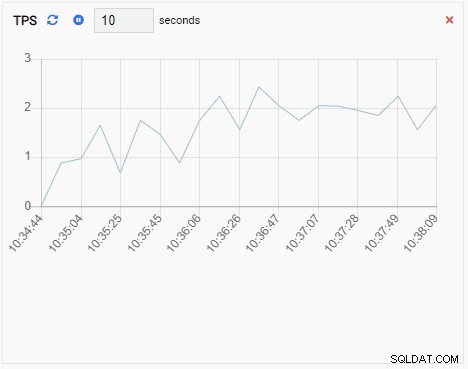
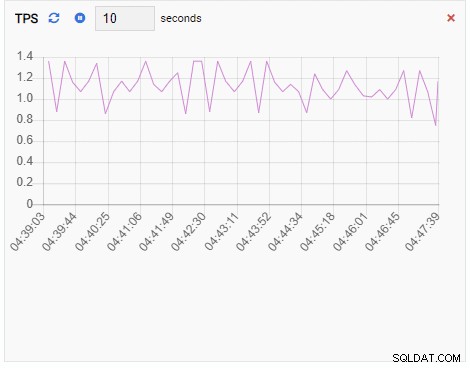
TPS (transakce za sekundu):
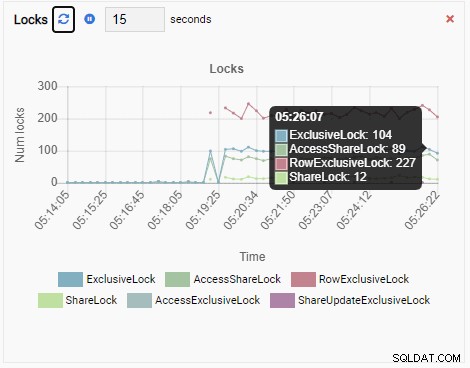
Počet zámků:
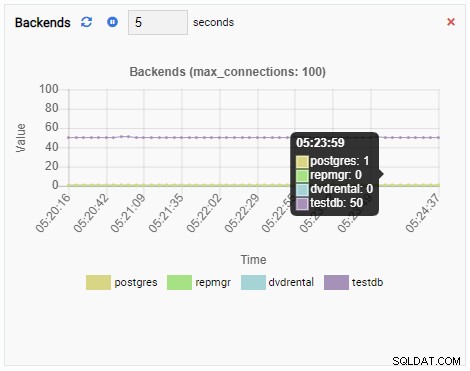
Počet backendů:
Protože je naše instance nečinná, vidíme, že hodnoty TPS, Locks a Backends jsou minimální.
Testování řídicího panelu monitorování
Nyní spustíme pgbench v našem primárním uzlu (PG-Node1). pgbench je jednoduchý nástroj pro srovnávání, který je dodáván s PostgreSQL. Stejně jako většina ostatních nástrojů svého druhu vytváří pgbench při inicializaci vzorové schéma a tabulky systémů OLTP v databázi. Poté může emulovat více klientských připojení, z nichž každé spouští určitý počet transakcí v databázi. V tomto případě nebudeme srovnávat primární uzel PostgreSQL; vytvoříme pouze databázi pro pgbench a uvidíme, zda naše monitorovací jednotky dashboardu zachytí změnu stavu systému.
Nejprve vytváříme databázi pro pgbench v primárním uzlu:
[example@sqldat.com ~]$ psql -h PG-Node1 -U postgres -c "CREATE DATABASE testdb";CREATE DATABASE
Dále inicializujeme databázi „testdb“ pro pgbench:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/pgbench -h PG-Node1 -p 5432 -I dtgvp -i -s 20 testdbhození starých tabulek...vytváření tabulek...generování data...100 000 z 2000000 n-tic (5 %) hotovo (uplynulo 0,02 s, zbývajících 0,43 s) 200 000 z 2000 000 n-tic (10 %) hotovo (uplynulo 0,05 s, zbývajících 0,41 s)…2 000 0000 z 20 %) hotovo (uplynulo 1,84 s, zbývá 0,00 s) vysávání...vytváření primárních klíčů...hotovo.
S inicializací databáze nyní zahájíme vlastní proces načítání. Ve úryvku kódu níže žádáme pgbench, aby začal s 50 souběžnými klientskými připojeními k databázi testdb, přičemž každé připojení provádí 100 000 transakcí ve svých tabulkách. Zátěžový test bude probíhat ve dvou vláknech.
[example@sqldat.com ~]$ /usr/pgsql-12/bin/pgbench -h PG-Node1 -p 5432 -c 50 -j 2 -t 100000 testdbspuštění vakua...konec.……Pokud se nyní vrátíme k našemu řídicímu panelu OmniDB, uvidíme, že monitorovací jednotky vykazují velmi odlišné výsledky.
Metrika TPS vykazuje poměrně vysokou hodnotu. Došlo k náhlému skoku z méně než 2 na více než 2000:
Počet backendů se zvýšil. Podle očekávání má testdb proti němu 50 připojení, zatímco ostatní databáze jsou nečinné:
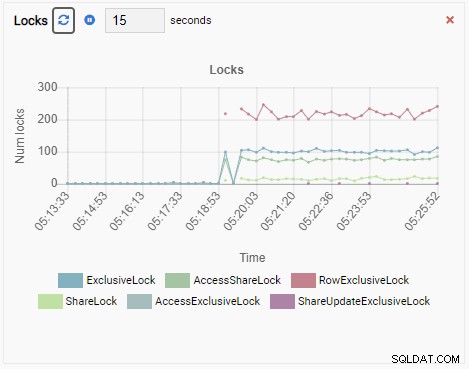
A konečně, počet výlučných zámků řádků v databázi testdb je také vysoký:
A teď si to představ. Jste DBA a používáte OmniDB pro správu flotily instancí PostgreSQL. V jednom z případů obdržíte výzvu k prošetření pomalého výkonu.
Pomocí řídicího panelu, jako je ten, který jsme právě viděli (ačkoli je to velmi jednoduché), můžete snadno najít hlavní příčinu. Můžete zkontrolovat počet backendů, zámků, dostupné paměti atd. a zjistit, co problém způsobuje.
A to je místo, kde může být OmniDB opravdu užitečným nástrojem.
Vytvoření vlastních monitorovacích jednotek
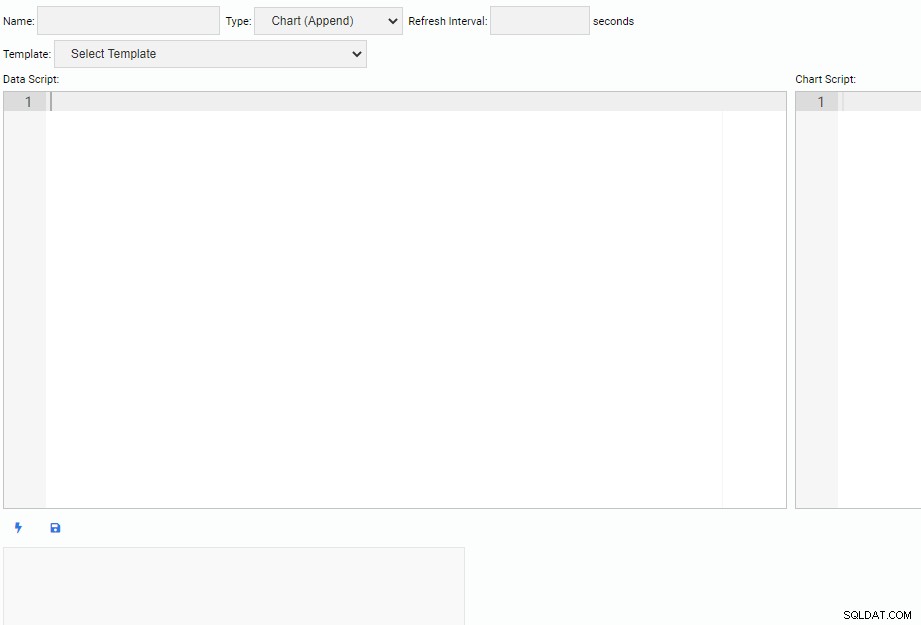
Někdy budeme muset vytvořit vlastní monitorovací jednotky. Pro vytvoření nové monitorovací jednotky klikneme na tlačítko „Nová jednotka“ v seznamu „Spravovat jednotky“. Tím se otevře nová karta s prázdným plátnem pro psaní kódu:
V horní části obrazovky musíme zadat název naší monitorovací jednotky, vybrat její typ a určit její výchozí interval obnovy. Můžeme také vybrat existující jednotku jako šablonu.
V části záhlaví jsou dvě textová pole. Editor „Data Script“ je místo, kde píšeme kód pro získávání dat pro naši monitorovací jednotku. Při každé aktualizaci jednotky se spustí kód datového skriptu. Editor „Chart Script“ je místo, kde píšeme kód pro kreslení skutečné jednotky. Toto se spustí při prvním vytažení jednotky.
Veškerý kód datového skriptu je napsán v Pythonu. Pro monitorovací jednotku typu grafu potřebuje OmniDB skript grafu napsaný v Chart.js.
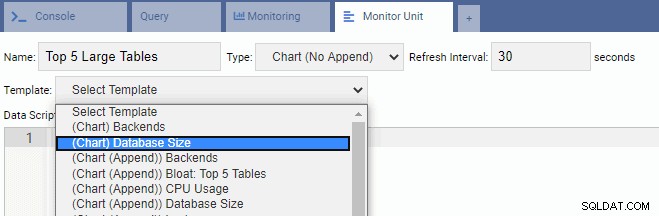
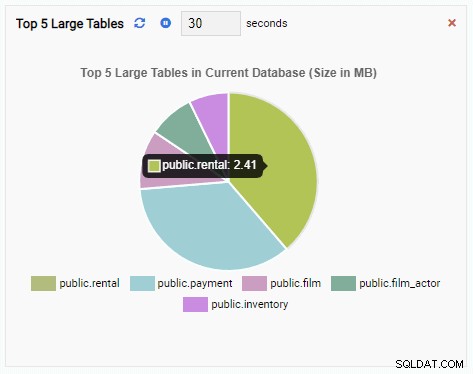
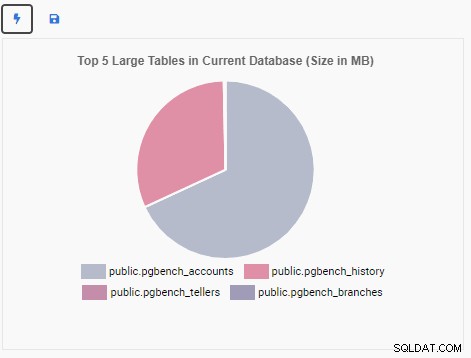
Nyní vytvoříme Monitorovací jednotku, která zobrazí 5 největších tabulek v aktuální databázi. Na základě databáze vybrané v OmniDB změní monitorovací jednotka své zobrazení tak, aby odráželo názvy pěti největších tabulek v této databázi.
Pro psaní nové jednotky je nejlepší začít s existující šablonou a upravit její kód. To ušetří čas i námahu. Na následujícím obrázku jsme naši monitorovací jednotku pojmenovali „Top 5 Large Tables“. Vybrali jsme jej jako typ grafu (No Append) a poskytli jsme obnovovací frekvenci 30 sekund. Naši monitorovací jednotku jsme také založili na šabloně Velikost databáze:
Do textového pole Data Script se automaticky vyplní kód pro jednotku sledování velikosti databáze:
from datetime import datetimefrom random import randintdatabases =connection.Query(''' SELECT d.datname AS dataname, round(pg_catalog.pg_database_size(d.datname)/1048576.0,2) AS size d. kat. FROM database WHE d_ pg g . dataname not in ('template0','template1')''')data =[]color =[]label =[]pro db v databázích. Řádky: data.append(db["size"]) color.append( "rgb(" + str(randint(125, 225)) + "," + str(randint(125, 225)) + "," + str(randint(125, 225)) + ")") label.append (db["datname"])total_size =connection.ExecuteScalar(''' SELECT round(sum(pg_catalog.pg_database_size(datname)/1048576.0),2) FROM pg_catalog.pg_database ) WHERE WHERE NO' dat ":label, "datasets":[ { "data":data, "backgroundColor":barva, "label":"Datová sada 1" ____) Velikost dat “ ] velikost } " MB)"}A textové pole Skript grafu je také vyplněno kódem:
total_size =connection.ExecuteScalar(''' SELECT round(sum(pg_catalog.pg_database_size(datname)/1048576.0),2) FROM pg_catalog.pg_database WHERE NOT')" datistemplate"'' type') , "data":None, "options":{ "responsive":True, "title":{ "display":True, "text":"Velikost databáze":"Velikost databáze" (celkem +) + MB" (celkem:+ } }}Můžeme upravit Data Script, abychom získali 5 nejlepších velkých tabulek v databázi. Ve skriptu níže jsme ponechali většinu původního kódu, kromě příkazu SQL:
from datetime import datetimefrom random import randinttables =connection.Query('''SELECT nspname || '.' || relname AS "tablename", round(pg_catalog.pg_total_relation_size(c.oid)/1048576.0,2) AS " table_size" OD pg_class C LEVÉ PŘIPOJENÍ pg_namespace N ZAPNUTO (N.oid =C.relnamespace) KDE NENÍ nspname ('pg_catalog', 'information_schema') A C.relkind <> 'i_ast' A nspname !'~ A nspname ! BY 2 DESC LIMIT 5;''')data =[]barva =[]štítek =[]pro tabulku v tabulkách. Řádky: data.append(table["table_size"]) color.append("rgb(" + str (randint(125, 225)) + "," + str(randint(125, 225)) + "," + str(randint(125, 225)) + ")") label.append(table["tablename" ])výsledek ={ "štítky":štítek, "datové sady":[ "data":data, "Barva pozadí":barva, ] "štítek" :"Na p "Zde získáváme kombinovanou velikost každé tabulky a jejích indexů v aktuální databázi. Výsledky řadíme v sestupném pořadí a vybíráme prvních pět řádků.
Dále vyplníme tři pole Pythonu iterací přes sadu výsledků.
Nakonec vytváříme řetězec JSON založený na hodnotách polí.
V textovém poli Skript grafu jsme upravili kód tak, aby byl odstraněn původní příkaz SQL. Zde specifikujeme pouze kosmetický aspekt grafu. Definujeme graf jako koláčový typ a poskytujeme mu název:
result ={ "type":"koláč", "data":Žádné, "možnosti":{ "responsive":True, "title":{ "display":True, " 5 Tabulky v aktuální databázi (velikost v MB)" } }}Nyní můžeme jednotku otestovat kliknutím na ikonu blesku. Tím se v oblasti náhledu zobrazí nová monitorovací jednotka:
Dále jednotku uložíme kliknutím na ikonu disku. Okno se zprávou potvrzuje, že jednotka byla uložena:
Nyní se vrátíme k našemu monitorovacímu panelu a přidáme novou monitorovací jednotku:
Všimněte si, že ve sloupci „Akce“ máme další dvě ikony pro naši vlastní monitorovací jednotku. Jeden slouží k jeho úpravě, druhý k jeho odstranění z OmniDB.
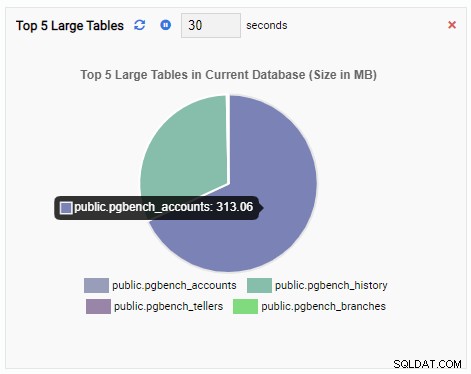
Monitorovací jednotka „Top 5 Large Tables“ nyní zobrazuje pět největších tabulek v aktuální databázi:
Pokud zavřeme řídicí panel, přepneme se na jinou databázi z navigačního panelu a znovu otevřeme řídicí panel, uvidíme, že se monitorovací jednotka změnila, aby odrážela tabulky této databáze:
Poslední slova
Tím končí naše dvoudílná série o OmniDB. Jak jsme viděli, OmniDB má několik šikovných monitorovacích jednotek, které PostgreSQL DBA považují za užitečné pro sledování výkonu. Viděli jsme, jak můžeme tyto jednotky použít k identifikaci potenciálních úzkých míst na serveru. Také jsme viděli, jak vytvořit vlastní jednotky na míru. Čtenářům se doporučuje, aby vytvořili a otestovali jednotky pro monitorování výkonu pro jejich konkrétní pracovní zátěž. 2ndQuadrant vítá jakýkoli příspěvek do repozitáře OmniDB Monitoring Unit GitHub.