Přidání filtrovaného indexu může mít překvapivé vedlejší účinky na existující dotazy, i když se zdá, že nový filtrovaný index spolu zcela nesouvisí. Tento příspěvek se zabývá příkladem ovlivňujícím příkazy DELETE, který má za následek slabý výkon a zvýšené riziko uváznutí.
Testovací prostředí
V tomto příspěvku bude použita následující tabulka:
CREATE TABLE dbo.Data
(
RowID integer IDENTITY NOT NULL,
SomeValue integer NOT NULL,
StartDate date NOT NULL,
CurrentFlag bit NOT NULL,
Padding char(50) NOT NULL DEFAULT REPLICATE('ABCDE', 10),
CONSTRAINT PK_Data_RowID
PRIMARY KEY CLUSTERED (RowID)
); Tento další příkaz vytvoří 499 999 řádků ukázkových dat:
INSERT dbo.Data WITH (TABLOCKX)
(SomeValue, StartDate, CurrentFlag)
SELECT
CONVERT(integer, RAND(n) * 1e6) % 1000,
DATEADD(DAY, (N.n - 1) % 31, '20140101'),
CONVERT(bit, 0)
FROM dbo.Numbers AS N
WHERE
N.n >= 1
AND N.n < 500000; To používá tabulku Numbers jako zdroj po sobě jdoucích celých čísel od 1 do 499 999. V případě, že ve svém testovacím prostředí žádný z nich nemáte, lze k efektivnímu vytvoření kódu obsahujícího celá čísla od 1 do 1 000 000 použít následující kód:
WITH
N1 AS (SELECT N1.n FROM (VALUES (1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS N1 (n)),
N2 AS (SELECT L.n FROM N1 AS L CROSS JOIN N1 AS R),
N3 AS (SELECT L.n FROM N2 AS L CROSS JOIN N2 AS R),
N4 AS (SELECT L.n FROM N3 AS L CROSS JOIN N2 AS R),
N AS (SELECT ROW_NUMBER() OVER (ORDER BY n) AS n FROM N4)
SELECT
-- Destination column type integer NOT NULL
ISNULL(CONVERT(integer, N.n), 0) AS n
INTO dbo.Numbers
FROM N
OPTION (MAXDOP 1);
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_Numbers_n
PRIMARY KEY (n)
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1); Základem pozdějších testů bude odstranění řádků z testovací tabulky pro konkrétní StartDate. Chcete-li proces identifikace řádků k odstranění zefektivnit, přidejte tento index bez klastrů:
CREATE NONCLUSTERED INDEX
IX_Data_StartDate
ON dbo.Data
(StartDate); Ukázková data
Po dokončení těchto kroků bude ukázka vypadat takto:
SELECT TOP (100)
D.RowID,
D.SomeValue,
D.StartDate,
D.CurrentFlag,
D.Padding
FROM dbo.Data AS D
ORDER BY
D.RowID;
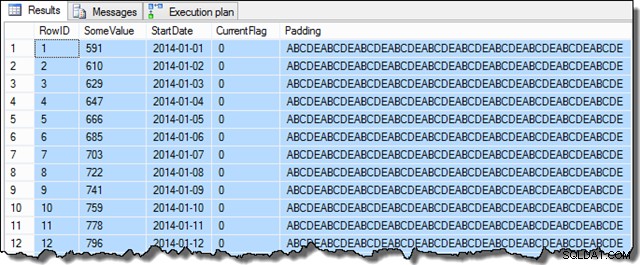
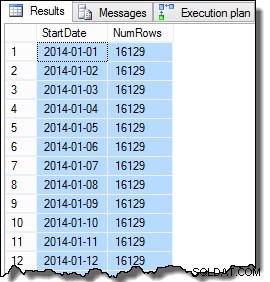
Data sloupce SomeValue se mohou mírně lišit kvůli pseudonáhodnému generování, ale tento rozdíl není důležitý. Celkově ukázková data obsahují 16 129 řádků pro každé z 31 dat StartDate v lednu 2014:
SELECT
D.StartDate,
NumRows = COUNT_BIG(*)
FROM dbo.Data AS D
GROUP BY
D.StartDate
ORDER BY
D.StartDate;
Posledním krokem, který musíme provést, aby byla data trochu realistická, je nastavení sloupce CurrentFlag na hodnotu true pro nejvyšší RowID pro každé StartDate. Následující skript provádí tento úkol:
WITH LastRowPerDay AS
(
SELECT D.CurrentFlag
FROM dbo.Data AS D
WHERE D.RowID =
(
SELECT MAX(D2.RowID)
FROM dbo.Data AS D2
WHERE D2.StartDate = D.StartDate
)
)
UPDATE LastRowPerDay
SET CurrentFlag = 1; Plán provádění této aktualizace obsahuje kombinaci segmentu a horní části pro efektivní nalezení nejvyššího RowID za den:

Všimněte si, jak se plán provádění jen málo podobá písemné formě dotazu. Toto je skvělý příklad toho, jak optimalizátor funguje na základě logické specifikace SQL, spíše než přímo implementovat SQL. V případě, že vás to zajímá, Eager Table Spool v tomto plánu je vyžadována pro Halloween Protection.
Smazání jednoho dne dat
Dobře, takže po dokončení přípravných prací je úkolem odstranit řádky pro konkrétní počáteční datum. Toto je druh dotazu, který můžete běžně spouštět k nejbližšímu datu v tabulce, kde data dosáhla konce své životnosti.
Vezmeme-li jako náš příklad 1. leden 2014, testovací dotaz na odstranění je jednoduchý:
DELETE dbo.Data WHERE StartDate = '20140101';
Prováděcí plán je také docela jednoduchý, i když stojí za to se na něj podívat trochu podrobněji:

Analýza plánu
Index Seek zcela vpravo používá neclusterovaný index k nalezení řádků pro zadanou hodnotu StartDate. Vrací pouze nalezené hodnoty RowID, jak potvrzuje nápověda operátora:
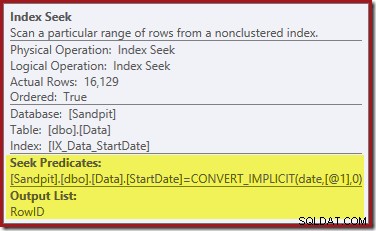
Pokud vás zajímá, jak index StartDate dokáže vrátit RowID, pamatujte, že RowID je jedinečný seskupený index pro tabulku, takže je automaticky zahrnut do neklastrovaného indexu StartDate.
Dalším operátorem v plánu je Clustered Index Delete. To používá hodnotu RowID zjištěnou hledáním indexu k vyhledání řádků k odstranění.
Posledním operátorem v plánu je odstranění indexu. Tím se odstraní řádky z neklastrovaného indexu IX_Data_StartDate které souvisí s RowID odstraněným pomocí Clustered Index Delete. K vyhledání těchto řádků v neklastrovaném indexu potřebuje procesor dotazů StartDate (klíč pro neklastrovaný index).
Pamatujte, že původní hledání indexu nevrátilo počáteční datum, pouze RowID. Jak tedy procesor dotazů získá StartDate pro odstranění indexu? V tomto konkrétním případě si mohl optimalizátor všimnout, že hodnota StartDate je konstanta a optimalizovat ji, ale nestalo se tak. Odpověď zní, že operátor Clustered Index Delete čte hodnotu StartDate pro aktuální řádek a přidá ji do streamu. Porovnejte výstupní seznam odstranění seskupeného indexu zobrazený níže se seznamem hledání indexu hned výše:
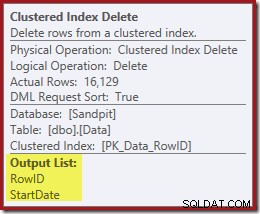
Může se zdát překvapivé, že operátor Delete čte data, ale takto to funguje. Procesor dotazů ví, že bude muset najít řádek v seskupeném indexu, aby jej mohl odstranit, takže může do té doby odložit čtení sloupců potřebných k udržování indexů bez klastrů, pokud je to možné.
Přidání filtrovaného indexu
Nyní si představte, že někdo má zásadní dotaz na tuto tabulku, která funguje špatně. Užitečný DBA provede analýzu a přidá následující filtrovaný index:
CREATE NONCLUSTERED INDEX
FIX_Data_SomeValue_CurrentFlag
ON dbo.Data (SomeValue)
INCLUDE (CurrentFlag)
WHERE CurrentFlag = 1; Nový filtrovaný index má na problematický dotaz požadovaný efekt a všichni jsou spokojeni. Všimněte si, že nový index vůbec neodkazuje na sloupec StartDate, takže neočekáváme, že to vůbec ovlivní náš dotaz na denní smazání.
Odstranění dne s filtrovaným indexem
Toto očekávání můžeme otestovat smazáním dat podruhé:
DELETE dbo.Data WHERE StartDate = '20140102';
Najednou se plán provádění změnil na paralelní Clustered Index Scan:

Všimněte si, že pro nový filtrovaný index neexistuje žádný samostatný operátor pro odstranění indexu. Optimalizátor se rozhodl udržovat tento index uvnitř operátoru Clustered Index Delete. Toto je zvýrazněno v SQL Sentry Plan Explorer, jak je znázorněno výše („+1 neklastrované indexy“) s úplnými podrobnostmi v popisku:
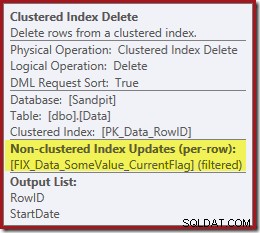
Pokud je tabulka velká (předpokládejme datový sklad), může být tato změna na paralelní skenování velmi významná. Co se stalo s pěkným Index Seek na StartDate a proč zcela nesouvisející filtrovaný index věci tak dramaticky změnil?
Nalezení problému
První vodítko pochází z pohledu na vlastnosti Clustered Index Scan:
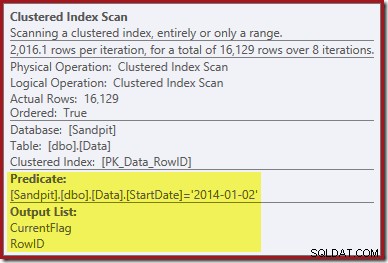
Kromě hledání hodnot RowID pro operátor Clustered Index Delete k odstranění nyní tento operátor čte hodnoty CurrentFlag. Potřeba tohoto sloupce není jasná, ale alespoň začíná vysvětlovat rozhodnutí skenovat:sloupec CurrentFlag není součástí našeho neshlukovaného indexu StartDate.
Můžeme to potvrdit přepsáním odstraňovacího dotazu, abychom vynutili použití neklastrovaného indexu StartDate:
DELETE D
FROM dbo.Data AS D
WITH (INDEX(IX_Data_StartDate))
WHERE StartDate = '20140103'; Prováděcí plán se blíží své původní podobě, ale nyní obsahuje vyhledávání klíčů:
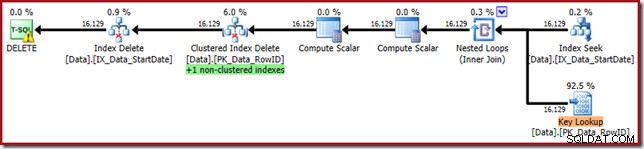
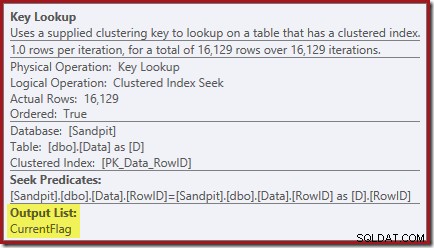
Vlastnosti vyhledávání klíčů potvrzují, že tento operátor načítá hodnoty CurrentFlag:
Možná jste si také všimli výstražných trojúhelníků v posledních dvou plánech. Toto jsou chybějící varování indexu:
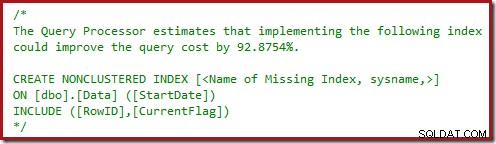
Toto je další potvrzení, že SQL Server by rád viděl sloupec CurrentFlag zahrnutý v neklastrovaném indexu. Důvod změny na paralelní Clustered Index Scan je nyní jasný:procesor dotazů rozhodne, že skenování tabulky bude levnější než provádění vyhledávání klíčů.
Ano, ale proč?
To vše je velmi zvláštní. V původním plánu provádění byl SQL Server schopen číst další sloupcová data potřebná k udržování neklastrovaných indexů na operátoru Clustered Index Delete. Hodnota sloupce CurrentFlag je potřebná k udržení filtrovaného indexu, tak proč ji SQL Server nezpracovává stejným způsobem?
Krátká odpověď je, že může, ale pouze pokud je filtrovaný index udržován v samostatném operátoru Index Delete. Můžeme to vynutit pro aktuální dotaz pomocí nedokumentovaného příznaku trasování 8790. Bez tohoto příznaku optimalizátor zvolí, zda bude každý index udržovat v samostatném operátoru nebo jako součást operace základní tabulky.
-- Forced wide update plan DELETE dbo.Data WHERE StartDate = '20140105' OPTION (QUERYTRACEON 8790);
Plán provádění je zpět k hledání StartDate neklastrovaného indexu:
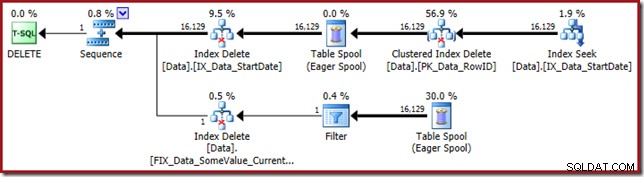
Index Seek vrací pouze hodnoty RowID (žádný CurrentFlag):
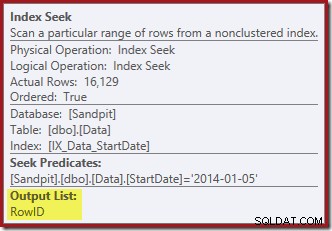
A Clustered Index Delete čte sloupce potřebné k udržování neklastrovaných indexů, včetně CurrentFlag:
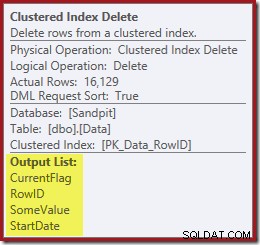
Tato data se dychtivě zapisují do tabulkového spoolu, který se přehrává pro každý index, který je třeba udržovat. Všimněte si také explicitního operátoru Filter před operátorem Index Delete pro filtrovaný index.
Další vzor, na který je třeba dávat pozor
Tento problém nevede vždy k prohledávání tabulky namísto hledání indexu. Chcete-li to vidět, přidejte do testovací tabulky další index:
CREATE NONCLUSTERED INDEX
IX_Data_SomeValue_CurrentFlag
ON dbo.Data (SomeValue, CurrentFlag); Tento index není filtrováno a nezahrnuje sloupec StartDate. Nyní zkuste znovu dotaz na smazání dne:
DELETE dbo.Data WHERE StartDate = '20140104';
Optimalizátor nyní přichází s tímto monstrem:
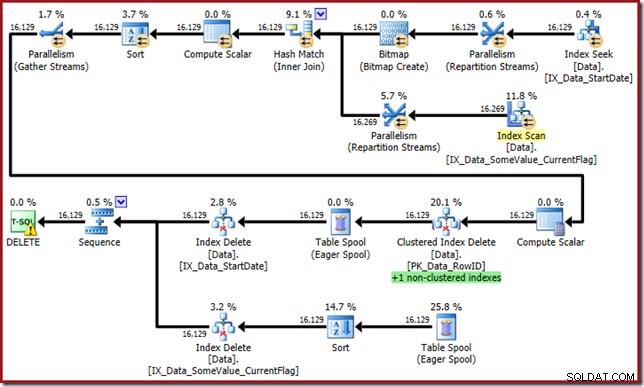
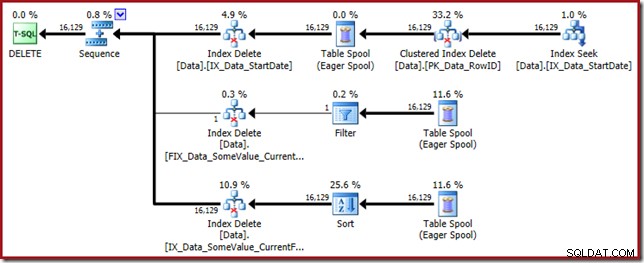
Tento plán dotazů má vysoký faktor překvapení, ale hlavní příčina je stejná. Sloupec CurrentFlag je stále potřeba, ale nyní optimalizátor zvolí strategii průsečíku indexu, aby jej získal namísto prohledávání tabulky. Použití příznaku trasování vynutí plán údržby podle indexu a zdravý rozum se znovu obnoví (jediným rozdílem je další přehrání cívky pro udržení nového indexu):
Způsobují to pouze filtrované indexy
K tomuto problému dochází pouze v případě, že se optimalizátor rozhodne udržovat filtrovaný index v operátoru Odstranění seskupeného indexu. Nefiltrované indexy nejsou ovlivněny, jak ukazuje následující příklad. Prvním krokem je vypuštění filtrovaného indexu:
DROP INDEX FIX_Data_SomeValue_CurrentFlag ON dbo.Data;
Nyní musíme napsat dotaz způsobem, který přesvědčí optimalizátor, aby udržoval všechny indexy v Clustered Index Delete. Moje volba je použít proměnnou a nápovědu ke snížení očekávání optimalizátoru ohledně počtu řádků:
-- All qualifying rows will be deleted
DECLARE @Rows bigint = 9223372036854775807;
-- Optimize the plan for deleting 100 rows
DELETE TOP (@Rows)
FROM dbo.Data
OUTPUT
Deleted.RowID,
Deleted.SomeValue,
Deleted.StartDate,
Deleted.CurrentFlag
WHERE StartDate = '20140106'
OPTION (OPTIMIZE FOR (@Rows = 100)); Prováděcí plán je:
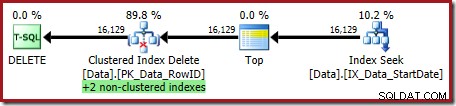
Oba neklastrované indexy jsou udržovány pomocí Clustered Index Delete:
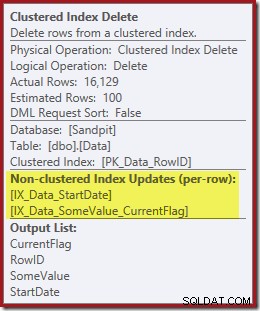
Hledání indexu vrátí pouze RowID:
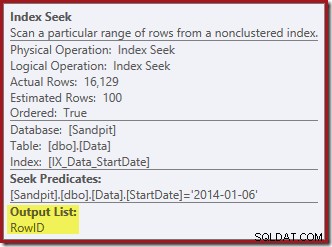
Sloupce potřebné pro údržbu indexu jsou načteny interně operátorem odstranění; tyto podrobnosti nejsou vystaveny ve výstupu plánu zobrazení (takže výstupní seznam operátoru delete by byl prázdný). Přidal jsem OUTPUT klauzule k dotazu, která znovu zobrazí odstranění seskupeného indexu a vrátí data, která neobdržela na svém vstupu:
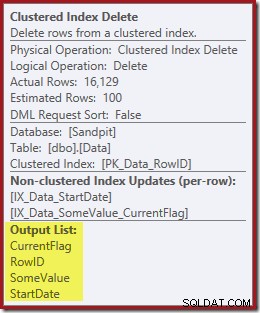
Poslední myšlenky
Toto je složité omezení, které lze obejít. Na jedné straně obecně nechceme v produkčních systémech používat nezdokumentované příznaky trasování.
Přirozenou „opravou“ je přidat sloupce potřebné pro údržbu filtrovaného indexu do všech neklastrované indexy, které lze použít k vyhledání řádků k odstranění. Z mnoha úhlů pohledu to není příliš přitažlivý návrh. Další alternativou je prostě nepoužívat filtrované indexy, ale ani to není ideální.
Domnívám se, že optimalizátor dotazů by měl u filtrovaných indexů automaticky uvažovat o alternativě údržby podle indexu, ale jeho zdůvodnění se v této oblasti nyní zdá být neúplné (a je založeno spíše na jednoduché heuristice než na správném stanovení nákladů na index/na řádek). alternativy).
Abychom toto tvrzení trochu vyčíslili, plán paralelního klastrovaného prohledávání indexů zvolený optimalizátorem byl 5.5 jednotky v mých testech. Stejný dotaz s příznakem trasování odhaduje náklady na 1,4 Jednotky. Po zavedení třetího indexu měl plán průsečíků paralelních indexů zvolený optimalizátorem odhadované náklady 4,9 , zatímco plán příznaků trasování přišel na 2.7 jednotek (všechny testy na SQL Server 2014 RTM CU1 sestavení 12.0.2342 podle modelu odhadu mohutnosti 120 a se zapnutým příznakem trasování 4199).
Považuji to za chování, které by se mělo zlepšit. Můžete hlasovat pro souhlas nebo nesouhlas se mnou v této položce Connect.