Sidenote/DISCLAIIMMENT:
Toto je špatný nápad, protože od doby vytvoření tabulky to není 100% spolehlivé, protože tabulka mohla být interně zrušena a znovu vytvořena kvůli operacím na tabulce, jako je CLUSTER.
Kromě toho můžete získat čas vytvoření takto (za předpokladu, že example-table-name z t_benutzer ):
--select datname, datdba from pg_database;
--select relname, relfilenode from pg_class where relname ilike 't_benutzer';
-- (select relfilenode::text from pg_class where relname ilike 't_benutzer')
SELECT
pg_ls_dir
,
(
SELECT creation
FROM pg_stat_file('./base/'
||
(
SELECT
MAX(pg_ls_dir::bigint)::text
FROM pg_ls_dir('./base')
WHERE pg_ls_dir <> 'pgsql_tmp'
AND pg_ls_dir::bigint <= (SELECT relfilenode FROM pg_class WHERE relname ILIKE 't_benutzer')
)
|| '/' || pg_ls_dir
)
) as createtime
FROM pg_ls_dir(
'./base/' ||
(
SELECT
MAX(pg_ls_dir::bigint)::text
FROM pg_ls_dir('./base')
WHERE pg_ls_dir <> 'pgsql_tmp'
AND pg_ls_dir::bigint <= (SELECT relfilenode FROM pg_class WHERE relname ILIKE 't_benutzer')
)
)
WHERE pg_ls_dir = (SELECT relfilenode::text FROM pg_class WHERE relname ILIKE 't_benutzer')
Tajemství spočívá v použití pg_stat_file v příslušném souboru tabulky.
-- https://www.greenplumdba.com/greenplum-dba-faq/howtofindtablecreationdateingreenplum
select
pg_ls_dir
,
(
select
--size
--access
--modification
--change
creation
--isdir
from pg_stat_file(pg_ls_dir)
) as createtime
from pg_ls_dir('.');
Podle komentáře v tomto příspěvku PostgreSQL:Čas vytvoření tabulky to není 100% spolehlivé, protože tabulka mohla být interně zrušena a znovu vytvořena kvůli operacím na tabulce, jako je CLUSTER.
Také vzor
/main/base/<database id>/<table filenode id>
Zdá se, že je to špatně, protože na mém počítači mají všechny tabulky z různých databází stejné ID databáze a zdá se, že složka byla nahrazena nějakým libovolným číslem inodu, takže musíte najít složku, jejíž číslo je nejblíže vaší tabulce id inode (maximální název složky, kde id složky <=ID_tabulky_inode a název složky je číselný)
Zjednodušená verze vypadá takto:
SELECT creation
FROM pg_stat_file(
'./base/'
||
(
SELECT
MAX(pg_ls_dir::bigint)::text
FROM pg_ls_dir('./base')
WHERE pg_ls_dir <> 'pgsql_tmp'
AND pg_ls_dir::bigint <= (SELECT relfilenode FROM pg_class WHERE relname ILIKE 't_benutzer')
)
|| '/' || (SELECT relfilenode::text FROM pg_class WHERE relname ILIKE 't_benutzer')
)
Potom můžete použít information_schema a cte, aby byl dotaz jednodušší, nebo si vytvořit vlastní pohled:
;WITH CTE AS
(
SELECT
table_name
,
(
SELECT
MAX(pg_ls_dir::bigint)::text
FROM pg_ls_dir('./base')
WHERE pg_ls_dir <> 'pgsql_tmp'
AND pg_ls_dir::bigint <= (SELECT relfilenode FROM pg_class WHERE relname ILIKE table_name)
) as folder
,(SELECT relfilenode FROM pg_class WHERE relname ILIKE table_name) filenode
FROM information_schema.tables
WHERE table_type = 'BASE TABLE'
AND table_schema = 'public'
)
SELECT
table_name
,(
SELECT creation
FROM pg_stat_file(
'./base/' || folder || '/' || filenode
)
) as creation_time
FROM CTE
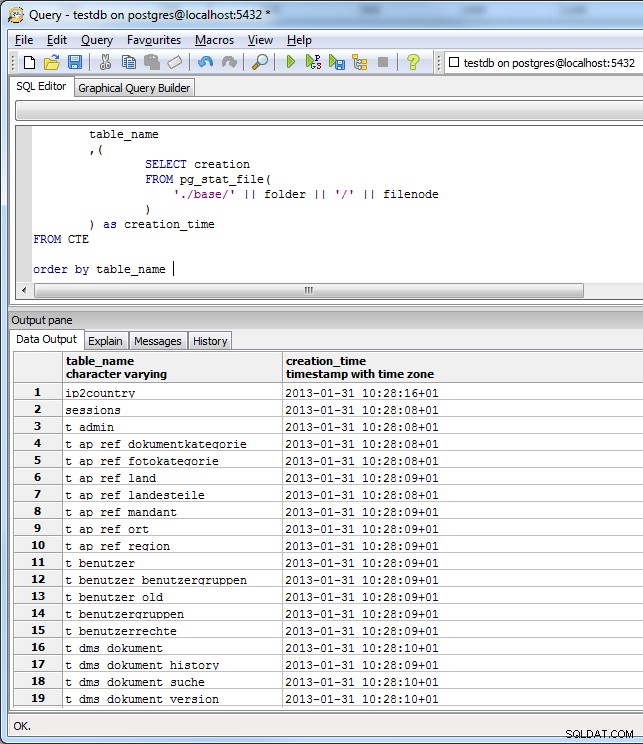
(všechny tabulky vytvořené pomocí schématu nhibernate jsou vytvořeny, takže víceméně stejný čas na všech tabulkách na snímku obrazovky je správný).
Pro rizika a vedlejší účinky použijte svůj mozek a/nebo se zeptejte svého lékaře či lékárníka;)