Provozování databází v cloudové infrastruktuře je v dnešní době stále populárnější. Přestože cloudový VM nemusí být tak spolehlivý jako podnikový server, hlavní poskytovatelé cloudu nabízejí různé nástroje pro zvýšení dostupnosti služeb. V tomto příspěvku na blogu vám ukážeme, jak vytvořit architekturu databáze MySQL nebo MariaDB pro vysokou dostupnost v cloudu. Budeme se konkrétně zabývat webovými službami Amazon a Google Cloud Platform, ale většinu tipů lze použít i u jiných poskytovatelů cloudu.
AWS i Google nabízejí databázové služby na svých cloudech a tyto služby lze nakonfigurovat pro vysokou dostupnost. Je možné mít kopie v různých zónách dostupnosti (nebo zónách v GCP), abyste zvýšili své šance na přežití částečného selhání služeb v rámci regionu. Přestože je hostovaná služba velmi pohodlným způsobem provozování databáze, uvědomte si, že služba je navržena tak, aby se chovala specifickým způsobem, který může nebo nemusí vyhovovat vašim požadavkům. Takže například AWS RDS pro MySQL má docela omezený seznam možností, pokud jde o zpracování převzetí služeb při selhání. Nasazení Multi-AZ přicházejí s dobou převzetí služeb při selhání 60–120 sekund podle dokumentace. Ve skutečnosti, vzhledem k tomu, že „stínová“ instance MySQL musí začínat od „poškozené“ datové sady, může to trvat ještě déle, protože může být zapotřebí více práce s aplikací nebo vrácením transakcí z opakovaných protokolů InnoDB. Existuje možnost povýšit otroka, aby se stal pánem, ale není to možné, protože nemůžete znovu zotročit stávající otroky od nového pána. V případě spravované služby je také ze své podstaty složitější a obtížnější vysledovat problémy s výkonem. Další informace o RDS pro MySQL a jejích omezeních naleznete v tomto příspěvku na blogu.
Na druhou stranu, pokud se rozhodnete spravovat databáze, jste v jiném světě možností. Řada věcí, které můžete dělat na holém kovu, je také možná na instancích EC2 nebo Compute Engine. Nemáte režii na správu základního hardwaru, a přesto si ponecháváte kontrolu nad tím, jak navrhnout systém. Při navrhování dostupnosti MySQL existují dvě hlavní možnosti – replikace MySQL a Galera Cluster. Pojďme o nich diskutovat.
Replikace MySQL
Replikace MySQL je běžný způsob škálování MySQL pomocí více kopií dat. Asynchronní nebo semisynchronní umožňuje šířit změny provedené na jediném zapisovači, masteru, na repliky/podřízené jednotky – z nichž každá by obsahovala úplnou datovou sadu a může být povýšena na novou master. Replikaci lze také použít pro škálování čtení, a to tak, že provoz čtení nasměrujete na repliky a tímto způsobem snížíte zátěž hlavního serveru. Hlavní výhodou replikace je snadné použití – je tak široce známá a oblíbená (je také snadná na konfiguraci), že existuje mnoho zdrojů a nástrojů, které vám pomohou ji spravovat a konfigurovat. Náš vlastní ClusterControl je jedním z nich – můžete jej použít ke snadnému nasazení replikačního nastavení MySQL s integrovanými nástroji pro vyrovnávání zatížení, ke správě změn topologie, převzetí služeb při selhání/obnovení atd.
Jedním z hlavních problémů replikace MySQL je, že není navržena tak, aby zvládla rozdělení sítě nebo selhání hlavního serveru. Pokud mistr selže, musíte povýšit jednu z replik. Jedná se o ruční proces, i když jej lze automatizovat pomocí externích nástrojů (např. ClusterControl). Neexistuje také žádný mechanismus kvora a neexistuje žádná podpora pro oplocení neúspěšných hlavních instancí v replikaci MySQL. Bohužel to může vést k vážným problémům v distribuovaných prostředích – pokud jste povýšili nový master, zatímco váš starý je znovu online, můžete skončit zápisem do dvou uzlů, což způsobí posun dat a způsobí vážné problémy s konzistencí dat.
Později v tomto příspěvku se podíváme na několik příkladů, které vám ukáží, jak detekovat rozdělení sítě a implementovat STONITH nebo jiný mechanismus oplocení pro vaše nastavení replikace MySQL.
Cluster Galera
V předchozí části jsme viděli, že replikace MySQL postrádá oplocení a podporu kvora – zde Galera Cluster září. Má vestavěnou podporu kvora a má také mechanismus oplocení, který brání rozděleným uzlům přijímat zápisy. Díky tomu je Galera Cluster vhodnější než replikace v nastaveních s více datovými centry. Galera Cluster také podporuje více zapisovačů a je schopen řešit konflikty při zápisu. V nastavení s více datovými centry tedy nejste omezeni na jeden zapisovač, je možné mít zapisovač v každém datovém centru, což snižuje latenci mezi vaší aplikací a vrstvou databáze. Nezrychluje to zápisy, protože každý zápis musí být stále posílán do každého uzlu Galera k certifikaci, ale stále je to jednodušší, než posílat zápisy ze všech aplikačních serverů přes WAN na jeden vzdálený master.
Jakkoli je Galera dobrá, není vždy tou nejlepší volbou pro všechny pracovní zátěže. Galera nenahrazuje MySQL/InnoDB. Sdílí společné funkce s „normálním“ MySQL – používá InnoDB jako úložný modul, obsahuje celou datovou sadu na každém uzlu, což umožňuje JOINy. Přesto se některé výkonnostní charakteristiky Galery (jako je výkon zápisů, které jsou ovlivněny latencí sítě) liší od toho, co byste očekávali od nastavení replikace. Údržba také vypadá jinak:zpracování změn schématu funguje trochu jinak. Některé návrhy schémat nejsou optimální:pokud máte v tabulkách aktivní body, jako jsou často aktualizované čítače, může to vést k problémům s výkonem. Existuje také rozdíl v osvědčených postupech souvisejících s dávkovým zpracováním – namísto provádění dotazů ve velkých transakcích chcete, aby vaše transakce byly malé.
Úroveň proxy
Je velmi těžké a těžkopádné vytvořit vysoce dostupné nastavení bez proxy. Jistě, můžete ve své aplikaci napsat kód, abyste měli přehled o instancích databáze, zablokovali ty nezdravé, sledovali zapisovatelné master(y) a tak dále. Ale to je mnohem složitější než pouhé odesílání provozu do jednoho koncového bodu – což je místo, kde přichází na řadu proxy. ClusterControl vám umožňuje nasadit ProxySQL, HAProxy a MaxScale. Uvedeme několik příkladů pomocí ProxySQL, protože nám poskytuje dobrou flexibilitu při řízení databázového provozu.
ProxySQL lze nasadit několika způsoby. Pro začátek může být nasazen na samostatných hostitelích a Keepalived může být použit k poskytování virtuální IP adresy. V případě selhání jedné z instancí ProxySQL se virtuální IP adresa přesune. V cloudu může být toto nastavení problematické, protože přidání IP do rozhraní obvykle nestačí. Museli byste upravit konfiguraci Keepalived a skripty, aby fungovaly s elastickou IP (nebo statickou – jakkoli to může váš poskytovatel cloudu nazývat). Pak by bylo možné použít cloudové rozhraní API nebo CLI k přemístění této IP adresy na jiného hostitele. Z tohoto důvodu doporučujeme propojit ProxySQL s aplikací. Každý aplikační server by byl nakonfigurován pro připojení k místnímu ProxySQL pomocí Unixových soketů. Protože ProxySQL používá proces angel, pády ProxySQL lze detekovat/restartovat během sekundy. V případě havárie hardwaru dojde k výpadku konkrétního aplikačního serveru spolu s ProxySQL. Zbývající aplikační servery mohou stále přistupovat ke svým příslušným lokálním instancím ProxySQL. Toto konkrétní nastavení má další funkce. Zabezpečení – ProxySQL od verze 1.4.8 nemá podporu SSL na straně klienta. Může pouze nastavit SSL připojení mezi ProxySQL a backendem. Umístění ProxySQL na hostitele aplikace a použití soketů Unix je dobré řešení. ProxySQL má také schopnost ukládat dotazy do mezipaměti a pokud se chystáte použít tuto funkci, má smysl ji udržovat co nejblíže k aplikaci, abyste snížili latenci. Doporučujeme použít tento vzor k nasazení ProxySQL.
Typická nastavení
Podívejme se na příklady vysoce dostupných nastavení.
Jedno datové centrum, replikace MySQL
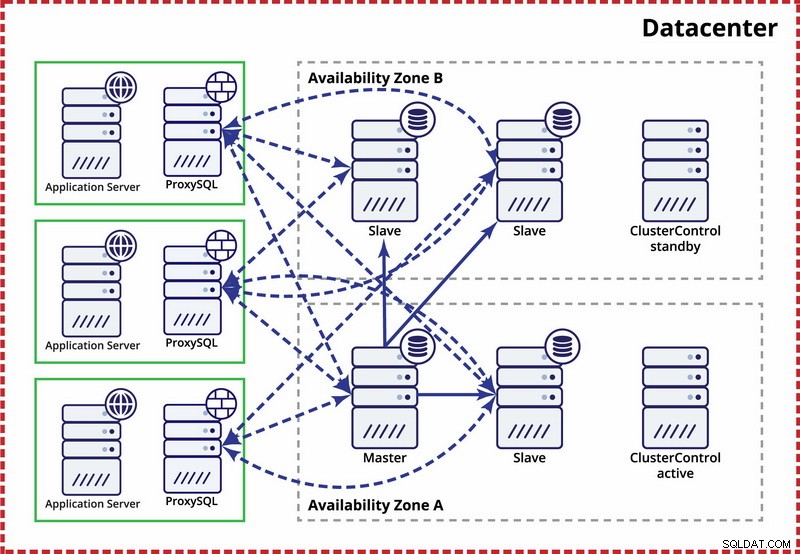
Zde se předpokládá, že v datovém centru existují dvě samostatné zóny. Každá zóna má redundantní a samostatné napájení, síť a konektivitu, aby se snížila pravděpodobnost selhání dvou zón současně. Je možné nastavit replikační topologii zahrnující obě zóny.
Zde používáme ClusterControl ke správě převzetí služeb při selhání. Abychom vyřešili scénář rozděleného mozku mezi zóny dostupnosti, spojíme aktivní ClusterControl s hlavním. Také jsme zakázali podřízené jednotky v druhé zóně dostupnosti, abychom zajistili, že automatické převzetí služeb při selhání nepovede k tomu, že budou k dispozici dva hlavní servery.
Více datových center, replikace MySQL
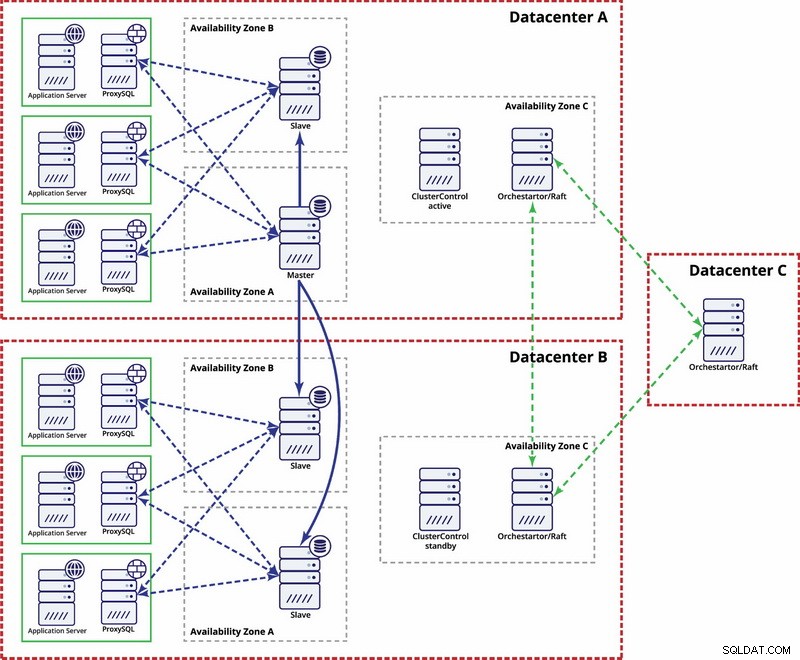
V tomto příkladu používáme tři datová centra a Orchestrator/Raft pro výpočet kvora. Možná budete muset napsat své vlastní skripty pro implementaci STONITH, pokud je master v rozděleném segmentu infrastruktury. ClusterControl se používá pro funkce obnovy a správy uzlů.
Více datových center, Galera Cluster
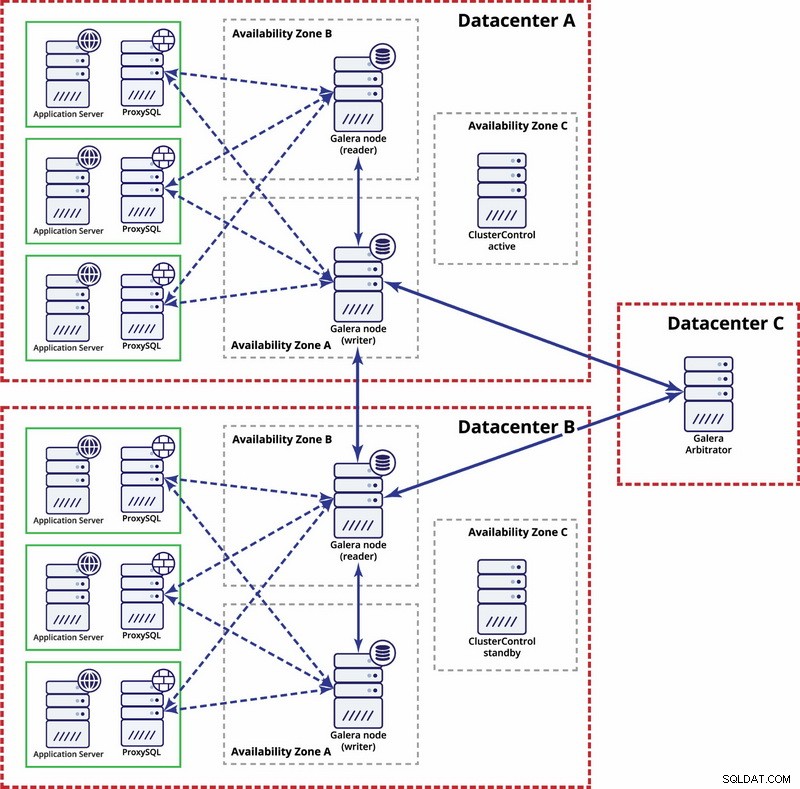
V tomto případě používáme tři datová centra s arbitrátorem Galera ve třetím - to umožňuje zvládnout selhání celého datového centra a snižuje riziko rozdělení sítě, protože třetí datové centrum lze použít jako relé.
Pro další čtení se podívejte na whitepaper „Jak navrhovat vysoce dostupná databázová prostředí s otevřeným zdrojovým kódem“ a podívejte se na záznam webináře „Navrhování databází s otevřeným zdrojovým kódem pro vysokou dostupnost“.