V sekci komentářů na jednom z našich blogů se čtenář zeptal na dopad wsrep_slave_threads na I/O výkon a škálovatelnost Galera Cluster. V té době jsme na tuto otázku nemohli snadno odpovědět a zálohovat ji dalšími daty, ale nakonec se nám podařilo nastavit prostředí a spustit nějaké testy.
Náš čtenář poukázal na benchmarky, které ukázaly, že zvýšení wsrep_slave_threads nemělo žádný dopad na výkon clusteru Galera.
Abychom vysvětlili, jaký je dopad tohoto nastavení, vytvořili jsme malý shluk tří uzlů (m5d.xlarge). To nám umožnilo využít přímo připojený nvme SSD pro datový adresář MySQL. Tím jsme minimalizovali možnost, že se úložiště stane překážkou v našem nastavení.
Nastavili jsme fond vyrovnávací paměti InnoDB na 8 GB a předělali jsme protokoly na dva soubory, každý o velikosti 1 GB. Zvýšili jsme také innodb_io_capacity na 2000 a innodb_io_capacity_max na 10000. Cílem bylo také zajistit, aby žádné z těchto nastavení neovlivnilo náš výkon.
Celý problém s takovými benchmarky je v tom, že existuje tolik úzkých míst, že je musíte jeden po druhém odstraňovat. Až po nějakém doladění konfigurace a po ujištění, že s hardwarem nebude problém, lze mít naději, že se objeví nějaké jemnější limity.
Vygenerovali jsme ~90 GB dat pomocí sysbench:
sysbench /usr/share/sysbench/oltp_write_only.lua --threads=16 --events=0 --time=600 --mysql-host=172.30.4.245 --mysql-user=sbtest --mysql-password=sbtest --mysql-port=3306 --tables=28 --report-interval=1 --skip-trx=off --table-size=10000000 --db-ps-mode=disable --mysql-db=sbtest_large preparePoté byl benchmark proveden. Testovali jsme dvě nastavení:wsrep_slave_threads=1 a wsrep_slave_threads=16. Hardware nebyl dostatečně výkonný, aby těžil z ještě dalšího zvýšení této proměnné. Mějte prosím také na paměti, že jsme neprováděli podrobné srovnávání, abychom určili, zda by měl být wsrep_slave_threads nastaven na 16, 8 nebo možná 4 pro nejlepší výkon. Zajímalo nás, zda můžeme ukázat dopad na klastr. A ano, dopad byl jasně viditelný. Pro začátek několik grafů řízení toku.
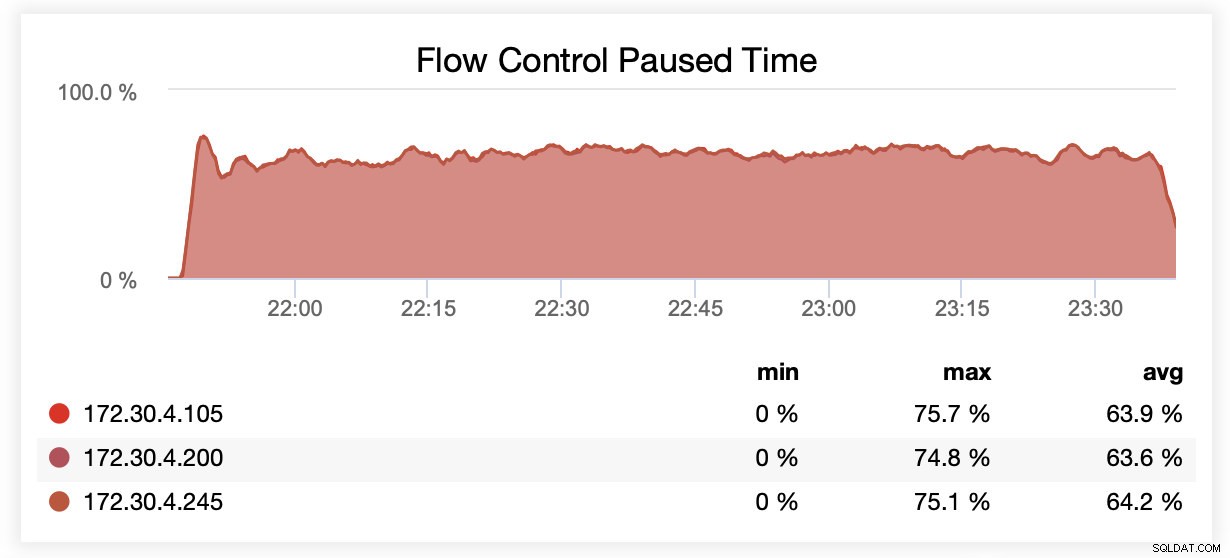
Při běhu s wsrep_slave_threads=1 byly uzly v průměru pozastaveny kvůli řízení toku ~64 % času.
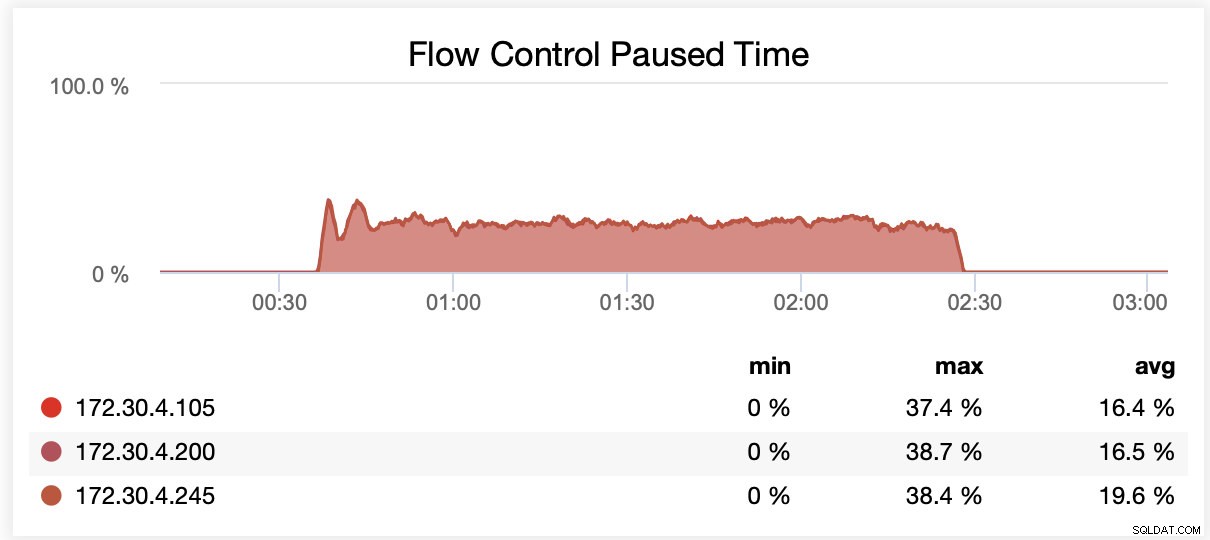
Při běhu s wsrep_slave_threads=16 byly uzly v průměru pozastaveny kvůli řízení toku ~20 % času.
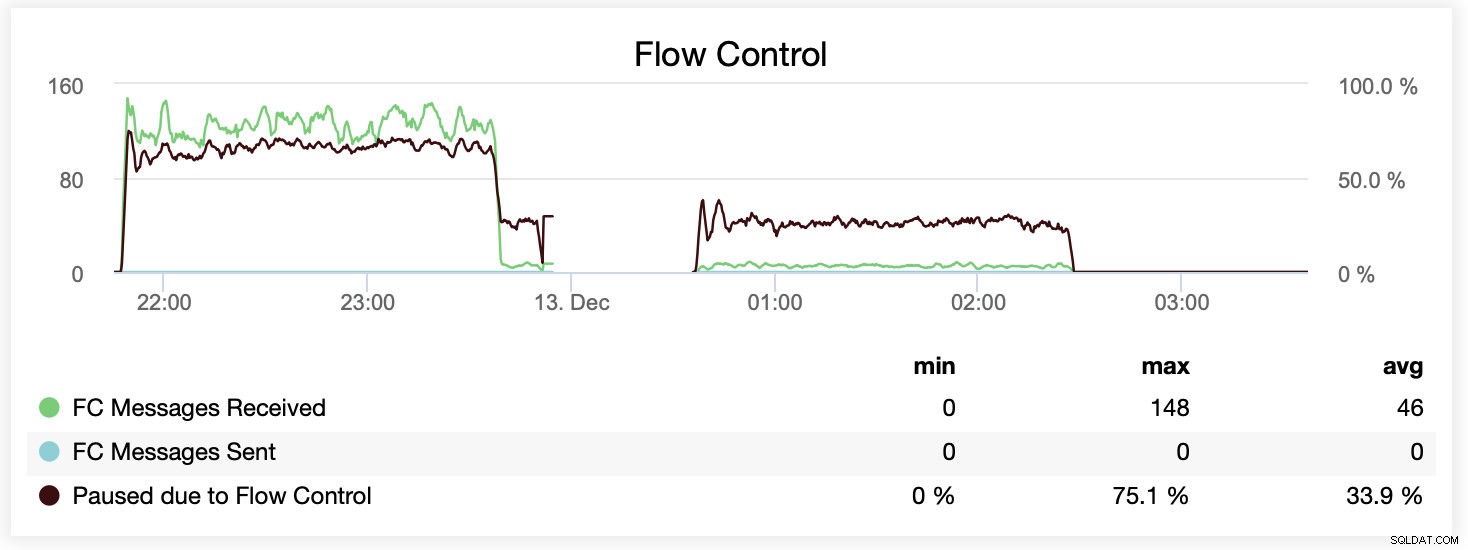
Rozdíl můžete také porovnat na jednom grafu. Pokles na konci první části je prvním pokusem o spuštění s wsrep_slave_threads=16. Serverům došel diskový prostor pro binární protokoly a my jsme museli tento benchmark spustit znovu později.
Jak se to projevilo z hlediska výkonu? Rozdíl je viditelný, i když rozhodně ne tak velkolepý.
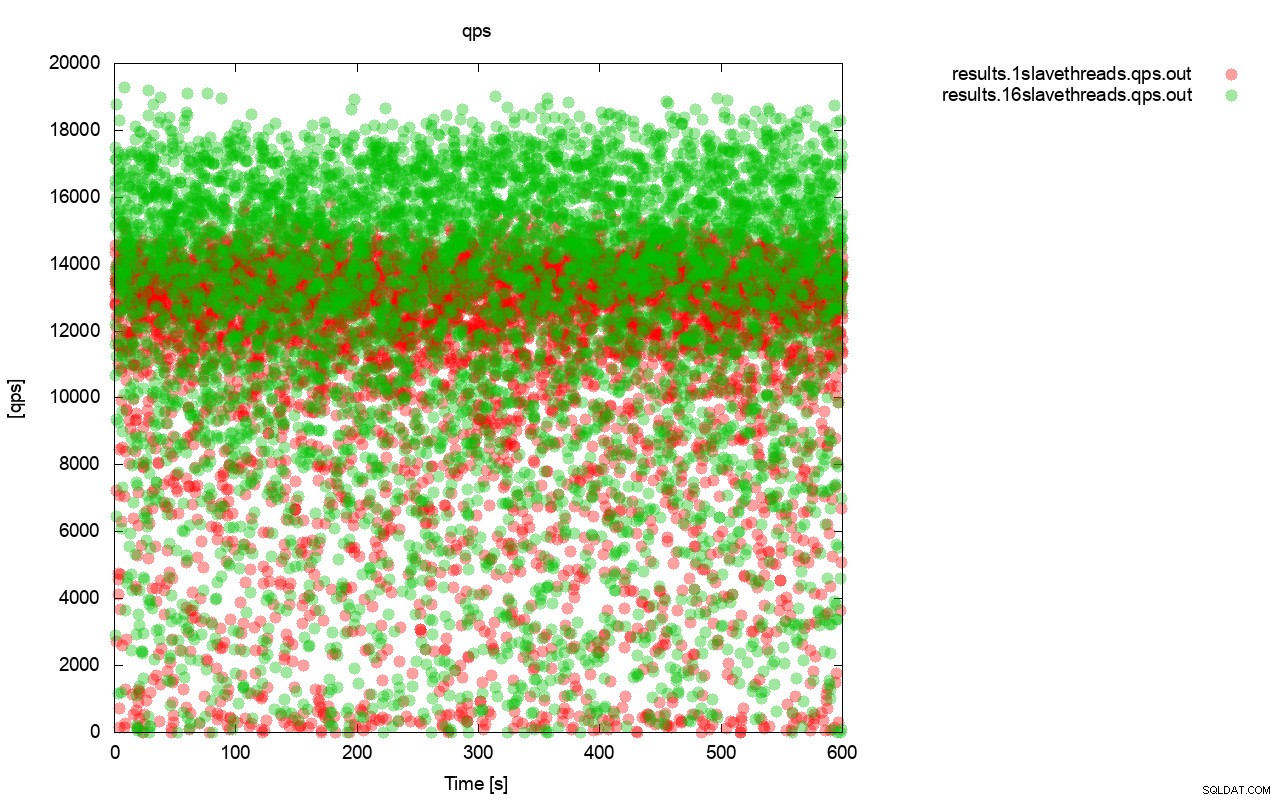
Za prvé, graf dotazu za sekundu. Nejprve si můžete všimnout, že v obou případech jsou výsledky všude. To většinou souvisí s nestabilním výkonem I/O úložiště a náhodným spouštěním řízení toku. Stále můžete vidět, že výkon „červeného“ výsledku (wsrep_slave_threads=1) je o dost nižší než „zeleného“ ( wsrep_slave_threads=16).
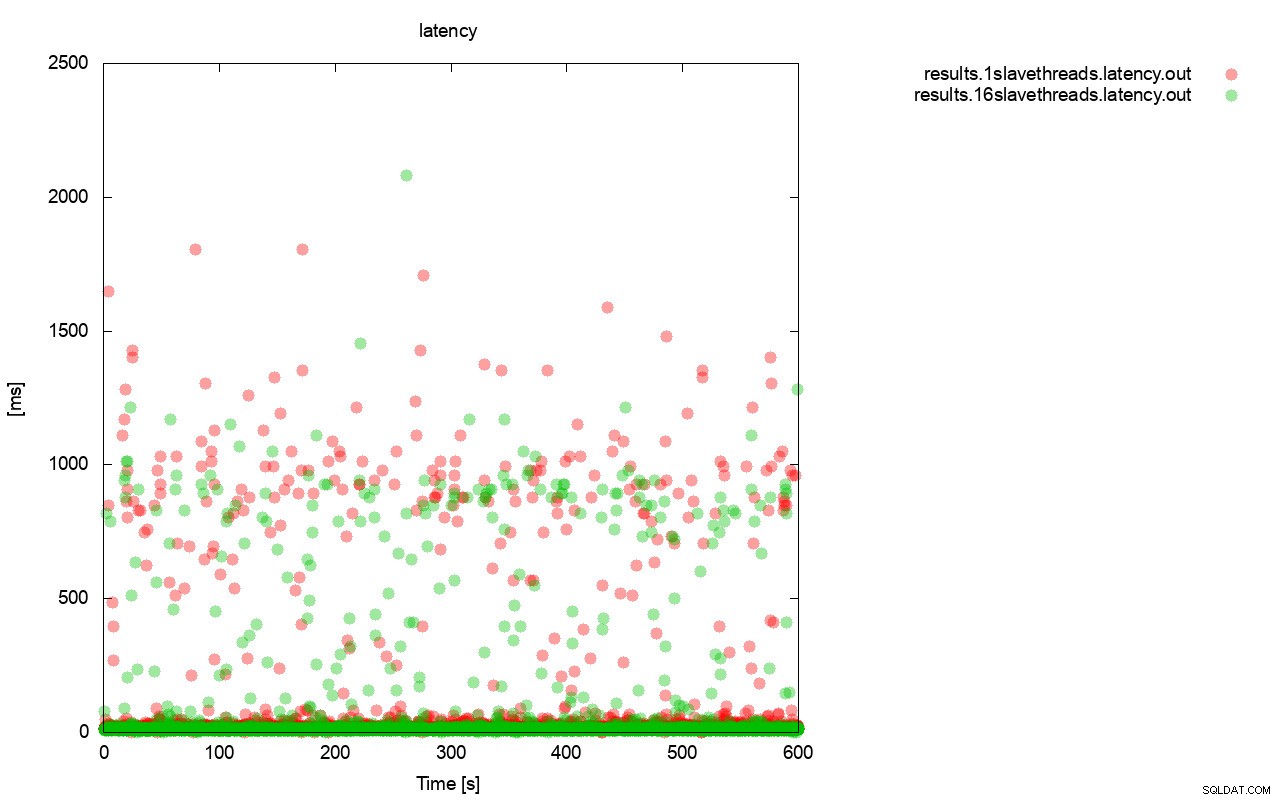
Docela podobný obrázek je, když se podíváme na latenci. Můžete vidět více (a obvykle hlubší) stání pro běh s wsrep_slave_thread=1.
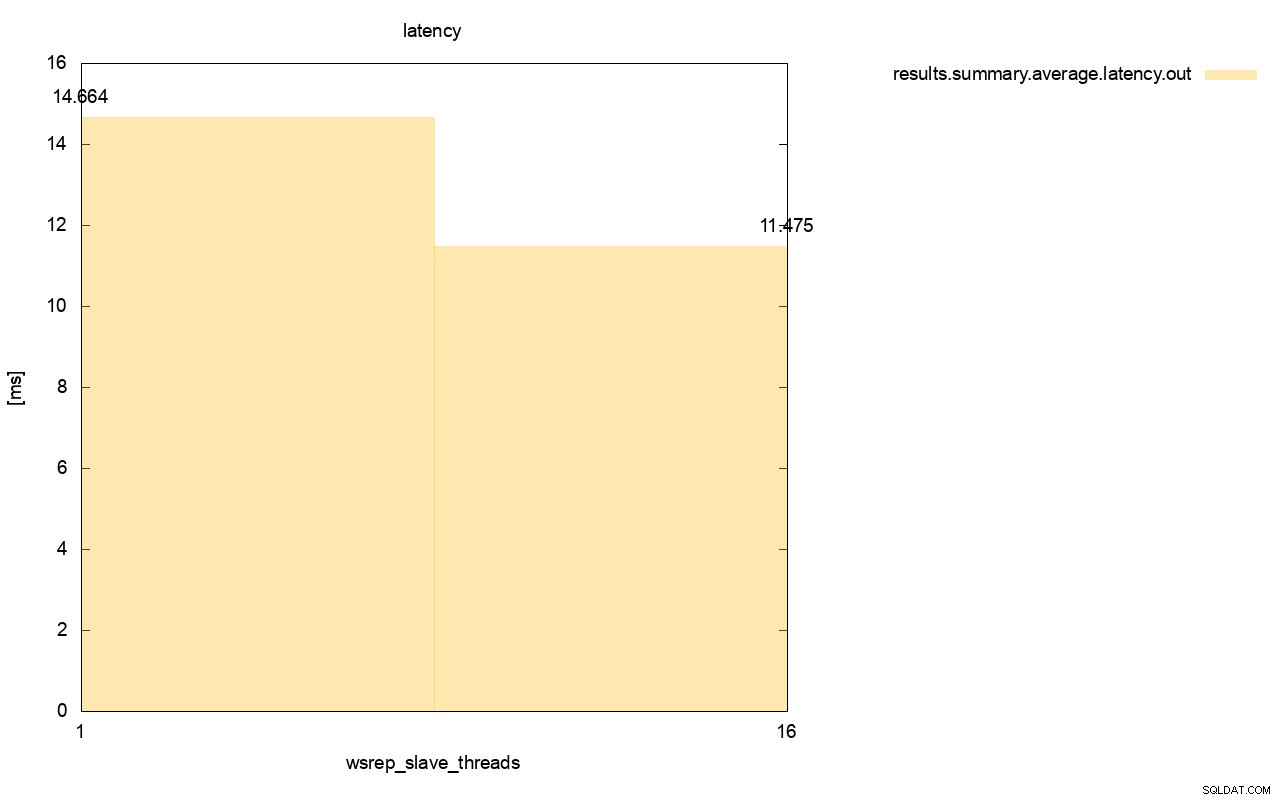
Rozdíl je ještě viditelnější, když jsme vypočítali průměrnou latenci napříč všemi běhy a můžete vidět, že latence wsrep_slave_thread=1 je o 27 % vyšší než latence s 16 podřízenými vlákny, což samozřejmě není dobré, protože chceme, aby byla latence nižší. , ne vyšší.
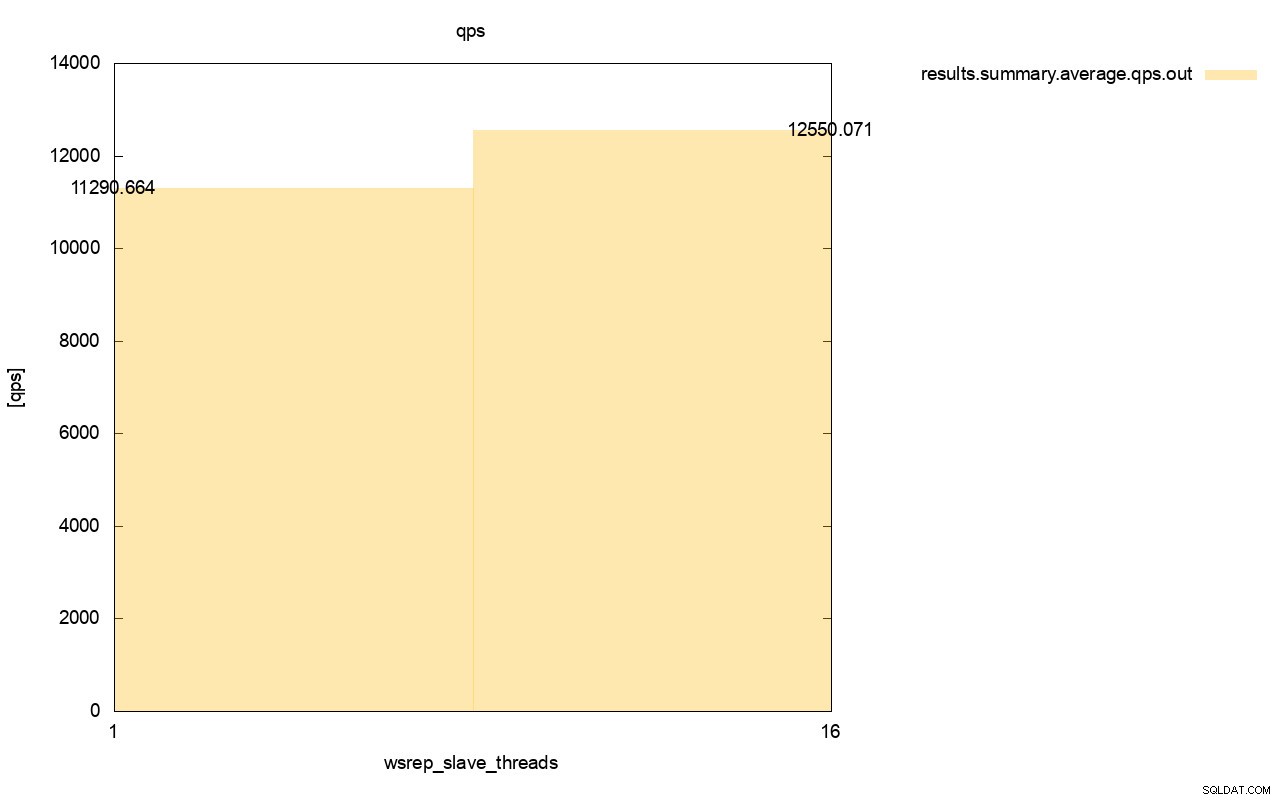
Rozdíl v propustnosti je také viditelný, přibližně 11% zlepšení, když jsme přidali více wsrep_slave_threads.
Jak vidíte, dopad tam je. Není to v žádném případě 16x (i když jsme tak zvýšili počet podřízených vláken v Galeře), ale rozhodně je to dost výrazné, takže to nemůžeme klasifikovat jako pouhou statistickou anomálii.
Mějte prosím na paměti, že v našem případě jsme použili docela malé uzly. Rozdíl by měl být ještě výraznější, pokud mluvíme o velkých instancích běžících na svazcích EBS s tisíci zřízených IOPS.
Pak bychom byli schopni provozovat sysbench ještě agresivněji, s vyšším počtem souběžných operací. To by mělo zlepšit paralelizaci zápisových sad a ještě dále zlepšit zisk z vícevláknového zpracování. Také rychlejší hardware znamená, že Galera bude moci využívat těchto 16 vláken efektivněji.
Při provádění testů, jako je tento, musíte mít na paměti, že musíte posunout nastavení téměř na jeho limity. Replikace s jedním vláknem zvládne poměrně velké zatížení a musíte provozovat velký provoz, aby skutečně nebyla dostatečně výkonná, aby zvládla úlohu.
Doufáme, že vám tento příspěvek na blogu poskytne více informací o schopnostech Galera Cluster paralelně používat sady zápisů a o omezujících faktorech, které to obklopují.