Pokud jste to ještě neviděli, právě jsme vydali ClusterControl 1.7.5 s velkými vylepšeními a novými užitečnými funkcemi. Některé z funkcí zahrnují Cluster Wide Maintenance, podporu pro verze CentOS 8 a Debian 10, podporu PostgreSQL 12, podporu MongoDB 4.2 a Percona MongoDB v4.0 a také nový MySQL Freeze Frame.
Počkejte, ale co je zmrazený rámec MySQL? Je to pro MySQL něco nového?
No, v samotném jádře MySQL to není nic nového. Je to nová funkce, kterou jsme přidali do ClusterControl 1.7.5 a která je specifická pro databáze MySQL. MySQL Freeze Frame v ClusterControl 1.7.5 bude pokrývat následující věci:
- Snímek stavu MySQL před selháním clusteru.
- Snímek seznamu procesů MySQL před selháním clusteru (již brzy).
- Kontrolujte incidenty clusteru v provozních zprávách nebo pomocí nástroje příkazového řádku s9s.
Toto jsou cenné soubory informací, které vám mohou pomoci vysledovat chyby a opravit vaše clustery MySQL/MariaDB, když věci půjdou na jih. V budoucnu plánujeme zahrnout také snímky stavových hodnot SHOW ENGINE InnoDB. Zůstaňte tedy naladěni na naše budoucí vydání.
Upozorňujeme, že tato funkce je stále ve stavu beta. Očekáváme, že při práci s našimi uživateli shromáždíme více datových sad. V tomto blogu vám ukážeme, jak tuto funkci využít, zvláště když potřebujete další informace při diagnostice clusteru MySQL/MariaDB.
ClusterControl při zpracování selhání clusteru
Při selhání clusteru ClusterControl nedělá nic, pokud není povoleno automatické obnovení (klastr/uzel), jak je uvedeno níže:

Po povolení se ClusterControl pokusí obnovit uzel nebo cluster pomocí vyvolání celé topologie klastru.
Pro MySQL, například v replikaci master-slave, musí mít v daný okamžik alespoň jednoho živého mastera, bez ohledu na počet dostupných slave/s. ClusterControl se pokusí opravit topologii alespoň jednou pro replikační clustery, ale poskytuje více opakování pro multi-master replikaci, jako je NDB Cluster a Galera Cluster. Obnova uzlu se pokouší obnovit selhávající databázový uzel, např. když byl proces zabit (abnormální vypnutí) nebo proces utrpěl OOM (Out-of-Memory). ClusterControl se připojí k uzlu přes SSH a pokusí se vyvolat MySQL. Již dříve jsme blogovali o tom, jak ClusterControl provádí automatické obnovení databáze a převzetí služeb při selhání, takže navštivte tento článek, kde se dozvíte více o schématu automatického obnovení ClusterControl.
V předchozí verzi ClusterControl <1.7.5 tyto pokusy o obnovení spouštěly alarmy. Ale jedna věc, kterou naši zákazníci postrádali, byla úplnější zpráva o incidentu s informacemi o stavu těsně před selháním clusteru. Dokud jsme si tento nedostatek neuvědomili a přidali tuto funkci do ClusterControl 1.7.5. Nazvali jsme to "MySQL Freeze Frame". MySQL Freeze Frame v době psaní tohoto článku nabízí stručné shrnutí incidentů vedoucích ke změnám stavu clusteru těsně před havárií. Nejdůležitější je, že na konci zprávy obsahuje seznam hostitelů a jejich proměnné a hodnoty globálního stavu MySQL.
Jak se liší zmrazený rámec MySQL s automatickým obnovením?
Zamrznutí rámce MySQL není součástí automatického obnovení ClusterControl. Bez ohledu na to, zda je automatické obnovení zakázáno nebo povoleno, MySQL Freeze Frame vždy odvede svou práci, pokud bude detekováno selhání clusteru nebo uzlu.
Jak funguje MySQL Freeze Frame?
V ClusterControl existují určité stavy, které klasifikujeme jako různé typy Stavu clusteru. MySQL Freeze Frame vygeneruje zprávu o incidentu, když jsou spuštěny tyto dva stavy:
- CLUSTER_DEGRADED
- CLUSTER_FAILURE
V ClusterControl je CLUSTER_DEGRADED, když můžete zapisovat do clusteru, ale jeden nebo více uzlů je mimo provoz. Když k tomu dojde, ClusterControl vygeneruje zprávu o incidentu.
Pro CLUSTER_FAILURE, ačkoli jeho nomenklatura vysvětluje sama sebe, je to stav, kdy váš cluster selže a již není schopen zpracovávat čtení nebo zápis. Pak je to stav CLUSTER_FAILURE. ClusterControl vygeneruje zprávu o incidentu bez ohledu na to, zda se proces automatického obnovení pokouší vyřešit nebo zda je deaktivován.
Jak povolíte MySQL Freeze Frame?
Zamrznutí MySQL rámce ClusterControl je ve výchozím nastavení povoleno a generuje hlášení o incidentu pouze tehdy, když jsou spuštěny nebo zjištěny stavy CLUSTER_DEGRADED nebo CLUSTER_FAILURE. Na straně uživatele tedy není potřeba nastavovat jakékoli konfigurační nastavení ClusterControl, ClusterControl to udělá automaticky za vás.
Vyhledání zprávy o incidentu zmrazeného rámce MySQL
V době psaní tohoto článku existují 4 způsoby, jak můžete najít zprávu o incidentu. Ty lze nalézt provedením následujících sekcí níže.
Použití karty Provozní zprávy
Provozní zprávy z předchozích verzí se používají pouze k vytváření, plánování nebo seznamování provozních zpráv, které vygenerovali uživatelé. Od verze 1.7.5 jsme zahrnuli zprávu o incidentu generovanou naší funkcí MySQL Freeze Frame. Viz příklad níže:
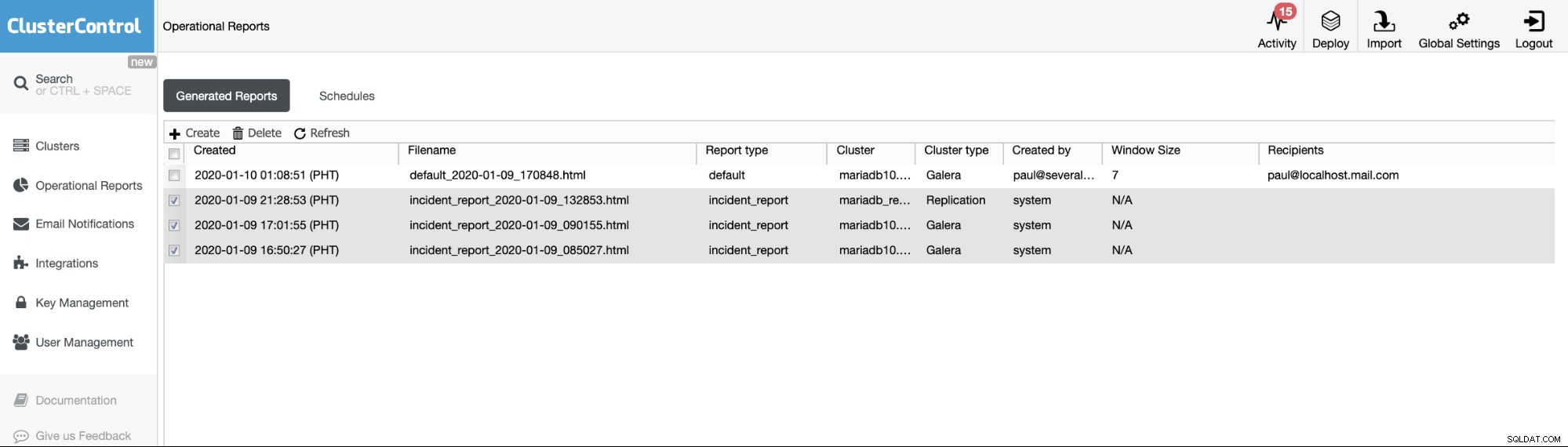
Zkontrolované položky nebo položky s typem zprávy ==incident_report jsou incidentem zprávy generované funkcí MySQL Freeze Frame v ClusterControl.
Použití chybových hlášení
Výběrem clusteru a vygenerováním chybové zprávy, tj. provedením tohoto procesu:
Použití příkazového řádku s9s CLI
Vygenerovaná zpráva o incidentu obsahuje pokyny nebo nápovědu, jak to můžete použít s příkazem CLI s9s. Níže je uvedeno, co je uvedeno ve zprávě o incidentu:
Tip! Použití nástroje s9s CLI vám umožní snadno získat data v tomto přehledu, např.:
s9s report --list --long
s9s report --cat --report-id=NPokud tedy chcete najít a vygenerovat chybové hlášení, můžete použít tento přístup:
[example@sqldat.com ~]$ s9s report --list --long --cluster-id=60
ID CID TYPE CREATED TITLE
19 60 incident_report 16:50:27 Incident Report - Cluster Failed
20 60 incident_report 17:01:55 Incident ReportPokud chci grep proměnné wsrep_* na konkrétním hostiteli, mohu provést následující:
[example@sqldat.com ~]$ s9s report --cat --report-id=20 --cluster-id=60|sed -n '/WSREP.*/p'|sed 's/ */ /g'|grep '192.168.10.80'|uniq -d
| WSREP_APPLIER_THREAD_COUNT | 4 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_CLUSTER_CONF_ID | 18446744073709551615 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_CLUSTER_SIZE | 1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_CLUSTER_STATE_UUID | 7c7a9d08-2d72-11ea-9ef3-a2551fd9f58d | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_EVS_DELAYED | 27ac86a9-3254-11ea-b104-bb705eb13dde:tcp://192.168.10.100:4567:1,9234d567-3253-11ea-92d3-b643c178d325:tcp://192.168.10.90:4567:1,9234d567-3253-11ea-92d4-b643c178d325:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b25e-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b25f-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b260-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b261-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b262-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b263-cfcbda888ea9:tcp://192.168.10.90:4567:1,b0b7cb15-3241-11ea-bdbc-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdbd-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdbe-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdbf-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdc0-1a21deddc100:tcp://192.168.10.100:4567:1,dea553aa-32b9-11ea-b321-9a836d562a47:tcp://192.168.10.100:4567:1,dea553aa-32b9-11ea-b322-9a836d562a47:tcp://192.168.10.100:4567:1,e27f4eff-3256-11ea-a3ab-e298880f3348:tcp://192.168.10.100:4567:1,e27f4eff-3256-11ea-a3ac-e298880f3348:tcp://192.168.10.100:4567:1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_GCOMM_UUID | 781facbc-3241-11ea-8a22-d74e5dcf7e08 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LAST_COMMITTED | 443 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LOCAL_CACHED_DOWNTO | 98 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LOCAL_RECV_QUEUE_MAX | 2 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LOCAL_STATE_UUID | 7c7a9d08-2d72-11ea-9ef3-a2551fd9f58d | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_PROTOCOL_VERSION | 10 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_PROVIDER_VERSION | 26.4.3(r4535) | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_RECEIVED | 112 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_RECEIVED_BYTES | 14413 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPLICATED | 86 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPLICATED_BYTES | 40592 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPL_DATA_BYTES | 31734 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPL_KEYS | 86 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPL_KEYS_BYTES | 2752 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_ROLLBACKER_THREAD_COUNT | 1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_THREAD_COUNT | 5 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_EVS_REPL_LATENCY | 4.508e-06/4.508e-06/4.508e-06/0/1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |Ruční vyhledání pomocí cesty k systémovému souboru
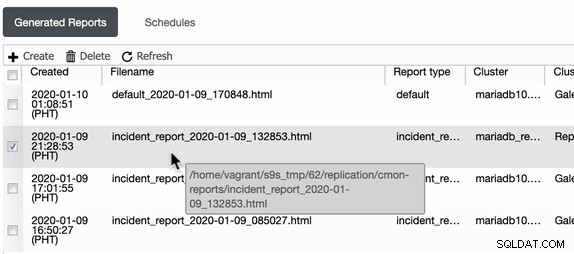
ClusterControl generuje tyto zprávy o incidentech v hostiteli, kde běží ClusterControl. ClusterControl vytvoří adresář v /home/
Existují nějaká nebezpečí nebo upozornění při používání MySQL Freeze Frame?
ClusterControl nemění ani neupravuje nic ve vašich MySQL uzlech nebo clusteru. MySQL Freeze Frame bude pouze číst ZOBRAZIT GLOBÁLNÍ STAV (od této chvíle) v určitých intervalech, aby se uložily záznamy, protože nemůžeme předvídat stav MySQL uzlu nebo clusteru, kdy může dojít k selhání nebo kdy může mít problémy s hardwarem nebo diskem. Není možné to předvídat, takže hodnoty ukládáme a můžeme tedy vygenerovat hlášení o incidentu v případě, že dojde k výpadku konkrétního uzlu. V tom případě je nebezpečí, že to bude, téměř žádné. Teoreticky může přidat sérii klientských požadavků na server(y) v případě, že některé zámky jsou drženy v MySQL, ale zatím jsme si toho nevšimli. Série testů to neukazuje, takže bychom byli rádi, kdybyste mohli víme nebo podáme žádost o podporu v případě problémů.
Jsou určité situace, kdy zpráva o incidentu nemusí být schopna shromáždit proměnné globálního stavu, pokud byl problémem před zmrazením konkrétního rámce ClusterControl za účelem shromáždění dat problém se sítí. To je zcela rozumné, protože ClusterControl nemůže žádným způsobem shromažďovat data pro další diagnostiku, protože v první řadě neexistuje žádné spojení s uzlem.
Nakonec se možná divíte, proč nejsou všechny proměnné zobrazeny v sekci GLOBAL STATUS? Mezitím jsme nastavili filtr, kde jsou v hlášení incidentu vyloučeny prázdné nebo 0 hodnot. Důvodem je, že chceme ušetřit nějaké místo na disku. Jakmile tyto zprávy o incidentech již nejsou potřeba, můžete je smazat na kartě Provozní zprávy.
Testování funkce MySQL Freeze Frame
Věříme, že toužíte vyzkoušet tento a uvidíte, jak to funguje. Ale prosím, ujistěte se, že to nespouštíte nebo netestujete v živém nebo produkčním prostředí. Pokryjeme 2 fáze scénáře v MySQL/MariaDB, jednu pro nastavení master-slave a jednu pro nastavení typu Galera.
Testovací scénář nastavení Master-Slave
V nastavení master-slave(ů) je to snadné a jednoduché vyzkoušet.
Krok jedna
Ujistěte se, že jste deaktivovali režimy automatického obnovení (klastr a uzel), jak je uvedeno níže:

takže se nepokusí ani se nepokusí opravit testovací scénář.
Krok dva
Přejděte do hlavního uzlu a zkuste nastavit pouze pro čtení:
example@sqldat.com[mysql]> set @@global.read_only=1;
Query OK, 0 rows affected (0.000 sec)Krok tři
Tentokrát byl spuštěn poplach a tak bylo vygenerováno hlášení o incidentu. Podívejte se níže, jak můj cluster vypadá:

a alarm byl spuštěn:

a bylo vygenerováno hlášení o incidentu:

Scénář testu nastavení clusteru Galera
U nastavení založeného na Galeře se musíme ujistit, že cluster již nebude dostupný, tj. dojde k selhání celého clusteru. Na rozdíl od testu Master-Slave můžete povolit automatické obnovení, protože si pohrajeme se síťovými rozhraními.
Poznámka:U tohoto nastavení se ujistěte, že máte více rozhraní, pokud testujete uzly ve vzdálené instanci, protože nemůžete rozhraní vyvolat, když sepnete rozhraní, ke kterému jste připojeni.
Krok jedna
Vytvořte 3-uzlový cluster Galera (například pomocí vagrant)
Krok dva
Vydejte příkaz (stejně jako níže), abyste simulovali problém se sítí a proveďte to se všemi uzly
[example@sqldat.com ~]# ifdown eth1
Device 'eth1' successfully disconnected.Krok tři
Nyní to odebralo můj cluster a mám tento stav:

vyhlásil poplach,

a vygeneruje hlášení o incidentu:

Pro ukázkovou zprávu o incidentu můžete použít tento nezpracovaný soubor a uložit jej jako html.
Je to docela jednoduché to zkusit, ale znovu, prosím, udělejte to pouze v neživém a neprodukčním prostředí.
Závěr
MySQL Freeze Frame v ClusterControl může být užitečný při diagnostice selhání. Při odstraňování problémů potřebujete velké množství informací, abyste mohli určit příčinu, a to je přesně to, co MySQL Freeze Frame poskytuje.