Nejlepší scénář je, že v případě selhání databáze máte dobrý plán obnovy po havárii (DRP) a vysoce dostupné prostředí s automatickým procesem převzetí služeb při selhání, ale... co se stane, když selže nějaký nečekaný důvod? Co když potřebujete provést ruční převzetí služeb při selhání? V tomto blogu se s vámi podělíme o některá doporučení, která byste měli dodržovat v případě, že potřebujete převzít svou databázi při selhání.
Ověřovací kontroly
Před provedením jakékoli změny musíte ověřit některé základní věci, abyste se vyhnuli novým problémům po procesu převzetí služeb při selhání.
Stav replikace
Je možné, že v době selhání není podřízený uzel aktuální z důvodu selhání sítě, vysokého zatížení nebo jiného problému, takže se musíte ujistit slave má všechny (nebo téměř všechny) informace. Pokud máte více než jeden podřízený uzel, měli byste také zkontrolovat, který z nich je nejpokročilejší, a zvolit jej pro převzetí služeb při selhání.
např.:Pojďme zkontrolovat stav replikace na serveru MariaDB.
MariaDB [(none)]> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.100.110
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000014
Read_Master_Log_Pos: 339
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 635
Relay_Master_Log_File: binlog.000014
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Last_Errno: 0
Skip_Counter: 0
Exec_Master_Log_Pos: 339
Relay_Log_Space: 938
Until_Condition: None
Until_Log_Pos: 0
Master_SSL_Allowed: No
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_SQL_Errno: 0
Replicate_Ignore_Server_Ids:
Master_Server_Id: 3001
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 0-3001-20
Parallel_Mode: conservative
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for the slave I/O thread to update it
Slave_DDL_Groups: 0
Slave_Non_Transactional_Groups: 0
Slave_Transactional_Groups: 0
1 row in set (0.000 sec)V případě PostgreSQL je to trochu jiné, protože potřebujete zkontrolovat stav WAL a porovnat použité s načtenými.
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn()=pg_last_wal_replay_lsn()
postgres-# THEN 0
postgres-# ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
postgres-# END AS log_delay;
log_delay
-----------
0
(1 row)Přihlašovací údaje
Před spuštěním převzetí služeb při selhání musíte zkontrolovat, zda vaše aplikace/uživatelé budou mít přístup k vašemu novému hlavnímu serveru s aktuálními přihlašovacími údaji. Pokud nereplikujete uživatele databáze, možná došlo ke změně přihlašovacích údajů, takže je před provedením jakýchkoli změn budete muset aktualizovat v podřízených uzlech.
např.:Můžete se dotazovat na tabulku uživatelů v databázi mysql a zkontrolovat přihlašovací údaje uživatele na serveru MariaDB/MySQL:
MariaDB [(none)]> SELECT Host,User,Password FROM mysql.user;
+-----------------+--------------+-------------------------------------------+
| Host | User | Password |
+-----------------+--------------+-------------------------------------------+
| localhost | root | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| localhost | mysql | invalid |
| 127.0.0.1 | backupuser | *AC01ED53FA8443BFD3FC7C448F78A6F2C26C3C38 |
| 192.168.100.100 | cmon | *F80B5EE41D1FB1FA67D83E96FCB1638ABCFB86E2 |
| 127.0.0.1 | root | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| ::1 | root | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| localhost | backupuser | *AC01ED53FA8443BFD3FC7C448F78A6F2C26C3C38 |
| 192.168.100.112 | user1 | *CD7EC70C2F7DCE88643C97381CB42633118AF8A8 |
| localhost | cmonexporter | *0F7AD3EAF21E28201D311384753810C5066B0964 |
| 127.0.0.1 | cmonexporter | *0F7AD3EAF21E28201D311384753810C5066B0964 |
| ::1 | cmonexporter | *0F7AD3EAF21E28201D311384753810C5066B0964 |
| 192.168.100.110 | rpl_user | *EEA7B018B16E0201270B3CDC0AF8FC335048DC63 |
+-----------------+--------------+-------------------------------------------+
12 rows in set (0.001 sec)V případě PostgreSQL můžete ke zjištění rolí použít příkaz ‚\du‘ a také musíte zkontrolovat konfigurační soubor pg_hba.conf, abyste mohli spravovat uživatelský přístup (nikoli přihlašovací údaje). Takže:
postgres=# \du
List of roles
Role name | Attributes | Member of
------------------+------------------------------------------------------------+-----------
admindb | Superuser, Create role, Create DB | {}
cmon_replication | Replication | {}
cmonexporter | | {}
postgres | Superuser, Create role, Create DB, Replication, Bypass RLS | {}
s9smysqlchk | Superuser, Create role, Create DB | {}A pg_hba.conf:
# TYPE DATABASE USER ADDRESS METHOD
host replication cmon_replication localhost md5
host replication cmon_replication 127.0.0.1/32 md5
host all s9smysqlchk localhost md5
host all s9smysqlchk 127.0.0.1/32 md5
local all all trust
host all all 127.0.0.1/32 trustPřístup k síti/firewallu
Přihlašovací údaje nejsou jediným možným problémem při přístupu k vašemu novému hlavnímu serveru. Pokud je uzel v jiném datovém centru nebo máte místní bránu firewall k filtrování provozu, musíte zkontrolovat, zda k němu máte povolen přístup, nebo dokonce, zda máte síťovou trasu k dosažení nového hlavního uzlu.
např.:iptables. Povolme provoz ze sítě 167.124.57.0/24 a po přidání zkontrolujte aktuální pravidla:
$ iptables -A INPUT -s 167.124.57.0/24 -m state --state NEW -j ACCEPT
$ iptables -L -n
Chain INPUT (policy ACCEPT)
target prot opt source destination
ACCEPT all -- 167.124.57.0/24 0.0.0.0/0 state NEW
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destinationnapř. trasy. Předpokládejme, že váš nový hlavní uzel je v síti 10.0.0.0/24, váš aplikační server je v 192.168.100.0/24 a můžete dosáhnout vzdálené sítě pomocí 192.168.100.100, takže do svého aplikačního serveru přidejte odpovídající trasu:
$ route add -net 10.0.0.0/24 gw 192.168.100.100
$ route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.100.1 0.0.0.0 UG 0 0 0 eth0
10.0.0.0 192.168.100.100 255.255.255.0 UG 0 0 0 eth0
169.254.0.0 0.0.0.0 255.255.0.0 U 1027 0 0 eth0
192.168.100.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0Akční body
Po kontrole všech zmíněných bodů byste měli být připraveni provést akce k překonání selhání vaší databáze.
Nová adresa IP
Jak budete podporovat podřízený uzel, změní se hlavní IP adresa, takže ji budete muset změnit ve své aplikaci nebo klientském přístupu.
Použití nástroje Load Balancer je skvělý způsob, jak se tomuto problému/změně vyhnout. Po procesu převzetí služeb při selhání zjistí Load Balancer starý master jako offline a (v závislosti na konfiguraci) odešle provoz na nový, aby na něj zapisoval, takže nemusíte ve své aplikaci nic měnit.
např.:Podívejme se na příklad konfigurace HAProxy:
listen haproxy_5433
bind *:5433
mode tcp
timeout client 10800s
timeout server 10800s
balance leastconn
option tcp-check
server 192.168.100.119 192.168.100.119:5432 check
server 192.168.100.120 192.168.100.120:5432 checkPokud je v tomto případě jeden uzel mimo provoz, HAProxy tam nebude posílat provoz a odesílá provoz pouze do dostupného uzlu.
Překonfigurujte podřízené uzly
Pokud máte více než jeden podřízený uzel, po povýšení jednoho z nich musíte překonfigurovat zbytek podřízených, aby se připojily k novému masteru. To může být časově náročný úkol v závislosti na počtu uzlů.
Ověřte a nakonfigurujte zálohy
Poté, co máte vše na svém místě (povýšení nového hlavního serveru, překonfigurování podřízených zařízení, zápis aplikací do nového hlavního serveru), je důležité provést nezbytná opatření, abyste předešli novému problému, takže zálohování je nutností tento krok. S největší pravděpodobností jste měli před incidentem spuštěnou politiku zálohování (pokud ne, musíte ji mít určitě), takže musíte zkontrolovat, zda zálohy stále běží, nebo budou fungovat v nové topologii. Je možné, že jste měli zálohy spuštěné na starém masteru nebo pomocí slave uzlu, který je nyní master, takže jej musíte zkontrolovat, abyste se ujistili, že vaše zásady zálohování budou po změnách stále fungovat.
Monitorování databáze
Když provádíte proces převzetí služeb při selhání, monitorování je nutností před procesem, během něj a po něm. Díky tomu můžete předejít problému dříve, než se zhorší, zjistit neočekávaný problém během převzetí služeb při selhání nebo dokonce zjistit, zda se po něm něco pokazí. Musíte například sledovat, zda vaše aplikace může přistupovat k vašemu novému hlavnímu serveru kontrolou počtu aktivních připojení.
Klíčové metriky ke sledování
Podívejme se na některé z nejdůležitějších metrik, které je třeba vzít v úvahu:
- Prodleva replikace
- Stav replikace
- Počet připojení
- Využití sítě/chyby
- Zatížení serveru (CPU, paměť, disk)
- Databázové a systémové protokoly
Vrácení zpět
Samozřejmě, pokud se něco pokazilo, musíte být schopni vrátit se zpět. Blokování provozu do starého uzlu a jeho udržování co nejizolovanější by pro to mohlo být dobrou strategií, takže v případě, že budete potřebovat vrátit zpět, budete mít starý uzel k dispozici. Pokud k vrácení dojde po několika minutách, v závislosti na provozu budete pravděpodobně muset vložit data těchto minut do starého hlavního uzlu, takže se ujistěte, že máte k dispozici a izolovaný také dočasný hlavní uzel, abyste mohli tyto informace převzít a použít je zpět. .
Automatizujte proces převzetí služeb při selhání pomocí ClusterControl
Když vidíte všechny tyto úkoly nezbytné k provedení převzetí služeb při selhání, s největší pravděpodobností je chcete automatizovat a vyhnout se veškeré této ruční práci. K tomu můžete využít některé z funkcí, které vám ClusterControl může nabídnout pro různé databázové technologie, jako je mimo jiné automatická obnova, zálohování, správa uživatelů, monitorování, to vše ze stejného systému.
S ClusterControl můžete ověřit stav replikace a její zpoždění, vytvořit nebo upravit pověření, znát stav sítě a hostitele a ještě více ověřit.
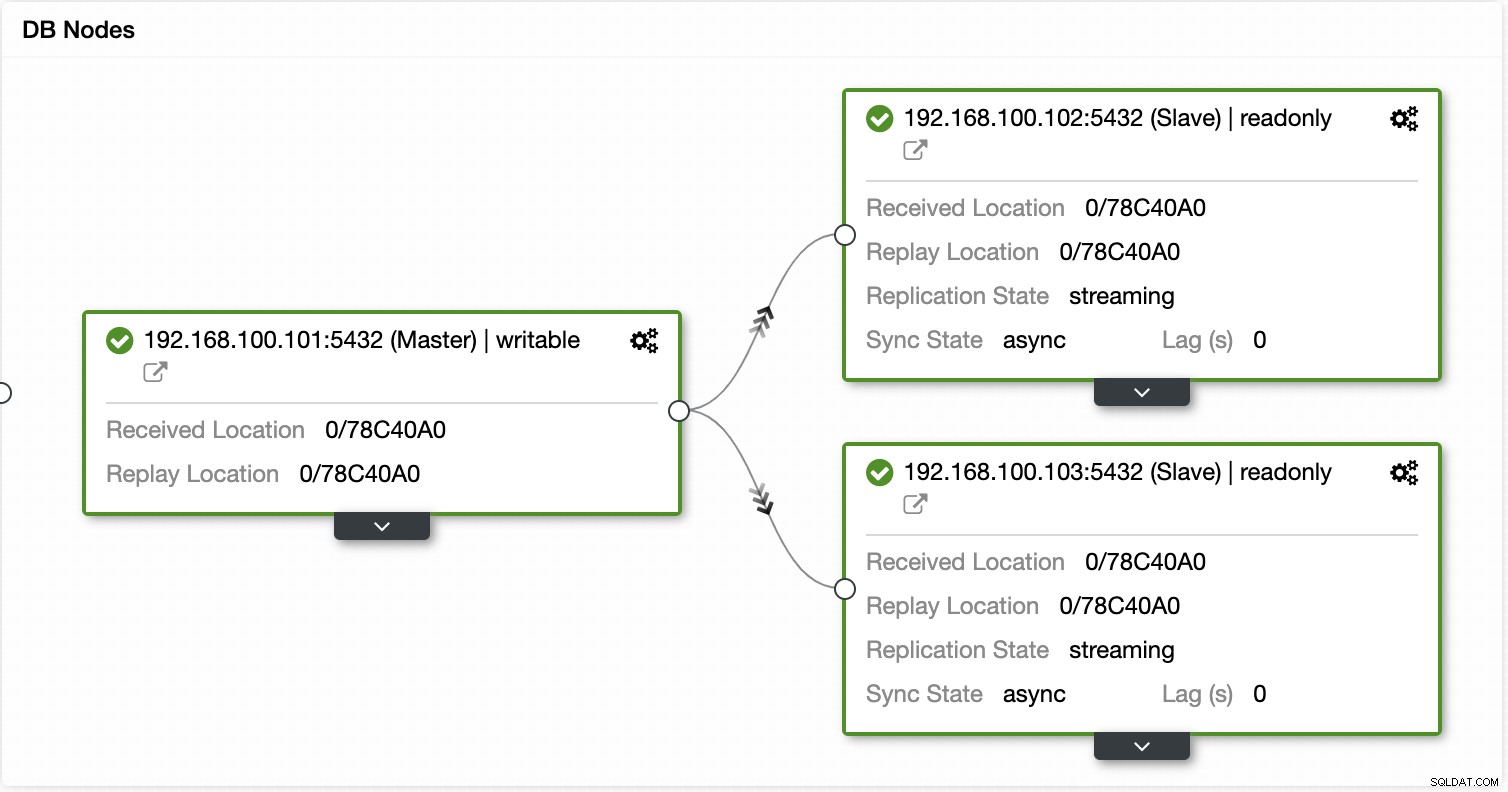
Pomocí ClusterControl můžete také provádět různé akce clusteru a uzlů, jako je podpora slave , restartovat databázi a server, přidat nebo odebrat databázové uzly, přidat nebo odebrat uzly nástroje pro vyrovnávání zatížení, znovu sestavit replikační slave a další.
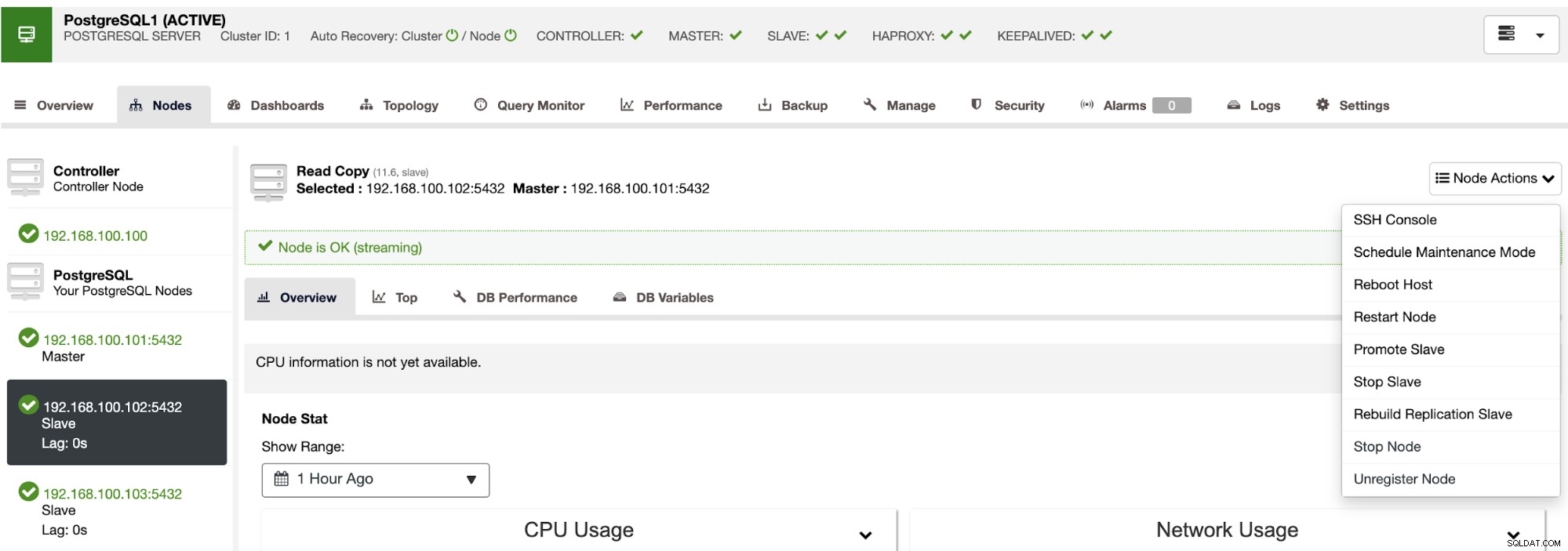
Pomocí těchto akcí můžete v případě potřeby vrátit zpět své převzetí služeb při selhání tím, že přebudujete a propagujete předchozí předlohu.
ClusterControl má monitorovací a výstražné služby, které vám pomohou zjistit, co se děje, nebo i když se něco stalo dříve.
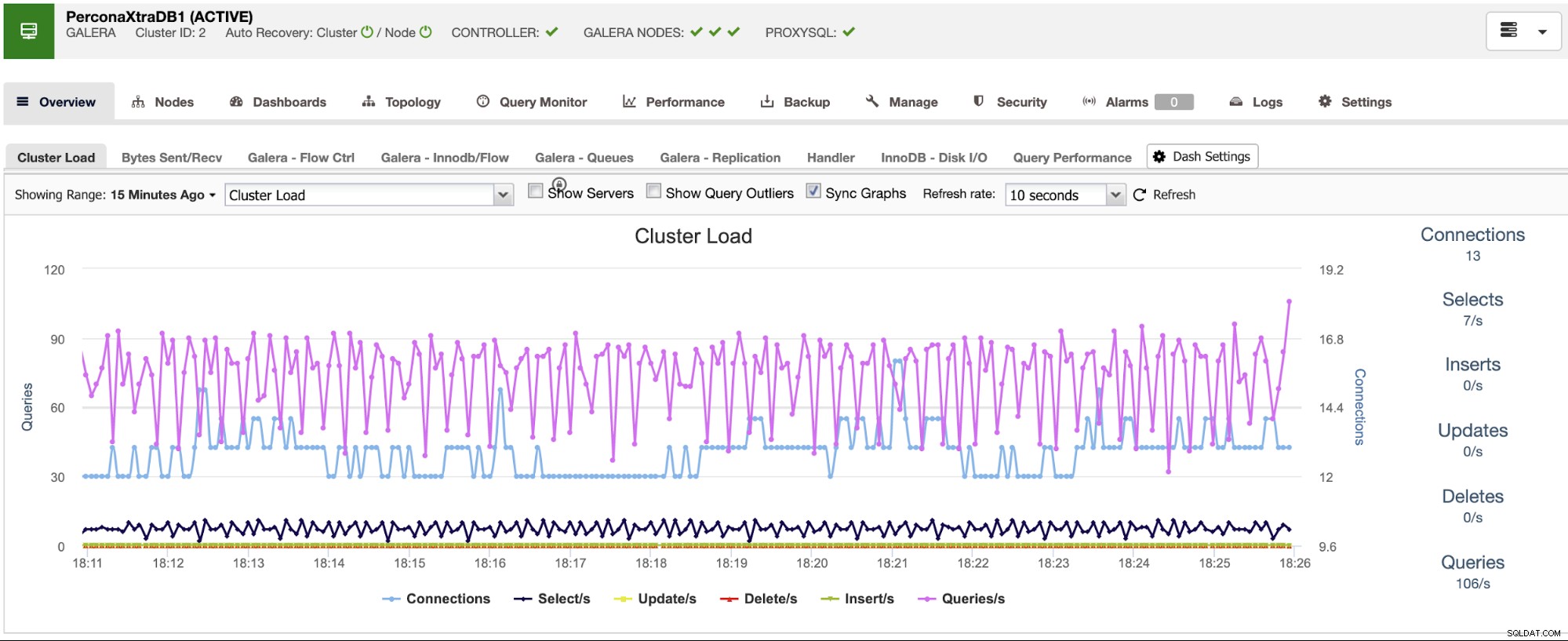
Můžete také použít sekci řídicího panelu pro uživatelsky přívětivější zobrazení o stavu vašich systémů.
Závěr
V případě selhání hlavní databáze budete chtít mít všechny informace k dispozici, abyste mohli co nejdříve provést potřebné akce. Mít dobrou DRP je klíčem k udržení vašeho systému v chodu po celou (nebo téměř celou) dobu. Tento DRP by měl zahrnovat dobře zdokumentovaný proces převzetí služeb při selhání, aby měl pro společnost přijatelný cíl doby obnovy (RTO).