Úvod
Před několika lety jsme byli pověřeni obchodním požadavkem na údaje o kartě ve specifickém formátu za účelem něčeho, co se nazývá „srovnání“. Záměrem bylo prezentovat data v tabulce do aplikace, která by spotřebovávala a zpracovávala data, která by měla dobu uchování šest měsíců. Pro tuto obchodní potřebu jsme museli vytvořit novou databázi a poté vytvořit základní tabulku jako dělenou tabulku. Zde popsaný proces je proces, který používáme k zajištění toho, aby data starší než šest měsíců byla přesunuta z tabulky čistým způsobem.
Něco o dělení
Table Partitioning je databázová technologie, která umožňuje ukládat data patřící do jedné logické jednotky (tabulky) jako sadu oddílů, které budou sedět na samostatné fyzické struktuře – datových souborech – prostřednictvím abstrakce nazvané File Groups na SQL Serveru. Proces vytváření této dělené tabulky zahrnuje dva klíčové objekty:
Funkce rozdělení :Funkce oddílu definuje, jak jsou řádky rozdělené tabulky mapovány na základě hodnot zadaného sloupce (sloupec oddílu). Dělená tabulka může být založena buď na seznamu nebo rozsah. Pro účely našeho případu použití (zachování dat za pouhých šest měsíců) jsme použili Rozsahový oddíl . Funkci oddílu lze definovat jako RANGE RIGHT nebo RANGE LEFT. Použili jsme RANGE RIGHT, jak je znázorněno v kódu ve výpisu 1, což znamená, že hraniční hodnota bude patřit k pravé straně intervalu hraničních hodnot, když jsou hodnoty seřazeny ve vzestupném pořadí zleva doprava.
-- Výpis 1:Vytvoření funkce oddílu POUŽÍVEJTE [post_office_history] VYTVOŘTE FUNKCI ODDĚLENÍPostTranPartFunc (datum a čas) JAKO ROZSAH SPRÁVNÝ PRO HODNOTY ('20190201','20190301','20190401','01'09'09','01'09'09 '20190801','20190901','20191001','20191101','20191201')GO Schéma rozdělení :Schéma oddílu je založeno na funkci oddílu a určuje, na kterých fyzických strukturách budou umístěny řádky patřící každému oddílu. Toho je dosaženo mapováním takových řádků na skupiny souborů. Výpis 2 ukazuje kód pro vytvoření schématu rozdělení. Před vytvořením schématu rozdělení musí existovat skupiny souborů, na které bude odkazovat.
-- Výpis 2:Vytvořte schéma rozdělení ---- Krok 1:Vytvořte skupiny souborů --POUŽÍVEJTE [hlavní]DATABÁZI GOALTER [post_office_history] PŘIDAT SKUPINU SOUBORŮ [JAN]ALTER DATABÁZI [post_office_history] PŘIDAT SKUPINU SOUBORŮ [FEB]ALTER DATABÁZI [historie_post_office ] PŘIDAT SKUPINU SOUBORŮ [MAR]ALTER DATABÁZI [post_office_history] PŘIDAT SKUPINU SOUBORŮ [APR]ALTER DATABÁZI [post_office_history] PŘIDAT SKUPINU SOUBORŮ [MAY]ALTER DATABÁZI [post_office_history] PŘIDAT [JUN]ALTER DATABÁZI_historie_SKUPINY [ČERVEN] ALTER DATABASEJALTERDATABASE [post_office_history] ] PŘIDAT SKUPINU SOUBORŮ [AUG]ALTER DATABÁZE [post_office_history] PŘIDAT SKUPINU SOUBORŮ [SEP]ALTER DATABASE [post_office_history] PŘIDAT SKUPINU SOUBORŮ [OCT]ALTER DATABÁZE [post_office_history] PŘIDAT SKUPINU SOUBORŮ [NOV]ALTER DATABASE_EC]GODDFILE Step-office 2:Přidejte datové soubory do každé skupiny souborů --POUŽÍVEJTE [hlavní]DATABÁZI GOALTER [post_office_history] PŘIDEJTE SOUBOR (NÁZEV =N'post_office_history_part_01', NÁZEV SOUBORU =N'E:\MSSQL\DATA\post_office_history_part_01.ndf', VELIKOST1 =2KBROW7TH1, 2009 SIZE=1048576 KB) DO SKUPINY SOUBORŮ [JAN] ZMĚNIT DATABÁZI [post_office_history] PŘIDAT SOUBOR (NÁZEV =N'post_office_history_part_02', NÁZEV SOUBORU =N'E:\MSSQL\DATA\post_office_history_part_02.ndf', FIL20951 SIZE =B040951 SIZE, FILEGFI57 SIZE FEB]ALTER DATABASE [post_office_history] PŘIDAT SOUBOR (NÁZEV =N'post_office_history_part_03', FILENAME =N'E:\MSSQL\DATA\post_office_history_part_03.ndf', VELIKOST =2097152 KB, DLE1_post_TO75 GROUP] FIL104KATASKUPINY 6BASEK ] PŘIDEJTE SOUBOR (NÁZEV =N'post_office_history_part_04', NÁZEV SOUBORU =N'E:\MSSQL\DATA\post_office_history_part_04.ndf', VELIKOST =2097152 kB, FILEGROWTH =1048576 KB) DO SOUBORU DATABARSE N'post_office_history_part_05', NÁZEV SOUBORU =N'E:\MSSQL\DATA\post_office_history_part_05.ndf', VELIKOST =2097152 kB, FILEGROWTH =1048576 KB) TO FILEGROUP [MAY]post_office NÁZEV_SOUBORU [MAY]post_office NÁZEV_DATABASE'ADD'ALTER_office NATABASE' =N'G:\MSSQL\DATA\post_office_history_part_06. ndf', VELIKOST =2097152 KB, ŠÍŘENÍ SOUBORU =1048576 KB) DO SKUPINY SOUBORŮ [ČERVEN] ZMĚNIT DATABÁZI [post_office_history] PŘIDAT SOUBOR (NÁZEV =N'post_office_history_part_07', NÁZEV SOUBORU =17_část1_5\00_history_BSQL_0SQL_07 , FILEGROWTH =1048576 KB) DO SKUPINY SOUBORŮ [ČERVENEC] ZMĚNIT DATABÁZI [post_office_history] PŘIDAT SOUBOR (NÁZEV =N'post_office_history_part_08', NÁZEV SOUBORU =N'G:\MSSQL\DATA\post_office_history_part,2KZEB,TH298 =TH2575WSI,048 TO28 TO4857KZEB08 =TH28572KZE08 FILEGROUP [AUG]ALTER DATABASE [post_office_history] PŘIDAT SOUBOR (JMÉNO =N'post_office_history_part_09', FILENAME =N'G:\MSSQL\DATA\post_office_history_part_09.ndf', VELIKOST =2097152KWB, TO597152KWB, TO50BATA152KWB, FIL70 FILENAME [post_office_history] PŘIDAT SOUBOR (NÁZEV =N'post_office_history_part_10', NÁZEV SOUBORU =N'G:\MSSQL\DATA\post_office_history_part_10.ndf', VELIKOST =2097152 KB, FILEGROWTH =104857 GOLFICE] [DDLE_OFFICE] GROUP NAME =N'post_office_history_part_09', FILENAME =N'G:\MS SQL\DATA\post_office_history_part_11.ndf', VELIKOST =2097152 KB, SOUBOR =1048576 KB) DO SKUPINY SOUBORŮ [NOV]ALTER DATABASE [post_office_history] PŘIDAT SOUBOR (NÁZEV =N'ATA_1\post_office_history_část N'ATA\20MS'Dhistory_part'part'post_office_1\post_office'Dhistory_část ndf', VELIKOST =2097152 KB, FILEGROWTH =1048576 KB) DO FILEGROUP [DEC]GO-- Krok 3:Vytvořte schéma oddílů --PRINT 'vytváření schématu oddílů ...'GOUSE [post_office_history]VYTVOŘTE SCHÉMA ROZDĚLENÍ NA ZAČÁTEK ZAČÁTEK ZAČÁTEK ZAČÁTEK ZAČÁTEK ZAČÁTEK ZAČÁTEK PŘÍSPĚVKY ,ÚNOR, BŘEZEN, DUBEN, KVĚTEN, ČERVEN, ČERVEN, SRPEN, ZÁŘÍ, ŘÍJN, LISTOPAD, PROSINEC) GO
Všimněte si, že pro N oddíly, vždy bude N-1 hranice. Při definování první skupiny souborů ve schématu rozdělení je třeba postupovat opatrně. První hranice uvedená ve funkci oddílu bude ležet mezi první a druhou skupinou souborů, takže tato hodnota hranice (20190201) bude sedět ve druhém oddílu (FEB). Navíc je ve skutečnosti možné umístit všechny oddíly do jedné skupiny souborů, ale v tomto případě jsme zvolili samostatné skupiny souborů.
Ušpiníme si ruce
Pojďme se tedy ponořit do úkolu přepínání oddílů!
První věc, kterou musíme udělat, je přesně určit, jak jsou naše data rozdělena mezi oddíly, abychom věděli, který oddíl bychom chtěli přepnout. Obvykle vypneme nejstarší oddíl.
-- Výpis 3:Zkontrolujte distribuci dat v oddílech --POUŽÍVEJTE POST_OFFICE_HISTORYGOSELECT $PARTITION.POSTTRANPARTFUNC(DATETIME_TRAN_LOCAL) JAKO [ČÍSLO ODDĚLENÍ] , MIN(DATETIME_TRAN_LOCAL) JAKO [MIN DATE] , MAX (DATETIME_TRAN_DATELOCAL) JAKO [MAX COUNT(*) JAKO [ROWS IN PARTITION]OD DBO.POST_TRAN_TAB – ROZDĚLENÁ TABLEGROUP PODLE $PARTITION.POSTTRANPARTFUNC(DATETIME_TRAN_LOCAL)ORDER BY [PARTITION NUMBER]PŘEJÍT
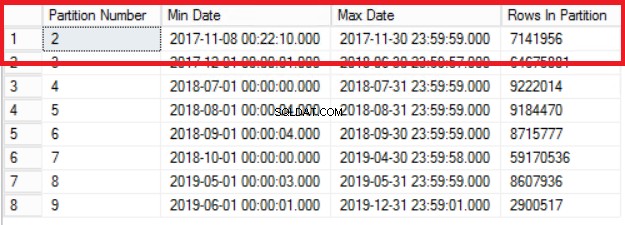
Obr. 1 Výstup výpisu 3
Obr. 1 nám ukazuje výstup dotazu ve výpisu 3. Nejstarší oddíl je oddíl 2, který obsahuje řádky z roku 2017. Ověříme to dotazem ve výpisu 4. Výpis 4 nám také ukazuje, která skupina souborů obsahuje data v oddílu 2.
-- Výpis 4:Zkontrolujte skupinu souborů přidruženou k oddílu --POUŽÍVEJTE POST_OFFICE_HISTORYGOSELECT PS.NAME JAKO PSNAME, DDS.DESTINATION_ID JAKO ČÍSLO PARTITION, FG.NAME JAKO FILEGROUPNAMEFROM (((SYS.TABLES AS T INNER JOIN SYS.INDEXES AS I ON (T.OBJECT_ID =I.OBJECT_ID)) VNITŘNÍ PŘIPOJENÍ K SYS.PARTITION_SCHEMES JAKO PS ZAPNUTO (I.DATA_SPACE_ID =PS.DATA_SPACE_ID)) VNITŘNÍ PŘIPOJENÍ SYS.DESTINATION_DATA_SPACES JAKO DDS ZAPNUTO (PS.DATA_SPACE_ID)_INS_ID INSTALACE SYSTÉMU FILEGROUPS AS FG ON DDS.DATA_SPACE_ID =FG.DATA_SPACE_IDWHERE (T.NAME ='POST_TRAN_TAB') A (I.INDEX_ID IN (0,1)) A DDS.DESTINATION_ID =$PARTITION.POSTTRANPARTFUNC('20171;
Obr. 1 Výstup výpisu 3
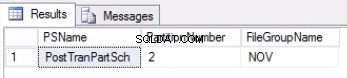
Obr. 2 Výstup výpisu 4
Výpis 4 nám ukazuje, že skupina souborů spojená s oddílem 2 je NOV . Abychom mohli vypnout oddíl 2, potřebujeme tabulku historie, která je replikou živé tabulky, ale je umístěna ve stejné skupině souborů jako oddíl, který hodláme vypnout. Protože již tuto tabulku máme, vše, co potřebujeme, je znovu ji vytvořit v požadované skupině souborů. Musíte také znovu vytvořit seskupený index. Vezměte na vědomí, že tento seskupený index má stejnou definici jako seskupený index v tabulce post_tran_tab a také sedí ve stejné skupině souborů jako post_tran_tab_hist tabulka.
-- Výpis 5:Znovu vytvořte tabulku historie -- Znovu vytvořte tabulku historie --USE [post_office_history]GOSET ANSI_NULLS ONGOSET QUOTED_IDENTIFIER ONGOSET ANSI_PADDING ONGODROP TABLE [dbo].[post_tran_tab_hist]TABLE GOCREATE].[GOCREATE].[TABLE] post_tran_tab_hist]( [tran_nr] [bigint] NOT NULL, [tran_type] [char](2) NULL, [tran_reversed] [char](2) NULL, [batch_nr] [int] NULL, [message_type] [char](4 ) NULL, [název_zdrojového_uzlu] [varchar](12) NULL, [system_trace_audit_nr] [znak](6) NULL, [settle_currency_code] [char](3) NULL, [sink_node_name] [varchar](30) NULL, [sink_code_currency_currency [znak](3) NULL, [to_account_id] [varchar](30) NULL, [pan] [varchar](19) NOT NULL, [pan_encrypted] [char](18) NULL, [pan_reference] [char](70 ) NULL, [datetime_tran_local] [datetime] NOT NULL, [trans_amount_req] [float] NOT NULL, [trans_amount_rsp] [float] NOT NULL, [trans_cash_req] [float] NOT NULL, [tran_cash_rsp] [float] NOT_NULL, ] [char](10) NULL, [merchant_type] [char](4) NULL, [pos_entry_mode] [char] (3) NULL, [kód_podmínky] [znak](2) NULL, [acquiring_inst_id_code] [varchar](11) NULL, [retrieval_reference_nr] [char](12) NULL, [auth_id_rsp] [char](6) NULL, [ rsp_code_rsp] [znak](2) NULL, [kód_omezení_služby] [znak](3) NULL, [id_terminálu] [znak](8) NULL, [vlastník_terminálu] [varchar](25) NULL, [kód_akceptoru_karty] [znak]( 15) NULL, [card_acceptor_name_loc] [char](40) NULL, [from_account_id] [varchar](28) NULL, [auth_reason] [char](1) NULL, [auth_type] [char](1) NULL, [message_reason_code ] [znak](4) NULL, [datetime_req] [datetime] NULL, [datetime_rsp] [datetime] NULL, [from_account_type] [char](2) NULL, [to_account_type] [char](2) NULL, [insert_date] [datetime] NOT NULL, [tran_postilion_originated] [int] NOT NULL, [card_product] [varchar](20) NULL, [card_seq_nr] [char](3) NULL, [expiry_date] [char](4) NULL, [srcnode_cash_approved ] [float] NOT NULL, [tran_completed] [char](2) NULL) ON [NOV] GOSET ANSI_PADDING OFFGO-- Znovu vytvořit seskupený index --USE [post_office_history]GO VYTVOŘTE CLUSTEROVANÝ INDEX [IX_Datetime_Local] ZAPNUTO [dbo].[post_tran_tab_hist] ( [datetime_tran_local] ASC, [tran_nr] ASC ) POMOCÍ (PAD_INDEX =VYPNUTO, STATISTICS_NORECOMPUTE =VYPNUTO, SORT_IN_TEMPDOPKEY =_EXISTING OFF, IMPDOPKEY =_EXISTING_TEMPDOPKEY =EXISTING_TEMPDOP =, ALLOW_ROW_LOCKS =ON, ALLOW_PAGE_LOCKS =ON) ON [NOV]PŘEJÍT
Vypnutí posledního oddílu je nyní jednořádkový příkaz. Počítání obou tabulek před a po provedení tohoto jednořádkového příkazu poskytne jistotu, že máme všechna požadovaná data.
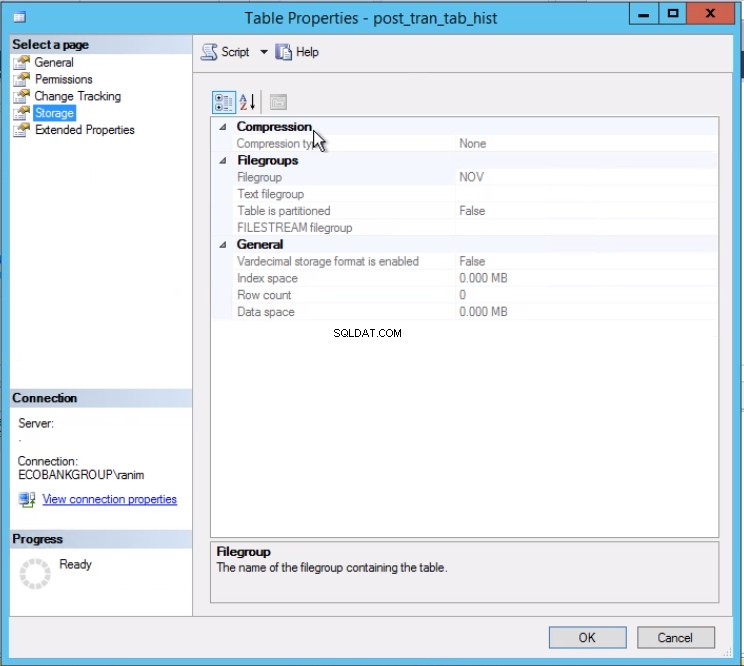
Obr. 3 Tabulka post_tran_tab_hist se nachází ve skupině souborů NOV
-- Výpis 6:Vypnutí posledního oddílu SELECT COUNT(*) Z 'POST_TRAN_TAB';SELECT COUNT(*) Z 'POST_TRAN_TAB_HIST';POUŽITÍ [POST_OFFICE_HISTORY]TABULKA BRANKA POST_TRAN_TAB PŘEPNOUT ODDĚLENÍ (*) 2 FOTOGRAM POST_TRAN_TAB';SELECT COUNT(*) Z 'POST_TRAN_TAB_HIST';
Protože jsme vypnuli poslední oddíl, hranici již nepotřebujeme. Sloučíme dva rozsahy dříve rozdělené touto hranicí pomocí příkazu ve výpisu 7. Dále zkrátíme tabulku historie, jak je znázorněno ve výpisu 8. Děláme to, protože o to jde:odstranění starých dat, která již nepotřebujeme.
-- Výpis 7:Sloučení rozsahů oddílů-- Sloučit rozsahUSE [POST_OFFICE_HISTORY]FUNKCE ROZDĚLENÍ BRANKA POSTTRANPARTFUNC() ROZSAH SLOUČENÍ ('20171101');-- Potvrďte, že rozsah je sloučenUSE [POST_OFFICE_HISTORY]GOpreSELECTI *FROMS>
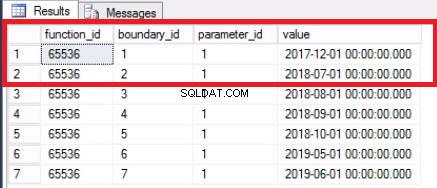
Obr. 4 Sloučená hranice
-- Výpis 8:Zkrácení tabulky historieUSE [post_office_history]GOTRUNCATE TABLE post_tran_tab_hist;GO
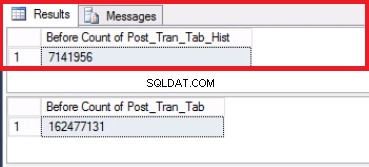
Obr. 5 Počet řádků pro obě tabulky před zkrácením
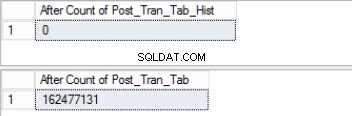
Vezměte na vědomí, že počet řádků v tabulce historie je přesně stejný jako počet řádků dříve v oddílu 2, jak je znázorněno na obr. 1. Další míli můžete udělat také obnovením prázdného místa ve skupině souborů, která patří do poslední rozdělit. To bude užitečné, pokud potřebujete tento prostor pro nová data, která budou sedět na dřívějším oddílu. Tento krok nemusí být nutný, pokud máte pocit, že máte ve svém prostředí dostatek prostoru.
-- Výpis 9:Obnovení místa v operačním systému-- Zjistěte, že byl soubor vyprázdněnUSE [post_office_history]GOSELECT DF.FILE_ID, DF.NAME, DF.PHYSICAL_NAME, DS.NAME, DS.TYPE, DF.STATE_DESC FROM SYS .DATABASE_FILES DFJOIN SYS.DATA_SPACES DS ON DF.DATA_SPACE_ID =DS.DATA_SPACE_ID;
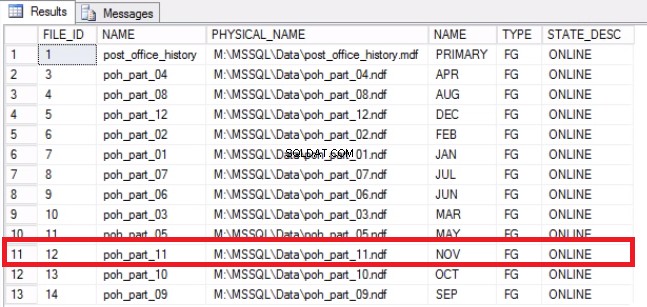
Obr. 7 Mapování souborů na skupinu souborů
-- Zmenšete soubor na 2 GBUSE [post_office_history]GODBCC SHRINKFILE (N'post_office_history_part_11', 2048)GO-- Z operačního systému potvrďte volné místo na discích VYBERTE DISTINCT DB_NAME (S.DATABASE_ID) JAKO DATABASE_NAME.DATABASE_ID,S. VOLUME_MOUNT_POINT--, S.VOLUME_ID, S.LOGICAL_VOLUME_NAME, S.FILE_SYSTEM_TYPE, S.TOTAL_BYTES/1024/1024/1024 AS [TOTAL_SIZE (GB)], S.AVAILABLE_BYTES/10424 ASFREE_424/1 VLEVO ((ROUND (((S.AVAILABLE_BYTES*1,0)/S.TOTAL_BYTES), 4)*100),4) JAKO PERCENT_FREEFROM SYS.MASTER_FILES JAKO FCROSS POUŽÍT SYS.DM_OS_VOLUME_STATS (F.DATABASE_ID) ASHERE DBASE_ID, F.FIRE (S.DATABASE_ID) ='POST_OFFICE_HISTORY';

Obr. 8 Volné místo v operačním systému
Závěr
V tomto článku jsme provedli postup, jak vypnout oddíly z rozdělené tabulky. Jedná se o velmi účinný způsob, jak nativně řídit růst dat v SQL Server. V aktuálních verzích SQL Serveru jsou k dispozici pokročilejší technologie, jako je Stretch Database.
Odkazy
Isakov, V. (2018). Zkouška č. 70-764 Správa infrastruktury databáze SQL. Pearson Education
Dělené tabulky a indexy v SQL Server