Moodle je velmi oblíbená platforma pro provozování online kurzů. Se situací, kterou vidíme v roce 2020, tvoří Moodle spolu s komunikátory, jako je Zoom, páteř služeb, které umožňují online výuku a výuku doma. Poptávka po platformách Moodle se oproti předchozím letům výrazně zvýšila. Byly vybudovány nové platformy, byla dodatečně zatížena platformy, které historicky fungovaly pouze jako pomocný nástroj a nyní mají řídit celé vzdělávací úsilí. Jak škálovat Moodle? Na toto téma máme blog. Jak škálovat backend databáze pro Moodle? No, to je jiný příběh. Pojďme se na to podívat, protože škálování databází není nejjednodušší věc, zvláště pokud Moodle přidává svůj vlastní malý obrat.
Jako vstupní bod použijeme architekturu popsanou v jednom z našich dřívějších příspěvků. MariaDB Cluster s ProxySQL a Keepalived navíc.
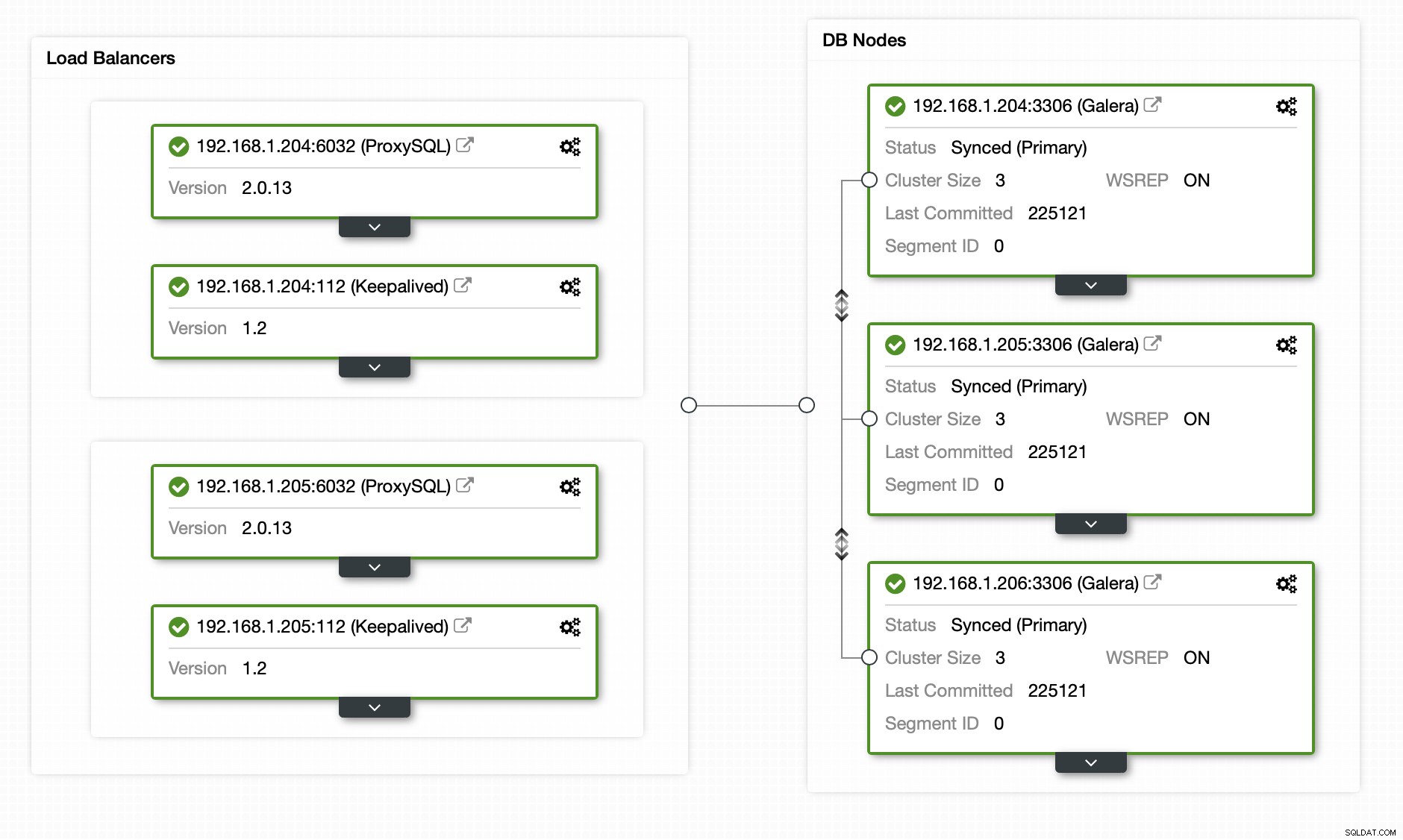
Jak vidíte, máme tříuzlový klastr MariaDB s ProxySQL, který odděluje bezpečné čtení od zbytku provozu na základě uživatele.
<?php // Moodle configuration file
unset($CFG);
global $CFG;
$CFG = new stdClass();
$CFG->dbtype = 'mysqli';
$CFG->dblibrary = 'native';
$CFG->dbhost = '192.168.1.222';
$CFG->dbname = 'moodle';
$CFG->dbuser = 'moodle';
$CFG->dbpass = 'pass';
$CFG->prefix = 'mdl_';
$CFG->dboptions = array (
'dbpersist' => 0,
'dbport' => 6033,
'dbsocket' => '',
'dbcollation' => 'utf8mb4_general_ci',
'readonly' => [
'instance' => [
'dbhost' => '192.168.1.222',
'dbport' => 6033,
'dbuser' => 'moodle_safereads',
'dbpass' => 'pass'
]
]
);
$CFG->wwwroot = 'https://192.168.1.200/moodle';
$CFG->dataroot = '/var/www/moodledata';
$CFG->admin = 'admin';
$CFG->directorypermissions = 0777;
require_once(__DIR__ . '/lib/setup.php');
// There is no php closing tag in this file,
// it is intentional because it prevents trailing whitespace problems!Uživatel, jak je uvedeno výše, je definován v konfiguračním souboru Moodle. To nám umožňuje automaticky a bezpečně posílat zápisy a všechny příkazy SELECT, které vyžadují konzistenci dat, do uzlu zapisovače a přitom stále odesílat některé SELECTy do zbývajících uzlů v clusteru MariaDB.
Předpokládejme, že toto konkrétní nastavení nám nestačí. Jaké máme možnosti? V nastavení máme dva hlavní prvky – MariaDB Cluster a ProxySQL. Zvážíme problémy na obou stranách:
- Co lze udělat, když si instance ProxySQL nedokáže poradit s provozem?
- Co lze udělat, když MariaDB Cluster nezvládne provoz?
Začněme prvním scénářem.
Instance proxySQL je přetížená
V současném prostředí může provoz obsluhovat pouze jedna instance ProxySQL – ta, na kterou odkazuje virtuální IP. Zůstane nám tak instance ProxySQL, která funguje jako pohotovostní režim – je v provozu, ale k ničemu se nepoužívá. Pokud se aktivní instance ProxySQL blíží k saturaci CPU, můžete chtít udělat několik věcí. Za prvé, samozřejmě, můžete škálovat vertikálně – zvětšení velikosti instance ProxySQL může být nejjednodušší způsob, jak ji nechat zvládnout vyšší provoz. Mějte prosím na paměti, že ProxySQL je ve výchozím nastavení nakonfigurováno pro použití 4 vláken.
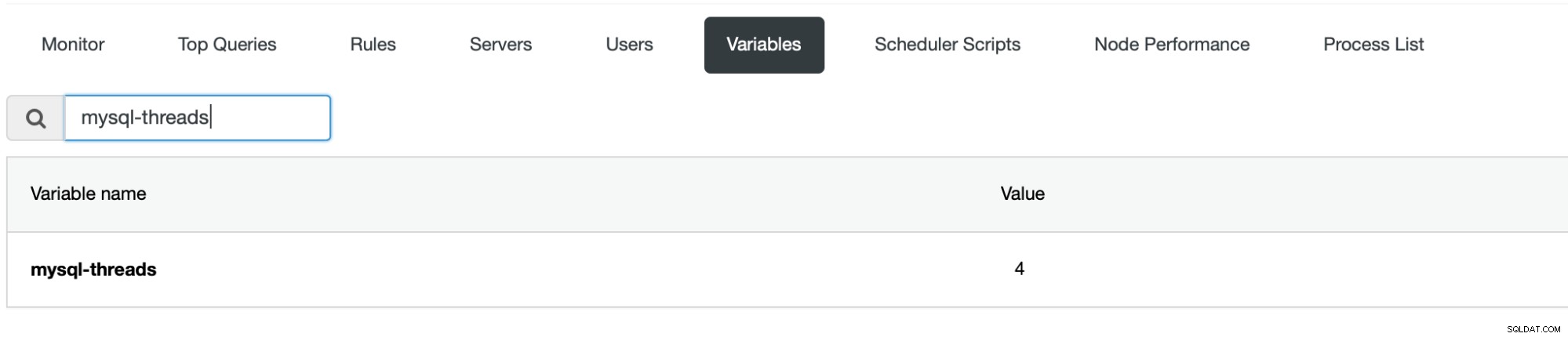
Pokud chcete využívat více jader CPU, toto je musíte také změnit nastavení.
Můžete se také pokusit o horizontální zvětšení. Namísto použití dvou ProxySQL instancí s VIP můžete propojit ProxySQL s hostiteli Moodle. Pak chcete překonfigurovat Moodle tak, aby se připojoval k ProxySQL na lokálním hostiteli, ideálně přes Unixový socket – je to nejefektivnější způsob připojení k ProxySQL. Není mnoho konfigurace, kterou používáme s ProxySQL, takže použití více instancí ProxySQL by nemělo přidávat příliš mnoho režie. Pokud chcete, můžete vždy nastavit ProxySQL Cluster, který vám pomůže udržovat instance ProxySQL v synchronizaci ohledně konfigurace.
Cluster MariaDB je přetížený
Nyní mluvíme o vážnějším problému. Samozřejmě pomůže zvětšení velikosti instancí, jako obvykle. Na druhou stranu je horizontální škálování poněkud omezené kvůli omezení „bezpečného čtení“. Jistě, můžete do clusteru přidat více uzlů, ale můžete je použít pouze pro bezpečné čtení. Do jaké míry vám to umožní škálovat, to závisí na pracovní zátěži. Pro čistou zátěž pouze pro čtení (procházení obsahu, fóra atd.) to vypadá docela dobře:
MySQL [(none)]> SELECT hostgroup, srv_host, srv_port, status, queries FROM stats_mysql_connection_pool WHERE hostgroup IN (20, 10) AND status='ONLINE';
+-----------+---------------+----------+--------+---------+
| hostgroup | srv_host | srv_port | status | Queries |
+-----------+---------------+----------+--------+---------+
| 20 | 192.168.1.204 | 3306 | ONLINE | 5683 |
| 20 | 192.168.1.205 | 3306 | ONLINE | 5543 |
| 10 | 192.168.1.206 | 3306 | ONLINE | 553 |
+-----------+---------------+----------+--------+---------+
3 rows in set (0.002 sec)To je v podstatě poměr 1:20 – na jeden dotaz, který zasáhne zapisovatele, máme 20 „bezpečných čtení“, které lze rozložit mezi zbývající uzly. Na druhou stranu, když začneme upravovat data, poměr se rychle změní.
MySQL [(none)]> SELECT hostgroup, srv_host, srv_port, status, queries FROM stats_mysql_connection_pool WHERE hostgroup IN (20, 10) AND status='ONLINE';
+-----------+---------------+----------+--------+---------+
| hostgroup | srv_host | srv_port | status | Queries |
+-----------+---------------+----------+--------+---------+
| 20 | 192.168.1.204 | 3306 | ONLINE | 3117 |
| 20 | 192.168.1.205 | 3306 | ONLINE | 3010 |
| 10 | 192.168.1.206 | 3306 | ONLINE | 6807 |
+-----------+---------------+----------+--------+---------+
3 rows in set (0.003 sec)Toto je výstup po vydání několika hodnocení, vytvoření témat fóra a přidání obsahu kurzu. Jak vidíte, s takovým poměrem bezpečných/nebezpečných dotazů bude zapisovač nasycen dříve než čtenáři, proto není vhodné škálování přidáváním dalších uzlů.
Co se s tím dá dělat? Existuje nastavení zvané „latence“. Podle konfiguračního souboru určuje, kdy je bezpečné číst tabulku po zápisu. Když dojde k zápisu, tabulka je označena jako upravená a po dobu „latence“ budou všechny SELECTy odeslány do zapisovacího uzlu. Jakmile uplyne čas delší než „latence“, mohou být SELECTy z této tabulky znovu odeslány čtecím uzlům. Mějte prosím na paměti, že s MariaDB Cluster je čas potřebný k použití sady zápisu ve všech uzlech obvykle velmi krátký, počítá se v milisekundách. To by nám umožnilo nastavit v konfiguračním souboru Moodle poměrně nízkou latenci, například hodnota jako 0,1s (100 milisekund) by měla být docela v pořádku. Samozřejmě, že pokud narazíte na nějaké problémy, vždy můžete tuto hodnotu ještě zvýšit.
Další možností testování by bylo spolehnout se čistě na MariaDB Cluster, aby zjistil, kdy je čtení bezpečné a kdy ne. Existuje proměnná wsrep_sync_wait, kterou lze nakonfigurovat tak, aby vynutila kontroly kauzality u několika vzorů přístupu (čtení, aktualizace, vkládání, odstraňování, nahrazování a SHOW příkazy). Pro náš účel by stačilo zajistit, aby se čtení provádělo s vynucenou kauzalitou, takže tuto proměnnou nastavíme na „1“.
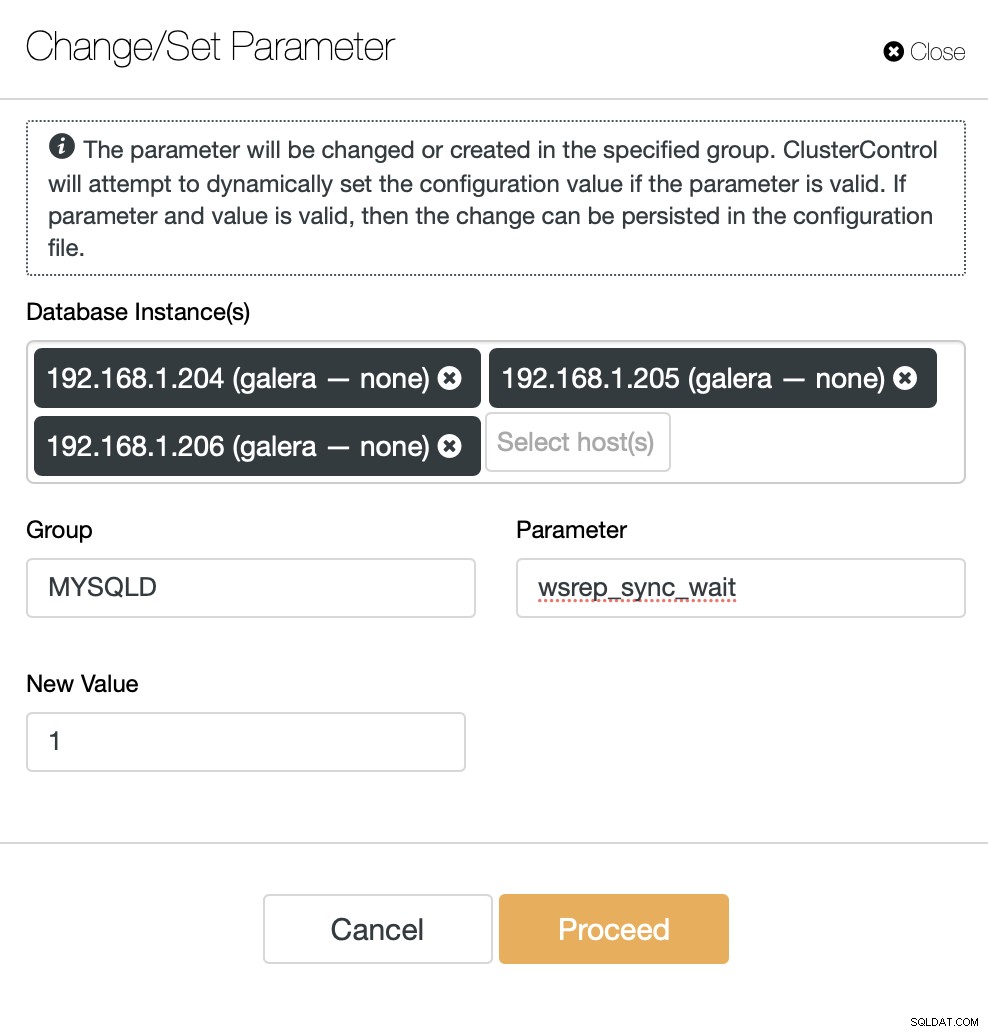
Chystáme se provést tuto změnu na všech uzlech clusteru MariaDB. Budeme také muset překonfigurovat ProxySQL pro rozdělení čtení/zápisu na základě pravidel dotazů, nejen uživatelů, jak jsme to dělali dříve. Odstraníme také uživatele „moodle_safereads“, protože v tomto nastavení již není potřeba.
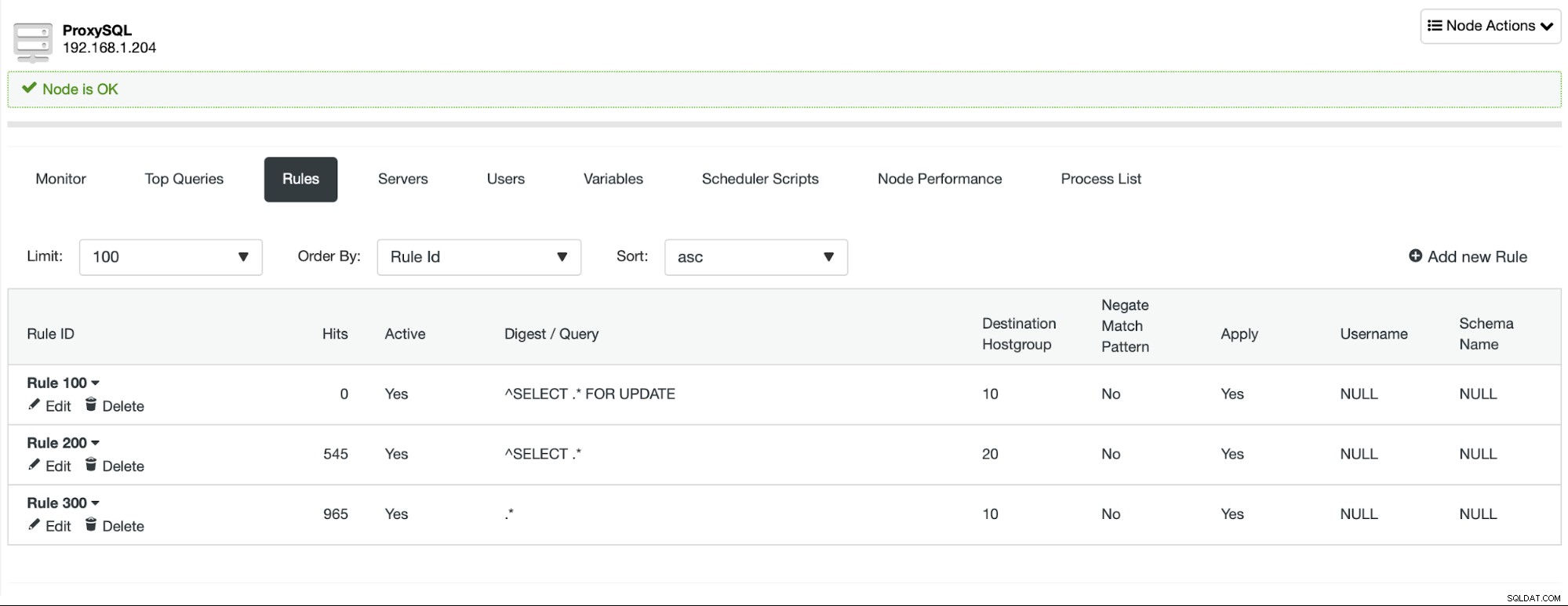
Nastavili jsme tři pravidla dotazu, která rozdělují provoz na základě dotazu. SELECT … FOR UPDATE je odeslána do zapisovacího uzlu, všechny dotazy SELECT jsou odeslány čtenářům a vše ostatní (INSERT, DELETE, REPLACE, UPDATE, BEGIN, COMMIT atd.) je zasláno také do zapisovacího uzlu.
To nám umožňuje zajistit, že všechna čtení lze rozložit mezi uzly čtečky, což umožňuje horizontální měřítko přidáním dalších uzlů do clusteru MariaDB.
Doufáme, že pomocí těchto několika tipů budete moci mnohem snadněji a ve větší míře škálovat backend databáze Moodle